排行榜系统设计
排行榜系统设计
学习核心
如何设计一个【排行榜】功能?(系统的核心功能)
- 此处核心针对排行榜的功能设计
沟通对齐
- ① 需求分析:排行榜功能设计(关注排行榜的场景和核心)
- ② 请求量分析:基于5k/s、5k/s-10w/s、10w/s+的不同请求量场景分析
- ③ 精准度分析:排行榜的实时性
- ④ 难点分析/要点分析:
- 排序结构和信息汇总结构设计:
- 信息汇总结构:Hash 存储
- 排序结构:基于不同的场景择选排序算法和排序结构存储,择选方向有List双向链表、Heap堆、Skiplist跳表
- 场景方案择选
- 海量数据排行榜(分支思想):按照排行榜访问分为多个zset
- TOP K用户排名(TOP K问题):用List双向链表或者Heap堆
- 常规的游戏排行榜:结合实时性需求来择选,例如top k刷新
- 排序结构和信息汇总结构设计:
整体设计(❌)
- ① 服务设计(分层设计)
- ② 存储设计(存储选型)
- ③ 业务设计(业务流程)
要点分析(或难点分析)(❌)
总结陈述
学习资料
🟢【排行榜】场景核心
1.游戏排行榜
以【王者荣耀】的游戏排行榜为例,根据排名发送奖励,以刺激用户让其更有动力提升自己在游戏的存在感
结合数据结构的CRUD,排行榜的主要功能有:
- 新上榜的用户(增)
- 用户作弊了得从排行榜上移除(删)
- 用户积分变更后,排名的更新(改)
- 查看前top K的情况/用户自己的排名(查)
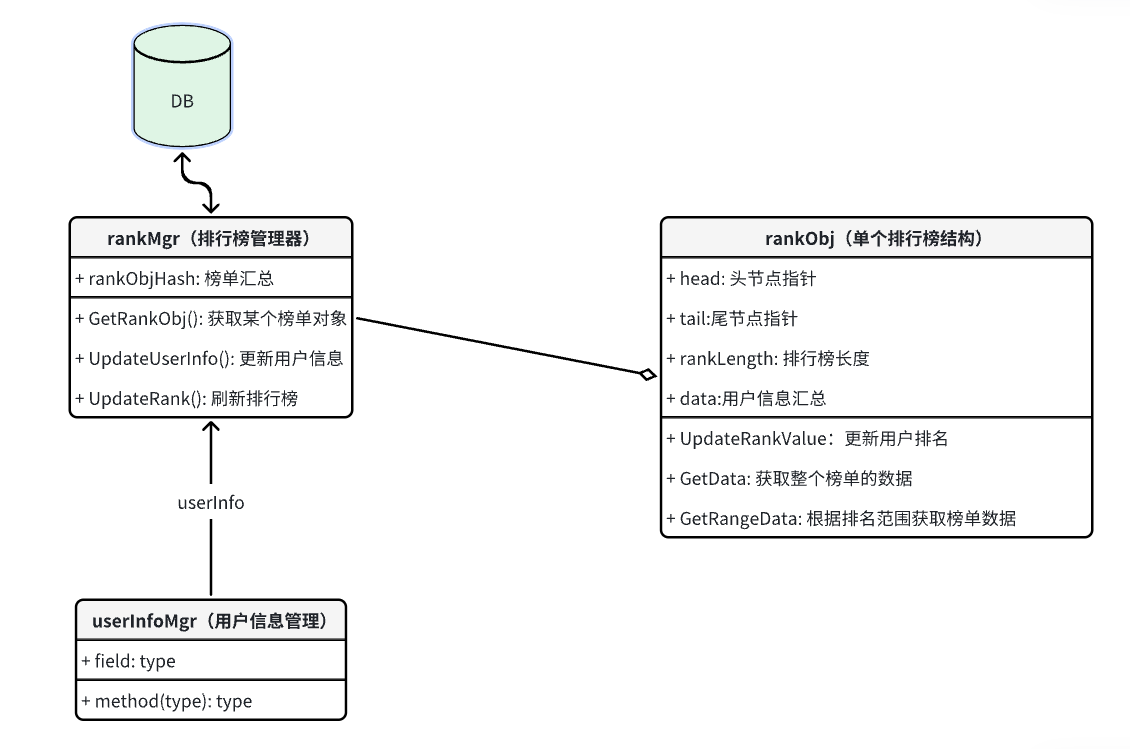
UML 图
用户信息关联榜单信息,对于排行榜管理器,其关联榜单汇总,可定位到每个排行榜的信息
🚀【排行榜】场景实战
PS:此处的设计阐述更倾向于功能设计,而不是提供服务的系统,具体核心介绍排行榜功能的实现,而对于其他的一些补充要参考实际系统应用的组合
1.沟通对齐
此处的沟通对齐方向,主核心方向是需求分析、请求量分析、精准度分析、难点/要点分析,可能还有涉及到其他的一些容量、设计等方面的对齐
① 需求分析
什么是排行榜?
