计数服务系统
计数服务系统
学习核心
- 如何设计一个高性能计数系统?
- 沟通对齐
- ① 需求分析:用于提供计数服务的系统(例如微博、B站的点赞、收藏、评论数量等)
- ② 请求量分析:基于5k/s、5k/s-10w/s、10w/s+的不同请求量场景分析
- ③ 精准度分析:针对数据统计的精准度,例如数据量较少的场景对数据多少比较敏感则要求数据统计准确,数据量较多的场景则可以接收几条数据丢失的情况
- ④ 难点分析:高并发、高精准的处理
- 整体设计
- ① 服务设计(分层设计):接入层(接口层)、业务服务层(可由业务服务调用计数服务,或者计数服务放在业务服务层)、存储层
- ② 存储设计(存储选型):MySQL + 缓存、Redis
- ③ 业务设计(业务流程):一个完整的计数操作业务流程,将服务和存储串联起来
- 要点分析
- ① 存储结构:核心数据存储结构分析
- 基于单行存储、多行存储的设计思路存储数据
- 单行存储:"分割概念",例如
cnt_xxx_xxx_xxx,每个xxx表示一个统计数,用分割符号分开每个统计数据,处理的时候需要拼接和解析操作 - 多行存储:"一对多概念",一条源数据对应多个统计维度,可根据不同业务类型调整统计目标,相对来说比较灵活
- 单行存储:"分割概念",例如
- 基于单行存储、多行存储的设计思路存储数据
- ② 异步化
- 内存聚合,异步写库:通过引入内存缓存的思路来实现批量操作,避免频繁访问数据库
- 引入异步组件:对于一些请求量比较大的场景,可引入异步化(例如引入MQ)的思路,提升系统整体的并发处理能力,达到削峰平谷的目的
- ③ 精准度
- 根据不同场景对数据统计敏感度的需求来选择,例如一些体量比较大的数据统计可能并不care极少数据的丢失,因此可以选用Redis来处理,充分利用其高性能的优势;而对于一些对数据统计敏感度要求较高的场景,则是可以选用MySQL来进行存储兜底
- .... 围绕功能核心要点展开叙述
- ① 存储结构:核心数据存储结构分析
- 总结陈述
学习资料
🟢【计数服务系统】场景核心
- 计数服务:指的是一个服务提供计数的能力,用于存储数字信息
🚀【计数服务系统】场景实战
1.沟通对齐
① 需求分析
什么是计数服务?
计数服务:指的是一个服务提供计数的能力,用于存储数字信息。常见的计数场景,例如一条微博的点赞数、一个B站视频的浏览量/点赞量等
结合B站站点视频的点赞、投币、收藏、浏览功能来看,例如【点赞数10.3万,投币数7.0万,收藏17.8万,浏览量290.1万】
一般来说,点赞数一般来说不会太爆炸,并且可以认为点赞分布是相对均匀的,不会说刚进来1w人,就直接点1w赞,后面就不点了,所以瞬间流量也不会太高的。浏览量(播放量)会大1个量级,并且只要进入就是浏览量,这样的话,如果是热门内容,可能瞬间流量也会比较高。当然,这只是单个视频分析,如果拉通平台来看,即使是点赞也可能会存在性能压力
