【微博系统】设计核心
【微博系统】设计核心
学习核心
如何设计一个【微博】系统?(系统的核心功能)
沟通对齐
- ① 需求分析:关注微博系统的核心功能(发微博、关注好友、刷微博)
- ② 系统量级参数预估:预估10亿用户(日活跃20%),平均每个日活用户每天发表1条微博,且平均有500个关注者
- (1)发微博所需存储空间预估(预计日内需要多少空间存储微博数据)
- 文本内容存储空间:每条微博限制140字(按照汉字存储,加上微博ID、用户ID、时间戳、经纬度等数据,设定一条微博大小为500KB),日内存储微博文本所需存储空间约为100GB
- 多媒体文件存储空间:设定每5条微博包含1张图片(图片大小500KB),每10条微博包含1个视频(视频大小10MB),日内存储多媒体文件所需存储空间为60TB
- (2)刷微博访问并发量预估
- QPS:假设2亿日活用户每日刷两次微博,每次进入某个人的主页10次,每次显示20条微博,那么每天刷新微博次数约为40亿次(40亿次查询接口调用),平均QPS约为5万,高峰期按照平均值的2倍计算,因此系统需要满足10万QPS
- 网络带宽:针对10万QPS刷新请求,每次返回微博20条,即每秒访问200万条微博(基于上述每5条微博包含1张图片、每10条微博包含1个视频,计算平均值,得到文本+图片+视频的带宽),约为4.8Tb/s
- (1)发微博所需存储空间预估(预计日内需要多少空间存储微博数据)
- ④ 难点分析
- 微博系统的业务核心功能并不复杂,需关注的核心要点在于解决高并发和大数据量问题(并发访问、大数据量存储)
整体设计
- ① 服务设计(分层设计)
- ② 存储设计(存储选型):MySQL + Redis + 本地缓存
- ③ 业务设计(业务流程)
要点分析(或难点分析)
① 微博的发表/订阅问题:推/拉模式的选择 =》采用推拉模式相结合(理解推拉模式的优缺点)
- 推模式:用户发表微博的时候将微博列表推送到其所有关注用户,当一个用户拥有很多关注者的时候存在写压力
- 拉模式:用户刷微博的时候主动拉取关注列表中最新发表的微博信息,虽然解决上述推模式的写压力,但如果关注列表过多或者关注好友发送太多微博就会存在读压力,需通过限制关注列表上限或引入缓存机制来缓解读压力
- 推拉模式结合:用户在线时采用推模式将更新的微博放在一个列表中;用户离线时清空最新微博列表,当用户在线采用拉模式进行拉取
② 缓存使用策略:基于10万QPS的考虑,尽量让访问落到缓存上,但缓存也不是无上限使用的,因此要选用合适的缓存淘汰机制、考虑缓存核心的数据
- LRU 缓存淘汰策略(最近未被使用):如果用户的好友发表了一条微博久久没有被访问,那么虽然其是对于用户来说是关注列表最新的,但仍存在淘汰风险
- 时间淘汰策略:限定一段时间内发表的最新微博被缓存起来,根据时间先后进行数据淘汰。但对于一些热门微博内容存在高并发访问压力(例如一个大V用户发表微博,可能会成为爆点),考虑引入本地缓存缓解查询压力
