hot150-01-数组/字符串
难度说明:🟢简单🟡中等🔴困难
hot150-01-数组/字符串
🟢01-合并两个有序数组(88)
1.题目内容
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
**注意:**最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
2.题解思路
👻方法1:双指针(参考合并两个有序链表思路)
思路分析:
(1)定义一个结果集合接收排序后的列表(此处尽量避免直接在nums1上操作,容易被一些边界条件坑,直接开新数组,然后得到结果封装)
(2)循环中同时遍历两个数组(当有任意一方遍历结束时则结束循环),随后判断剩下的nums1、nums2数组中是否还存在没有遍历的元素,将元素补到res中即可(这个思路和合并两个有序链表的思路是类似的)
(3)最后再将res元素赋值给nums1
public class Solution1 {
public void merge(int[] nums1, int m, int[] nums2, int n) {
// 定义结果
int[] res = new int[m + n];
// 定义遍历指针分别对应nums1、nums2数组遍历
int pointer1 = 0;
int pointer2 = 0;
int cur = 0 ; // 当前存储的位置
// 在数组下标限制范围内进行遍历
while(pointer1 < m && pointer2 < n) {
// 判断nums1 和 nums2 当前指针位置元素大小,按升序进行排序
if(nums1[pointer1] <= nums2[pointer2]) {
// 选择小数:即选择nums1[pointer1],指针后移
res[cur++] = nums1[pointer1++];
}else{
// 选择小数:即选择nums2[pointer2],指针后移
res[cur++] = nums2[pointer2++];
}
}
/**
* 尾巴判断(上述循环中必然有一个数组先遍历完,此处则继续确认剩下的元素)
* 如果是nums1还没遍历完,则需要把nums1的数补到res中
* 如果是nums2还没遍历完,则需要把nums2的数补到res中
*/
while(pointer1<m){
res[cur++] = nums1[pointer1++];
}
while(pointer2<n){
res[cur++] = nums2[pointer2++];
}
// nums1作为结果返回,此处封装结果
for(int i = 0 ; i < res.length ; i++){
nums1[i] = res[i];
}
}
}
复杂度分析
时间复杂度:O(m+n)需要对两个数组进行排序
空间复杂度:O(m+n)此处借助了额外的辅助数组存储排序后的结果元素
👻方法2:双指针(参考合并两个有序链表思路,空间优化版本)(🚀)
上述【方法1】中的算法中定义了额外的数组存储结果集,实际上此处可以基于"逆序遍历"的思路,从后往前存数据。选择这种遍历方式的好处主要是基于两个方面思考:
- ① 将
nums2合并到nums1中,直接用nums1的冗余的数组空间处理,不需要额外定义m+n的数组空间存储结果集 - ② 直接正序遍历会涉及到元素覆盖问题,因此考虑逆序遍历从后往前填充元素,则不存在元素覆盖的问题
/**
* 🟢 088 合并两个有序数组 - https://leetcode.cn/problems/merge-sorted-array/description/
*/
public class Solution1 {
/**
* 给定两个非递减顺序,合并nums2到nums1( nums1(预留空间为m+n),将nums2合并到nums1 )
*/
public void merge(int[] nums1, int m, int[] nums2, int n) {
int idx = m + n - 1; // idx 指向当前填充位置
// 用两个指针分别遍历两个数组元素,采用逆序遍历思路将较大的元素依次填充到指定位置
int p1 = m - 1, p2 = n - 1;
while (p1 >= 0 && p2 >= 0) {
if (nums1[p1] >= nums2[p2]) {
// 选择nums1中的元素
nums1[idx--] = nums1[p1--]; // 填充元素,且两个指针移动
} else {
// 选择nums2中的元素
nums1[idx--] = nums2[p2--]; // 填充元素,且两个指针移动
}
}
// 校验剩余元素(如果是nums1有剩余则不需要动(本身nums1就是结果集),如果nums2有剩余则继续填充处理)
while (p2 >= 0) {
nums1[idx--] = nums2[p2--]; // 填充元素,且两个指针移动
}
}
public static void main(String[] args) {
int[] nums1 = new int[]{1, 2, 3, 0, 0, 0};
int m = 3;
int[] nums2 = new int[]{2, 5, 6};
int n = 3;
Solution1 solution = new Solution1();
solution.merge(nums1, m, nums2, n);
PrintUtil.print(nums1);
}
}
👻方法3:硬核排序法
本质上这就是一个排序的思路,有时候不要把问题复杂化,类似合并两个有序链表也是可以类似地借助集合进行排序来实现的。其主要思路就是将两个数组的元素都丢到一个容器中,然后借助排序算法进行排序,随后返回排序结果
public class Solution2 {
public void merge(int[] nums1, int m, int[] nums2, int n) {
// 因为题目中nums1作为返回的结果,说明可以直接将nums2加入到nums1中,直接排序即可
int cur = 0;
for (int i = m; i < m + n; i++) {
nums1[i] = nums2[cur++];
}
// 对nums1进行排序
Arrays.sort(nums1);
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟢02-移除元素(27)
1.题目内容
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:
- 更改
nums数组,使nums的前k个元素包含不等于val的元素。nums的其余元素和nums的大小并不重要。 - 返回
k
2.题解思路
思路分析:根据题意说明,其目的有两个,一方面是要计算值为val的个数,一方面还要将所有的非val值给汇聚到数组头部。基于此如果不考虑原地的限制的话,实际上就可以在遍历的过程中统计val个数,并将非val收集到新数组。
但考虑原地做法,此处则考虑"交换"的思路,将所有的val移动到后面去,但比较尴尬的是这个K(val的个数)一开始并不明确,所以不知道从哪里开始后面的部分可以存val,所以首要思路可能就会先去遍历一遍数组元素确定这个K界限,然后再遍历一遍数组元素进行移动操作
另一种思路就是双指针,将val值全部移动到后面去
👻方法1:覆盖法
因为此处只需要关注将非val值收集到前面来,因此定义一个指针来记录当前非val可存储的下一个位置,然后遍历一遍数组,将非val依次填充到前面的数组中来(遍历的过程中,通过left指针非val值依次进行覆盖的位置)
public int removeElement(int[] nums, int val) {
int n = nums.length;
int left = 0; // 非 val 可存储的位置
for (int right = 0; right < n; right++) { // 遍历数组
if (nums[right] != val) { // 判断是否为非val,如果为非val则将其值覆盖到当前left的位置,并将left指针指向下一个存储的位置
nums[left] = nums[right];
left++;
}
}
return left;
}
复杂度分析
时间复杂度:
空间复杂度:
👻方法2:双指针法
public class Solution2 {
// 使用原地方法移除元素
public int removeElement(int[] nums, int val) {
// 双指针:把所有的val移动到右边
int left = 0, right = nums.length - 1;
// left 找val元素,right 找不是val的元素,指针相遇遍历结束
while (left <= right) {
if (nums[left] == val) {
// 判断当前右边位置,找一个可以交换的位置进行交换
if (nums[right] == val) {
// 如果right位置元素为val,则继续往前找
right--;
} else {
// 如果left位置元素不为val,则可进行一次交换操作,交换完成左指针继续后移
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
// 交换完成,左指针右移
left++;
}
} else {
// 如果left位置元素不为val,则继续往下找
left++;
}
}
return left;
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟢03-删除有序数组中的重复项(26)
1.题目内容
给你一个 非严格递增排列 的数组 nums ,请你** 原地** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。 - 返回