排行榜可以理解为针对某一活动的积分排行,也可以是针对一些行为操作累积排行体现
- 最常见的就是游戏活动排行榜,针对每次不同的活动都有相应的排行榜单,以实施不同的奖励机制
- 再者就是对于一些行为操作的统计排行概念,例如公司内部知识库对不同部门的知识库的文档输入输出的操作排行、用户活跃度等一些统计维度的数据排行概念
业务流程分析
以上述游戏的排行榜设计实现分析,整体的流程就是用户参与了某个活动触发积分信息的变化,联动触发排行榜更新
② 请求量分析
③ 精准度分析
④ 难点/要点分析(实现方案)
🚀排序结构和信息汇总结构的设计
排行榜的组成有排序结构和信息汇总结构两部分(简单来说就是确定统计维度和排序规则)。当并发量很大的时候,可以考虑根据排序结构和信息汇总结构组合成完整的排行榜,然后使用缓存结构缓存起来,不需要每次请求都去把两者组装起来。而需要查自己的排名的时候,可以把刚刚排序好的名次,写回去信息汇总结构当中去。
对于信息汇总结构基本都采用Hash就好,用户ID作为key,用户的信息、分数等作为value,主要用于用户ID索引用户的其它信息,然后定时调度排序并把排序结构和信息汇总结构组装起来就可以形成排行榜了,而排序结构可考虑以下方案:
- 方案1:List 双向链表
- 方案2:Heap 堆
- 方案3:Skiplist 跳跃表
(1)List 双向链表
- 优点:实现节点,查找第n~m名的效率高
- 缺点:不支持随机读取,顺序遍历查找效率较低,容量不能太大(链表越长查找效率就越低)

(2)Heap 堆
- 优点:实现简单,基于数组实现的情况下课随机读取,内存使用率高
- 缺点:容量不能太大,堆排序不稳定(需要在排序的比较函数上做文章)

(3)Skiplist 跳跃表
- 优点:实现简单,查询效率基本上在O(log(N))
- 缺点:当达到亿级别的数据时,性能会急剧下降,因此需要避免bigKey问题

需额外注意的是,如果是基于Redis的zset,对于相同的score排序会按照key来进行排序,一般思路采用实际分数和时间戳相组合作为最终的分数存入(zset 的 score),类似UUID的雪花算法:

例如年月日时分秒xx(2x年)xx(月)xx(日)xx(时)xx(分)xx(秒),这里需要10个十进制位,如果还需要精确到亳秒,那么需要13个十进制位
- 一个int类型最大值是231-1(包含±),2,147,483,647,大约是10个十进制位
- 一个double类型最大值是263-1(包含±),9,223,372,036,854,775,807,大约是19个十进制位
- 而Zset的分数是 64位的有符号长整型,也就是约19个十进制位,所以去掉亳秒级别13个十进制位的时间戳,还剩6个十进制位,能存储999999个数据
分数 = 【分数段:6位】【时间戳段:13位】(毫秒版本) = [999999][1709017478803]
分数 = 【分数段:9位】【时间戳段:10位】(毫秒版本) = [999999999][1709017478]
基于这个设计,优先按照分数进行排序(分数越大越靠前),分数相等的情况下时间戳排名越小越靠前
🚀不同的情景选择择选合适的方案
(1)海量数据的排行榜(分治思想)
需求:需要全部的用户都能知道自己在排行榜的准确位置,且用户基数较大
方案:对于海量数据的排序处理的核心思想就是分而治之,按照分数拆分为多个段,每个段交由一个Zset来维护排序(如果量级大的话,就打散到不同机器上的Zset)
分数段【1-100】 Zset1 共x个用户
分数段【101-200】 Zset2 共y个用户
分数段【201-300】 Zset3 共z个用户
......
