【分布式ID】设计核心
【分布式ID】设计核心
学习核心
- 如何设计一个【分布式ID】?
- 分布式ID主流实现方案?各个方案的优缺性比较
- 基于本地程序运算:UUID、雪花算法(snowflake)
- 基于常用主键:MySQL自增主键 和 Redis 的
incr命令 - 基于分布式ID生成服务,类似美团的
leaf算法(leaf-segment、leaf-snowflake)
学习资料
- MySQL - 高可用篇 - 03 - 分布式ID
🟢【分布式ID】场景核心
什么是分布式ID?
在分布式系统中,需要对大量的数据和消息进行唯一标识,例如订单ID、分布式IM系统中的消息ID等。随着产品的使用,数据日渐增长,在一定规模场景需求下需要对数据进行拆分(即分库分表),并且需要通过一个唯一ID来标识一条数据或者消息。在这个场景下,因为不同数据库的自增ID会发生冲突,所以单纯使用数据库的自增ID显然无法满足需求,此时拥有个生成全局唯一ID的方案是非常必要的。
分布式ID的特性
- 全局唯一:确保主键全局唯一(基础)
- 单调递增:满足单调递增或者一段时间内递增,主要出于两方面的考虑
- 数据库写入性能:有序的主键可以保证写入性能
- 业务考虑:一些场景中会使用主键来进行一些业务处理,比如通过主键排序等。如果生成的主键是乱序的,就无法体现一段时间内的创建顺序
- 高可用:要求尽可能快地生成正确的ID,以支撑高可用
- 高性能:要求在高并发的环境表现良好
- 存储拆分后,业务写入强依赖主键生成服务,假设生成主键的服务不可用(例如出现单点故障问题),订单新增、商品创建等都会阻塞,这在实际项目中是绝对不可以接受的
在分布式系统中设计一个唯一 ID 生成器。 初步想法可能是在传统数据库中使用具有 auto_increment 属性的主键。 但是 auto_increment 在分布式环境中不起作用,因为 单个数据库服务器不够大,跨多个数据库以最小延迟生成唯一 ID 具有挑战性
🚀【分布式ID】场景实战
1.沟通对齐
此处的沟通对齐方向,主核心方向是需求分析、请求量分析、精准度分析、难点/要点分析,可能还有涉及到其他的一些容量、设计等方面的对齐
① 需求分析
什么是分布式ID?分布式ID的设计特点
分布式ID的一些特点确认:
- 分布式ID的唯一性:唯一,且可排序的
- 分布式ID的递增规则:例如每增加一条记录,ID就加1
- 分布式ID的位数(长度要求):64位
- 系统规模:例如系统每秒生成1w个ID
② 重点分析/要点分析
多种生成分布式ID的方案选择
- 多主复制(使用数据库的 auto_increment 特性)
- UUID(通用唯一标识符)
- Ticket 服务器
- 推特雪花算法等
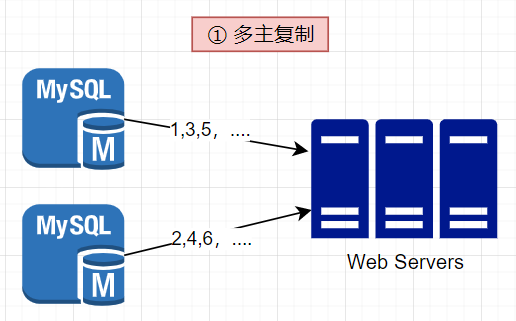
(1)多主复制(使用数据库的 auto_increment 特性)
a.MySQL
使用数据库的 auto_increment 特性,但不是将下一个ID增加1,而是增加指定步长(增加k),例如有 k 个数据库服务器,那么由这些服务器组成一个数据库集群,每个数据库的主键递增规则按照基础+步长来实施
- 优点:实施简单,充分利用数据库的 auto_increment 特性,解决了一些可扩展性问题
缺点:
难以通过多个数据中心进行扩展- ID在多个服务器上不随时间而增长
- 在增加或删除服务器时,不能很好地扩展
b.Redis
以Redis的incr命令为例,通过该命令实现ID的顺序递增,以生成分布式ID。通过多机部署的方式,设定不同的起始值和步长以确保不同的Redis生成的ID不重复。同理,当访问流量增加需要扩容的时候,得重新改变Redis机器的ID起始值和步长,此外对于Redis来说还需要考虑单点故障和数据持久化问题