k。
2.题解思路
👻方法1:覆盖法
通过哈希表判断是否存在重复元素,如果存在则不做任何操作,如果不存在则将元素加入set集合,然后依次将非重复元素覆盖存储(定义cur指针来指向当前非重复元素存储的位置)
public class Solution1 {
/**
* 基础思路:判断重复元素概念,将所有非重复元素加入Set集合(去重),然后转化为nums即可
*/
public int removeDuplicates(int[] nums) {
// set存储不重复元素
HashSet<Integer> set = new HashSet<>();
// 定义数组元素的存储位置
int cur = 0;
for(int i=0;i<nums.length;i++){
if(!set.contains(nums[i])){
set.add(nums[i]);
nums[cur++] = nums[i]; // 直接覆盖值依次存储非重复元素
}
}
return cur;
}
}
复杂度分析
时间复杂度:
空间复杂度:
👻方法2:覆盖法(和删除有序数组中的重复项II解法思路类似(双指针概念))
// 覆盖法:cur 指向当前可覆盖的位置
public int removeDuplicates(int[] nums) {
// 数组本身有序
int cur = 1;
for (int i = 1; i < nums.length; i++) {
if(nums[cur-1]!=nums[i]){
nums[cur++] = nums[i];
}
}
return cur;
}
复杂度分析
时间复杂度:
空间复杂度:
🟡04-删除有序数组中的重复项II(80)
1.题目内容
给你一个有序数组 nums ,请你** 原地** 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以**「引用」**方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3。 不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,1,2,3,3]
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前七个元素被修改为 0, 0, 1, 1, 2, 3, 3。不需要考虑数组中超出新长度后面的元素。
2.题解思路
❌方法1:计数法
分别对每个元素进行计数,然后根据元素出现次数进行筛选,如果出现次数超出2则只存两次
// 计数法
public int removeDuplicates(int[] nums) {
// 定义map存储每个元素出现的次数
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<Integer, Integer>();
for (int i = 0; i < nums.length; i++) {
// 如果不存在则为0,存在则加1
map.put(nums[i], map.getOrDefault(nums[i], 0) + 1);
}
// 遍历Map集合,获取满足条件的元素长度
int cur = 0;
Set<Integer> keys = map.keySet();
Iterator<Integer> iterator = keys.iterator();
while (iterator.hasNext()) {
int key = iterator.next();
int value = map.get(key);
// value最多为2,value超出2次设置为2
value = value > 2 ? 2 : value;
for (int i = 0; i < value; i++) {
nums[cur++] = key;
}
}
return cur;
}
复杂度分析
时间复杂度:
空间复杂度:
👻方法2:指针法(覆盖法)
public class Solution2 {
/**
* todo 画图
* 因为给定数组有序,因此相同的元素是连续的
* 定义快慢指针进行遍历:慢指针指向当前元素存储的位置(新数组)、快指针用于遍历时指向当前比较元素
*/
public int removeDuplicates(int[] nums) {
// 判断nums长度
int len = nums.length;
// 如果nums长度小于等于2则直接返回数组长度
if(len<=2){
return len;
}
// 如果nums长度大于2,则通过覆盖的方式来进行元素更新
// 定义快、慢指针
int slow = 2;
int fast = 2;
// 遍历数组元素确认条件进行覆盖,当快指针走完了说明操作完成
while(fast<len){
// 判断当前快指针指向元素和其前2个元素是否相同,如果相同则快指针继续前进
if(nums[slow-2]==nums[fast]){
fast ++;
}else{
// 如果不相同,则覆盖当前位置
nums[slow] = nums[fast];
slow ++;
fast ++;
}
}
return slow;
}
}
public class Solution3 {
/**
* 因为给定数组有序,因此相同的元素是连续的
*/
public int removeDuplicates(int[] nums) {
// 数组边界校验
if (nums.length <= 2) {
return nums.length;
}
// 定义双指针实现
int cur = 2;
for (int i = 2; i < nums.length; i++) {
if (nums[i] != nums[cur - 2]) {
nums[cur] = nums[i];
cur++;
}
}
return cur;
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟢05-多数元素(169)🚀
1.题目内容
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素
2.题解思路
此处检索的是多数元素,可以采用计数法、排序法解决:
- 计数法:统计每个元素出现次数并记录到map中,然后遍历map找出出现次数大于n/2的元素
- 排序法:因此此处多数元素的设定是次数大于n/2的元素,且题目样例提供必定存在多数元素,因此次此处可以转化为排序思路,将数据元素进行排序,然后最终选择最中间的数
👻方法1:计数法
// 计数法
public int majorityElement1(int[] nums) {
// 思路:定义集合进行计数,判断元素出现次数大于n/2(只有1个)
HashMap<Integer, Integer> map = new HashMap<>(); // map<元素,对应出现次数>
for(int i=0;i<nums.length;i++){
map.put(nums[i],map.getOrDefault(nums[i],0)+1); // getOrDefault:指定key存在则返回value,不存在则返回0
}
// 遍历map集合,判断元素出现此处是否大于n/2
Set<Integer> set = map.keySet();
Iterator<Integer> iterator = set.iterator();
while(iterator.hasNext()){
int key = iterator.next();
if(map.get(key)>nums.length/2){
return key;
}
}
// 其他情况返回默认值
return -1;
}
复杂度分析
时间复杂度:
空间复杂度:
👻方法2:排序法
排序法思路过于简单,因此在排序的时候要考虑手撕排序算法(冒泡、归并、快速等)
// 排序法
public int majorityElement1(int[] nums) {
// 思路:对数组元素进行排序,然后选择最中间
Arrays.sort(nums);
return nums[nums.length / 2];
}
复杂度分析
时间复杂度:
空间复杂度:
🟡06-轮转数组(189)🚀
1.题目内容
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数
示例 1:
输入: nums = [1,2,3,4,5,6,7], k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右轮转 1 步: [7,1,2,3,4,5,6]
向右轮转 2 步: [6,7,1,2,3,4,5]
向右轮转 3 步: [5,6,7,1,2,3,4]
示例 2:
输入:nums = [-1,-100,3,99], k = 2
输出:[3,99,-1,-100]
解释:
向右轮转 1 步: [99,-1,-100,3]
向右轮转 2 步: [3,99,-1,-100]
2.题解思路
👻方法1:反转法(规律法)
- 思路分析
- 反转整个数组
- 反转数组的前K个元素(0,k)
- 反转数组的后N-K个元素(k,n)
反转法【1】:借助工具类进行反转
/**
* 189 轮转数组
*/
public class Solution1 {
// 反转法
public void rotate(int[] nums, int k) {
/**
* 此处轮转的体现效果可以理解为先对数组进行反转,然后分别对前k个元素反转、对后n-k个元素反转
* 此外还需注意轮转次数k和nums长度的关系(以len为一个轮次)
*/
k = k % nums.length;
// 将数组nums转化为List进行轮转(Stream流)
List<Integer> list = Arrays.stream(nums).boxed().collect(Collectors.toList());
// 反转整个数组
Collections.reverse(list);
// 反转前K个元素
Collections.reverse(list.subList(0,k));
// 反转后N-K个元素
Collections.reverse(list.subList(k,list.size()));
// 输出结果
for (int i = 0; i < nums.length; i++) {
nums[i] = list.get(i);
}
}
}
反转法【2】:自定义反转方法
此处核心是先自定义反转方法对数组进行反转,其次考虑到如果这个反转方法仅仅设定一个nums参数,那么操作过程中就需要对数组进行截断,然后再调用反转方法,这个过程实际上是可以再优化。对于自定义反转方法可以传入反转指定的start、end,以此简化了(省略)截断操作,可以对任意位置的数组段进行反转
/**
* 189 轮转数组
*/
public class Solution2 {
// 反转法(自定义反转逻辑)
public void rotate(int[] nums, int k) {
/**
* 此处轮转的体现效果可以理解为先对数组进行反转,然后分别对前k个元素反转、对后n-k个元素反转
* 此外还需注意轮转次数k和nums长度的关系(以len为一个轮次)
*/
k = k % nums.length;
// 反转整个数组
reverse(nums, 0, nums.length - 1);
// 反转数组的前k个元素
reverse(nums, 0, k - 1);
// 反转数组的后N-K个元素
reverse(nums, k, nums.length - 1);
}
// 数组反转:原地反转(双指针)
public void reverse(int[] nums, int start, int end) {
// int start = 0,end = nums.length-1;
while (start < end) {
// 交换当前指针元素
int temp = nums[start];
nums[start] = nums[end];
nums[end] = temp;
// 指针移动
start++;
end--;
}
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟢07-买卖股票的最佳时机(121)🚀
1.题目内容
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0
2.题解思路
暴力思路:双层循环(暴力遍历),依次判断假设当天买入,其后的每一天卖出的利润的最大值
贪心算法:单层循环,以低买高卖的思路操作,记录股票的历史最低价,假设股票是以历史最低价买入,然后卖出的话能获得的利润
👻方法1:贪心算法(低买高卖)
/**
* 121 买卖股票的最佳时机
*/
public class Solution1 {
/**
* 贪心算法:记录股票的历史低价,以及股票隔日卖出时可以获得利益(更新max)
*/
public int maxProfit(int[] prices) {
// 记录利益的最大值
int maxProfit = 0; // Integer.MIN_VALUE(此处设定利润初始化为0,后续利润是负数也没办法卖)
// 记录股票价格的历史最低价
int minHisPrice = prices[0]; // 默认第1天为最低价,后续遍历过程中更新最低价
// 遍历数组元素
for(int i=1;i<prices.length;i++) {
// 假设股票当前卖出,计算这个利润值,并对比是否可获得最大利益(更新目前的最大收益)
maxProfit = Math.max(maxProfit,prices[i] - minHisPrice);
// 更新历史最低价
minHisPrice = Math.min(minHisPrice,prices[i]);
}
// 返回结果
return maxProfit;
}
}
复杂度分析
时间复杂度:O(n),n 为数组长度
空间复杂度:O(1) 用了两个字段存储值,常数级别的消耗
👻方法2:动态规划
🟡08-买卖股票的最佳时机II(122)🚀
1.题目内容
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润
2.题解思路
👻方法1:贪心思路:利润拆分,收集正利润
如果基于利润分解的思路,可以将本题结合如下思路理解:
- 假设第0天买入,第3天卖出,则利润为prices[3] - prices[0],其等价于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])
- 也就是说,将利润分解为每天为单位的维度,而不是以一个整体的思路去考虑。也就是说每次都是今天买隔日卖(低买高卖)的思路去做,如果这个操作有利润就落袋为安,如果没有利润则不去做这个操作(相当于没有买卖)
- 股票价格:【7,1,5,10,3,6,4】
- 每日利润:【0,-6,4,5,-7,3,-2】(首日是没有利润的,贪心的思路是只收集每天的正利润)
/**
* 122 买卖股票的最佳时机II
*/
public class Solution2 {
// 每日可操作股票,但最多只能持有一股
public int maxProfit(int[] prices) {
/**
* 贪心思路:收集正利润,如果有利润就做T,没利润就不动
* nums[2]-nums[0] = (nums[2]-nums[1]) + (nums[1]-nums[0])
* 即可以理解为假设每天做T能得到正利润,那么就去做,如果不能则继续持有等待,进而使得这个数值最大
*/
// 定义最大利润值
int maxProfit = 0;
// 第1天没有利润,从第2天开始操作
for(int i = 1; i < prices.length; i++) {
// 判断是否能得到正利润
int t = prices[i] - prices[i-1];
if(t>0){
maxProfit += t; // 累加正利润
}
}
// 返回结果
return maxProfit;
}
}
复杂度分析
时间复杂度:O(n) n为数组长度
空间复杂度:O(1)
🟡09-跳跃游戏(55)
1.题目内容
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
2.题解思路
👻方法1:一步步走
核心:类似加油站加油场景,判断当前已走里程+加油里程能否支撑汽车走到下一个节点
可以结合实际场景案例分析:假设设定了N个加油站(n对应数组元素个数),每到一个加油站可以进行加油(nums[i]为最大加油油量),要看已走里程+站点的加油里程能否走到下一个节点,如果可以则一直延续到终点即可,如果中间某个环节不行则是无法到达终点的
在这个过程中必须始终选择可覆盖的最大范围,而不是"累加"概念
以【2 3 1 1 4】案例为例:起点是2,max设定为当前可覆盖的最大范围
i = 0:max=2i=1:从第i=1节点开始进行判断,判断此时的max能否支持走到i这个位置(即max>i是否成立)- 如果
max<i说明当前的max并不能支撑走到i这个位置,直接返回false(也就是说目前的最大覆盖范围并不能支持走到下一个节点) - 如果
max>=i说明当前的max能够支撑走到i这个位置,相应的要更新目前最新的最大覆盖范围,max 与i + nums[i]进行比较取最大值(i表示已走步数,nums[i]表示加油里程) 2>1说明此时是可以走到这个位置的,更新最大覆盖范围(max(2,1+3)=》4)
- 如果
i=2:以此类推,4>=2可以走,更新(max(4,2+1)=》4)i=3:以此类推,4>=3可以走,更新(max(4,3+1)=》4)i=4:以此类推,4>=4可以走,更新(max(4,4+4)=》8)
/**
* 55 跳跃游戏
*/
public class Solution1 {
// 思路:加油站加油概念,判断当前已走里程+当前可加油数(覆盖范围)能否支撑走到下一个节点
public boolean canJump(int[] nums) {
// 定义覆盖范围(最大覆盖范围:看最大覆盖范围能否支撑走到下一个节点)
int max = nums[0]; // 初始化最大覆盖范围为第一个加油站可加油量
for(int i = 1; i < nums.length; i++) {
if(max < i) {
return false; // 判断目前的覆盖范围能不能到达这个节点,如果不能则返回false
}
// 如果可以到达这个节点,则需要更新最大覆盖范围(一个是原来的max,一个是已走路程+可加油量,选择这两个中的最大值作为下一个可覆盖范围)
max = Math.max(max, i + nums[i]);
}
return true;
}
}
复杂度分析
时间复杂度:O(n) n 为数组长度
空间复杂度:O(1)
👻方法2:动态规划思路
步骤分析
【步骤1】:确定dp数组及下标含义(根据穷举规律来理解分析)
dp[i]:表示到达i位置时能到达的最远距离
【步骤2】:得到推导公式(结合规律得到
dp[k]的推导公式,即dp[k]与前面的元素有什么联系)dp[i] = max(dp[i-1], i + nums[i])(max(前i-1个节点的最大距离,当前节点能跳的最大距离))
【步骤3】:初始化dp数组(处理初始状态和一些临界的情况)
dp[0]=nums[0](起始可跳的距离就是当前节点提供的跳跃距离)
【步骤4】:确定循环(通过循环和推导公式填充dp数组)
- 循环遍历数组元素
【步骤5】:验证dp数组正确性
简化下述动态规划存储(因为不需要记录过程中的数据,只需要关注最大覆盖的距离,因此此处简化的版本之后就会变成解法【1】的思路)
// 思路:动态规划
public boolean canJump(int[] nums) {
// 1.dp[i] 表示到达`i`位置时能到达的最远距离
int[] dp = new int[nums.length];
// 2.确认dp公式 dp[i] = max{dp[i-1],i+nums[i]} 即max{第i-1个节点能到达的最远位置 , 已走距离+当前可支持跳跃距离}
// 3.初始化
dp[0] = nums[0];
// 4.确定循环
for (int i = 1; i < nums.length; i++) {
if (dp[i - 1] < i) { // 比较上一个覆盖范围可否到达当前节点
return false;
}
dp[i] = Math.max(dp[i - 1], i + nums[i]);
}
// 5.遍历dp数据,判断dp对应的值是否可以支撑走到当前节点(即前一个范围能否覆盖到当前节点)
// 此处可以在循环中就进行判断,如果走不到当前节点,则可以直接返回false
return true;
}
复杂度分析
时间复杂度:O(n) n 为数组长度
空间复杂度:O(n) n 为数组长度
🟡10-跳跃游戏II(45)
1.题目内容
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
0 <= j <= nums[i]i + j < n
返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。
2.题解思路
👻方法1:贪心算法
核心:每次都选择当前能跳的最大距离位置进行跳
以:[2,3,1,0,4]为例,自然是希望在可以跳的范围内下一跳能跳的更远,只要到达那个最远的位置才会选择去跳:
i=0:max = 2,说明其可以经过3、1,因此需要在3、1这两个位置处选择下一个最优性价比的位置进行跳- 如何确定这个性价比:即分别计算3、1这两个位置最远可到达的位置,其计算公式为当前
走的步数+支持跳的步数,分别为4 和 3,因此选择跳到3这个元素它的性价比才是最高的,因为它的最远到达可以多走一些距离- 因此此处max=4,此时point、i 都在起点,因此可以跳1步,在记录步数的同时附带更新point的值(point指向指向下一个可跳的最大位置)
- 如何确定这个性价比:即分别计算3、1这两个位置最远可到达的位置,其计算公式为当前
public class Solution1 {
/**
* 贪心思路:每次都选择当前能跳的最大距离位置进行跳
*/
public int jump(int[] nums) {
int max = 0; // max记录当前i位置可跳的最大位置
int point = 0; // point记录上一跳指定的可跳的最大位置
int step = 0; // 记录步数
for(int i=0;i<nums.length-1;i++){
// 更新当前位置可跳的最大位置
max = Math.max(max,i+nums[i]);
// 如果走到上一跳指定的最大的位置,则跳
if(point == i){
step++; // 当前位置可跳
point = max ;// 更新下一个可跳的最大位置
}
}
// 返回步数
return step;
}
}
复杂度分析
时间复杂度:O(n) n为数组大小
空间复杂度:O(1)
🟡11-H指数(274)
1.题目内容
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。
2.题解思路
核心:找n个论文,而且这n个论文被引用的次数不小于n,n取最大值
因此可以基于排序的思路,初始化h=0,从最高引用次数的元素开始遍历,如果nums[i] > h则说明起码有一篇论文被引用了h次,因此可以执行h++,以此类推,直到找到不满足条件则停止
👻方法1:排序法
思路
- 排序:对数据元素进行排序
- 遍历:从最大引用次数开始遍历,k 从 0开始计数,如果
nums[i]>k说明至少有一篇论文被引用了k+1次,则可以更新k值
public class Solution1 { // 核心:找n个论文,而且这n个论文被引用的次数不小于n,n取最大值 public int hIndex(int[] citations) { // 1.排序 Arrays.sort(citations); // 此处默认是升序排序 /** * 下标 0 1 2 3 4 * 原有 3 0 6 1 5 * 正序 0 1 3 5 6 * 对比可以看到,正序排序序列,要找出这个最大的K,需要逆序遍历 */ // 2.遍历(由于前面是升序排序,因此此处要逆序遍历) int k = 0; // k 表示h值 for(int i=citations.length-1; i>=0; i--) { if(citations[i] > k) { // citations[i] > k 表示找到一篇至少被引用k+1次的论文,因此h值可以+1 k++; } } // 返回结果 return k; } }复杂度分析
时间复杂度:
空间复杂度:
🟡12-O(1)时间插入、删除和获取随机元素(45)
1.题目内容
实现RandomizedSet 类:
RandomizedSet()初始化RandomizedSet对象bool insert(int val)当元素val不存在时,向集合中插入该项,并返回true;否则,返回false。bool remove(int val)当元素val存在时,从集合中移除该项,并返回true;否则,返回false。int getRandom()随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。
你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1) 。
2.题解思路
数据结构选型:首先理解如果用普通的方式实现CRUD操作的话,对应的时间复杂度:
- 数组:检索O(1)、插入O(n)、删除O(n)
- 哈希表:不支持下标定位到特定元素,无法在O(1)时间内完成随机元素操作、插入和删除复杂度为O(1)
基于此则需要将两者结合使用,来支持O(1)的操作。使用哈希表存储元素:key为元素值,value为元素在数组(变长数组)中所在的下标索引值
- 初始化:需要的辅助数据结构(可变长数组ArrayList、HashMap、Random)
- insert:
Map<val,val对应存储在数组的下标索引>、数组存储相应的元素- 此处新增元素都是在数组尾部追加的,因此新增元素的下标索引实际就是curLen(当前数组长度大小,因为下标是从0开始计算的)
- delete:此处删除操作如果待删除元素存在则需要先将待删除元素与最后一个元素进行交换,然后直接删除交换后的最后一个元素即可,以此确保整体的顺序
- 找:先找到待删除元素的索引
- 交换:将待删除元素与最后一个元素进行交换(map、list都要执行)
- 删除:删除交换后的最后一个元素(map、list都要执行)
- random:借助Random对象,随机生成一个
0-size直接的数据,然后返回指定下标索引的元素即可
👻方法1:变长数组+哈希表
/**
* 380 O(1) 时间插入、删除和获取随机元素
* 思路:借助数组(可变长数组)+哈希表结合使用
* 哈希表:key 存储实际的元素值,value 存储该元素在可变长数组中对应的下标位置,可变长数组存储相应的元素
*/
class RandomizedSet {
// 分别定义哈希表、可变长数组、Random对象
public HashMap<Integer, Integer> map;
public List<Integer> list;
public Random random;
/**
* 初始化函数(为了简化操作关注核心设计思路,使用现成的数据结构)
*/
public RandomizedSet() {
map = new HashMap<>();
list = new ArrayList<>();
random = new Random();
}
/**
* 插入操作:Map<key,对应其在数组的下标> list(存储元素)
* 需插入指定元素值,首先需判断元素是否存在,不存在则插入并返回true,存在则返回false
*/
public boolean insert(int val) {
if (map.containsKey(val)) {
// 元素存在,返回false
return false;
}
// 元素不存在,则需插入元素到集合中(分别插入到HashMap、List)
/**
* O(1) 思路:由于插入操作每次都是尾部插入,因此新元素的索引就是原数组的大小(下标从0开始计算)
* 因此此处不需要先插入数组,然后通过indexOf获取索引
* 而是直接根据数组长度来处理,以此达到O(1)计算的目的
*/
int curLen = list.size();
map.put(val, curLen);
list.add(val);
return true;
}
/**
* 删除操作
* 需分别删除数组和哈希表中的数据,首先需判断元素是否存在,存在则移除并返回true,不存在则返回false
*/
public boolean remove(int val) {
// 元素不存在,返回false
if (!map.containsKey(val)) {
return false;
}
// 元素存在,移除元素并返回true
/**
* O(1)思路:将待删除的值与最后一个元素进行交换,以确保删除操作可以直接删除更新后数组的最后一个元素,以此达到O(1)目的
* 交换的过程需要注意两个集合操作都需要交换
*/
int idx = map.get(val);
// 交换当前待删除元素和最后一个元素
int lastVal = list.get(list.size() - 1);
map.put(lastVal, idx); // map 操作:将最后一个元素移动到当前待删除位置
list.set(idx, lastVal);// 可变长数组操作:将最后一个元素移动到当前待删除位置