假设分数越小排名越高,那么榜单第1名就是Zset1的第一名,而对于Zset2的第一名就是整体的x+1名,以此类推可以得到用户的具体榜单定位
(2)只取TOP K用户(TOP K问题)
- 需求:只需要排出TOP K用户
- 方案:双向链表/堆
此处可以参考情景(1)的思路,假设当第n次刷新的时候,根据上次k名分数x作为临界门槛,只有超过该分数的人才能进入第k名,以此来减少排行榜的排序压力。而对于第1次刷新的时候,可以先根据数据分析给定的第k名预估的分数作为比较值x来进行参考,超过x才能进入排行榜参与排序
采用堆的思路,就是用一个堆去遍历整体的数据,当所有的数据遍历完成,排行榜也就出来了。针对TOP K问题,老生长谈的就是堆排序了,确认排序顺序,结合时间和空间优化选择合适的堆进行构建,优化排序效率:
- 例如求TOP K大,则有两种思路:
- 大顶堆:构建大顶堆,将所有元素入堆,然后依次弹出K个元素即为TOP K
- 小顶堆:维护K个元素的小顶堆,每次比较以此将最小的元素给置换出来,最终剩余在堆中的就是TOP K
(3)常规的游戏排行榜
top k 的用户实时排行榜,top k 后的30min刷新排行榜
也是参考场景(1),只不过各个Zset的刷新频率不同,而实际情况往往只需要top k
扩展问题:为什么不直接用Redis实现实时排行榜?
考虑数据量级和组件引入成本:杀鸡焉用牛刀,使用Redis会增加部署成本,要是量级不高,简单的快排都可以满足排序的需求,反之要是数据量级较大,而且追求相对实时,而且项目中已有Redis,建议采用Redis的Zset+Dict
2.整体设计(架构设计)
① 服务设计(分层设计)
② 存储设计(存储选型)
③ 业务设计(业务流程)
3.要点分析
① 为什么要用跳表来实现有序集合,而不是红黑树/b树等?
主要基于这三个方面:内存占用、n到m名查找的支持和实现难易程度这几方面总结的原因、还有并发性(不过并发性不是最重要的)
② 需要获取某个用户的排名如何获取?
排序结构更新的时候,把排名同步回去信息汇总中供用户查询
③ 当用户信息,例如名字发生改变,排行榜是如何实现更新的呢?
先同步到信息汇总中去,等待下一次排行榜刷新并且生成排行榜缓存的时候,再更新进去
④ 如何计算实时排名
要是基于Zset+Dict的实时排行榜的话,很容易实现,直接查询即可,不过要是查询一个Redis的频率太高,就打散到不同的节点/主从去请求,然后可以考虑在査询的用户身上记录一个排名还有排名的有效时间(例如5分钟),失效了再重新请求实时的数据,可要是不可使用实时排行榜呢,情景例如,参与PVP竞技类玩法,打完之后想立即知道积分改变后,排名变化多少?
可以整一个假数据给用户,根据上一次排行榜的分数和排名情况,结合新的分数预测排名(例如某一积分最后的排名),运算量不大可排名不一定准确。
4.总结陈述
- 深刻总结
- 要点牵引
- 收尾请教