RDB:快照持久化每隔一段时间保存数据库快照,从而进行持久化,假如Redis没有及时持久化一段时间内的自增数据,而这时Redis挂掉了,重启Redis后可能会出现ID重复的情况
AOF:增量持久化,执行命令后,会将命令也写入到AOF文件中,可以弥补RDB持久化实时性的不足,但仍然存在丢失数据的可能性
基于Redis实现分布式ID 特点
- 优点:
- 实现简单
- 整体吞吐量比数据库要高
- 缺点:
- 需考虑Redis的单点故障(发号服务不可用,导致阻塞业务服务)和数据持久化(可能导致数据丢失引发重复发号问题)问题
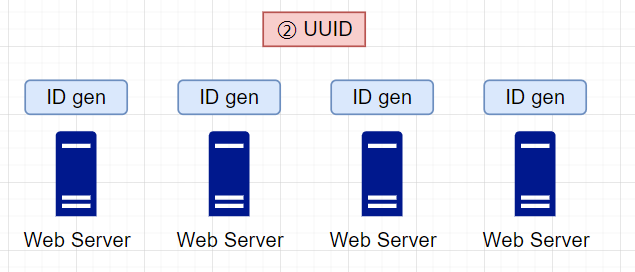
(2)UUID(通用唯一标识符)
UUID是 128 位数字,用于识别计算机系统中的信息。UUID获得串通的概率非常低。引自维基百科,"在每秒产生10亿个UUIDs,大约100年后,创造一个重复的概率会达到50%"。
例如09c93e62-50b4-468d-bf8a-c07e1040bfb2(8-4-4-4-12的36个字符,目前业界共有5种方式可以生成UUID),UUID 可以独立生成,无需服务器之间的协调。基于这个设计,每个Web服务器都包含一个ID生成器,由各自的Web服务器负责独立生成ID
- 优点:在不考虑低概率串通的情况下,UUID生成方式非常简单,不需要服务器的协调,由各个Web服务器独立部署、控制,ID生成器可以非常方便地与Web服务器一起扩展
- 缺点:
- 可读性差:生成的ID中包含了数字和字母,不一定能适配一些特殊的业务场景
- 存储成本高:UUID太长,16字节128位,通常用36长度的字符串表示
- 信息安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露
- 非单调递增:由于随机序列的生成不具备有序性,当将数据插入到数据库中容易产生页分裂问题
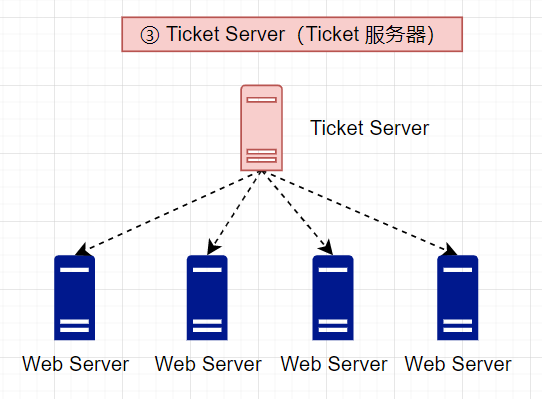
(3)Ticket 服务器
票据服务器是产生唯一ID的另一种有趣的方式。Flicker开发了票据服务器来生成分布式主键。可以理解为单独开辟一个服务专门用于服务分布式ID生成(集中管理分布式ID),在一个单一的数据库服务器(Ticket Server)中使用一个集中的自动增量功能
- 优点:生成数字ID,易于实施,适用于中小型应用程序
- 缺点:
- 存在单点故障问题,由于Web Server依赖于Ticket Server分配的主键,也就意味着一旦Ticket Server 出现故障,所有依赖它的服务都会受到阻塞
- 为了解决单点故障问题,可以设置多个Ticket Server,但同时也意味着面临着新的挑战(如数据同步)
(4)推特雪花算法
上述的分布式ID生成策略提供了分布式ID生成系统工作的一些思路,但也存在一些不足之处,为了寻找更适配的方式,Twitter 的ID生成系统snowflake则是一个新的启发,它采用一个分而治之的思想,不是直接生成一个ID,而是将ID分成不同的部分:
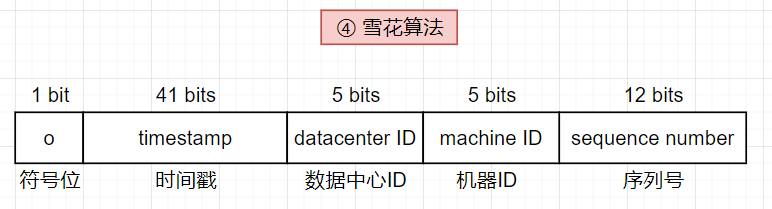
64 位 ID 布局说明:
- 符号位:1 位(始终为0),为将来使用保留,可潜在地用于区分有符号数和无符号数
- 时间戳:41 位(自纪元或自定义纪元以来的毫秒数),使用Twitter雪花默认给予纪元 1288834974657,相当于 2010 年 11 月 4 日 01:42:54 UTC
- 数据中心ID:5 位(可定义 25=32 个数据中心)