// 执行删除操作(此处交换后删除的是最后一个元素)
map.remove(val);// map 操作:删除交换后的最后一个元素(即目标val)
list.remove(list.size() - 1); // 可变长数组 操作:删除交换后的最后一个元素(即目标val)
return true;
}
public int getRandom() {
// 生成随机数,并返回
return list.get(random.nextInt(list.size()));
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟡13-除自身以外的乘积(238)🚀
1.题目内容
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 **不要使用除法,**且在 O(n) 时间复杂度内完成此题。
2.题解思路
👻方法1:暴力法
思路:双层循环统计每个元素除自身之外的所有乘积
public class Solution1 {
// 双层循环(暴力法):依次求除自身之外的乘积
public int[] productExceptSelf(int[] nums) {
// 定义结果
int[] res = new int[nums.length];
// 初始化res(1乘以任何数都为其本身)
Arrays.fill(res, 1); // 填充所有元素都为1
// 循环遍历计算乘积
for(int i=0;i<nums.length;i++){
for(int j=0;j<nums.length;j++){
if(i!=j){
res[i]*=nums[j];
}
}
}
// 返回结果
return res;
}
}
复杂度分析
时间复杂度:O(n2)
空间复杂度:O(n)
👻方法2:左右乘积法(动态规划思路:左侧前缀乘积*右侧后缀乘积)
- 左右乘积法思路(类似动态规划的思路,可以从最简单的案例进行分析寻找规律)
- 分别计算每个元素的左侧乘积和右侧乘积,然后循环遍历进行整合(但需注意此处并不是在循环中嵌套循环去计算,而是分别计算每个元素的左侧乘积和右侧乘积)
- 左侧乘积:正向遍历(从第2个元素位置开始:
left[i]=left[i-1]*nums[i-1]) - 右侧乘积:反向遍历(从倒数第二个元素开始:
right[i]=right[i+1]*nums[i+1]) - res:再次正向遍历,得到
res[i]=left[i]*right[i]
public class Solution2 {
// 左右乘积法:分别计算指定元素左侧和右侧的乘积,然后进行相乘
public int[] productExceptSelf(int[] nums) {
// 定义结果
int[] res = new int[nums.length];
// 左乘积
int[] left = new int[nums.length]; // 存储当前元素的左侧乘积(除自身)
Arrays.fill(left, 1);
int[] right = new int[nums.length];// 存储当前元素的右侧乘积(除自身)
Arrays.fill(right, 1);
// 左侧乘积计算
for (int i = 1; i < nums.length; i++) {
left[i] = left[i - 1] * nums[i - 1];
System.out.print(left[i] + "-");
}
System.out.println("-----------");
// 右侧乘积计算
for (int i = nums.length - 2; i >= 0; i--) {
right[i] = right[i + 1] * nums[i + 1];
System.out.print(right[i] + "-");
}
// 再次遍历,得到乘积(每个元素除自身的乘积=left*right)
for (int i = 0; i < nums.length; i++) {
res[i] = left[i] * right[i];
}
// 返回结果
return res;
}
}
复杂度分析
时间复杂度:需要进行3次遍历,时间复杂度趋向O(n)
空间复杂度:需要用到3个和原数组等长的数组进行处理,空间复杂度趋向O(n)
🟡14-加油站(150)
1.题目内容
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的
示例 1:
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
示例 2:
输入: gas = [2,3,4], cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
2.题解思路
👻方法1:规律法
问题的核心:从某个加油站出发,如果能够到达下一个加油站且剩余油量更多或者刚好够,就继续前进;如果剩余油量不足以到达下一个加油站,就从下一个加油站重新开始尝试确认
- 初始化:总油量(到达当前的【i】位置需要的总油量)、当前油量(当前【i】位置加油后到达下一个加油站后的剩余油量)、startIdx(出发的加油站起始索引)
- 依次遍历每个加油站,判断以startIdx开始,能否顺利走到下一个加油站,如果出现不可达情况,则从当前startIdx的下一个位置开始重新计算
- 遍历加油站,更新总油量和到达下一站的剩余油量
- 如果遍历过程中发现某站不可达下一站,则说明当前起始站出发无法完成行程,需要重置出发点和当前油量为0
- 通过不断遍历调试起始站,如果最终可以遍历完所有加油站,且总油量大于等于0,则说明找到了可行的起点,否则返回-1
此处设计巧妙的一点是,遍历过程中只关心的是当前站能否到达下一个站点,如果不能到达则重置起点,在遍历完成后才去校验所需总油量是否大于等于0(以确认循环是否可完成)
核心:如果x可以到达y,但是无法到达y+1,则x-y之间的任何一个点也无法到达y+1。因此循环遍历的过程是,如果无法到达下一个点则不断切换起点位置,确认循环能否完整走完,如果循环可以走完的话,则确认这段距离的总油量是否有剩余,如果无剩余则说明是不可构成环的
利用x点可以到达y但是到达不了y的下一站这个前提条件,然后运用放缩法对等式进行放缩,利用数学就可以得出,如果x可以到达y,但是到达不了y+1,那么x至y之间的任何点也不可能到达y+1。 `当然也可以直接分析得出结论,因为如果从x能到y,但是到不了y的下一站,那么肯定从y开始出发也必然到不了y的下一站,因为x能到y则必然到y时剩余的油量大于等于0,既然这个大于等于0都到不了y的下一站,那么必然从y点重新出发前,油量为0,则肯定到不了y的下一站。依次类推,x至y的所有中间点都到不了y的下一站
public class Solution1 {
/**
* 确认是否可以绕一圈
* @param gas 当前加油站可提供油量
* @param cost 从当前加油站到下一个加油站需要消耗的油量
*/
public int canCompleteCircuit(int[] gas, int[] cost) {
/**
* 思路:循环遍历每个加油站,确认其是否可到达下一个加油站
* 需要记录当前总油量、出发起点的加油站索引、从指定索引开始出发至今油量
*/
int totalGas = 0;
int startIdx = 0; // 起点加油站索引
int curGas = 0;
// 遍历每个加油站,确认是否可到达下一个加油站,如果出现不可到达的情况,则从下一个位置开始重新出发
for(int i = 0; i < gas.length; i++) {
// 更新最大油量和当前可剩油量
totalGas = totalGas + (gas[i] - cost[i]);
curGas = curGas + (gas[i] - cost[i]);
// 判断当前能否走到下一个加油站(如果出现不可达,则应从下一个加油站重新出发进行计算)
if(curGas < 0) { // (当前剩余油量+可加油量) 小于 到达下一站所需油量,说明此站不可达下一个站,则需切换起点
startIdx = i + 1; // 切换下一个起点进行计算
curGas = 0 ; // 重新切换后,当前剩余油量需重置为0
}
}
// 最终判断totalGas是否大于等于0(表示足够或者刚好能够到达)
return totalGas>=0?startIdx:-1;
}
}
复杂度分析
时间复杂度:
空间复杂度:
思路2:tocheck
1.先不考虑循环问题。
-2 -2 -2 3 3 这是每一个站加了油到下一个站能剩余的量(gas[i] - cost[i])(不考虑之前站加的油。) 从这个数组可以看出来, 是负数的必然不是起点,因为,就不可能走到下一个站。所以必然是正数的才可能是起点。 再猜想: 该数组的前缀和最小处可能是循环的终点,下一个位置可能是起点。 假设该点为a, 若a之前的某个点b是终点, 它的差数组接下来一段b->a和是负值,必然不能从b的下一个出发到a点。 (因为到达a才是前缀和最小,a前的一段和必然是负值) 再假设,终点在a的后边的某个位置b , 则a->b这一段和必然是正数,否则前缀和到b才是最小。在该段和是正数的情况下,从b的下一个出发,很可能无法到达a. 因为,该段和是正数,它在最小前缀的后边,需要最后经过a之后才能取到,但是可能恰好缺少该段和而不能到达a。
2.循环 对 前缀和 的影响。 若原差数组是 -2 3 3 -2 -2 求最小前缀和依然可以定位到第一个3作为出发点。 但是为什么循环没有影响呢。 为什么会等价于-2 -2 -2 3 3呢? 其实求前缀和的意义,就是划分,最小最大子段和, 对于 -2 3 3 -2 -2 完全肯伊等价于 -2 2 的问题把后边写成一个和 其就和 -2 -2 -2 3 3 是一致的的了。都是在前边存在最小前缀和, 后边为起点。
- 不可行的判断