业务流程分析
- ① 用户进入页面,看到某个微博或者文章等
- ② 产生兴趣,想给以支持
- ③ 点赞/收藏 表示支持
- ④ 前端展示效果一般会以动画效果反馈点赞成功,后台点赞计数+1
② 请求量分析
- 5000/s之内:如果是业务刚起步,请求量如果在5000/s以内,直接MySQL单机可以支撑
- 5000/s - 10w/s:如果5000/s以上(5k/s-10w/s),可能就要考虑MySQL分库分表或者上Redis
- 10w/s以上:如果10w/s以上,引入Redis集群方案
- 一般不会用MySOL堆机器的方式(成本太高),考虑引入Redis集群缓冲性能压力
在设计的时候,一定要确认清楚请求量,例如微博的这个业务,访问量就巨大,参考微博20年公布的数据:【微博20209月月活用户5.11亿】、【微博20209月日活用户2.24亿】
微博计数系统的访问量级峰值应该是能接近百万/s,并且从体验上来讲,响应也挺快,基本都是点了就出结果,一般就是1s以内了,甚至更低。后面重点考虑的,都是计数服务高并发场景,毕竟低并发直接MySQL就可以扛住,并没有过多亮点
③ 精准度分析
以点赞数为例,根据文章的热度不同的场景,对其点赞计数的精准度要求可能也会有所不同。举个例子,例如一个人气极高的明星随手发布的一个帖子可能随时能达到成千上万级别的点赞体量(例如微博上显示可能就会精确到类似2.3w这种表示),而对于一个常见微博来说能有上千的点赞已经是很不错的了。对于大的数据而言,可能少几个点赞数量对整体的影响并不大(数字显示反馈也不明显),但是对于一些小的数据而言,可能少了1个赞都是天塌了
而对于浏览量而言,其实多一点少一点影响也不大,用户本身也并不好去验证(参考微博热搜榜的浏览量统计)
根据不同的精准度场景,方案设计的区别也很大:
- 如果是精准度要求不高,可以采取内存计算、Redis当存储等方式,允许小概率少量数据丢失
- 如果精准度要求比较高,那么就需要采取更可靠的方式来兜底,比如MySOL
④ 难点分析
2.整体设计
① 服务设计(分层设计)
按照分层设计的思路,可以将架构拆分为3层:接入层、业务层、存储层
- (1)接入层:网关服务(负责接入)
- (2)业务层:计数服务
- 业务层可以有个独立的业务服务,也可以将计数服务当做业务层服务直接对外
- (3)存储层:存储 + 缓存
- MySQL + 缓存:如果是基于MySQL做存储的话,则考虑接入缓存缓解访问压力
- Redis:如果是基于Redis做存储的话,可以不需要考虑额外引入缓存,因为Redis本身的性能已经很高了
- 如果是大流量下的异步场景,可以接入消息队列(例如热点数据的请求量可能会很大,记录浏览数的场景则可考虑接入MQ)
② 存储设计(存储选型)
方案1:存储选用Redis
如果对数据的敏感度要求不高,选用Redis是一个经济实惠的方案。