- 机器ID:5 位(每个数据中心有 25=32 台机器)
- 序列号:12 位,对于在该机器/进程上生成的每个ID,序列号都会递增1(该数字每毫秒重置为0)
特点
- 优点:
- 按照时间整体有序
- ID结构设计非常灵活,可以根据自身业务特性分配 bit 位
- 不依赖于第三方系统,以本地生成的方式进行,生成ID的性能非常高
- 缺点:
- 强依赖于机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态
- 所谓【时钟回拨】:指时间回拨到过去的某一个时间点(每一台计算机都有自己的本地时钟,这个时钟是根据 CPU 的晶振脉冲计算得来的,然而随着运行时间的推移,这个时间和世界时间的偏差会越来越大,就需要利用到NTP服务来进行时钟校准
NTP(Network Time Protocol)服务自动校准就可能导致时钟回拨)
- 所谓【时钟回拨】:指时间回拨到过去的某一个时间点(每一台计算机都有自己的本地时钟,这个时钟是根据 CPU 的晶振脉冲计算得来的,然而随着运行时间的推移,这个时间和世界时间的偏差会越来越大,就需要利用到NTP服务来进行时钟校准
- 强依赖于机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态
- 优点:
(5)Leaf
Leaf是美团技术团队开源的一个分布式ID生成服务,名字取自德国哲学家、数学家菜布尼茨的一句话:"There areno two identical leaves in the world."("世界上没有两片相同的叶子"),也代表着Leaf不会生成重复的ID。对于目前常应用在生产中的的分布式ID生成方式,都是基于数据库号段模式和雪花算法(snowflake),而leaf刚好同时兼具了这两种方式,可以根据不同业务场景灵活切换,把这两种模式分别称为Leaf-segment和Leaf-snowflake
Leaf-segment(分段获取ID号段)
Leaf-segment 实际上可以看做是MySQL模式的一种改进方案
- 原方案:每次获取ID都要读取一次数据库,造成数据库压力巨大
- 优化方案:改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值,用完之后再去数据库获取新的号段,以减轻数据库的压力
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '', -- your biz unique name`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`max_id` bigint(20) DEFAULT 1,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
- biz_tag:用于区分业务
- max_id:表示该biz_tag目前所被分配的ID号段的最大值
- step:step表示每次分配的号段长度
insert into leaf_alloc(biz_tag,step,max_id) values('pay_ordertag',1000,3000);
insert into leaf_alloc(biz_tag,step,max_id) values('waimai_ordertag',2000,10000);
insert into leaf_alloc(biz_tag,step,max_id) values('banma_ordertag',20000,20000);
