短链系统
短链系统
学习核心
如何设计一个【短链】系统?(系统的核心功能)
- 核心功能:生成短链、短链映射(根据短链返回长链)
沟通对齐
- ① 需求分析:用户请求短链,短链系统根据请求检索相应的长链并返回,随后用户再根据返回的长链访问到真实的网页地址
- ② 请求量分析:基于5k/s、5k/s-10w/s、10w/s+的不同请求量场景分析
- 此处需确认生成短链和短链映射这两个请求的QPS,然后选择合适的组件处理
- ③ 容量对齐:短链的容量决定了使用多长的字符串来存储短链(例如要生成多少条短链数据要多少位)
- 假设采用生成62进制的短链数据,那么5位则可以支撑大概9亿条短链数据,而6位则可以支撑大概568亿条短链数据的表示
- ④ 设计对齐:
- short_url 和 long_url 是否要一一对应?
- short_url 是否有有效期?
- 功能设计:提供哪些接口?(生成短链、还原短链)
- ⑤ 难点分析(要点分析)
- 短链和长链的映射算法
- 分布式ID的设计
整体设计
- ① 服务设计(分层设计)
- 接口设计(生成短链、还原短链/短链映射):接口方法、请求参数、响应数据等
- ② 存储设计(存储选型)
- SQL or NoSQL的选择
- SQL:构建
url_map存储短链和长链的映射关系(并对短链和长链字段构建索引,用于检索数据),一一对照 - NoSQL:
short_urltolong_url/long_urltoshort_url,通过字段快速定位映射关系
- SQL:构建
- SQL or NoSQL的选择
- ③ 业务设计(业务流程)
- 通过短链访问长链
- 通过长链访问短链(校验长链是否已经存在短链,避免重复创建)
- ① 服务设计(分层设计)
要点分析
- ① 存储结构:核心数据存储结构分析
- 存储选型:MySQL
- 数据结构设计优化方向:对
short_url和long_url构建索引,便于快速检索
- ② 映射算法选择:
- "短链"如何尽可能短?:选用
62进制进行存储,5位可存储9亿条短链数据,6位可存储百亿级(568亿)短链数据 - 三种不同算法的对比:使用哈希函数、使用随机生成+数据库去重、使用进制转化(十进制转为Base62)
- "短链"如何尽可能短?:选用
- ③ 优化短链服务的响应速度:
- 利用缓存提速
- 根据短链/长链快速定位到其映射内容
- 利用地理位置提速(CDN)
- 使用CDN帮助用户访问最近的服务器
- 优化服务器访问速度:
- 不同地区使用不同的Web服务器
- 通过DNS解析不同地区的用户到不同的服务器
- 利用缓存提速
- ① 存储结构:核心数据存储结构分析
总结陈述
学习资料
🟢【短链系统】场景核心
1.短链的工作原理
以访问一个网址为例:传统方式直接访问原始地址链接:https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D(对应MySQL实战45讲),其对应短链为:http://gk.link/a/10q2I
可以通过curl命令来验证:输入curl -i http://gk.link/a/10q2I指令,可以看到响应返回的是302 Moved Temporarily,返回了上述的原始地址
-- curl -i http://gk.link/a/10q2I
HTTP/1.1 302 Moved Temporarily
Date: Mon, 20 Jan 2025 02:07:07 GMT
Content-Type: text/html
Content-Length: 158
Connection: keep-alive
Location: https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D
Set-Cookie: gksskpitn=5021d8ee-b049-4352-8d55-d88f9eebe8ac; Path=/
Set-Cookie: GRID=284a0eb-7f1097e-18d002b-8dd05e8;Expires=Wed, 19-Feb-25 02:07:07 GMT;Max-Age=2592000;Path=/; domain=.gk.link
Set-Cookie: SERVERID=1fa1f330efedec1559b3abbcb6e30f50|1737338827|1737338827;Path=/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>openresty</center>
</body>
</html>
在浏览器中访问两个地址,会发现都会跟踪到同一个网页,结合图示理解这个过程
整体的核心流程为:浏览器先访问短链地址,然后短链服务返回一个重定向状态码 并带上长链(原始地址),浏览器再去访问长链,获取内容,响应解析到浏览器给用户展示
扩展问题:此处的重定向状态码可以用301吗?用301和302有什么区别呢?