基于Redis的K-V存储:key 存储信息名字(某个微博的点赞数:weiboID_good_num),value 就是相应的计数
方案2:存储选用MySQL+缓存
如果希望数据是比较可靠的,可以采用MySQL+缓存的方案。可以基于上述分析设计表
| 字段 | 类型 | 说明 |
|---|---|---|
| data_key | varchar(256) | 存储的信息名字(例如上述weiboID_good_num:表示某个微博的点赞数) |
| num | bigint(20) | 数字 |
借助Redis用作旁路缓存以缓解MySQL访问压力(对于Redis的架构可以做读写分离,一般情况下也可以读主写主)
③ 业务设计(业务流程)
消息队列
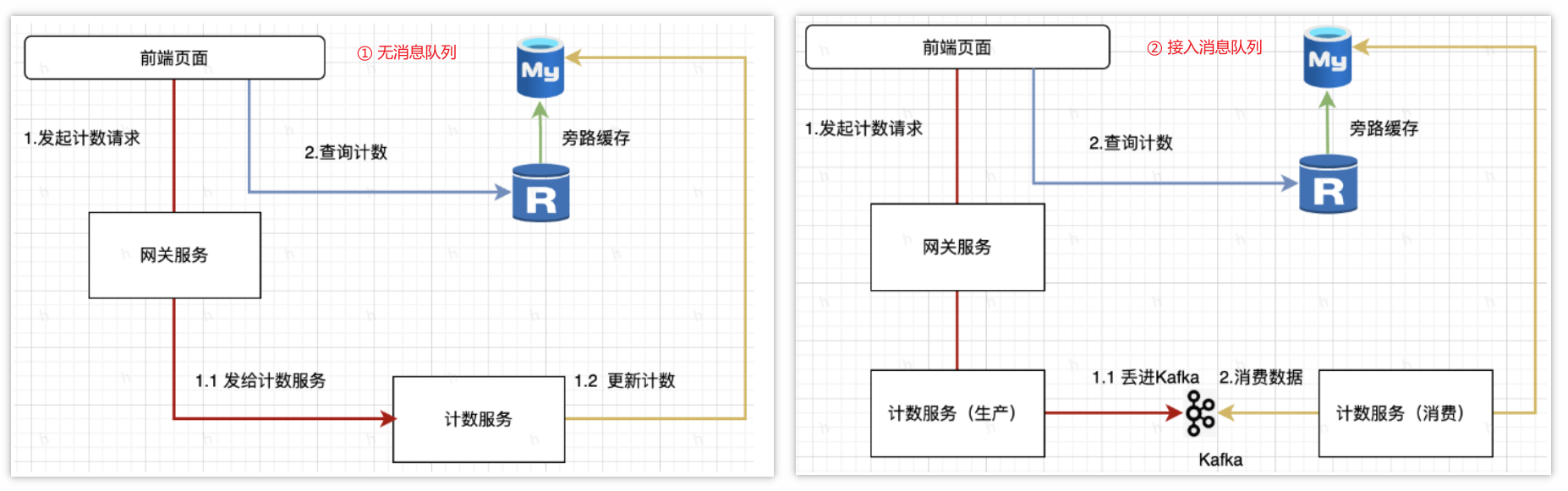
消息队列的引入取决于实际业务场景(看量够不够大),它可以用于提升整体的并发能力,异步处理任务,也可以在一些瞬时场景下削锋平谷缓冲瞬时访问压力,下图展示接入消息队列与否的方案:
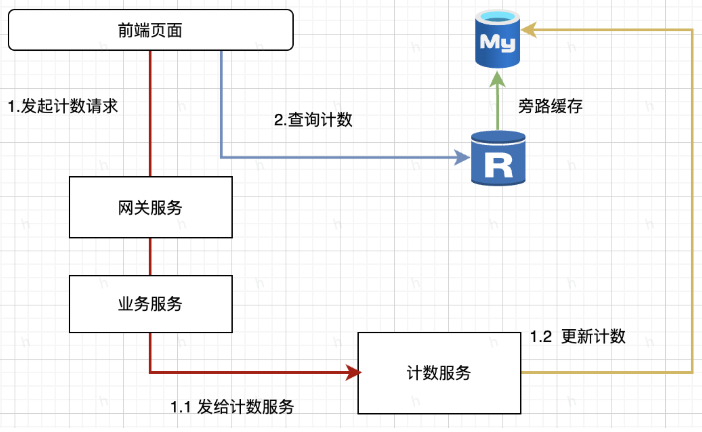
实际的业务场景中,计数服务可能是经由业务服务调用的(计数服务藏在业务服务后面),例如微博业务服务:从网关出来的请求,先请求到微博业务服务,然后再根据情况请求计数服务
至此,一个【计数服务】的整体架构雏形就出来了,后序则是基于这个版本就扩展细节
3.要点分析
① 存储结构
(1)MySQL VS Redis?(数据的精准度要求)
MySQL VS Redis 的选择取决于业务场景中的精准度要求,整体来说,Redis性能高一些、MySQL可靠性强一些,但也不局限于仅使用一种存储结构。例如点赞、收藏可以用MySQL计数,而浏览量通常用Redis比较合适
(2)单行还是多行?(数据的统计维度)
一个数据可能有多个维度的统计,例如一条微博,可以统计点赞数、评论数、收藏数、浏览数等,那么MySQL对应的数据库设计可以为:
| 字段 | 类型 | 说明 |
|---|---|---|
| stat_key | varchar(256) | 可以是微博ID、B站视频ID,结合实际业务情况区分 用于唯一关联绑定到原数据信息 |
| good_count | int(11) | 点赞数 |
| star_count | int(11) | 收藏数 |
| comment_count | int(11) | 评论数 |
| view_count | bigint(20) | 浏览量 |
对应Redis的K-V设计,有两种设计思路:单行、多行模式:
单行模式:
stat_key作为key,而value则是上述统计数据的组合数据- 例如点赞数100、收藏数200、评论数30、浏览量5000,那么可以得到:
stat_key:100_200_30_5000,可以通过下划线分割来获取所需数据 - 优点:数据集中,方便管理