(1) : 差数组的和 为负数, 必然不能走完循环。显然 (2): 那么对于和为正数的差数组,一定可以吗? 不显然,但是是的。 对于 该问题 总能划分为 -2 -2 -2 3 3 类似的形式, 如果后半段有负数如-2 3 3 -2 -2 也等价于 -2 2 问题 : 总是分为最小前缀和部分,和后边和为正数的形式。正数 >= 最小前缀 就一定能走完。
4 : 如果最小前缀是在最后的位置,如果sum >= 0 则 说明正数段在前边。
- code 将求差 和 求最小前缀和的过程合并。 */
class Solution {
public int canCompleteCircuit(int[] gas, int[] cost) {
int index = 0;
int minsum = gas[0] - cost[0];
int presum = gas[0] - cost[0];
for(int i = 1; i < gas.length; i++){
int tempsum = presum + gas[i] - cost[i];
if(tempsum < minsum) {
index = i;
minsum = tempsum;
}
presum = tempsum;
}
if(presum < 0) return -1;
return (index+1) % gas.length;
}
}
🔴15-分糖果(135)
1.题目内容
2.题解思路
👻方法1:
复杂度分析
时间复杂度:
空间复杂度:
🔴16-接雨水(42)
1.题目内容
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水

2.题解思路
👻方法1:动态规划
将接雨水的思路转化为:计算每个柱子可以接的雨水量,然后进行相应的累加(每个柱子可以接的雨水量等于其min(左侧最大前缀,右侧最大后缀)-柱子高度)
/**
* 42 接雨水
*/
public class Solution1 {
public int trap(int[] height) {
int res = 0;
/**
* 接雨水:计算每个柱子可以接的雨水量,然后进行累加
* 每个柱子可接雨水量=min(左侧最大前缀,右侧最大后缀)-柱子高度
*/
// 先分别计算每个元素的右侧最大后缀、左侧最大前缀
int n = height.length;
int[] leftMax = new int[n];
leftMax[0] = height[0]; // 初始化
int[] rightMax = new int[n];
rightMax[n-1] = height[n - 1]; // 初始化
// 计算左侧最大前缀
for (int i = 1; i < n; i++) {
leftMax[i] = Math.max(leftMax[i-1], height[i]);
}
// 计算右侧最大后缀
for(int i=n-2;i>=0;i--){
rightMax[i] = Math.max(rightMax[i+1], height[i]);
}
// 累计每个柱子可接雨水量(水往低处流,选择较小的柱子然后减去自身高度)
for(int i=0;i<n;i++){
res += Math.min(leftMax[i],rightMax[i]) - height[i];
}
// 返回结果
return res;
}
}
复杂度分析
时间复杂度:O(n)
空间复杂度:O(n)
🟢17-罗马数字转整数(13)
1.题目内容
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数
2.题解思路
通常情况下,罗马数字中小的数字在大的数字的右边。若输入的字符串满足该情况,那么可以将每个字符视作一个单独的值,累加每个字符对应的数值即可。
例如 XXVII 可视作 X+X+V+I+I=10+10+5+1+1=27
若存在小的数字在大的数字的左边的情况,根据规则需要减去小的数字。对于这种情况,我们也可以将每个字符视作一个单独的值,若一个数字右侧的数字比它大,则将该数字的符号取反。
例如 XIV 可视作 X−I+V=10−1+5=14
👻方法1:模拟(规律法)
解题核心:只要当前位置的元素比下个位置的元素小,就减去当前值,否则加上当前值
/**
* 013 罗马数字转整数
*/
public class Solution {
public int romanToInt(String s) {
// 定义结果
int res = 0;
// 构建字符映射集合
HashMap<Character, Integer> map = new HashMap<>();
map.put('I', 1);
map.put('V', 5);
map.put('X', 10);
map.put('L', 50);
map.put('C', 100);
map.put('D', 500);
map.put('M', 1000);
// 解析字符串(规则:只要当前元素比下一位元素小就减去值,如果比下一位大就加上值)
int len = s.length();
for (int i = 0; i < len; i++) {
int curVal = map.get(s.charAt(i));
if ((i < len - 1) && (curVal < map.get(s.charAt(i + 1)))) { // 如果当前元素比下一位小则减去当前值,如果比下一位元素大就加上,且i最大可达n-2的位置(注意数组越界)
res -= curVal;
} else {
res += curVal;
}
}
// 返回结果
return res;
}
}
复杂度分析
时间复杂度:O(n)
空间复杂度:O(1)
🟡18-整数转罗马数字(45)
1.题目内容
七个不同的符号代表罗马数字,其值如下:
| 符号 | 值 |
|---|---|
| I | 1 |
| V | 5 |
| X | 10 |
| L | 50 |
| C | 100 |
| D | 500 |
| M | 1000 |
罗马数字是通过添加从最高到最低的小数位值的转换而形成的。将小数位值转换为罗马数字有以下规则:
- 如果该值不是以 4 或 9 开头,请选择可以从输入中减去的最大值的符号,将该符号附加到结果,减去其值,然后将其余部分转换为罗马数字。
- 如果该值以 4 或 9 开头,使用 减法形式,表示从以下符号中减去一个符号,例如 4 是 5 (
V) 减 1 (I):IV,9 是 10 (X) 减 1 (I):IX。仅使用以下减法形式:4 (IV),9 (IX),40 (XL),90 (XC),400 (CD) 和 900 (CM)。 - 只有 10 的次方(
I,X,C,M)最多可以连续附加 3 次以代表 10 的倍数。你不能多次附加 5 (V),50 (L) 或 500 (D)。如果需要将符号附加4次,请使用 减法形式。
给定一个整数,将其转换为罗马数字。
示例 1:
输入:num = 3749
输出: "MMMDCCXLIX"
解释:
3000 = MMM 由于 1000 (M) + 1000 (M) + 1000 (M)
700 = DCC 由于 500 (D) + 100 (C) + 100 (C)
40 = XL 由于 50 (L) 减 10 (X)
9 = IX 由于 10 (X) 减 1 (I)
注意:49 不是 50 (L) 减 1 (I) 因为转换是基于小数位
示例 2:
输入:num = 58
输出:"LVIII"
解释:
50 = L
8 = VIII
示例 3:
输入:num = 1994
输出:"MCMXCIV"
解释:
1000 = M
900 = CM
90 = XC
4 = IV
2.题解思路
👻方法1:模拟(规律法)
思路分析
根据罗马数字的表示规则:可以看到其一共列举了13种独特的符号
- 普通规则:1 (
I),5 (V),10 (X),50 (L),100 (C) 和 1000 (M) - 减法规则:4 (
IV),9 (IX),40 (XL),90 (XC),400 (CD) 和 900 (CM)
罗马数字的规则是:对于罗马数字从左到右的每一位,选择尽可能大的符号值。对于 140,最大可以选择的符号值为 C=100。接下来,对于剩余的数字 40,最大可以选择的符号值为 XL=40。因此,140 的对应的罗马数字为 C+XL=CXL
因此可以借助罗马数字的唯一表示规律:每次都循环找到不超过num的最大符号值,用num减去这个符号值,并将这个符号值拼接到结果中,循环直到num减为0
写法1:暴力循环
public class Solution2 {
public String intToRoman(int num) {
// 构建字符串序列
StringBuilder roman = new StringBuilder();
// 罗马数字表示规则:一直找最大的字符值,找到后进行拼接,并减去对应整数值,以此类推,直到num为0(硬核遍历方式)
while (num > 0) {
// 从大到小遍历
if (num >= 1000) {
num -= 1000;
roman.append("M");
} else if (num >= 900) {
num -= 900;
roman.append("CM");
} else if (num >= 500) {
num -= 500;
roman.append("D");
} else if (num >= 400) {
num -= 400;
roman.append("CD");
} else if (num >= 100) {
num -= 100;
roman.append("C");
} else if (num >= 90) {
num -= 90;
roman.append("XC");
} else if (num >= 50) {
num -= 50;
roman.append("L");
} else if (num >= 40) {
