【评论系统】设计核心
【评论系统】设计核心
学习核心
如何设计一个【评论】系统?(系统的核心功能)
沟通对齐
- ① 需求分析
- 发布评论、读取评论、删除评论、管理评论,支持用户管理评论,为后台运营提供数据支持
- ② 请求量分析:
- ③ 精准度分析:
- ④ 难点分析
- ① 需求分析
整体设计
- ① 服务设计(分层设计)
comment-bff、comment-service(依赖服务:account-service、filter-service)、job(消息队列)、comment-admin(运营平台)
- ② 存储设计(存储选型):基于MySQL+Redis构建存储,借助ES辅助数据运营
- ③ 业务设计(业务流程)
- 从流量方向的角度出发,分析一个业务流程调度的流程:用户发表评论,可以对已发表的评论进行查看、删除操作,后台可查看评论数据进行运营分析
- ① 服务设计(分层设计)
要点分析(或难点分析)
① 存储结构:核心数据存储结构分析
- 存储选型:MySQL + Redis,设计了
comment_subject、comment_content、commnet_index三个表构建评论数据的层级关系 - 数据结构设计优化方向:缓存的选择(Memcache、Redis)、层级关系关键的方式选择(邻接表、分段式、Nested Set、Closure Table、Resursive Query)
- 存储选型:MySQL + Redis,设计了
② 高并发:缓存穿透问题、热点问题
- Singleflight(单飞):解决缓存穿透问题
- 热点问题:
- 读热点:自动分析热点key(利用滚动窗口统计某时段的key访问频率),对热点key进行hash分片,缓解读热点压力
- 写热点:引入MQ异步写库,缓解写时压力
③ 高精准:缓存的数据一致性问题,根据场景选择缓存模式(cache pattern)
旁路缓存:缓存的读写由应用本身控制,适用于灵活性要求较高的复杂业务
透读缓存:引入缓存层,当出现
cache miss时由缓存层主动查询DB然后回写缓存,需要快速访问并且能够容忍一定程度缓存一致性问题的应用场景(例如商品数据、用户会话等)透写缓存:引入缓存层,同时写入缓存和数据库(当进行写操作时,写入缓存并将数据写入数据库),适用于数据一致性要求较高的场景(例如金融行业相关场景)
预加载缓存:通过主动预测未来可能会被访问的数据,提前从主存储载入缓存中,从而减少未来请求时的缓存未命中率(Cache Miss)
总结陈述
- 深刻总结
- 从评论系统的核心功能点切入(发布、读取、删除、管理评论信息),构建评论的核心业务流程和整体的服务架构
- 要点牵引
- ① 架构设计:
comment-bff、comment-service(依赖服务:account-service、filter-service)、job(消息队列)、comment-admin(运营平台) - ② 存储设计:主存储选用 MySQL + Redis 缓存组合,基于ES辅助构建数据分析
- ③ 要点设计:
singlefilght:解决缓存穿透问题热点问题:采用自适应发现热点的思路(例如在内存中通过滑动窗口统计单位时间的数据访问量,自动进行热点识别)- 读热点:根据热点 key 进行一致性hash 分片,或者根据热点分析引入临时的二级缓存缓解读取压力
- 写热点:MQ 削峰
- 数据库层级结构设计:对多层级结构的数据设计,可采用多种思路(邻接表、分段式Path、Nested Set、Closure table、Resursive Query ),例如此处通过闭包表设计,基于索引数据分离思路,构建评论主题和评论数据的多级关联
- 缓存模式:不同场景下缓存模式的选择(旁路缓存、读透缓存、写透缓存、预刷新缓存)
- ① 架构设计:
- 收尾请教
- 深刻总结
学习资料
🟢【评论系统】场景核心