- 缺点:数据互相耦合,处理的时候会互相干扰(例如点赞明明很少,都是浏览量,偶尔的点赞操作还会受浏览操作的干扰,举个例子,假设浏览请求积压了,点赞请求就会受影响,本来该互不干扰的)
- 例如点赞数100、收藏数200、评论数30、浏览量5000,那么可以得到:
多行模式:一行多个数据的模式设计,根据业务选择灵活制定不同的表和统计字段配置
- 例如只有评论数和点赞数的话,那么就可以去掉其他统计字段已节约空间,且相互之间不受影响。例如可以通过前缀嵌入的方式区分不同业务数据的统计字段:
xxx_comment_count、xxx_good_count这种形式(通过前缀后者后缀来关联业务数据,拆分多行存储统计数据) - 优点:在大流量场景下数据统计相互独立不干扰彼此,存储独立且清晰
- 例如只有评论数和点赞数的话,那么就可以去掉其他统计字段已节约空间,且相互之间不受影响。例如可以通过前缀嵌入的方式区分不同业务数据的统计字段:
② 异步化
高并发是计数服务最大的挑战,解决高并发的一个思路就是异步化。异步化有一个前提,就是要能接受最终一致性,新写入的数据会有一定延迟才能查到,不过大多数点赞、浏览量的场景都ok,有些业务还会做点小手段,比如点了之后,先前端给你+1,等刷新之后才用最新的。
此处可以有两种方案异步化:
- (1)内存聚合,异步写库
- (2)引入消息队列MQ
(1)内存聚合,异步写库(批量入库)
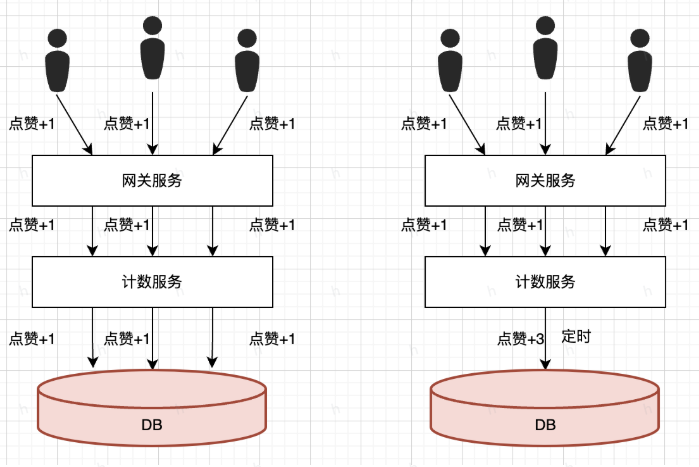
如图所示,左侧每条请求都直接写入DB,右侧则是在计数服务内存里,将多次聚合之后的结果一次写入DB,可以理解为批量入库的概念。
其流程分析说明:计数服务收到请求在内存中原子性增加,然后定时写入DB,比如1s一次,如果每秒1w个请求,计数服务有10个节点,那么1s对DB的压力只有10个。如果是单个写入的话,相当于每次写入都要访问数据库,DB的压力会非常大
众所周知,DB是不太好水平扩展的,比如MySOL做集群也会带来不少麻烦,但是业务服务是非常方便进行扩容的,内存操作本身也是非常快的,这里是个很典型的思路,以计算资源代替存储资源。但是这种方案有个缺点,就是数据丢失问题,比如某个计数服务节点宕机了,那么在内存中保存的数据就会丢失,如果能接受一定程度数据损失的场景,比如损失1s数据可以接受的话,用内存聚合挺好的,架构清晰好维护,对用户的响应也很快
(2)引入消息队列MQ
计数服务将请求先扔入消息队列,起一个消费者服务来固定频率消费,这样MySQL可以比较均匀的消费,不至于被打崩,也就是常说的削峰
当然,在消息队列模式下也可以聚合数据,消费时候存一批计数一起写入,成功就确认最后一条消息的位置,如果崩溃也可以重复消费数据,这种模式要考虑提供幂等性,比如一条消息有一个编号,记录到MySOL,消费过的消息不要重复消费
这种方案的优点在于不会丢失数据,缺点在于引入消息队列之后架构也变复杂了,同时消息队列也是额外的成本
③ 精准度
核心:精度度的考虑贯穿整个设计,如果有些场景不需要太精准(比如浏览量)就不多去叙述,主要针对需要考虑精准度的数据统计,着重分析
(1)少记(数据丢失)
如果一个用户发现自己有点赞记录,点赞数却少了,或者关注记录有,关注人数却没增加,这时候用户是非常在意的,所以少记是比较严重的问题。
少记容易出现在一些流程异常崩溃,却没补偿机制的场景,比如:没用消息队列,又用了聚合模式,数据先在内存里聚合,再批量刷入磁盘,此时,如果机器挂了就会丢数据,这种模式下,很容易出现少记,所以少记敏感场景要慎用
(2)多记(数据重复处理)
多记虽然用户不会觉得很受伤,但是其他用户会觉得不公平,如果被人发现,也是大问题。
多记的场景:
- 业务限制一个用户对同一个记录只能点1次赞,如果没做限制就会被疯狂刷赞:
- 对应解决办法可以通过"屏蔽入口+后端校验"来避免出现刷赞的行为,确保业务层一定是一个用户点赞记录的,便于后台可以做检测,同时前端也可以在用户点赞之后屏蔽掉点赞按钮
- 数据重复消费:
- 如果用了消息队列,丢数据倒不容易了,这时候要考虑重复消费问题,比如用消息队列,消费了,还没确认就崩溃,服务重启后又会去消费同一笔数据
- 所以最终兜底需要MySQL增加个记录,来避免重复消费(防止多记最兜底的方式)。记录格式类似下表:
| 字段 | 类型 | 说明 |
|---|---|---|
| count_record | varchar(256) | 与业务关联的唯一值 |
count_record 用于记录与业务关联的唯一值,例如在点赞场景中,如果一个用户001限定只能给一条记录B123点赞一次的话则可以记录值为B123_001,在更新MySQL点赞计数的时候插入一条计数记录,用事务保证操作的原子性
(3)缓存一致性
在【MySQL+缓存】的存储选型中,对应读请求(查询计数服务当前数值的请求),可以使用Redis来做一层缓存,为查询提速,也减少存储压力。
引入缓存,老生常谈的必然是缓存和存储始终会存在一定时间的不一致:
- 如果对于一致性要求稍高的服务,在更新存储之后也要去更新一次缓存,再依托一个过期时间兜底就行了
- 如果是一致性要求一般的场景,完全依赖过期时间就行,当然这个时间也别设置得太长
- 如果对于一致性极其苛求的场景,那就不能用缓存了,这时候为了性能存储会更偏向Redis一些(其实这种一致性极其苛求的场景,是比较少的,但也可以拿出来讨论)
4.总结陈述
- ① 说点深刻一点的结论
- 计数服务难点是高并发场景如何精准的计数
- ② 要点作为线索牵引
- 这个过程中最重要的,就是高并发、高可靠设计。高并发可以用异步化、聚合来解决,特别是聚合,效果非常好。高精准还得用MVSOL,通过崩溃重试、消息队列来避免少记,通过事务、唯一系引实现幂等性来避免多记
- ③ 收尾
- 以上就是本人对计数服务的设计,有不成熟的地方还请指教