insert into leaf_alloc(biz_tag,step,max_id) values('test_tag',1000,3000);
select * from leaf_alloc;
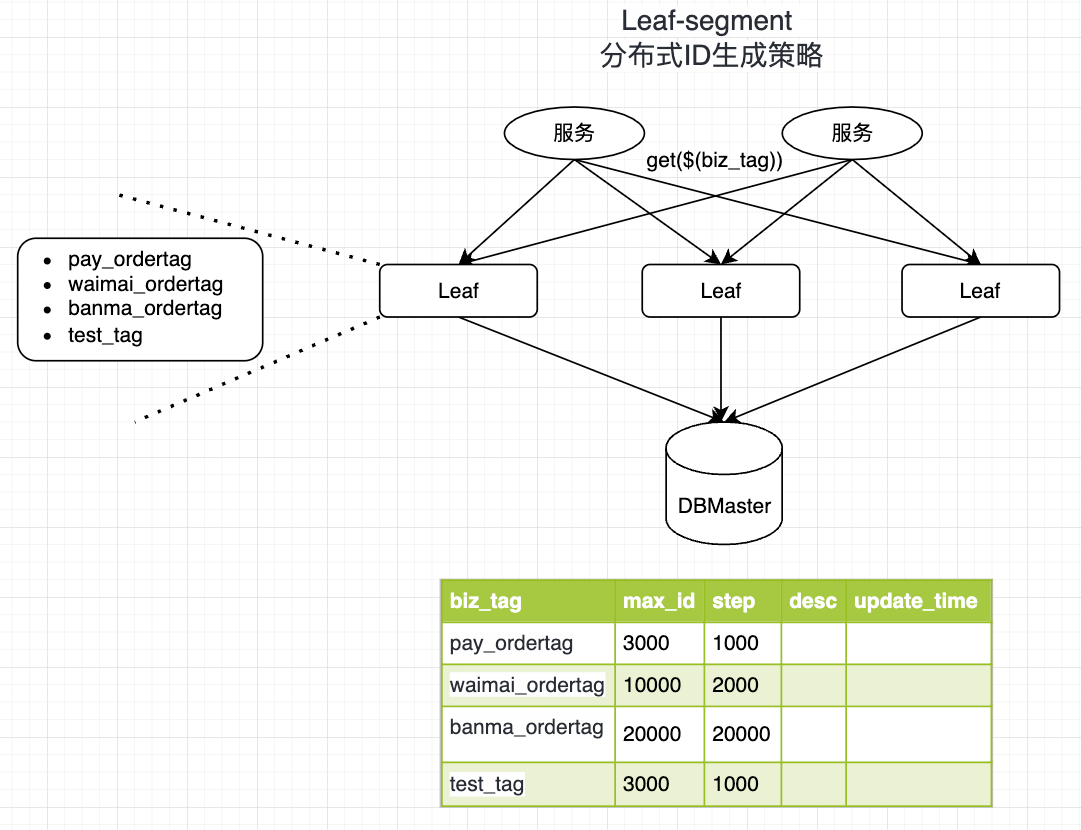
基于上述图示分析,有3台Leaf机器,从左到右:Leaf01、Leaf02、Leaf03
其中test_tag在Leaf01机器上的1-1000的号段,当这个号段用完之后就会向数据库申请一个长度为1000的号段,申请成功后Leaf01机器新加载的号段为3001~4000,相应更新biz_tag为test_tag的数据(其max_id会从3000更新为4000)
BEGIN ;
UPDATE leaf_alloc SET max_id = max_id + step where biz_tag = 'test_tag';
SELECT biz_tag,max_id,step from leaf_alloc where biz_tag = 'test_tag';
COMMIT;
如果单纯使用上述方案,ID生成的性能容易产生波动。因为当某个Leaf机器号段使用完之后,会等待在更新数据库的I/O上,所以 Leaf-segment 还做了进一步的优化-双buffer优化(用于优化号段用尽时更新号段所造成的性能阻塞)
双buffer优化的思路:
- 原始方案:Leaf 取号段是需要等待一个号段消耗完的时候才会进行,那么从DB取回新号段的时间就决定了号段交替时ID下发所花费时间,如果号段交替期间有新的请求进来,那么也会因为号段没有交替完成而让线程阻塞等待,包括DB的网络情况、DB的性能都是会造成一些影响
- 优化思路:提前加载号段=>为了让DB交替号段的过程做到无阻塞,可以当号段消费到某个点时就异步的把下一个号段加载到内存中,而不用等到号段用尽的时候才去更新号段

可以从上图看出,对于某一个biz tag,Leaf服务内部可以缓存两个号段(segment),当号段已下发10%时,如果下一个号段未更新,则另启一个线程去获取下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发ID,循环往复。
- 每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响
- 每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新
优缺点
- 优点
- Leaf-segment服务可以很方便扩展机器,性能完全能够支撑大多数业务场景
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服
- 缺点
- ID号码不够随机,容易泄露发号数量的信息,不太安全
- 强依赖DB,如果DB宕机会造成整个系统不可用(实际上用到数据库的方案都有可能)
⚽️滴滴TinyID方案(基于 Leaf-segment 升级版本)
Tinyid 方案是在 Leaf-segment 的算法基础上升级而来,不仅支持了数据库多主节点模式,还提供了 tinyid-client 客户端的接入方式,使用起来更加方便。
Tinyid 会将可用号段加载到内存中,并在内存中生成 ID,可用号段在首次获取 ID 时加载,如当前号段使用达到一定比例时,系统会异步的去加载下一个可用号段,以此保证内存中始终有可用号段,以便在发号服务宕机后一段时间内还有可用 ID。

Leaf-snowflake
针对上述 Leaf-segment 方案的缺点问题(ID生成不够随机),可能会存在一种泄露信息的危险。例如针对一些订单ID或者其他相关的ID生成场景,可通过订单号ID相减来大致估算公司一天的订单量,容易泄露秘密。因此通过引入Leaf-snowflake来应用上述问题。
Leaf-snowflake是完全沿用snowflake方案的bit位设计,主要进行了两点优化:
- 对于其中workerlD的分配,Leaf-snowflake使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerlD
- 对于原生snowflake可能存在的时钟回拨问题进行优化(强制等待)
Leaf-snowflake方案启动过程:
启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)
如果有注册过,就直接取回自己的workerlD(Zookeeper顺序节点生成的int类型ID号),启动服务
如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerlD号,启动服务

优缺点
- 优点
- ID生成按照时间整体有序,且每一个ms会随机起始序列号,ID安全性较好
- 不会出现因时钟回拨而导致ID生成异常问题(例如ID冲突、ID乱序)
- 缺点
- 依赖于Zookeeper,存在服务不可用风险
- 发生时钟回拨时,服务会短暂不可用
2.整体设计(架构设计)
① Twitter 雪花算法设计
基于上述对Twitter雪花算法的介绍,此处进一步深入理解基于该算法背景下的分布式ID的生成方案
数据中心ID 和 机器ID (一般也会将两者称为工作机器ID(workId),对应配置为机房ID + 机器ID 等)
结合上述64位布局分析,可以看到数据中心ID和机器ID是在部署启动的时候就确定下来的(一般系统运行后就固定下来),数据中心ID和机器ID的任何变化都需要仔细地审查,因为这些数值的意外变化都会导致ID冲突问题产生。而对于时间戳和序列号是ID生成器运行时生成的
时间戳
最重要的41位构成了时间戳部分,由于时间戳的顺序增长,生成的ID可按照时间排序。
可以用 41 位表示的最大时间戳是: 241−1=2199023255551毫秒(ms) ≈69年=2199023255551毫秒/1000秒/365天/24小时/3600秒,这意味着 ID 生成器将工作 69 年,并且自定义纪元时间接近今天的日期会延迟溢出时间。 69年后,则需要一个新的纪元时间或采用其他技术来迁移ID
既然使用的时间戳有限,因此实际场景中也不是直接使用当前时间戳(会损耗一些ID),可以通过定义一个固定开始时间戳,用【当前时间戳-固定时间戳】的差值作为存入的值,使得产生的ID可以从更小的值开始,用以定义更多的ID
序列号
序列号是12位,提供了212=4096 种组合,除非在同一台机器上1ms内生成多个ID,否则该字段设置为0。理论上,一台机器每毫秒最多可以支持4096个新ID(自增值支持同一毫秒内容一个节点可以生成4096个ID)
3.要点分析
基于上述分布式ID的方案设计,结合实际的ID生成需求选择适配的方案。此处基于现有需求选用雪花算法进行生成,但还需注意其他一些额外的问题:
- 由于雪花算法snowflake强依赖于机器始终,因此可能存在时钟回拨问题(如果机器上出现时钟回拨,会导致发号重复或者服务处于不可用状态)
- 当出现时钟回拨问题时,可以进行延迟等待,知道服务器时间追上来为止
4.总结陈述
分布式ID有哪些方案?
- 基于本地程序运算:UUID、雪花算法(snowflake)
- 基于常用主键:MySQL自增主键和 Redis 的
incr命令 - 基于分布式ID生成服务,类似美团的
leaf算法(leaf-segment、leaf-snowflake)