架构设计最重要的就是理解整个产品体系在系统中的定位。搞清楚系统背后的背景,才能做出最佳的设计和抽象。不要做需求的翻译机,先理解业务背后的本质,事情的初衷。
评论系统,往小里做,就是视频评论系统,往大做就是评论平台,可以接入各种业务形态。
评论的主要功能:
- 发布评论:支持回复楼层、楼中楼(一般会做两层效果较好,但是设计上可以支持无限嵌套)
- 读取评论:按照时间、热度排序
- 删除评论:用户删除、作者删除
- 管理评论:作者置顶、后台运营管理(搜索、删除、审核等)
概念补充
BFF:BFF一般指的是在前端与后端之间加增加一个中间层- BFF,即Backend For Frontend(服务于前端的后端),也就是服务器设计API 时会考虑前端的使用,并在服务端直接进行业务逻辑的处理,又称为用户体验适配器
🚀【评论系统】场景实战
1.沟通对齐
此处的沟通对齐方向,主核心方向是需求分析、请求量分析、精准度分析、难点/要点分析,可能还有涉及到其他的一些容量、设计等方面的对齐
① 需求分析
【评论系统】的核心功能
- 发布评论:支持回复楼层、楼中楼(一般会做两层效果较好,但是设计上可以支持无限嵌套)
- 读取评论:按照时间、热度排序
- 删除评论:用户删除、作者删除
- 管理评论:作者置顶、后台运营管理(搜索、删除、审核等)
业务流程分析
基于微服务框架构建,将大体的模块设计出来,处理好流量方向,构建业务流程
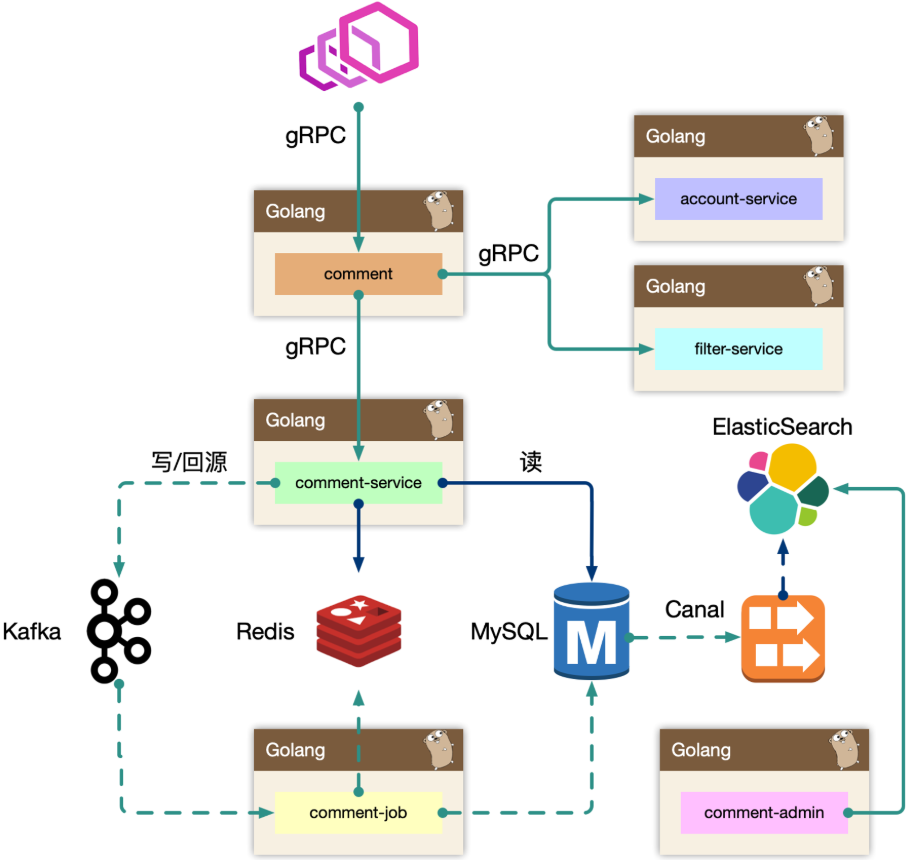
流量方向:BFF端 =》service 层 =》DB层,其中引入RPC框架(gRPC或dubbo)来进行微服务调用,基于MySQL + Redis 作为底层存储组件,借助ElasticSearch第三方组件辅助数据存储和分析(辅助运营体系的构建,支撑数据大量检索),业务流程构建图示分析如下(业务整体架构)
架构设计等同于数据设计,梳理清楚数据的走向和逻辑。尽量避免环形依赖、数据双向请求等
② 请求量分析
③ 精准度分析
④ 难点/要点分析
2.整体设计(架构设计)
① 服务设计(分层设计)
基于上述架构图示分析,理解各个架构层的核心概念
(1)分层设计
bff:业务逻辑平台层(负责评论业务的服务编排)关注业务逻辑servive:核心评论业务API层 关注数据读写(comment-service负责评论服务的去平台业务逻辑处理,专注于API实现。此外,还关联依赖其他服务调用,例如account-service、filter-service)job:消息队列(用于削峰处理,当写入请求非常大的时候,通过异步消息队列处理写请求)admin:comment-admin提供后台管理平台
🍚 BFF:comment-bff(comment,平台业务层)
复杂评论业务的服务编排,这一层专注于处理平台业务逻辑,比如访问账号服务进行等级判定(糅杂一些业务规则,例如 account-service,filter-service),同时需要在 BFF 面向 移动端 / WEB 场景来设计 API,这一层抽象把评论的本身的内容列表处理(加载、分页、排序等)进行了隔离,关注在业务平台化逻辑上
🍚 service:comment-service(服务层)
服务层,去平台业务的逻辑,专注在评论功能的 API 实现上。比如发布、读取、删除等,关注在稳定性、可用性上,这样让上游可以灵活组织逻辑,把基础能力和业务能力剥离。这一层专注于处理数据本身
dependency(依赖服务):account-service、filter-service,整个评论服务还会依赖一些外部grpc服务,统一的平台业务逻辑在 comment BFF 层收敛,例如此处 account-service 主要是账号服务,filter-service 是过滤服务
🍚 job:comment-job(消息队列)
消息队列的最大用途是削峰处理。当写入请求非常大的时候,通过异步消息队列处理写请求
🍚 admin:comment-admin(管理平台(后台))
管理平台,按照安全等级划分服务,尤其划分运营平台,他们会共享服务层的存储层(MySQL、Redis)。运营体系的数据大量都是检索,使用 Canal 进行同步到 ES 中,整个业务的展示都是通过 ES,再通过业务主键更新业务数据层,这样运营端的查询压力就下放给了独立的 fulltext search 系统(运营后台搜索、统计等,这种业务不适合使用 OLTP,使用 ES更加适合)
(2)服务说明
🍚 comment-service
评论服务,专注在评论数据处理。(将 DDD 思想分隔开,作为独立的服务(Separation of Concerns))
如果将 comment-service 和 comment 是一层,业务耦合和功能耦合在一起,非常不利于迭代。虽然在设计层面可以考虑目录结构进行拆分,但是从架构层次来说迭代隔离是更好的。将两个服务拆分开,注重不同的核心点,BFF 关注业务逻辑,comment-service 关注数据读写处理
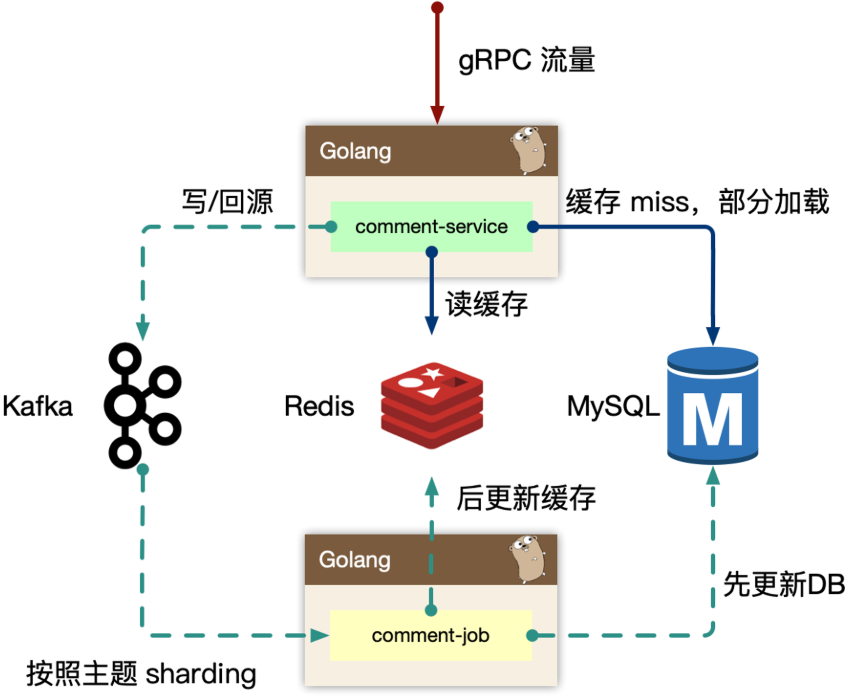
读的核心逻辑:
Cache-Aside模式(先读取缓存,再读取存储)
早期 cache rebuild 是做到服务里的,对于重建逻辑,一般会使用 read ahead 的思路。即预读,用户访问了第一页,很有可能访问第二页,所以缓存会超前加载,避免频繁 cache miss
当缓存抖动,特别容易引起集群 thundering herd 现象(线程惊群效应),大量的请求会触发 cache rebuild,大量往 MySQL 获取数据,并且回填到 Redis 中。因为使用了预加载,容易导致服务 OOM。所以再到回源的逻辑里,改为使用消息队列来进行逻辑异步化,对于当前请求只返回 MySQL 中部分数据即止,然后发送异步消息,处理 cache miss 的数据和预读的数据到 Redis
写的核心逻辑
如果发生类似 “明星出轨” 等热点事件的发生,而且写和读相比较,写可以认为是透穿到存储层的,系统的瓶颈往往就来自于存储层或者有状态层。
对于写的设计上,一定程度上可以认为刚发布的评论有极短的延迟(通常小于几 ms),对用户可见是可接受的,把对存储的直接冲击下放到消息队列,按照消息反压的思路,即如果存储 latency 升高,消费能力就下降,自然消息容易堆积,系统始终以最大化方式消费
Kafka 存在 partition 概念,可以认为是物理上的一个小队列,一个 topic 是由一组 partition 组成的,所以 Kafka 的吞吐模型理解为:全局并行,局部串行的生产消费方式。对于入队的消息,可以按照 hash(comment_subject) % N(partitions) 的方式进行分发,那么某个 partition 中的评论主题的数据一定都在一起,这样方便串行消费
同样的,处理回源消息也是类似的思路
🍚 comment-admin
分析运营平台(管理平台)的读写能力
MySQL binlog 中的数据被 canal 中间件流式消费,获取到业务的原始 CRUD 操作,需要回放录入到 ES 中,但是 ES 中的数据最终是面向运营体系提供服务能力,需要检索的数据维度比较多,在入 ES 前需要做一个异构的 joiner,把单表变宽预处理好 join 逻辑,然后倒入到 ES 中

一般来说,运营后台的检索条件都是组合的,使用 ES 的好处是避免依赖 MySQL 来做多条件组合检索,同时 MySQL 毕竟是 OLTP 面向线上联机事务处理的。通过冗余数据的方式,使用其他引擎来实现。
ES 一般会存储检索、展示、primary key 等数据,当操作编辑的时候,找到记录的 primary key,最后交由 comment-admin 进行运营侧的 CRUD 操作。内部运营体系,基于 ES 来完成更加有优势。
🍚 comment-bff(comment)
comment 作为 BFF,是面向端,面向平台、面向业务组合的服务。所以平台扩展的能力,都在 comment 服务来实现,方便统一和准入平台,以统一的接口形式提供平台化的能力

- 服务依赖:依赖其他
gRPC服务,整合统一平台侧的逻辑(比如发布评论用户等级限定) - 接口统一:直接向端上提供接口,提供数据的读写接口,甚至可以整合端上,提供统一的端上 SDK
- 服务降级:需要对非核心依赖的
gRPC服务进行降级,当这些服务不稳定时
② 存储设计(存储选型)
此处存储设计组件选用MySQL + Redis 的组合,借助ES辅助数据处理和分析
(1)MySQL 底层数据结构设计
基于数据库设计可以设计如下数据表:comment_subject(主题表:一个资源、视频或文稿等)、comment_content(评论内容表)、comment_index(索引表)
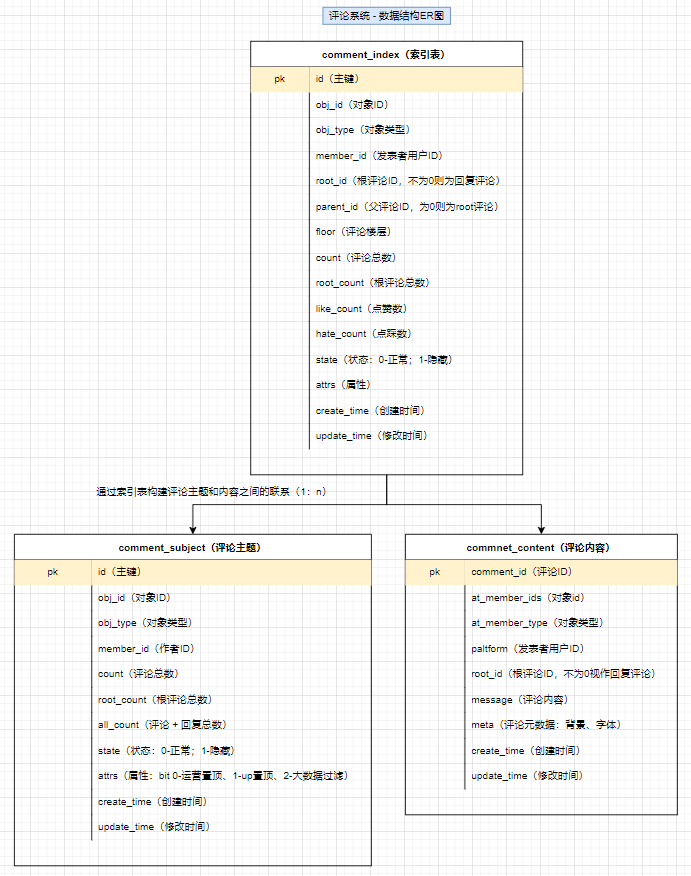
表数据结构设计
对于表设计都应该带有create_time和update_time属性,且设置主键,并设定顺序写入(避免出现页分裂的情况)
comment_subject(评论主题表):记录不同资源类型的评论主题(文章、视频、音源等)- 为了适配多种资源类型,通过
obj_id和obj_type匹配各种资源类型 member_id记录作者用户ID- 统计数(
count、root_count、all_count分别于用于记录评论总数、根评论总数、评论+回复数),便于展示统计数(不需要每次都用count *统计一遍) state记录资源状态attrs记录资源属性(可通过二进制代表多个属性)
- 为了适配多种资源类型,通过
comment_content(评论内容表):记录核心评论的内容,避免检索的时候内容过多导致效率低comment_index(索引表):记录评论的索引(可以理解为将主题和评论内容关联起来,构建层级关系)- 记录关联主题和评论内容
- 构建层级关系:通过
root、parent属性记录是否为根评论、子评论的上级(父节点),定义floor记录评论层级
此处采用索引内容分离的设计技巧,将用于检索的索引和评论的具体内容分离成两张表:
comment_index评论楼层的索引组织表(不包含内容);comment_content评论内容表(包括评论的具体内容)- 其中
comment_index与comment_content是一对一的关系:- 表都有主键(
cluster index),是物理组织形式存放的,comment_content没有id,是为了减少一次二级索引查找(回表),直接基于主键检索,同时comment_id在写入要尽可能的顺序自增。 - 索引、内容分离,方便
mysql datapage缓存更多的row,如果和content耦合,会导致更大的IO,长远来看content信息可以直接使用KV storage存储
- 表都有主键(
数据读写
数据写入:事务更新
comment_subject,comment_index,comment_content三张表content属于非强制需要一致性考虑的。可以先写入content,之后事务更新其他表。即便content先成功,后续失败仅仅存在一条ghost数据
数据读取:先根据评论主题定位索引,随后根据索引检索相应的评论内容列表
- ① 基于
obj_id+obj_type在comment_index表找到评论列表,WHERE root = 0 ORDER BY floor - ② 随后根据
comment_index的id字段获取出comment_content的评论内容。对于二级的子楼层,WHERE parent/root IN (id...)
- ① 基于
(2)缓存设计
comment_subject_cache(string):可以选用memcache或者Redis缓存KV值- key:
oid_type - value:主题缓存(value使用
protobuf序列化的方式存入) - expire:24h
- key:
comment_index_cache(sorted set):使用redis sortedset缓存索引(数据的组织顺序,而非数据内容),参考百度贴吧的设计,也可以基于拉链存储来组织索引- key:
oid_type_sort(其中sort为排序方式:0-楼层;1-回复数量) - member:
comment_id(评论ID) - score:楼层号、回复数量、排序得分
- expire:8h
- key:
使用 mysql 作为主力存储,利用 redis 来做加速完全足够,因为 cache miss 的构建,使用 kafka 的消费者作为中间处理,预加载少量数据,通过增量加载的方式主键预热填充缓存,而 redis sortedset skiplist 的实现,可以做到 O(logN) + O(M) 的时间复杂度,效率很高。过期时间可以通过内存大小调整。sorted set是要增量追加的,因此必须判定 key 存在,才能 zadd
comment_content_cache(string):- key:
comment_id - value:评论数据内容缓存(value使用
protobuf序列化的方式存入) - expire:24h
- key:
增量加载(将数据库中的数据批量放到 redis 中,而且先续约时间,然后再加缓存) + lazy 加载(所以没有分页,都是使用懒加载,使用 mget 批量获取)
如果选用分页方式,则可以使用预加载,获取第一页时,将第二页的数据加入到缓存中
③ 业务设计(业务流程)
以【添加评论】为例,分析整个请求的流转:
- ① 数据接收:用户通过客户端发送评论到服务端,随后服务端接收到评论消息之后响应客户端,并将其转发交由MQ异步处理
- ② 数据处理:消费者服务从MQ上拉取并消费消息,将评论数据插入到数据库,随后将添加成功的消息通知到客户端
- ③ 数据分析:通过canal将评论数据同步到ES上,运营人员可通过第三方组件分析和处理评论数据
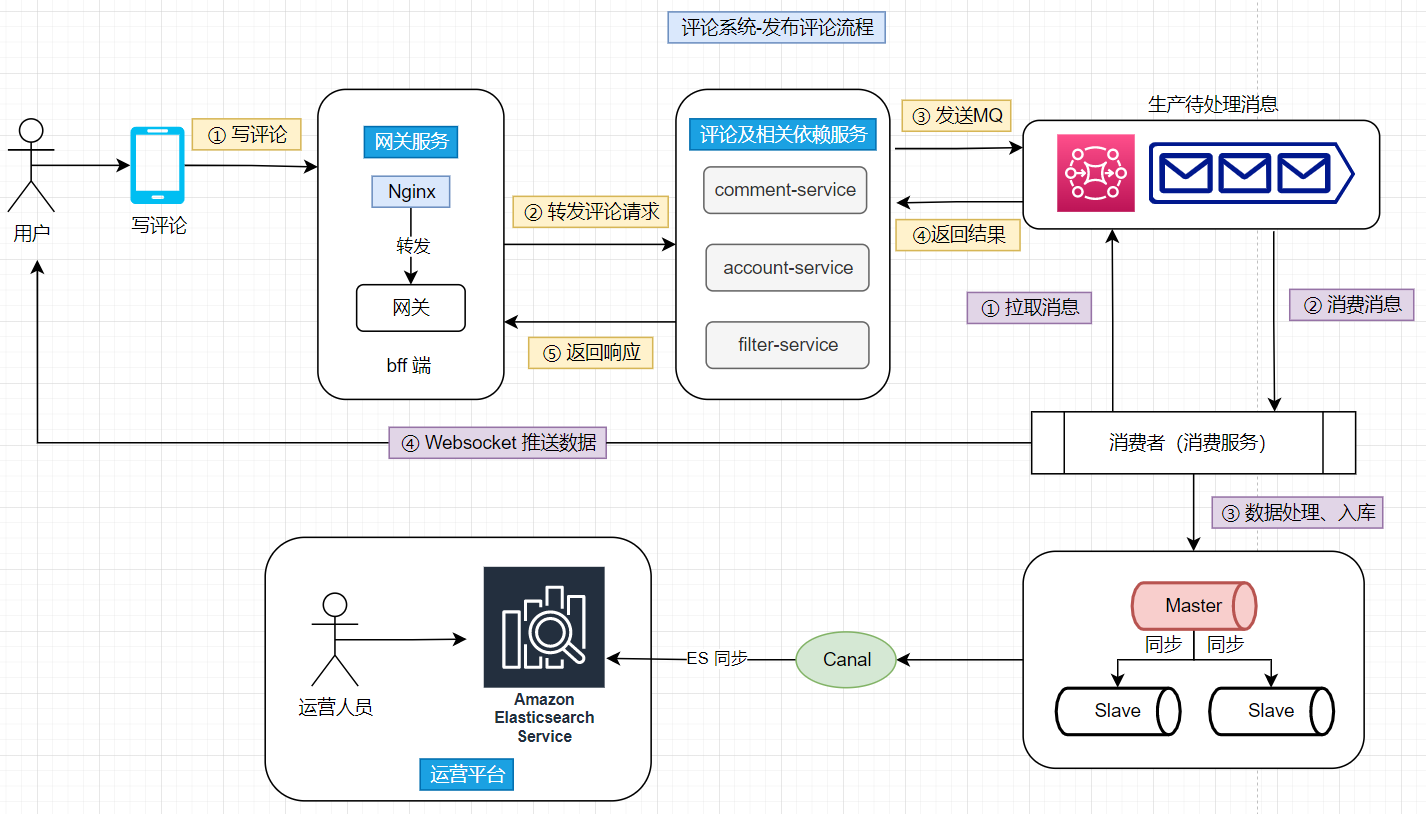
3.要点分析
① Singlefilght(解决缓存穿透问题)
SingleFlight(单飞)针对多个并发请求对一个失效的 key 进行获取源数据时,只让其他一个请求得到执行,其余均会阻塞等待执行的那个请求完毕后,将结果传递给阻塞的其他请求,达到防止击穿的效果
对于热门的主题,如果存在缓存穿透(缓存中没有数据,请求穿透了缓存,直接打到数据库)的情况,会导致大量的同进程、跨进程的数据回源到存储层,可能会引起存储过载的情况,如何只交给同进程内,一个人去做加载存储

同进程只交给一个人去获取 mysql 数据,然后批量返回。同时这个 lease owner 投递一个 kafka 消息,做 index cache 的 recovery 操作。这样可以大大减少 mysql 的压力,以及大量穿透导致的密集写 kafka 的问题。
更进一步的,后续连续的请求,仍然可能会短时 cache miss ,可以在进程内设置了一个 short-lived flag,标记最近有一个人投递了 cache rebuild 的消息,直接 drop
可以看到,这里说明的都是单进程下的解决思路。那么在多进程下,能否使用分布式锁来解决。理论上可以,但是实际操作起来,容易将这个简单问题复杂化,不推荐使用分布式锁。(PS:redis 作者不推荐使用 redis 实现分布式锁)多进程下,也是一样的思想,多个进程会发送多个消息到消息队列中,消费端获取消息的时候,通过单飞的思路,同样处理。
② 热点处理(读热点、写热点)
热点分为写热点和读热点。
写操作一般会通过 MQ 削峰,当大量的请求都集中在 MQ 中,不仅仅会影响当前服务,还可能导致下游服务出现异常。这种情况下,可以再进行解耦,增加上游服务的吞吐,将下游服务解耦,不依赖同一个同步逻辑。
流量热点是因为突然热门的主题,被高频次的访问,因为底层的 cache 设计,一般是按照主题 key 进行一致性 hash 来进行分片,但是热点 key 一定命中某一个节点,这时 remote cache 可能会变成瓶颈。因此做 cache 升级 local cache 是有必要的,一般使用单进程自适应发现热点的思路,附加一个短时的 ttl local cache,可以在进程内吞掉大量的读请求。
热点识别:在内存中使用 hashmap 统计每个 key 的访问频次,这里可以使用滑动窗口(左角标和右角标一起移动,统计区间内部的数据量)统计,即每个窗口中,维护一个 hashmap,之后统计所有未过去的 bucket,汇总所有 key 的数据。之后使用小堆计算 TopK 的数据,自动进行热点识别

③ 数据库层级结构设计
很多时候会碰到需要设计带有层级结构的数据,例如部门和成员、树级结构、评论、聊天等,一般会有要求检索某个节点下的子节点。这种情况下,可以有根节点、叶子节点、中间节点。针对这种层级结构的数据有多种方式维护:
(1)
邻接表 Adjacency List:通过 parent_id 记录层级关系缺点:
- 难以查询全部子节点
- 难以查询特定层的节点
- 难以查询聚合函数
(2)
分段式 Path:通过/a/b/c的形式(或者使用#分隔符_)缺点:
- 查找主要依赖于
LIKE查询 - 无法保证 PATH 正确
- Path 依赖于应用的字符串处理
- 查找主要依赖于
(3)
Nested Set:记录左节点和右节点。nsleft 小于所有子节点的 nsleft,nlright 大于所有子节点的 nright,本质上是一个深度优先遍历的顺序缺点:
- 查找父亲非常困难:c 结点的父亲节 点是祖先节点里面,没有别的祖先节 点作为其子节点的节点
- 插入非常困难:需要重新计算节点的 nsleft 和 nsright
(4)Closure Table:用单独的表来存储节点之间的关系
(5)
Resursive Query:依赖于数据库特性
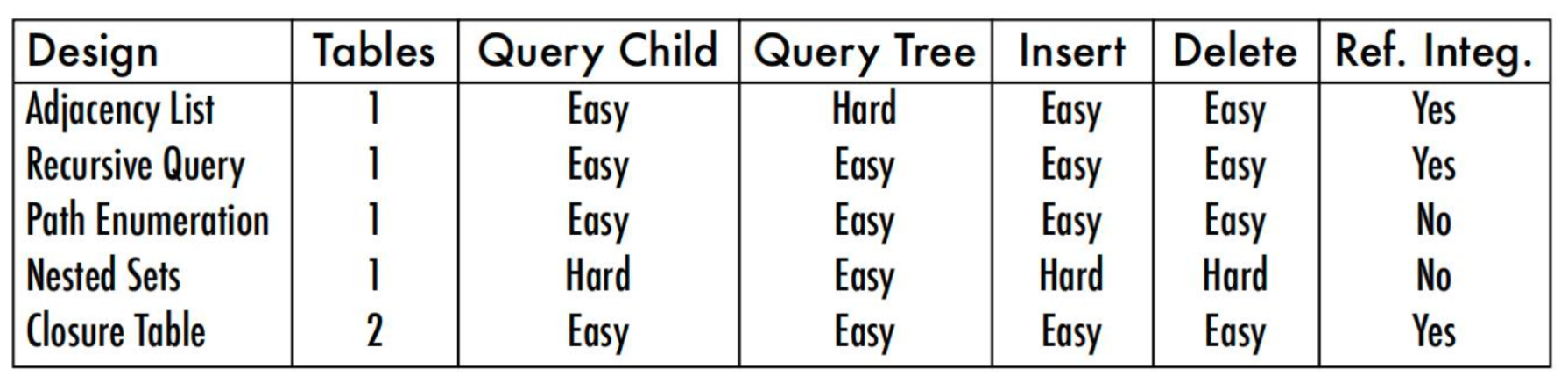
④ 缓存模式(cache pattern)
对于不同缓存模式的理解分析,从读、写两方面切入,理解cache miss谁刷新cache(即缓存更新的时机),更新DB的时候谁更新(DB的更新时机)
(1)cache aside(旁路缓存)
cache aside(旁路缓存):又称懒加载模式(lazy-load),把 cache 当成一个普通的数据源,更新 cache 和 DB 都是依赖于开发者自己写代码
读:cache miss 则读取数据库(需要注意穿透问题,需要使用
singlefilght),从数据库中加载数据并将其存储在缓存中写(更新操作):先写后删 =》先写数据库,后删除原本的 cache(这是数据不一致间隔最短的一种方式)
特点:
- 优点
- 灵活:开发者可以根据需求选择从缓存或数据库读取数据
- 减少数据库负载,提高访问速度
- 简单易于实现,开发者可以完全控制缓存管理
- 缺点
- 需要手动管理缓存,增加了开发和维护的复杂度
- 存在缓存一致性问题,需要小心处理缓存的清除和更新
- 适用场景:
- 读多写少:适用于读取频繁但更新较少的数据。例如,用户信息、商品详情、广告推荐等
- 优点
public class CacheAside {
private Map<String, String> cache = new HashMap<>();
private Map<String, String> database = new HashMap<>();
public String getFromCacheOrDatabase(String key) {
String data = cache.get(key);
if (data == null) {
data = database.get(key);
cache.put(key, data);
}
return data;
}
}
(2)read through(透读缓存/读取穿透)
read through模式下,缓存层自动管理数据的读取,当应用程序请求数据时,缓存层会先检查缓存,如果缓存命中则直接返回数据;如果缓存未命中,则缓存层自动从数据库加载数据,并将数据存入缓存
- 读:从 cache 中读取数据,cache 会在缓存不命中的时候读取数据
- 写:更新数据的时候也直接更新 DB,等待 Cache 过期;也可以更新 DB 之后同步更新 Cache
需要独立设计缓存层:
缓存层实现:需要一个独立的缓存系统(如 Redis、Memcached)。缓存系统需要能够在数据未命中时,自动从数据库加载数据,并缓存这些数据
缓存一致性:通常需要通过缓存管理器来控制数据过期、更新和一致性
特点:
- 优点:
- 简化了应用程序的逻辑,应用程序无需关心数据是从缓存还是数据库加载
- 减少了数据库的负担,提升了系统性能
- 缺点:
- 增加了对缓存层的依赖,缓存层需要具备高可用性和强大的扩展性
- 当缓存未命中时,可能会造成缓存层和数据库的负载增加
- 适用场景:
- 适用于需要快速访问并且能够容忍一定程度缓存一致性问题的应用场景,比如商品数据、用户会话等
- 优点:
public class ReadThrough {
private Map<String, String> cache = new HashMap<>();
private Map<String, String> database = new HashMap<>();
public String getFromCacheOrReadThroughDatabase(String key) {
String data = cache.get(key);
if (data == null) {
data = database.get(key);
cache.put(key, data);
}
return data;
}
}
cache aside(旁路缓存)与 read through(透读缓存/读取穿透)
两者的核心区别可以从方面切入:cache miss的时候谁刷新缓存、更新DB的时候谁主导更新
cache aside中的刷新缓存和DB更新都是由Application主导的read through中刷新缓存是由缓存层(缓存系统)推动的(缓存系统会自动更新缓存以保持数据一致性),DB更新则是由Application主导的
(3)write through(透写缓存)
write through模式下,数据在写入的时候同时更新缓存和数据库。即当应用程序写入数据时,数据首先写入缓存,然后立即写入数据库。这种模式保证了缓存中的数据始终与数据库中的数据一致
- 读:当
cache miss则从数据库中读取数据并更新cache - 写:写入时同时更新缓存和数据库,写入缓存后立刻写入数据库
独立设计缓存层:
缓存层实现:需要一个缓存层,在写数据时同步更新缓存和数据库。这样可以确保缓存中的数据与数据库中的数据保持一致
特点:
- 优点:
- 保证了缓存和数据库中的数据一致性
- 每次数据更新时,都会更新缓存,避免了缓存过期问题
- 缺点:
- 写操作会增加缓存层和数据库的负担,可能影响性能
- 相对于其他模式,写入操作的延迟较高
- 适用场景:
- 适用于数据一致性要求较高的场景,如库存管理、金融交易等
- 优点:
public class WriteThrough {
private Map<String, String> cache = new HashMap<>();
private Map<String, String> database = new HashMap<>();
public void writeToCacheAndDatabase(String key, String value) {
cache.put(key, value);
database.put(key, value);
}
}
(4)refresh-ahead(预刷新缓存)
Refresh-ahead 是一种缓存预取策略,旨在提高系统的响应速度,尤其是在可预测的访问场景下,与其他缓存策略的被动性不同,refresh-ahead通过主动预测未来可能会被访问的数据,提前从主存储载入缓存中,从而减少未来请求时的缓存未命中率(Cache Miss)
依赖于 CDC (changed data capture)接口:
数据库暴露数据变更接口
cache 或者第四方在监听到数据变更之后自动更新数据
特点:
- 优点:
- 缺点:
- 适用场景:
缓存策略是优化系统性能的重要工具,不同的缓存模式适用于不同的场景。理解这些模式的工作原理、优缺点和适用场景有助于在开发中选择最合适的缓存策略。
- Cache-Aside:由应用程序自己管理缓存,提供灵活性,适合复杂业务逻辑
- Read-Through:在缓存缺失时从主存取数据并更新缓存,适合读多写少场景
- Write-Through:实时在缓存和主存同步写数据,保证一致性但写入稍慢
- Write-Back:先写缓存,后续批量写入主存,提升写性能,但最终一致性难以保证
选择应根据性能需求和一致性要求平衡选择合适的缓存模式,能够在提高性能的同时,确保系统的稳定性和数据一致性
4.总结陈述
深刻总结
- 从评论系统的核心功能点切入(发布、读取、删除、管理评论信息),构建评论的核心业务流程和整体的服务架构
要点牵引
- ① 架构设计:
comment-bff、comment-service(依赖服务:account-service、filter-service)、job(消息队列)、comment-admin(运营平台) - ② 存储设计:主存储选用 MySQL + Redis 缓存组合,基于ES辅助构建数据分析
- ③ 要点设计:
singlefilght:解决缓存穿透问题热点问题:采用自适应发现热点的思路(例如在内存中通过滑动窗口统计单位时间的数据访问量,自动进行热点识别)- 读热点:根据热点 key 进行一致性hash 分片,或者根据热点分析引入临时的二级缓存缓解读取压力
- 写热点:MQ 削峰
数据库层级结构设计:对多层级结构的数据设计,可采用多种思路(邻接表、分段式Path、Nested Set、Closure table、Resursive Query ),例如此处通过闭包表设计,基于索引数据分离思路,构建评论主题和评论数据的多级关联
缓存模式:不同场景下缓存模式的选择(旁路缓存、读透缓存、写透缓存、预刷新缓存)
- ① 架构设计:
收尾请教