301 状态码代表永久重定向,只要浏览器拿到长链之后就会对其缓存,下次再请求。短链就直接从缓存中拿对应的长链地址。这样的话,就没办法对短链进行相关分析了 而302状态码代表资源被临时重定向了,不会存在上面说的这种问题
比如现有一个活动链接,是将短链发送给了 10w 用户,如果系统想统计短链后续的点击情况,使用 301 状态码就不行(因为是从浏览器缓存中得到长链地址)
2.为什么要使用短链?
短链的唯一优势就是"短",如果要基于扩展来讲,主要体现在三点:简洁、易用、节约成本
- 更加简洁:例如一些微信文章的链接很长,通过换成短链的形式体现更加简洁
- 便于使用:
- ① 一些平台对内容长度有限制(例如早期的微博只能发140个字),基于短网址则可以输入更多的内容
- ② 将链接转为二维码的时候,短链接生成的二维码更容易识别
- ③ 一些平台无法识别特殊的长链参数,转化成短链可以简化这个问题
- 节约成本:
- 在一些发短信的业务场景中,短信是按照长度进行计费的,通过短网址可以节省成本
🚀【短链系统】场景实战
1.沟通对齐
① 需求分析
什么是【短链系统】?
将原始长链地址转化短链,然后访问短链的时候会返回短链关联的原始长链地址
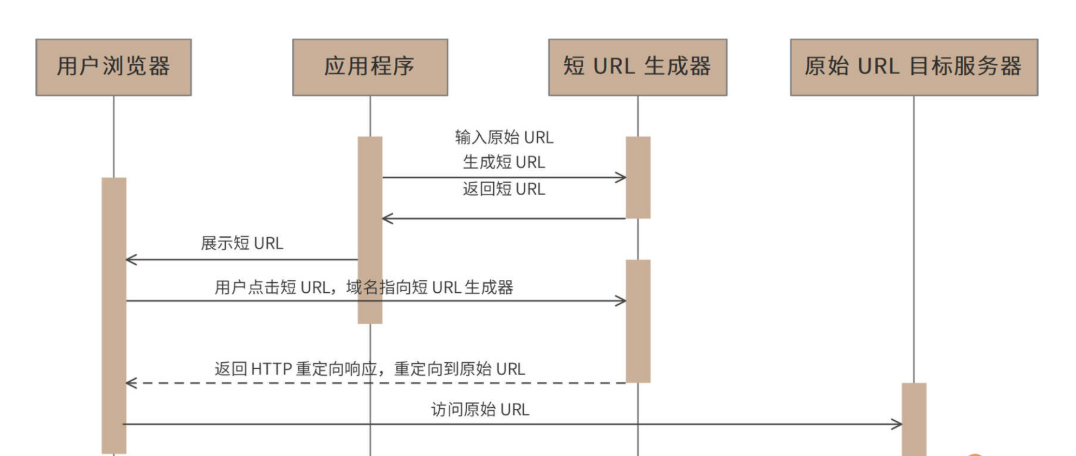
业务流程分析
整体的核心流程为:浏览器先访问短链地址,然后短链服务返回一个重定向状态码 并带上长链(原始地址),浏览器再去访问长链,获取内容,响应解析到浏览器给用户展示
② 请求量分析
- 根据不同的请求量分析选用合适的中间件和存储容器
- 请求量分析:产生短链的QPS、访问短链的QPS
- 例如访问短链的QPS只有2K,那么用一台SSD的MySQL可以支撑
- 如果是大于2K的话,考虑用MySQL集群+Redis加速的方案
- 请求量分析:产生短链的QPS、访问短链的QPS
③ 容量对齐
- 短链 的容量估计 直接决定了 使用多长的字符串来存储短链
- 系统容量评估:
流量评估:假设每个月新生的短链接是500M,读写比例100:1
- 短链生成请求QPS:500million / (30 × 24 × 3600) 约等于200 URLs/s(每秒有200个生成短链的请求打进来)
- 短链查询请求QPS:读写比例是100:1,因此其QPS为100 × 200 = 2w / s(每秒有2w个查询短链的请求打进来)
存储空间:
- 假设短链接会保存5年,那么总共需要保存的链接总数为 500million × 5年 × 12个月 = 30 billion,预估每行数据占据存储大小为500bytes,那么所需空间大小为30billion × 500 bytes = 15TB
网络带宽:
- 读:200 × 500bytes 约等于 100KB/s
- 写:2w × 500bytes 约等于10MB/s
内存:
- 如果选择将频繁访问的热点url缓存在内存中,根据28原则,则需要缓存20%的url,计算每日的请求量级别为:
- 读:2w/s × 24小时 × 3600秒 = 1,728,000,000 = 1.7 billion,缓存20%的url则需要存储空间为:0.2 × 1.7 billion × 500bytes 约等于 170GB
- 如果选择将频繁访问的热点url缓存在内存中,根据28原则,则需要缓存20%的url,计算每日的请求量级别为:
④ 设计对齐
- ① Long URL 和 Short URL 是不是需要一一对应?
- 一般情况下,Long URL 和 Short URL是一一对应的(因为不太可能在点开一个Short URL还要客户端确认是访问A网址还是B网址)
- ② 如果 Short URL 长时间没有被使用的话需要被释放吗?
- 例如一种场景:一个短链网址被收藏,多年后再次点击查看,如果不希望收藏的这个短链失效的话如何处理?
- 结合实际需求,有些情况下也会给短链设置过期时间
- ③ 功能设计:
- (1)根据一个Long URL 生成一个 Short URL
- (2)根据Short URL还原成Long URL,并进行跳转
2.整体设计
① 服务设计(分层设计)
短链系统设计是系统设计的一个比较常见的基础设计,它只需要一个服务即可(URLService),其本身就可以当做是一个小的Application
方法设计
| 函数名 | 方法作用 | 函数参数 | 函数返回值 |
|---|---|---|---|
| encode | 将长链编成短链 | long_url | short_url |
| decode | 通过短链获取原始长链 | short_url | long_url |
访问端口设计
| HTTP请求方法 | 路径 | 请求体数据 | 响应 |
|---|---|---|---|
| GET | short_url | null | 状态码:301/302,原始长链 |
| POST | shorten | long_url | short_url |
② 存储设计(存储选型)
(1)选择SQL
CREATE TABLE `url_map` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`long_url` varchar(160) DEFAULT NULL COMMENT '长链',
`short_url` varchar(10) DEFAULT NULL COMMENT '短链',
INDEX idx_long_url (long_url),
INDEX idx_short_url (short_url)
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
构建long_url和short_url的对照关系,分别对long_url和short_url建立索引(用short_url找long_url,用long_url来判断是否存在short_url)
(2)选择NoSQL
long_url to short_url (生成short_url的时候可以快速进行判断)
- 例如:longlink:
http://mysite.com/original_url=>abcdef123456
- 例如:longlink:
short_url to long_url(查询short_url的时候可以快速找到对应)
- 例如:shortlink:
abcdef123456=>http://mysite.com/original_url
- 例如:shortlink:
③ 业务设计(业务流程)
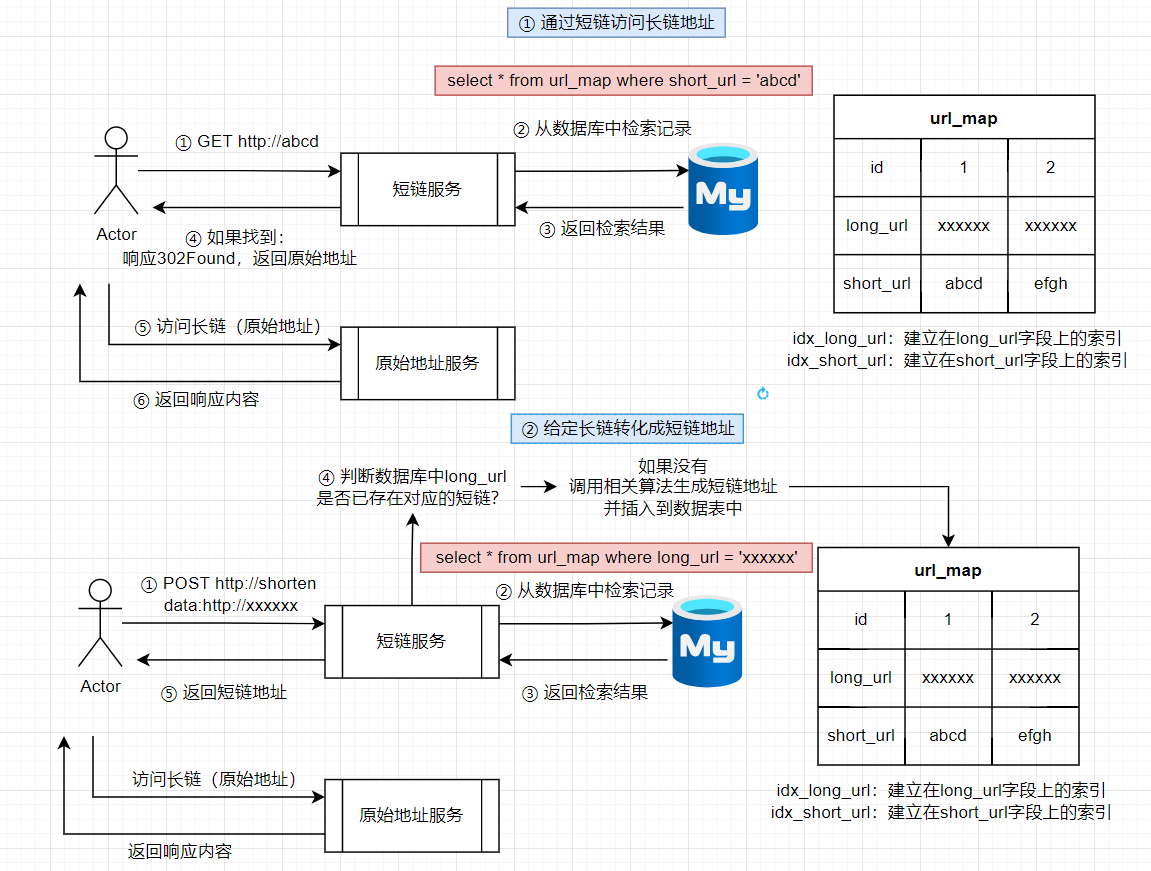
3.要点分析
① 数据库的设计?索引设计?
构建url_map表建立短链和长链的关系,并为短链和长链字段创建各自的索引,用于支持两个查询场景:
- ① 根据短链查找长链
- ② 根据长链查找短链
② HTTP响应状态的选择
绝大部分短链系统都选择使用302状态码处理,用于扩展短链系统的功能(例如统计通过短链服务访问长链的情况等)
③ 数据量(用多少位来存储?)
短链的核心是短,选择多少位存储很重要,对后续数据量的扩增速度判断也是一个核心判断依据
④ 选用什么算法来生成短链?
为了保证短链尽可能短,可以采用62进制(62进制:A-Z、a-z、0-9 刚好62位以构成62进制,1亿数据的短链,5位短链就能完全覆盖,62^5约等于9亿),下述可参考算法:
- ① 使用哈希函数
- 优点:快
- 缺点:存在哈希冲突问题,难以设计出一个没有哈希冲突的Hash算法
- ② 随机生成short_url + 数据库去重
- 优点:实现简单
- 缺点:每次生成新短链都要进行数据库校验,随着时间和数据量的递增(短网址的增多),生成短网址的速度会越来越慢
- ③ 进制转化为
Base62- 分析:将每个整数转化为对应的
Base62进制(对应到一条短链),例如5位的Base62可以表示9亿条短链,而6位的Base62可以表示568亿条短链 - 优点:效率高
- 缺点:依赖于全局的自增ID(分布式场景下需考虑全局共享的问题)
- 分析:将每个整数转化为对应的
针对短链接相同的情况,可以通过补充后缀的方式来解决:
- ① 可以考虑在url后增加一个自增的唯一序号来解决问题,但需要注意这个自增序号是否会溢出
- ② 可以考虑将用户ID(user_id)拼接在url的后面,但是如果用户没有登录的话则无法拿到user_id
⑤ 如何设计全局唯一的ID?
基于分布式场景思考,如果要设计全局唯一的ID可以从以下几个方面考虑:
- 雪花算法(Snake)
- Zookeeper
- Redis Incr
- UUID
- 数据库自增ID
⑥ 优化短链服务的响应速度?
- ① 缓存提速:利用缓存提速(Cache Aside)
- 缓存里面存储两类数据,基于前面的估算如果采用内存缓存(例如
memcache)存放每日全量流量的20%需要170GB,对于现有的服务器而言内存大小是足够的,需考虑还是的缓存淘汰策略(例如LRU)- long_url To short_url(生成short_url时候可以快速进行判断):
<key,value> => <long_url,short_url> - short_url To long_url(查询short_url时可以快速找到对应的long_url):
<key,value> => <short_url,long_url>
- long_url To short_url(生成short_url时候可以快速进行判断):
- 缓存里面存储两类数据,基于前面的估算如果采用内存缓存(例如
- ② 利用地理位置提速:例如使用CDN来帮助用户访问最近的服务器
- ③ 优化服务器访问速度:
- a.不同地区,使用不同的Web服务器
- b.通过DNS解析 不同地区的用户 到 不同的服务器
- ④ 预生成短链地址:采用预先生成足够数量的短链地址的方式(而不是请求的时候生成),以提高响应速度。同步思考可以切换到更适合海量数据存储的存储组件(例如hbase等)
- 例如通过KGS(独立的key生成服务)提前生成6位并存储于DB中,每当需要使用的时候直接从db中获取即可,需确保每个key只能被取用1次(标记已使用),需考虑并发问题
⑦ 水平拆分
短链服务不适合做垂直拆分(url_map表中字段较少,不适合再单独拆分多列),因此基于水平拆分的思路去做。那么此处的sharding_key的选择有两个方向:
- ① 用ID/short_url做sharding_key:如果做
long_urltoshort_url的查询,只能广播给N台数据库查询(创建的时候需要避免重复创建,需先做long_urltoshort_url的查询) - ② 用long_url做sharding_key:如果做
short_urltolong_url的查询,只能广播给N台数据库查询
⑧ 全局自增ID
如何在N台服务器中共享一个自增ID是一个难点,可以基于分布式全局ID的设计思路来处理
- 方案1:专门用一台数据库来做自增ID服务(该数据库不存储真实的数据,也不负责其他查询)。即部署一个独立的key生成服务(key generation service)
- 方案2:使用 zookeeper 生成
⑨ 数据库过期数据清除
如果设定了数据有效期概念,那么对于过期的数据需要进行清理,以此降低数据库的存储空间,降低成本,提升查询性能。需要保证清除工作不会影响到正常的短链接生成服务:
- 当用户请求到了一个过期的链接的时候,删除过期链接,并返回给用户错误码
- 单独设置一个过期数据清除服务,这个服务必须保证很轻量,可以在用户流量低峰期定时执行
- 若用户未设置过期时间,系统可以设置一个默认的过期时间,确保数据不会永久存在,导致DB无限增长
4.总结陈述
- 深刻总结
- 短链服务的难点是 长链接与短链接的映射存储 和 短链接的生成算法
- 要点牵引
- ① 对于短链接的生成算法,可以考虑使用基于哈希函数或随机字符串或进制转换生成的方法。关键是要保证生成的短链接具有足够的唯一性和随机性,以避免冲突和预测
- ② 确定好数据量,计算好用多少位存储短链,对整个系统至关重要
- ③ 在性能优化方面,可以使用缓存技术来提高短链接的生成和访问速度。将频繁访问的短链接缓存在内存中,可以减少数据库访问的次数,提升系统的响应性能
- ④ 另外,考虑到短链服务的可扩展性,可以采用分布式架构和负载均衡技术。将短链接服务分布在多个服务器上,并通过负载均衡器来分配请求流量,可以提高系统的并发处理能力和可用性
- 收尾请教
- 以上就是我对短链服务的设计,有不成熟的地方还请指教