- 淘汰策略选择:缓存所有用户7日内发表的全部微博,为了缓解热点访问数据压力,引入本地缓存(缓存拥有100万以上关注者的大V用户48h内发表的全部微博)
③ 数据分片策略:考虑到单机无法承载5000/s的写入压力,引入分片部署缓解数据库压力,分片的规则可以采用【用户ID分片】或【微博ID】分片
【按用户ID(的hash值)分片】那么一个用户发表的全部微博都会保存到一台数据库服务器上
- 优点:支持按用户查找,当系统需要按用户查找其发表的微博的时候,只需要访问一台服务器就可以完成
- 缺点:存在热点问题,对于一个明星大V用户,其数据访问会成热点,进而导致这台服务器负载压力太大。同样地,如果某个用户频繁发表微博,也会导致这台服务器数据增长过快
【按微博 ID(的hash值)分片】
- 优点:可以避免上述按用户ID分片的热点聚集问题
- 缺点:不支持按用户查找,当查找一个用户的所有微博时,需要访问所有的分片数据库服务器才能得到所需的数据,对数据库服务器集群的整体压力太大
综合考虑,用户ID分片带来的热点问题,可以通过优化缓存来改善;而某个用户频繁发表微博的问题,可以通过设置每天发表微博数上限(每个用户每天最多发表50条微博)来解决。因此可以考虑按用户ID分片的策略
总结陈述
学习资料
🟢【微博系统】场景核心
微博(microblog)是一种允许用户即时更新简短文本(比如140个字符),并可以公开发布的微型博客形式。此处思考如何开发一个面向全球用户、可以支持10亿级用户体量的微博系统
微博有一个重要特点就是部分明星大V拥有大量的粉丝。如果明星们发布一条比较有话题性的个人花边新闻,比如宣布结婚或者离婚,就会引起粉丝们大量的转发和评论,进而引起更大规模的用户阅读和传播。这种突发的单一热点事件导致的高并发访问会给系统带来极大的负载压力,处理不当甚至会导致系统崩溃。而这种崩溃又会成为事件热点的一部分,进而引来更多的围观和传播。
因此,微博系统面临的技术挑战,一方面是微博这样类似的信息流系统架构是如何设计的,另一方面就是如何解决大V们的热点消息产生的突发高并发访问压力,保障系统的可用性
🚀【微博系统】场景实战
1.沟通对齐
此处的沟通对齐方向,主核心方向是需求分析、请求量分析、精准度分析、难点/要点分析,可能还有涉及到其他的一些容量、设计等方面的对齐
① 需求分析
【微博】系统的核心功能
- 微博系统核心功能(此处对于系统的通用功能例如登录注册、用户资料等不做概述,关注微博的核心功能)
- ① 发微博:用户可以发表微博,内容包含不超过140个字的文本,可以包含图片和视频
- ② 关注好友:用户可以关注其他用户
- ③ 刷微博:
- 用户打开自己的微博主页,主页显示用户关注的好友最近发表的微博;
- 用户向下滑动页面(或者点刷新按钮),主页将更新关注好友的最新微博,且最新的微博显示在最上方;