num -= 40;
roman.append("XL");
} else if (num >= 10) {
num -= 10;
roman.append("X");
} else if (num >= 9) {
num -= 9;
roman.append("IX");
} else if (num >= 5) {
num -= 5;
roman.append("V");
} else if (num >= 4) {
num -= 4;
roman.append("IV");
} else if (num >= 1) {
num -= 1;
roman.append("I");
}
}
// 返回结果
return roman.toString();
}
}
写法2:集合遍历
/**
* 012 整数转罗马数字
*/
public class Solution1 {
public String intToRoman(int num) {
// 构建字符串序列
StringBuilder roman = new StringBuilder();
// 定义罗马数字映射集(将13种情况进行列举):每次查找都优先找最大的,此处借助需构建有序性(此处也可以通过两个数组做)
LinkedHashMap<Integer, String> map = new LinkedHashMap<>();
map.put(1000, "M");
map.put(900, "CM");
map.put(500, "D");
map.put(400, "CD");
map.put(100, "C");
map.put(90, "XC");
map.put(50, "L");
map.put(40, "XL");
map.put(10, "X");
map.put(9, "IX");
map.put(5, "V");
map.put(4, "IV");
map.put(1, "I");
// 罗马数字表示规则:一直找最大的字符值,找到后进行拼接,并减去对应整数值,以此类推,直到num为0
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while (it.hasNext()) { // 依次遍历映射集
Map.Entry<Integer, String> entry = it.next();
int key = entry.getKey();
String value = entry.getValue();
while (num >= key) { // 如果num>=key 说明需进行转化(因为映射集本身从大到小进行排序,因此此处就是在转化最大值)
roman.append(value);
num -= key;
}
if (num == 0) { // 当num为0的时候,退出,直到所有的字符遍历完成
break;
}
}
return roman.toString();
}
}
写法3:集合遍历(和写法2类似,此处用数组做)
public class Solution3 {
public String intToRoman(int num) {
// 构建字符串序列
StringBuilder roman = new StringBuilder();
// 定义罗马数字映射集(将13种情况进行列举):每次查找都优先找最大的,此处借助需构建有序性(此处也可以通过两个数组做)
int[] numbers = new int[]{1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1};
String[] romans = new String[]{"M","CM", "D","CD","C","XC", "L", "XL", "X", "IX", "V", "IV", "I"};
// 罗马数字表示规则:一直找最大的字符值,找到后进行拼接,并减去对应整数值,以此类推,直到num为0
for(int i=0;i<numbers.length;i++) {
while(num>=numbers[i]){
roman.append(romans[i]);
num -= numbers[i];
}
if(num==0){
break;
}
}
// 返回结果
return roman.toString();
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟢19-最后一个单词的长度(58)
1.题目内容
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串
示例 1:
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为 5。
示例 2:
输入:s = " fly me to the moon "
输出:4
解释:最后一个单词是“moon”,长度为 4。
示例 3:
输入:s = "luffy is still joyboy"
输出:6
解释:最后一个单词是长度为 6 的“joyboy”。
2.题解思路
👻方法1:字符串切割
可借助String的split将字符串切割为字符串数组,然后取最后一个
/**
* 058 最后一个单词的长度
*/
public class Solution1 {
// 思路:字符串切割,取最后一个字母
public int lengthOfLastWord(String s) {
String[] splitStr = s.split(" ");
return splitStr[splitStr.length - 1].length();
}
}
复杂度分析
时间复杂度:
空间复杂度:
👻方法2:反向遍历
反向遍历字符串,从第一个非空格字符开始遍历,遇到空格则说明这个单词结束了
public class Solution2 {
// 思路:反向遍历(从第一个非空格字符开始遍历,后面遇到空格说明单词遍历结束了)
public int lengthOfLastWord(String s) {
// 定义结果
int res = 0;
// 逆序(反向遍历)
for(int i = s.length() - 1; i >= 0; i--) {
char c = s.charAt(i);
// 跳过尾部可能存在的空格字符,且要遍历的第一个字母肯定不为空(因此遍历退出的条件是字符为空格且res不为空)
if(c==' ' && res !=0){
break ;
}
// 非空格字符才计算
if(c!=' '){
res ++;
}
}
// 返回结果
return res;
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟢20-最长公共前缀(14)
1.题目内容
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀
2.题解思路
👻方法1:正常思路
正常分析思路:理想情况下最长前缀是这个数组中长度最小的字符串,因此可以拆分思路:
- (1)找到这个理想的最长前缀 minStr (长度最小的字符串)
- (2)通过截取这个minStr 的前缀来依次进行匹配,确认最长
/**
* 14 最长公共前缀
*/
public class Solution1 {
/**
* 思路:理想情况下最长前缀是这个数组中长度最小的字符串,因此可以拆分思路:
* 1.找到这个理想的最长前缀 prefix(长度最小的字符串)
* 2.通过截取这个prefix来依次进行匹配,确认最长
*/
public String longestCommonPrefix(String[] strs) {
// 定义最大前缀
String maxPrefix = "";
String minStr = strs[0];
// 1.找到minStr(最短ed字符串)
for (int i = 0; i < strs.length; i++) {
if (strs[i].length() < minStr.length()) {
minStr = strs[i];
}
}
// 预设maxPrefix为理想情况
maxPrefix = minStr;
// 2.通过截取minStr,分别和数组元素进行匹配(此处需注意i最大可以取到minStr.length()位置)
for(int i = 0; i <= minStr.length(); i++) {
String prefix = minStr.substring(0, i);
// 如果校验不匹配则直接返回
if(!valid(prefix,strs)){
return minStr.substring(0, i-1);
}
}
return maxPrefix; // return null; ""表示不存在最长前缀
}
// 校验数组中的每个元素是否有公共前缀
public boolean valid(String prxfix,String[] strs) {
for (String str : strs) {
if(!str.startsWith(prxfix)) {
return false;
}
}
return true;
}
}
复杂度分析
时间复杂度:O(n2) 理想情况下找出最小字符串,然后遍历数组校验前缀是否匹配,最坏的情况就是数组中所有元素都一样,因此遍历匹配就会变成暴力的双层校验
空间复杂度:O(1)
👻方法2:技巧法(排序:比较最长和最短)
分析:通过将字符串进行排序,然后比较最短的字符和最长的字符的最大公共前缀即可
例如:["flower","flow","flight"] 字符串排序后:[]
/**
* 14 最长公共前缀
*/
public class Solution2 {
/**
* 思路:先对字符串数组进行排序,然后只需要比较最短和最长字符串这两个元素的最大前缀
*/
public String longestCommonPrefix(String[] strs) {
String maxPrefix = "";
// 对字符串数组进行排序
Arrays.sort(strs);
// 获取最短和最长的两个元素(首位)
String minStr = strs[0];
String maxStr = strs[strs.length - 1];
maxPrefix = minStr; // 理想情况下maxPrefix是最小的字符串
// 定义游标位置(记录最大前缀的位置)
int idx = 0;
for (int i = 0; i <= minStr.length(); i++) {
// 如果最大的字符串包括了这个前缀部分,则可以继续后移
if (maxStr.startsWith(minStr.substring(0, idx))) {
idx++;
} else {
// 不包括说明不符合
return minStr.substring(0, idx - 1);
}
}
return maxPrefix;
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟡21-反转字符串中的单词(151)
1.题目内容
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
**注意:**输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = "the sky is blue"
输出:"blue is sky the"
示例 2:
输入:s = " hello world "
输出:"world hello"
解释:反转后的字符串中不能存在前导空格和尾随空格。
示例 3:
输入:s = "a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个
2.题解思路
👻方法1:字符串切割+反向遍历
切割字符串(需注意可能存在多个连续空格的情况,需要引入正则表达式进行限定)
/**
* 151 反转字符串中的单词
*/
public class Solution1 {
/**
* 思路分析:字符串切割思路:先把单词拆出来,然后逆序遍历单词数组
*/
public String reverseWords(String s) {
// 定义结果
StringBuilder res = new StringBuilder();
// 字符串切割,拆分单词(注意首尾空格和连续空格的情况)
s = s.trim(); // 去除首尾空格
String[] words = s.split("\\s+"); // s.split(" ") 单个空格切分
// 逆序遍历,插入结果集
for (int i = words.length - 1; i >= 0; i--) {
res.append(words[i]);
// 单词补充空格(如果遍历到最后一个单词则不需要补充)
if (i > 0) {
res.append(" ");
}
}
// 返回结果
return res.toString();
}
}
复杂度分析
时间复杂度:
空间复杂度:
👻方法2:字符串切割(split)+反转(reverse)+拼接(join)
思路:和思路1类似,此处完全依靠Java工具类(语言特性)完成操作
public class Solution2 {
/**
* 思路分析:字符串切割思路
* 字符串切割(split) + 反转(reverse) + 拼接(join)
*/
public String reverseWords(String s) {
// 1.切割字符串(注意首尾空格和连续空格的处理)
String[] words = s.trim().split("\\s+");
// 2.反转数组
List<String> list = Arrays.asList(words);
Collections.reverse(list);
// 3.拼接返回
return String.join(" ", list);
}
}
复杂度分析
时间复杂度:
空间复杂度:
🟡22-Z字形变换(6)
1.题目内容
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:
P A H N
A P L S I I G
Y I R
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"PAHNAPLSIIGYIR"。
请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);
示例 1:
输入:s = "PAYPALISHIRING", numRows = 3
输出:"PAHNAPLSIIGYIR"
示例 2:
输入:s = "PAYPALISHIRING", numRows = 4
输出:"PINALSIGYAHRPI"
解释:
P I N
A L S I G
Y A H R
P I
示例 3:
输入:s = "A", numRows = 1
输出:"A"
2.题解思路
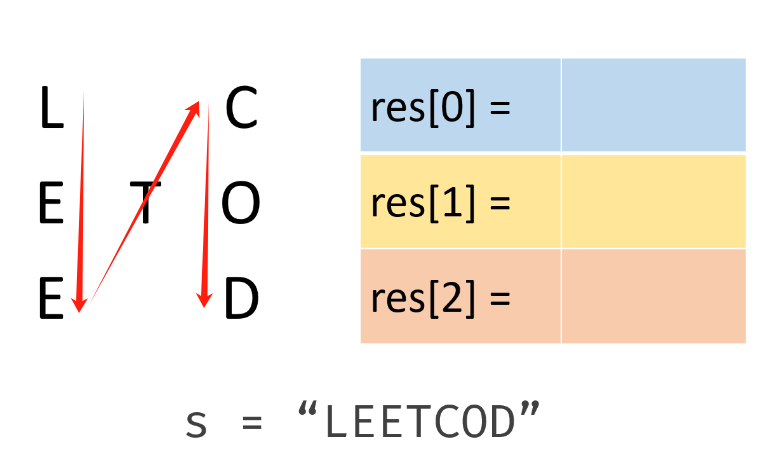
👻方法1:规律法
结合题意,问题的核心可以梳理为两部分:
- 【步骤1】将元素放在合适的位置(例如此处可以用二维数据或者
List<StringBuffer>来存储)(需考虑指定行数的边界情况,如果numRows<2直接返回即可) - 【步骤2】遍历元素(遍历生成的集合)
/**
* 006 Z字形变换
*/
public class Solution1 {
/**
* Z 字形变换:实际就是将字符串按照顺序存放到一个二维数组中
* 此处的二维数组:可以用一个List<StringBuffer>来平替,便于操作
*/
public String convert(String s, int numRows) {
// 对边界进行处理
if(numRows < 2) return s;
// 定义一个集合分别存储行的数据,通过flag来指定当前行(此处使用StringBuilder便于拼接,也可以用二维数组)
List<StringBuilder> list = new ArrayList<>();
for (int i = 0; i < numRows; i++) {
list.add(new StringBuilder());
}
int idx = 0;// 记录当前插入行的位置
int flag = -1; // 一个操作标识
// 遍历元素,然后将其插入集合合适的位置
for (int i = 0; i < s.length(); i++) {
// 插入指定元素
StringBuilder curRow = list.get(idx); // 获取当前插入行
curRow.append(s.charAt(i)); // 插入元素
// 如果遇到行的上下边界则需要进行切换(此处Z型反转的逻辑需注意处理)
if (idx == 0 || idx == numRows - 1) {
flag = -flag; // 取相反数,表示切换+1、-1操作(遇到上边界则后面的操作是+1、遇到下边界则后面的操作是-1)
}
// 更新插入的行位置
idx = idx + flag;
}
// 遍历处理好的元素(按行输出)
StringBuilder res = new StringBuilder();
for (StringBuilder sb : list) {
res.append(sb);
}
// 返回结果
return res.toString();
}
}
复杂度分析
时间复杂度:初始化容器需要时间、遍历封装需要时间、遍历读取需要时间,整体看为O(n)
空间复杂度:需要一个
List<StringBuilder>进行存储,其大小取决于指定行数、字符串大小
🟢23-找出字符串中第一个匹配项的下标(28)
1.题目内容
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
2.题解思路
👻方法1:滑动窗口
- 核心思路:
- 【1】定义一个和target等大的窗口
- 【2】通过这个窗口截取源字符串,然后进行校验
/**
* 028 找出字符串中第一个匹配项的下标
*/
public class Solution1 {
/**
* 思路:快速判断target字符串是否为原字符串的一部分,如果不是则返回-1,如果是则找出其索引
* 滑动窗口思路:定义一个和target等大的窗口,因此滑动校验目标字符串是否存在target
*/
public int strStr(String haystack, String needle) {
// 定义一个滑动窗口的开始和结束索引的起始位置
int start = 0;
int end = needle.length();
// 遍历字符串,确认target是否存在(当end滑到右侧表示遍历结束)
while(end<=haystack.length()) { // 注意边界条件
// 判断窗口是否和target匹配,如果匹配则返回
if(haystack.substring(start,end).equals(needle)) {
return start;
}
// 如果没有找到合适的值,则窗口继续向右移动
start ++;
end ++;
}
// 无响应结果
return -1;
}
}
复杂度分析
时间复杂度:O(n)(n为源字符串长度)
空间复杂度:O(1)
👻方法2:投机取巧法(indexOf)
class Solution {
public int strStr(String haystack, String needle) {
return haystack.indexOf(needle);
}
}
复杂度分析
时间复杂度:
空间复杂度:
🔴24-左右文本对齐(68)
1.题目内容
2.题解思路
👻方法1:
复杂度分析
时间复杂度:
空间复杂度: