接口幂等性
接口幂等性
学习核心
- 什么是接口幂等性?为什么要引入?
- 接口幂等性的场景(CRUD操作)
- 幂等性的常见解决方案
- ① 数据库唯一键(新增)
- ② 防重表(新增)
- ③ 数据库乐观锁(更新)
- ④ 防重Token令牌(增删改)
学习资料
🟢【接口幂等性】核心
1.什么是接口幂等性?
接口幂等性是指一个接口在多次调用中的结果与调用一次的结果相同。换句话说,无论对一个幂等性接口进行多少次重复调用,系统的状态都保持一致,不会因为多次调用而导致不同的结果。这样的设计可以增加系统的可靠性减少重复操作可能带来的问题。
尤其在Web开发中,由于重试机制或者网络不稳定经常导致对接口的重复调用,如果接口是幂等的,那么在这些情况下,系统可以更容易地处理重复的请求,不会因为多次相同的请求而导致意外的副作用。
2.为什么需要接口幂等性?
基于接口幂等性的概念理解,因为多次相同的请求与一次请求带来的结果不一样而给系统带来了副作用,因此需要引入接口幂等性来避免这个副作用的产生
举个最常见的例子(金融支付),网上支付场景,比如用户购买商品下单成功,跳到支付页面,点击了支付按钮进行扣款,假设系统在返回支付结果的时候出现了网络异常,但此时后台已经扣款成功,但用户没看到支付成功的结果,再次点击支付按钮,此时会进行第二次扣款,返回结果成功,用户查询余额就会发现钱多扣了流水记录也变成了两条,这是金融场景中很严重的错误,这就是没有保证接口幂等性带来的副作用
常见的重复请求的场景
① 前端表单的重复提交
类似于上面的支付场景,前端表单在提交的时候遇到网络波动,没有及时对用户做出提交成功响应,致使用户认为没有成功提交,然后一直点提交按钮,这时就会发生重复提交表单请求
② 黑客恶意攻击
比如网上投票,黑客会针对一个用户进行重复提交投票,这样会导致接口接收到用户重复提交的投票信息,这样会使投票结果与事实严重不符
③ 接口超时重试
现在很多htp请求或者是rpc请求在实现的时候都会添加超时重试的机制,为了防止网络波动超时等造成的请求失败,这样就可能出现一次请求会出现多次请求
④ 消息重复消费
当使用 MQ 消息中间件时候,如果Consumer消费超时或者producer发送了消息但由于网络原因未收到ACK导致消息重发,都会出现重复请求
3.哪些接口需要幂等?
判断操作是否幂等,则需要看其对系统资源的操作变化情况。根据业务操作类型(CRUD)进行划分,看操作一次和操作多次对系统资源的操作结果是不是一样的
接口幂等性的验证和实施需要消耗一定的资源,因此并非每个接口都应该被赋予幂等性验证。相反,这种决策应该基于实际业务需求和操作类型进行区分
以查询和删除操作为例,这两种操作通常不需要进行幂等性验证。在查询操作中,无论执行一次还是多次,结果都是一致的,因此无需进行幂等性验证。对于删除操作,无论是执行一次还是多次,都是将相关数据进行删除(这里指的是有条件的删除而不是删除所有数据),因此也无需进行幂等性验证
后台的业务接口无非就是增删改查四种接口,幂等性如下表:
| 接口类型 | 描述 | 是否幂等 |
|---|---|---|
| 【新增】操作 | 新增每次都会往db中插入数据 | ❌ |
| 【更新】操作 | 具体看修改操作的目的: ① 如果将某个数修改为1,那么无论执行多少次这个数都会被修改为1,因此操作是幂等的 ② 如果将某个数增加1,那么每执行1次这个数都会变化,因此操作不是幂等的 | 分情况 |
| 【查询】操作 | 查询操作是根据条件获取系统资源,并不会对当前系统资源进行改变 | ✅ |
| 【删除】操作 | 删除一次和删除多次都是将数据删除,执行效果体现一致 | ✅ |
4.幂等性的常见解决方案
① 数据库唯一键(新增场景)
方案描述
数据库唯一键保证幂等性主要是利用了数据库中Unique Key唯一约束的特性,通常来说是将业务表中的某个字段设置为唯一键,即加上唯一索引,一般来说这种方式比较适用于插入数据的场景,唯一键能够确保一张表中只存在一条具有该唯一主键的记录。
在使用数据库唯一键确保幂等性时,需要注意通常情况下并不使用数据库中的自增键,而是采用分布式ID生成一个唯一键。这样做的目的是为了保证在分布式环境下ID的全局唯一性。
适用场景
- 适用于【新增操作】场景
使用限制
- 需要生成全局唯一键ID
核心流程
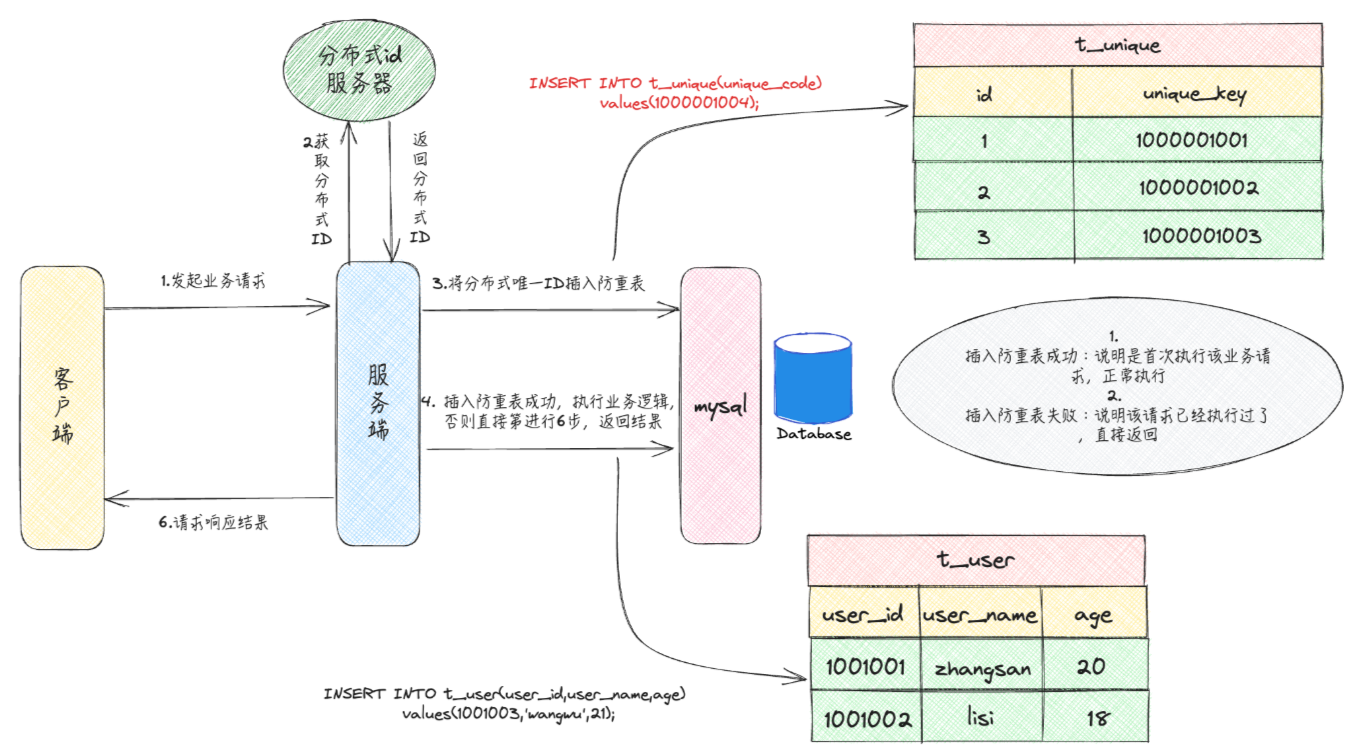
① 客户端发起请求,请求服务端对应接口
② 服务端进行业务处理,生成一个分布式ID,并将其指定为待插入数据的唯一键。接着,执行数据插入操作,执行相应的SQL语句
③ 服务端将新该条数据插入数据库。若插入成功,表示没有发生重复调用接口的情况。若插入失败,表明数据库中已存在相同记录,服务端直接返回操作成功信息给客户端

② 防重表(新增场景)
方案描述
利用防重表来解决幂等的原理其实和数据库唯一键差不多,都是利用唯一键的约束来进行,这种方式比较适用于插入数据的场景。但是防重表和数据库唯一键有一个区别,那就是把这个唯一键抽离出去了,而不是耦合在原来的业务表中,这样做有一个好处,这个业务表可能涉及到多个业务场景比如有A,B两个场景,其中A场景不允许存在重复,但是B场景允许重复,这样如果是在业务表中直接加唯一键的话,就会影响B场景,而防重表通过将唯一键与业务表分开,将判重逻辑与业务逻辑剥离,就可以避免这种情况
通常防重表表只包含两个字段: id 和 唯一索引(比如支付场景中的订单ID),这个唯一索引唯一标识一次业务请求,这个唯一请求ID通常也是采用分布式唯一ID生成器来处理,比如可以用雪花算法。
适用场景
- 适用于【新增操作】场景
使用限制
- 需要生成全局唯一键ID
- 需要额外新增一张防重表,还要考虑数据量大的情况下的分库分表或者是过期数据清理问题
核心流程
① 客户端发起请求,请求服务端对应接口
② 服务生成一个全局唯一ID,并尝试将其插入到防重表中
③ 若插入成功,表示没有发生重复调用接口的情况,继续执行业务逻辑,若插入失败,表明数据库中已存在相同记录,直接返回操作成功信息给客户端
因为防重操作和业务操作具有整体性,所以防重表和业务表必须在同一个数据库中,并且操作要在同一个事务中
③ 数据库乐观锁(更新场景)
方案描述
通常,数据库中的乐观锁方案主要用于执行“更新操作”。一种常见的实现方式是在相关数据表中预先添加一个字段,用来充当当前数据的版本标识。这样,每次对该表中的数据执行更新操作时,都会将该版本标识作为一个条件,其值应为上一次待更新数据中的版本标识值。这种方式能够有效地处理并发更新操作,通过比对版本标识的值来确保在更新过程中不会发生冲突。
适用场景
- 适用于【更新操作】场景
使用限制
- 需要数据库对应业务表中添加额外的字段(例如version版本表示)
核心流程
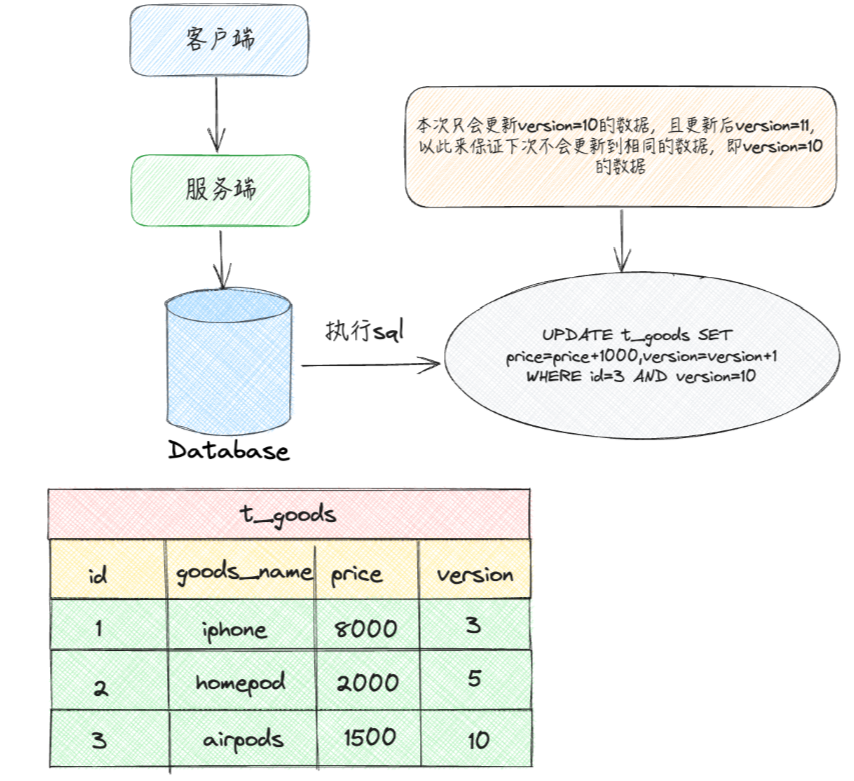
步骤① :客户端发起更新请求并且携带之前查询出的版本号version
步骤②:服务端执行update的时候需要给version+1,并且需要加version的更新条件如下SQL
update t set num = num - 1,version = version + 1
where id = #{id} and version = #{version}
#{id} 表示要修改的记录ID号
#{version} 表示更新操作执行之前查找出来的版本号信息
案例分析
以商品表为例,需在原有的商品表中新增version字段用于记录当前字段的记录版本,在更新的时候携带相应的version,在执行操作的时候就能确定更新的是哪个版本下的记录
| id | goods_name | price | version |
|---|---|---|---|
| 1 | phone | 800 | 3 |
| 2 | homepod | 200 | 5 |
| 3 | airpods | 1500 | 10 |
例如执行更新的时候执行要进行更新的记录的版本号(将airpods的价格上调1000):update t_goods set price = price+1000,version=version+1 where id = 3 and version = 10
- 当第①次执行更新的时候,id为3的airpods价格和版本被更新:price为2500、version为11
- 当第②次执行更新的时候,此时满足
id=3 and version=10的记录已经不存在(在前面的更新操作中被更新了),因此这个执行是无效的,多次执行也不会对数据结果产生影响,以此确保更新操作的幂等性
④ 防重Token令牌(增删改场景)
方案描述
核心:通过Redis + token 方式置换原有在db层面的幂等性校验(但存在精准性问题,无法做到完全幂等性保证)
为了应对客户端连续点击或调用方的超时重试等情况,例如在提交订单时,可以通过 Token 机制来防止重复提交。简而言之,调用方在调用接口之前会首先向后端请求一个全局ID(Token),并在请求时将该全局ID与其他数据同发送(最好将Token放置在Headers中)。后端会将该Token作为键,用户信息作为值存储在Redis中进行键值内容校验。如果该键存在且值匹配,就会执行删除命令,然后正常执行后续的业务逻辑。如果找不到对应的键或值不匹配,则表明是重复请求,不会再执行业务逻辑,直接返回重复请求信息,从而确保幂等性操作
适用场景
- 适用于新增、更新、删除操作
使用限制
- 需要生成全局唯一Token串
- 需引入第三方组件Redis进行数据校验,增加了系统的复杂性
核心流程
要点:此处既然是根据 token 来控制重复提交操作,因此要理解 Token 的生成时机必须能够保证可以使该操作多次执行都能得到相同的效果才行,也就是说Token的生成时机要可以确保幂等操作(结合后面的【防重token令牌案例】理解)
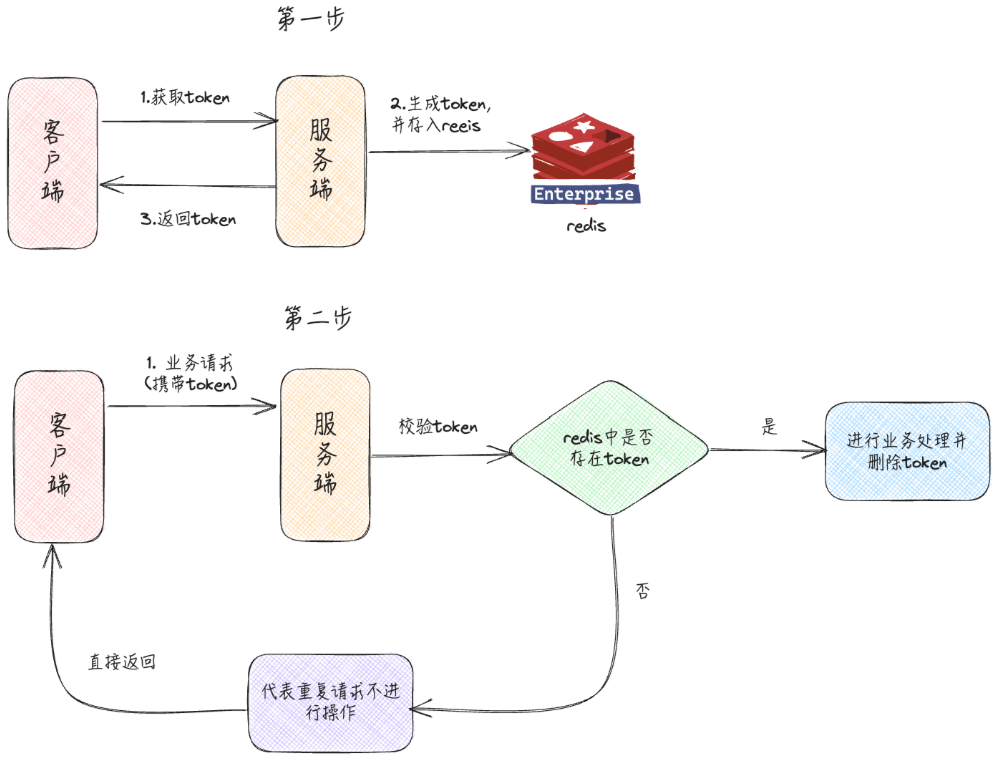
① 客户端会先发送一个请求去获取 token,服务端会生成一个 token 保存在 redis 中(这个token可以是一个分布式 ID 或者 UUID 串),并且设置过期时间,在redis中保存完之后,把这个 ID 返回给客户端
② 客户端第二次调用业务请求的时候必须携带这个 token(通常将这个token放在header中,请求携带这个header)
③ 服务端收到请求从header中获取该token,然后校验这个 token(根据token 到 Redis 中查找该 key 是否存在)
- 如果校验成功,则执行业务,并删除 redis 中的 token
- 如果校验失败,说明 redis 中已经没有对应的 token,则表示重复操作,直接返回指定的结果给客户端
注意事项
- redis 中是否存在 token 以及删除的代码逻辑建议用 Lua 脚本实现,保证原子性
- 全局唯一 ID 可以用 百度的 uid-generator、美团的 Leaf 去生成
问题分析
(1)防重Token令牌可否保证完全幂等性
问题分析:通过redis + token的方式虽然绕开了db层面来进行幂等性的校验,总的效率来说会高很多,但是却存在着不够精准的场景,不能够做到完全幂等性保证
假设某个客户端第一次发起请求,然后服务端收到后将token从Redis中删除,接着去执行业务逻辑,但是业务逻辑执行失败了,此时有两种可能:
- 此时服务端可能会向客户端返回执行失败,客户端收到该返回后自动重新请求一个token,然后再次发起请求重试,这种场景下是正常请求,不存在幂等性问题
- 如果此时服务端向客户端返回执行失败的过程中,由于网络或其他什么原因导致 客户端无法接收到 服务端返回的 执行失败 响应。那么此时客户端会再次使用 第一次申请的token 再次向服务端发送请求,但是此时服务端返回的确却是 重复请求 或 执行成功
但综合效率以及网络故障概率等因素总体来说,这种方案实用性较强,没有明显的缺陷。如果在使用这种方式的基础上想要保证严格意义上的幂等性,可以结合业务场景,在db层加上之前的三种方案进行兜底
(2)token防重令牌的方式和分布式锁的方式类似,可否用分布式锁来处理?
token防重令牌的方式跟分布式锁的方式很像,都是维护全局资源,类似于全局锁,获取到了才有资格进行请求处理,那用分布式锁来处理幂等性可以吗,例如加锁成功执行请求处理,加锁失败说明请求已经在处理了,直接返回?
答案是不合适的,试着思考下面三种情况:
- 客户端连续发起两次请求(比如用户快速点击按钮的情况):第一次请求先到达服务端,然后第二次请求由于某些原因过了一会儿才到达服务端。等第二次请求达到服务端的时候,第一次请求已经执行完毕并且释放了锁。此时第二次请求仍然能加锁成功,并且执行业务逻辑,导致在这种情况下幂等性失效
- 客户端发起请求处理成功但由于网络抖动没有接收到响应,于是客户端再次尝试发起请求:客户端发起第一次请求,服务端正常执行完毕并释放了分布式锁,但由于网络原因客户端没有正常收到服务端的响应,此时客户端再次发起请求。由于第一次请求所加的分布式锁已经过期所以第二次请求仍然能够加锁成功,然后执行业务逻辑,此时幂等性失效
- 客户端连续发起多次请求,这多次请求同时到达服务端,此时开始争抢锁,谁抢到锁谁就执行,其他没有抢到锁的请求都统统不执行,这种情况能保证幂等性。
⑤ 幂等性方案总结
幂等性是开发过程中比较常见的一类问题,后端比较常见的解决方案
| 方案 | 适用场景 | 实现复杂度 | 方案缺点 |
|---|---|---|---|
| 数据库唯一键 | 新增 | 简单 | 只适用于插入场景,与业务表耦合,必须要设定业务表唯一键,无法很好应对场景 |
| 防重表 | 新增 | 简单 | 只适用于插入场景,在DB层完成,效率不高 |
| 数据库乐观锁 | 修改 | 简单 | 只适用于更新场景,在DB层完成,效率不高 |
| 防重Token令牌 | 增删改 | 复杂 | 无法做到接口的完全幂等性保证,由于网络原因可能造成客户端收不到服务端的执行失败请求 |
🚀【幂等性】实战
1.防重Token令牌
参考代码:noob-demo/system-design-demo/TokenCheck
① 业务流程分析
构建一个SpringBoot项目接入Redis,模拟接口提供方,引入Token机制进行防重校验。业务流程分析如下:
- 客户端向后端请求生成一个token(可以根据自身用户信息去关联生成,用于后续校验身份信息),服务端会生成token保存在redis中并设定过期时间,随后将token返回给客户端
- 随后客户端调用业务API需要携带该token(放在header请求头处)以进行身份校验和防重判断
- 服务端收到请求后会校验请求的header中的token,随后进行校验
- 如果校验成功,则执行业务,并删除redis中的token
- 如果校验失败,则说明redis中已经没有对应的token,表示重复操作,返回相关提示给客户端
此处思考几个场景,思考设计场景问题:
- ① 前端连续点击:客户端调用API之前会向后端请求获取token,因此当获取到token后调用API接口时应用同一个token进行校验,否则不同token会被认为是不同的客户端操作而放行,反而没有防重的效果。当出现连续点击的情况,客户端用同一个token访问接口,当前面的操作执行成功会删除token,则后面的请求将会被拒绝
- ② 当第1次获取token随后调用接口执行业务逻辑时,删除了token,但是业务逻辑执行或者响应出现了问题:
- 删除了token,业务逻辑执行失败,客户端收到响应重新申请token并再次请求接口,这是正常的业务逻辑操作,不存在幂等性问题
- 删除了token,业务逻辑执行失败但是没能及时反馈给客户端,客户端再次使用第1次申请的token去
② 要点分析
(1)如何理解【Token 的生成时机必须能够保证可以使该操作多次执行都能得到相同的效果】这句话?
关注token:token的生成一定是跟用户、时间,有时候甚至是IP等信息关联,用以唯一标识这个请求
针对客户端的连续点击或者调用方的超时重试等情况,可以用Token的机制实现防止重复提交。以最常见的【提交订单】案例场景为例进行分析,理解Token的不同生成时机的重要性(可以说Token的生成时机是该机制的核心)
例如在商城系统中,如果说每次点击提交订单都生成 token(生成 token ,然后携带 token 请求API),就无法保证幂等性(相当于每次点击提交按钮都是一次新的请求操作,当出现连续点击或者失败重试的情况,就会执行一次【生成+访问】的组合操作,那么这种情况幂等性是失效的)。
那么该什么时候生成呢?如果设定用户进入订单页面的时候就生成该token,那么当用户提交订单的时候携带这个token一起提交,基于这个场景用户不管提交多少次订单最多就只能成功一次。
出现连续点击的情况token一般都是相通的,即用同一个token去访问接口(具体也看业务流程设计是否合理)
(2)先删除token再执行业务逻辑?还是先执行业务逻辑再删除token?
这两种方案的选择取决于业务场景需求。
先删除token再执行业务逻辑:可能存在业务逻辑执行失败,但是token被删除的情况,此处可能存在两种处理
- token 被删除,业务执行失败反馈给客户端(或者业务执行失败但是由于网络抖动等其他问题导致客户端没有接收到响应),客户端触发重试机制再次发起请求:
- 如果是继续用同一个token发起请求此时就会被告知重复处理/请求成功(因为token已经被删除了)而无法执行业务逻辑;
- 如果是重新触发生成token然后携带新token再发起请求,这个操作流程是正常的重试操作(无幂等性问题)
- 适用于实时性要求较高且能容忍少量的重复处理的服务
先执行业务逻辑再删除token:可能存在业务逻辑执行成功,但是token删除失败的情况
可以避免由于业务逻辑执行失败而无法再次重试的问题(业务执行失败,但是token还没有过期或者还没被删除,因此可以重新发起验证并处理)
如果业务逻辑执行成功,但是token删除失败,那么在token存活期间可能会连续触发接口请求,从而导致重复调用,存在幂等性问题
如果业务逻辑执行时间较长,token还没来得及删除,也是可能存在连续触发接口请求,从而导致重复调用的问题
适用于对数据一致性要求较高的场景(例如金融交易系统,需确保每笔交易只被处理一次)
其次,从重复执行发生的概率性考虑,如果是【先执行业务逻辑再删除token】其出现重复执行的概率会比【先删除token后执行业务逻辑】发生的概率要高一点,因为它在没有网络延迟的情况下也会有一定的概率出现(例如Redis宕机导致删除失败等情况),而【先删除token后执行业务逻辑】相对比较保守,可能会由于网络抖动导致业务逻辑没法正常重试(token被删除,由于网络抖动导致客户端无法感知任务执行失败,再次用同一个token重试就会被告知重复而无法处理),所以一般也是推荐【先删除token后执行业务逻辑】这种做法
(3)为什么要将token放在header中?
如果和业务数据放在请求体中,可能会导致Token被恶意篡改,如果放在URL中,会增加Token的泄漏机率。因为浏览器这些都会记录URL,放在请求头中也有利于分离关注点
(4)Redis 的原子性操作应用体现在哪个设计部分?
通过定义lua脚本来辅助处理,在验证token的时候需要确保获取和验证token操作的原子性,返回验证结果。