- 主页一次显示20条微博,当用户滑动到主页底部后,继续向上滑动,会按照时间顺序,显示当前页面后续的20条微博
- ④ 扩展:收藏、转发、评论微博
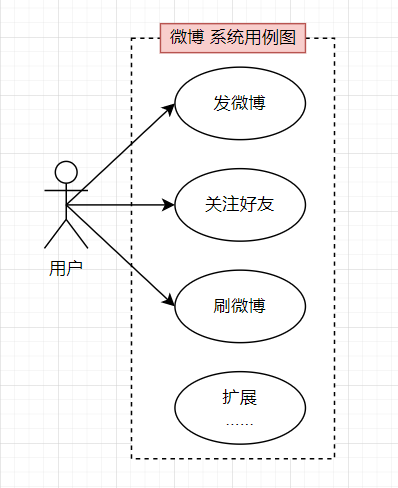
业务流程分析
② 性能指标估算
系统按10亿用户设计,按20%日活估计,大约有2亿日活用户(DAU),其中每个日活用户每天发表一条微博,并且平均有500个关注者。
而对于发微博所需的存储空间,做如下估算。
- 文本内容存储空间
遵循惯例,每条微博140个字,如果以UTF8编码存储汉字计算,则每条微博需要140*3=420个字节的存储空间。除了汉字内容以外,每条微博还需要存储微博ID、用户ID、时间戳、经纬度等数据,按80个字节计算。那么每天新发表微博文本内容需要的存储空间为100GB(2亿 * (420B+80B) = 100GB/天)
- 多媒体文件存储空间
除了140字文本内容,微博还可以包含图片和视频,按每5条微博包含一张图片,每10条微博包含一个视频估算,每张图片500KB,每个视频2MB,每天还需要60TB的多媒体文件存储空间(2亿 / 5 * 500KB + 2亿 / 10 * 2MB = 60TB/天)
对于刷微博的访问并发量,做如下估算
- QPS
假设2亿日活用户每天浏览两次微博,每次向上滑动或者进入某个人的主页10次,每次显示20条微博,每天刷新微博次数40亿次,即40亿次微博查询接口调用,平均QPS大约5万(40亿 / 24 / 3600 = 46296/秒)高峰期QPS按平均值2倍计算,所以系统需要满足10万QPS
- 网络带宽
10万QPS刷新请求,每次返回微博20条,那么每秒需访问200万条微博。按此前估计,每5条微博包含一张图片(假设每张图片500KB,每秒图片数量为200万/5=40万张),每10条微博包含一个视频(假设每个视频2MB,每秒视频数量为200万/10=20万张),需要的网络总带宽为4.8Tb/s
((200万 / 1 / 500KB + 200万 / 5 / 500KB + 200万 / 10 / 2MB) * 8 bit = 4.8Tb/s,此处1024用1000近似计算,需考虑微博文本 + 图片 + 视频)
④ 难点/要点分析
微博系统的整体核心功能业务逻辑比较简单,重点核心关注在并发量和数据量都比较大,因此系统架构的核心是解决高并发的问题,系统整体部署模型分析如下:
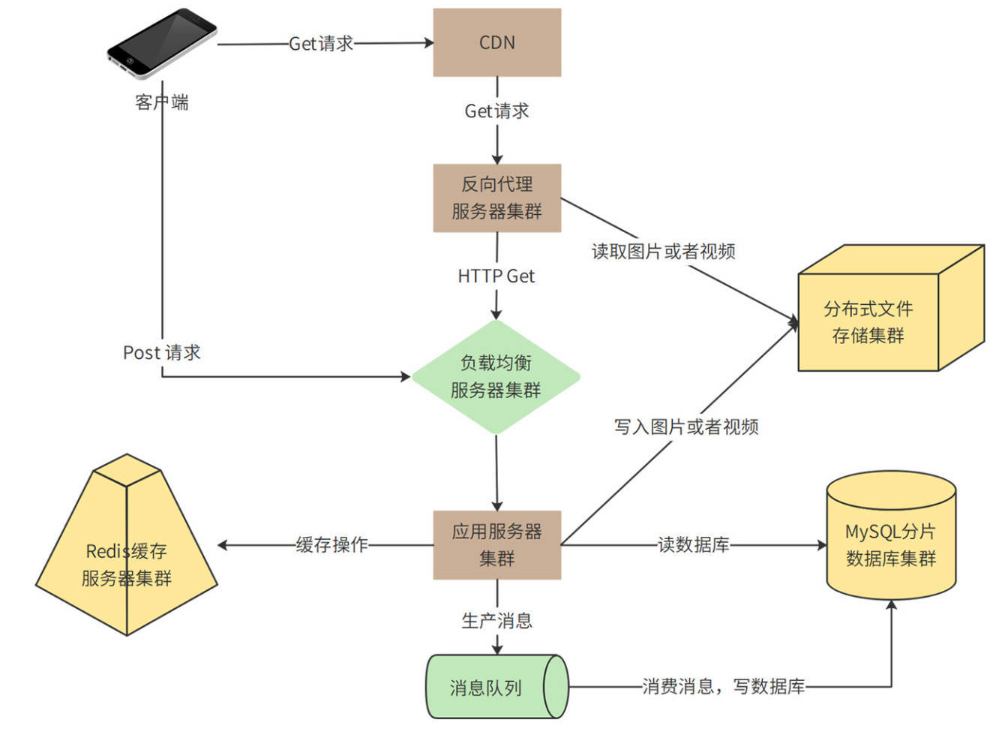
此处划分为“Get请求”和“Post请求”两条链路,Get请求主要处理刷微博的操作,Post请求主要处理发微博的请求,这两种请求处理也有重合的部分(结合下述拆分图示分析)
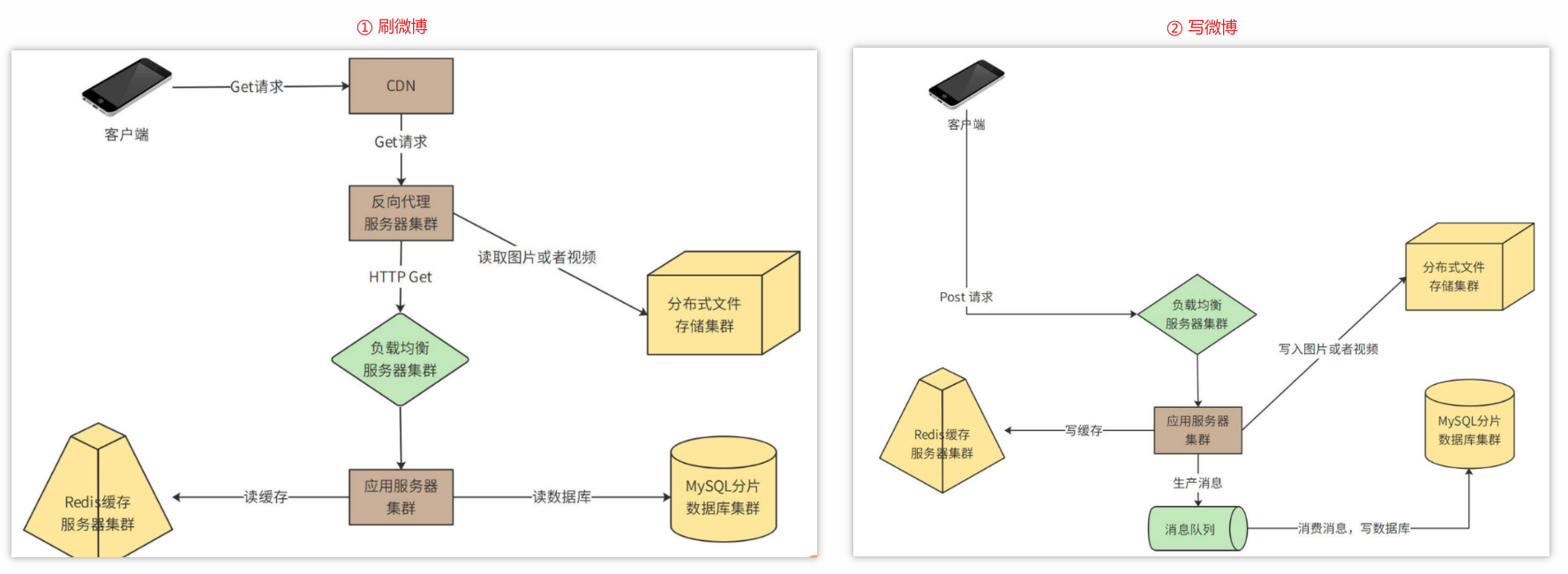
① Get 请求(刷微博)
用户通过CDN访问数据中心、图片以及视频等极耗带宽的请求,绝大部分可以被CDN缓存命中(也就是说,4.8Tb/s的带宽压力,90%以上可以通过CDN消化掉)。
没有被CDN命中的请求,一部分是图片和视频请求,其余主要是用户刷新微博请求、查看用户信息请求等,这些请求到达数据中心的反向代理服务器。反向代理服务器检查本地缓存是否有请求需要的内容。如果有,就直接返回;如果没有,对于图片和视频文件,会通过分布式文件存储集群获取相关内容并返回(分布式文件存储集群中的图片和视频是用户发表微博的时候上传上来的)
对于用户微博内容等请求,如果反向代理服务器没有缓存,就会通过负载均衡服务器到达应用服务器处理。应用服务器首先会从Redis缓存服务器中,检索当前用户关注的好友发表的最新微博,并构建一个结果页面返回。如果Redis中缓存的微博数据量不足,构造不出一个结果页面需要的20条微博,应用服务器会继续从MySQL分片数据库中查找数据。
② Post 请求(发微博)
客户端不需要通过CDN和反向代理,而是直接通过负载均衡服务器到达应用服务器。应用服务器一方面会将发表的微博写入Redis缓存集群,一方面写入分片数据库中。
在写入数据库的时候,如果直接写数据库,当有高并发的写请求突然到来,可能会导致数据库过载,进而引发系统崩溃。所以,数据库写操作,包括发表微博、关注好友、评论微博等,都写入到消息队列服务器,由消息队列的消费者程序从消息队列中按照一定的速度消费消息,并写入数据库中,保证数据库的负载压力不会突然增加
2.整体设计(架构设计)
① 服务设计(分层设计)
② 存储设计(存储选型)
③ 业务设计(业务流程)
3.要点分析
① 微博的发表/订阅问题
用户关注好友后,如何快速得到所有好友的最新发表的微博内容,即发表/订阅问题,是微博的核心业务问题。此处涉及有两种模式方向切入:推模式(发表微博时推送,存在写压力)、拉模式(用户主动拉取微博信息,存在读压力)
所谓“推模式”,即建一张用户订阅表,用户关注的好友发表微博后,立即在用户订阅中为该用户插入一条记录,记录用户id和好友发表的微博id。这样当用户刷新微博的时候,只需要从用户订阅表中按用户id查询所有订阅的微博,然后按时间顺序构建一个列表即可。也就是说,推模式是在用户发微博的时候推送给所有的关注者,如下图,用户发表了微博0,他的所有关注者的订阅表都插入微博0
所谓“拉模式”,即在用户刷微博的时候拉取他关注的所有好友的最新微博。用户刷新微博的时候,根据其关注的好友列表,查询每个好友近期发表的微博,然后将所有微博按照时间顺序排序后构建一个列表
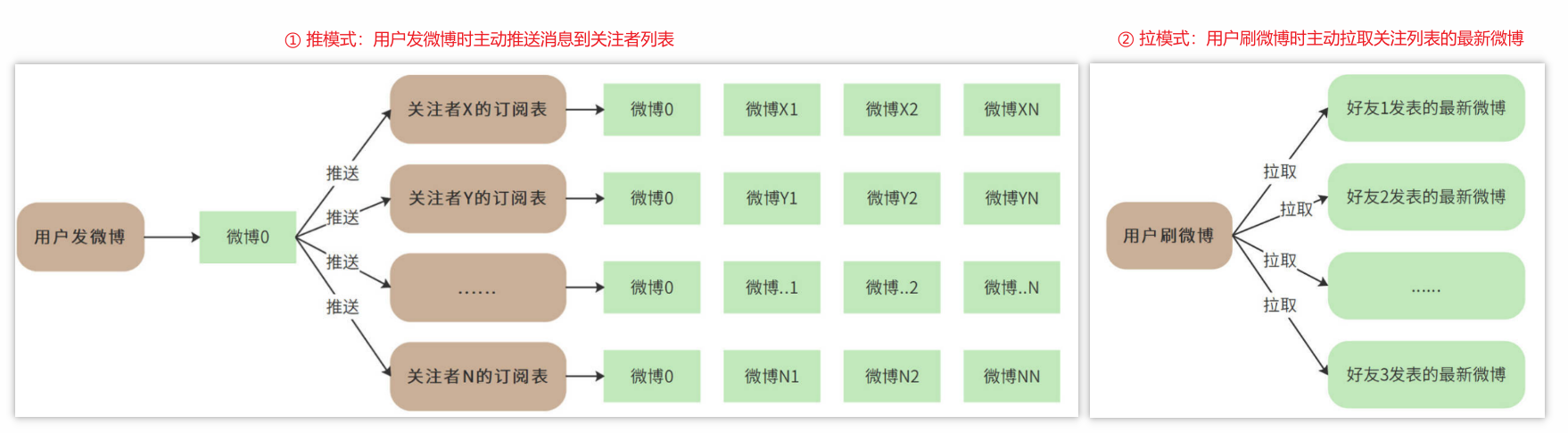
推 VS 拉?
推模式实现起来比较简单,但是推模式存在写压力。如果一个用户有大量的关注者,那么该用户每发表一条微博,就需要在订阅表中为每个关注者插入一条记录。而对于明星用户而言,可能会有几千万的关注者,明星用户发表一条微博,就会导致上千万次的数据库插入操作,直接导致系统崩溃。
所以,对于10亿级用户的微博系统而言,需考虑使用“拉模式”解决发表/订阅问题,即由用户主动拉取关注列表的最新微博数据。虽然拉模式可以极大降低了发表微博时写入数据的负载压力,但是却又急剧增加了刷微博时候读数据库的压力。因为对于用户关注的每个好友,都需要进行一次数据库查询。如果一个用户关注了大量好友,查询压力也是非常巨大的
针对拉模式的风险点,可以采用限制用户关注好友数、引入缓存缓解查询压力等方案来处理:
- 例如平台根据等级制度限定关注上限:普通用户关注上限是2000人,VIP用户关注上限是5000人
- 引入缓存缓解查询压力:尽量减少刷新时直接查询数据库的次数(即尽量通过缓存读取数据)
但实际上,即使采用上述方案缓解查询压力,但查询压力还是太大,因此可以考虑针对不同的业务场景用"推拉结合"的模式来搭配使用:
- 如果用户当前在线,那么就会使用推模式,系统会在缓存中为其创建一个好友最新发表微博列表,关注的好友如果有新发表微博,就立即将该微博插入列表的头部,当该用户刷新微博的时候,只需要将这个列表返回即可
- 如果用户当前不在线,那么系统就会将该列表删除。当用户登录刷新的时候,用拉模式为其重新构建列表。
基于上述分析,也引入了一个新的问题:如何确定一个用户是否在线?一方面可以通过用户操作时间间隔来判断,另一方面也可以通过机器学习,预测用户的上线时间,利用系统空闲时间,提前为其构建最新微博列表
② 缓存使用策略
通过前面的分析控制,微博系统设计是一个典型的高并发读操作的场景。对于10万QPS刷新请求,每个请求需要返回20条微博,如果全部到数据库中查询的话,数据库的QPS将达到200万,即使是使用分片的分布式数据库,这种压力也依然是无法承受的。所以,需要大量使用缓存以改善性能,提高吞吐能力。
但是缓存的空间是有限的,必定不能将所有数据都缓存起来。一般缓存使用的是LRU淘汰算法,即当缓存空间不足时,将最近最少使用的缓存数据删除,空出缓存空间存储新数据。
但是LRU算法并不适合微博的场景,因为在拉模式的情况下,当用户刷新微博的时候,需要确保其关注的好友最新发表的微博都能展示出来,如果其关注的某个好友较少有其他关注者(或者可以理解为该用户发表的微博还没来得及被访问),那么这个好友发表的微博就很可能会被LRU算法淘汰删除出缓存。对于这种情况,系统就不得不去数据库中进行查询。
而最关键的是,系统并不能知道哪些好友的数据通过读缓存就可以得到全部最新的微博,而哪些好友需要到数据库中查找。因此不得不全部到数据库中查找,这就失去了使用缓存的意义。
基于此,系统采用时间淘汰算法,也就是将最近一定天数内发布的微博全部缓存起来,用户刷新微博的时候,只需要在缓存中进行查找。如果查找到的微博数满足一次返回的条数(20条),就直接返回给用户;如果缓存中的微博数不足,就再到数据库中查找。
基于上述分析,拟定初步缓存方案为:缓存7天内发表的全部微博,需要的缓存空间约700G。缓存的key为用户ID,value为用户最近7天发表的微博ID列表。而微博ID和微博内容分别作为key和value也缓存起来
此外,对于特别热门的微博内容,比如某个明星的离婚微博,这种针对单个微博内容的高并发访问,由于访问压力都集中一个缓存key上,会给单台Redis服务器造成极大的负载压力。因此,微博还会启用本地缓存模式,即应用服务器在内存中缓存特别热门的微博内容,应用构建微博刷新页的时候,会优先检查微博ID对应的微博内容是否在本地缓存中。因此针对拥有100万以上关注者的大V用户,缓存其48小时内发表的全部微博以缓解缓数据存压力
③ 数据库分片策略
基于上述分析,如果微博系统每天新增2亿条微博,即平均每秒需写入2400条微博,高峰期每秒写入4600条微博,基于预估的写入压力,对于单机数据库而言是无法承受的。而且,每年新增700亿条微博记录,这也超出了单机数据库的存储能力。因此,应用数据库需要采用分片部署的分布式数据库。分片的规则可以采用 用户ID分片或者 微博 ID分片。
按用户ID(的hash值)分片,那么一个用户发表的全部微博都会保存到一台数据库服务器上
- 优点:支持按用户查找,当系统需要按用户查找其发表的微博的时候,只需要访问一台服务器就可以完成
- 缺点:存在热点问题,对于一个明星大V用户,其数据访问会成热点,进而导致这台服务器负载压力太大。同样地,如果某个用户频繁发表微博,也会导致这台服务器数据增长过快
按微博 ID(的hash值)分片
- 优点:可以避免上述按用户ID分片的热点聚集问题
- 缺点:不支持按用户查找,当查找一个用户的所有微博时,需要访问所有的分片数据库服务器才能得到所需的数据,对数据库服务器集群的整体压力太大
综合考虑,用户ID分片带来的热点问题,可以通过优化缓存来改善;而某个用户频繁发表微博的问题,可以通过设置每天发表微博数上限(每个用户每天最多发表50条微博)来解决。因此可以考虑按用户ID分片的策略
4.总结陈述
- 深刻总结
- 要点牵引
- 收尾请教
微博是信息流应用产品中的一种,这类应用都以滚动的方式呈现内容,而内容则被放置在一个挨一个、外观相似的版块中。微信朋友圈、抖音、知乎、今日头条等,都是这类应用。因此这些应用也都需要面对微博这样的发表/订阅问题:如何为海量高并发用户快速构建页面内容?
在实践中,信息流应用也大多采用文中提到的推拉结合模式,区别只是朋友圈像微博一样推拉好友发表的内容,而今日头条则推拉推荐算法计算出来的结果。同样地,这类应用为了加速响应时间,也大量使用CDN、反向代理、分布式缓存等缓存方案。所以,熟悉了上述微博系统基础架构,就相当于进一步理解了信息流产品的架构
🚀实战案例
功能/组件设计相关: