🚀数据批量操作篇
🚀数据批量操作篇
前情提要
在MySQL原理学习中,经常需要用到一些大数据量的表来支撑理论学习,因此不免会陷入"造数据"的烦恼,虽然可以借助一些函数或者程序设计(例如hutool工具类)的方式来动态生成一些可用的数据,但还需要进一步满足对大数据量处理的需求,从一开始的1w、10w、100w的数据测试过程会发现可能批量插入几万条数据借助存储过程可能就几分钟忍忍就过去了,但是对于更大的数据量批量插入操作却直接断层拉开时间成本,可能需要更长的时间去完成批量操作
- MySQL服务环境:MySQL8.0.21(核心测试)、MySQL5.7.44(辅助对照)
- IDEA(JAVA程序构建,用于批量生成数据)
- 客户端环境:Navicat、Windows 10(16G)
参考模块:springboot-demo-batchHnadler
MySQL数据原生批量插入
1.借助存储过程
借助存储过程实现批量插入
操作核心:借助存储过程随机生成模拟数据,执行insert语句依次完成批量操作
参考案例:模拟100w数据插入的存储过程( t_user_batch )
# 1.创建数据表
CREATE TABLE `t_user_batch` (
`uid` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`account` varchar(30) NOT NULL DEFAULT '' COMMENT '用户账号(邮箱/手机号/昵称)',
`mobile` varchar(11) NOT NULL DEFAULT '' COMMENT '中国境内手机号',
`add_time` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '注册时间',
PRIMARY KEY (`uid`)
) ENGINE=InnoDB COMMENT='用户表';
# 2.定义一个循环插入的存储过程(模拟插入100w数据)
# 定义存储过程
DROP PROCEDURE IF EXISTS `p_insert_t_user_batch`;
DELIMITER ;;
CREATE PROCEDURE `p_insert_t_user_batch`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<= 1000000
DO
# 插入语句
insert into `t_user_batch` (`uid`, `account`, `mobile`, `add_time`) VALUES (NULL, substring(MD5(RAND()),1,10), substring(RAND()*1000000000000,1,11), UNIX_TIMESTAMP());
SET i=i+1;
END WHILE ;
commit;
END;;
DELIMITER;
# 3.执行存储过程
call p_insert_t_user_batch();
# 执行结果(距测试结果大概是9565.953s,即大概2个多小时)
通过调用存储过程完成数据批量插入操作,但这个过程显然是非常耗费时间的,可以分析上述存储过程中耗费的时间成本主要是那些,进而分析主要耗费是在哪块,进行定向优化。从上述存储过程分析,整个过程耗费的时间主要在于两个方面
- 【1】函数使用:例如字符串处理、MD5函数调用、时间戳
- 【2】SQL解析和插入动作
为了进一步排除其他因素对数据插入的影响,此处单独测试下如果仅仅基于上述步骤【1】大概耗时是多少,构建如下存储过程进行测试(排除步骤【2】的处理)
# 单独把函数使用的成本大致估算下(通过存储过程,去除掉insert部分)
# 定义存储过程(用于计算函数调用的成本)
DROP PROCEDURE IF EXISTS `p_insert_t_user_batch_call`;
DELIMITER ;;
CREATE PROCEDURE `p_insert_t_user_batch_call`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<= 1000000
DO
# 取消插入语句,计算函数调用成本
set @va = substring(MD5(RAND()),1,10);
set @vb = substring(RAND()*1000000000000,1,11);
set @vc = UNIX_TIMESTAMP();
SET i=i+1;
END WHILE ;
commit;
END;;
DELIMITER;
# 执行存储过程
call p_insert_t_user_batch_call();
# 执行结果
[SQL]call p_insert_t_user_batch_call();
受影响的行: 0
时间: 35.193s
结合上述测试结果分析,可以看到函数调用的耗费时间也仅仅在35s左右,在这个整体的数据导入过程中并不占大头,因此要考虑如何优化步骤【2】的insert部分。拆解该存储过程的定义和执行过程,实际上就是生成一条条的SQL语句并循环执行,最后一次性提交,所以基于这种形式的执行方式等同于在Navicat中开启客户端查询窗口,把100w条insert语句copy进去并执行
存储过程批量插入优化方案梳理
结合上述成本分析,可以看到真正的成本消耗主要在于SQL解析和插入动作。且这种方式如果直接一次性插入大数据量的数据,就很有可能造成客户端卡死崩溃,方向不对努力白费。但可以试着通过调整配置的方式来解决
设置 innodb_flush_log_at_trx_commit = 0 ,相对于 innodb_flush_log_at_trx_commit = 1 可以十分明显的提升导入速度;
修改参数 bulk_insert_buffer_size, 调大批量插入的缓存;(默认是8388608=8M,可以适当调大:设置为16-100M,具体看插入的数据量)
合并多条 insert 为一条
此外,针对不同存储引擎的表也有相应的优化方案:
针对MyISAM类型的表(仅对MyISAM表有效)
- 如果是导入数据到空Myisam表,默认就是先导入数据然后才创建索引的,不需要额外设置
- 如果是导入数据到非空Myisam表
# 导入前暂时禁用索引和约束,避免额外的检查耗时 ALTER TABLE `table_name` DISABLE KEYS; ALTER TABLE `table_name` DISABLE TRIGGER; # 在导入完成后,记得重新启用索引和约束: ALTER TABLE `table_name` ENABLE KEYS; ALTER TABLE `table_name` ENABLE TRIGGER;针对InnoDB类型的表(仅对InnoDB表有效)
- 如果没有主键则建议创建主键:Innodb类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率
- 唯一性检验参数:
# 导入数据前关闭唯一性校验 SET UNIQUE_CHECKS=0; # 在导入结束后恢复唯一性校验 SET UNIQUE_CHECKS=1;- 自动提交参数:
# 导入数据前关闭自动提交 SET AUTOCOMMIT = OFF; # 导入数据后恢复自动提交 SET AUTOCOMMIT = ON;
优化实践:存储过程插入100w条数据
(1)优化思路
首先确认要插入的表的表结构:t_user_batch 表是基于InnoDB引擎构建的,因此此处通过调整配置来校验批量插入效率是否有效提升
- 设置刷盘方案:
set innodb_flush_log_at_trx_commit = 0; - 设置批量插入的缓存大小:
set bulk_insert_buffer_size = 16*1024*1024;(默认是8M) - 设置唯一性校验和自动提交:
# 导入数据前关闭唯一性校验和自动提交
SET UNIQUE_CHECKS=0;
SET AUTOCOMMIT = OFF;
# 在导入结束后恢复唯一性校验和自动提交
SET UNIQUE_CHECKS=1;
SET AUTOCOMMIT = ON;
(2)优化实践参考
⚽️原默认配置测试分析
==原默认配置:==排查默认配置更改的影响,全部初始化为默认配置。测试结果数据插入特别慢
# 1.导入数据前设置优化配置
set global innodb_flush_log_at_trx_commit = 1;
set bulk_insert_buffer_size = 8 * 1024 * 1024;
SET UNIQUE_CHECKS= ON;
SET AUTOCOMMIT = ON;
# 2.批量导入
call p_insert_t_user_batch();
commit;
# 3.导入数据后恢复默认配置
set global innodb_flush_log_at_trx_commit = 1; # 默认刷盘方式为1
set bulk_insert_buffer_size = 8 * 1024 * 1024; # 默认为8M
SET UNIQUE_CHECKS = ON; # 默认是开启唯一性校验
SET AUTOCOMMIT = ON; # 默认是自动提交
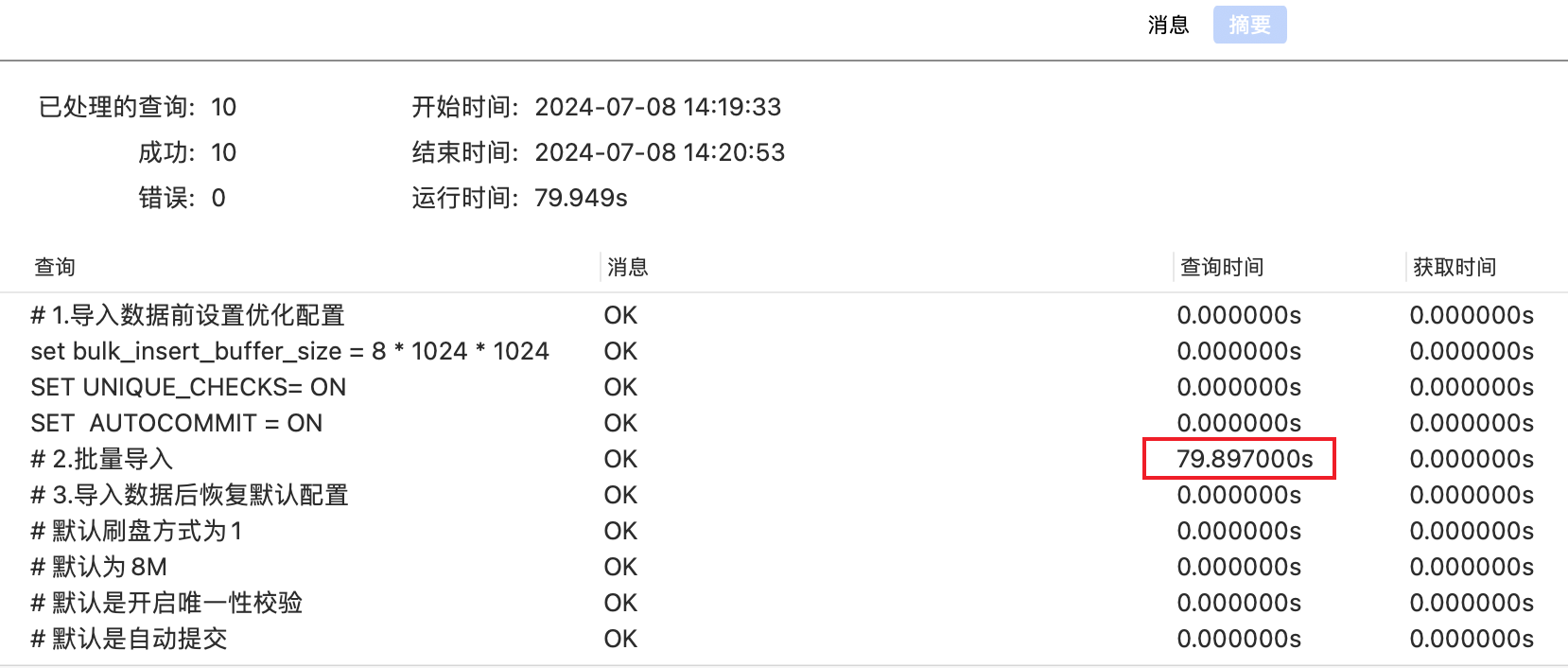
优化前:WIN10 & MySQL-8.0.21 执行结果(特别卡,卡到崩溃,有统计数据参考大概是2h左右)
优化前:MAC & MySQL-5.7.44 执行结果(100w数据插入总耗时80s左右,其中函数调用占用3.5s左右,实际SQL解析插入操作耗时为76.5s)
⚽️优化配置后测试分析
优化配置参考:
# 1.导入数据前设置优化配置
set global innodb_flush_log_at_trx_commit = 0; # 调整刷盘方式
set bulk_insert_buffer_size = 16 * 1024 * 1024; # 调整为16M
SET UNIQUE_CHECKS= OFF; # 关闭唯一性校验
SET AUTOCOMMIT = OFF; # 关闭自动提交
# 2.批量导入
call p_insert_t_user_batch(); # 批量导入存储过程内部已经设定了关闭自动提交,因此此处也可无需额外设定AUTOCOMMIT参数
commit;
# 3.导入数据后恢复默认配置
set global innodb_flush_log_at_trx_commit = 1; # 默认刷盘方式为1
set bulk_insert_buffer_size = 8 * 1024 * 1024; # 默认为8M
SET UNIQUE_CHECKS = ON; # 默认是开启唯一性校验
SET AUTOCOMMIT = ON; # 默认是自动提交
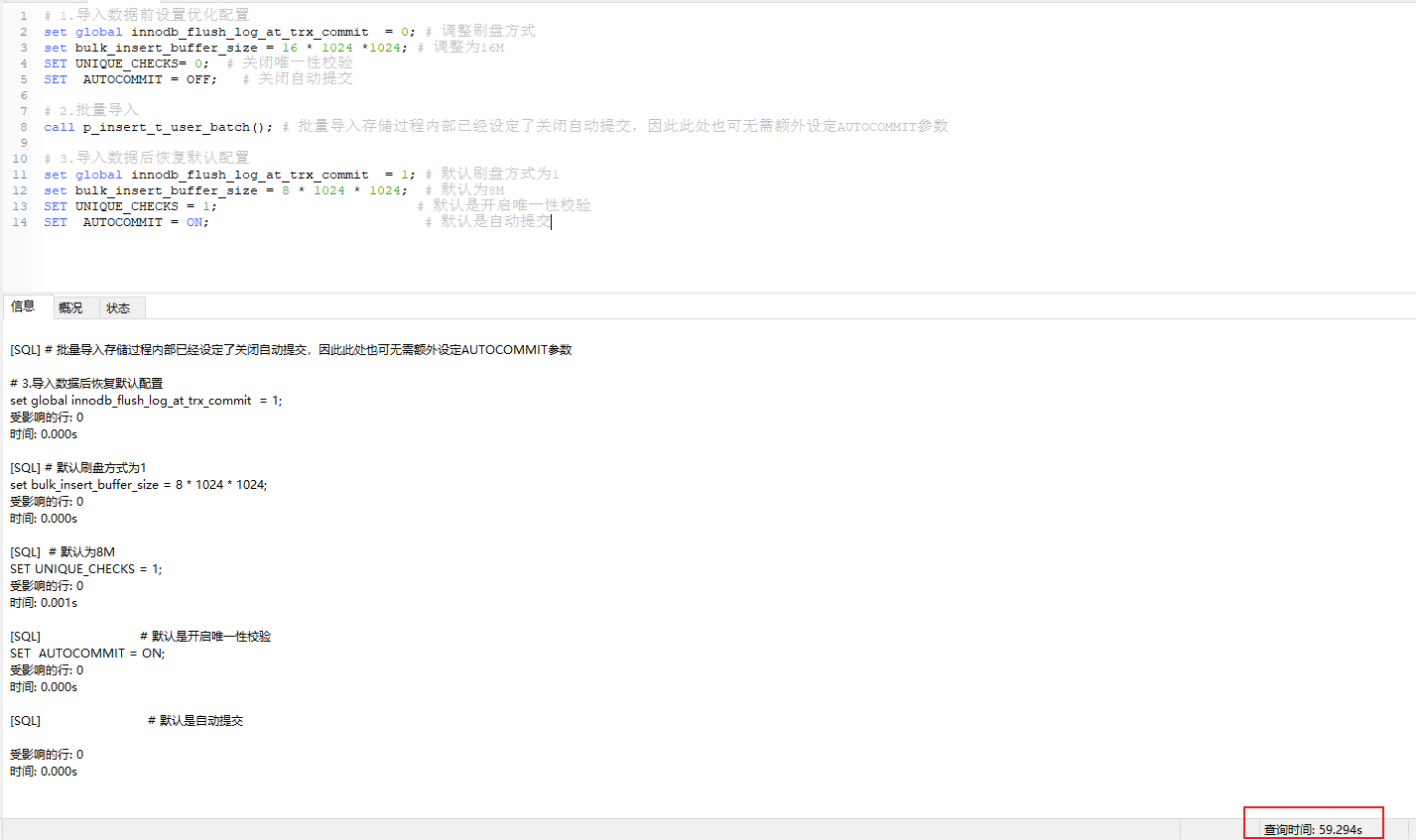
WIN10 & MySQL-8.0.21 执行结果
插入100w条记录的过程总耗时为59.537s,除去函数调用的35.19s,则整个SQL解析和insert过程大概耗时为25s左右,效率大大提高
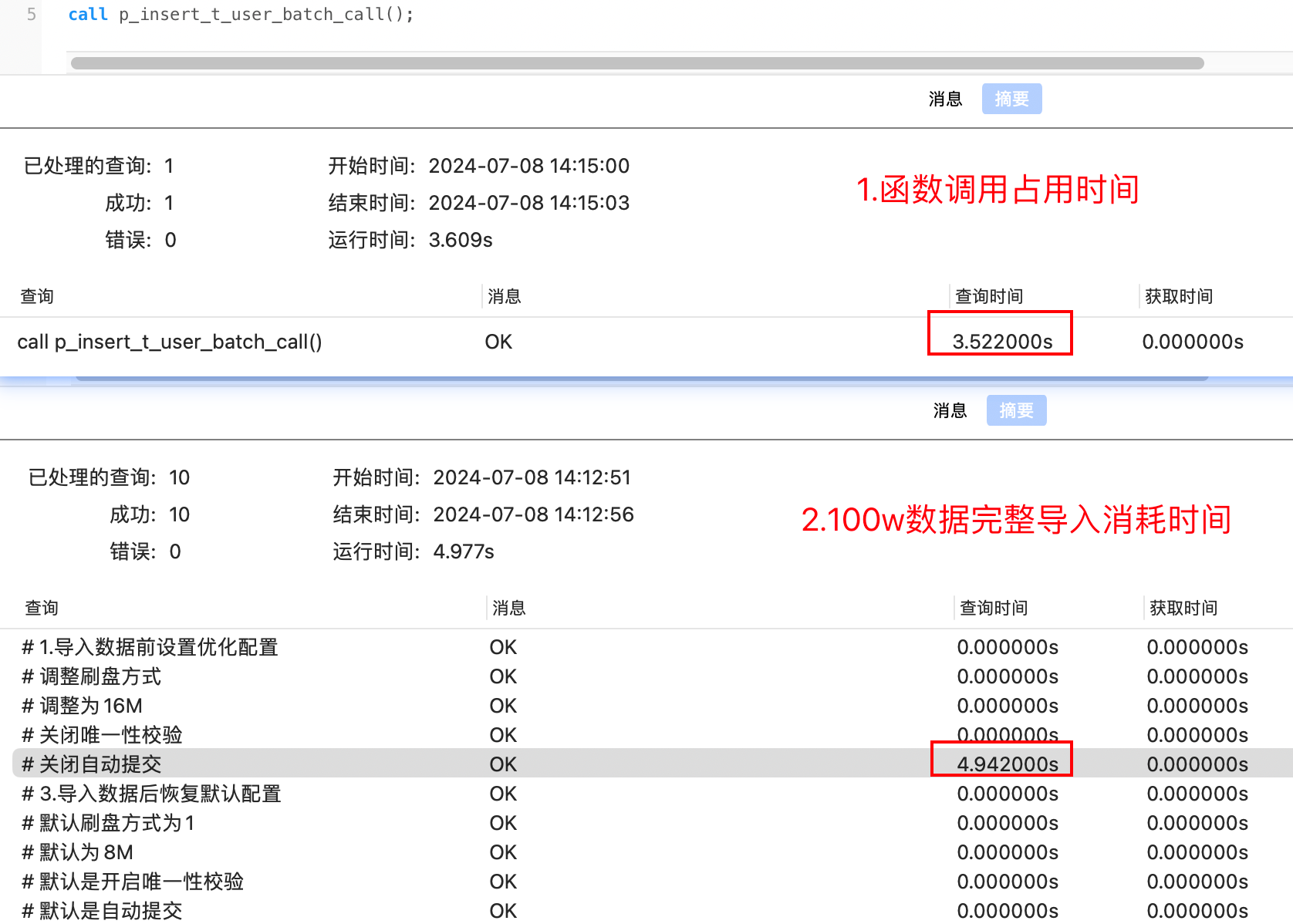
MAC & MySQL-5.7.44 执行结果(100w数据插入总耗时4.94s左右,其中函数调用占用3.52s左右,实际SQL解析插入操作耗时为1.42s)
2.通过LOAD DATA LOCAL INFILE的方式
100w数据处理(基于t_user_batch表)
优化方案
LOAD DATA LOCAL INFILE 方式导入数据文件:(导入本地服务器数据)
- 【1】创建一个SQL脚本(里面存储了要批量导入的SQL insert语句),可通过程序来模拟生成SQL语句
- 【2】借助
LOAD DATA LOCAL INFILE语句导入脚本文件
需注意此处通过执行SQL脚本的方式不是通过类似借助Navicat客户端直接打开SQL脚本点击运行(这种操作效果和直接执行insert语句概念是一样的),而且在打开一个大数据量的SQL脚本甚至直接会把Navicat、VSCode这类客户端卡死。
MySQL 8.0 中默认关闭了local_infile,在使用的时候如果报错:ERROR 1148 (42000): The used command is not allowed with this MySQL version需要手动开启
MySQL 5.7 中默认local_infile是ON状态
数据表构建
DROP TABLE IF EXISTS `t_user_batch`;
CREATE TABLE `t_user_batch` (
`uid` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`account` varchar(30) NOT NULL DEFAULT '' COMMENT '用户账号(邮箱/手机号/昵称)',
`mobile` varchar(11) NOT NULL DEFAULT '' COMMENT '中国境内手机号',
`add_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '注册时间',
PRIMARY KEY (`uid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';
模拟生成数据
public void batchGenTUserBatchToSQL() throws Exception {
List<TUserBatch> tUserBatchList = RandomGenEntityUtil.genTUserBatch(1000000);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 封装SQL文本信息
List<String> insertList = new ArrayList<>();
tUserBatchList.forEach(tUserBatch -> {
// 拼接SQL语句
StringBuffer insertSql = new StringBuffer();
// 主键自增
/*
insertSql.append("insert into t_user_batch (account,mobile,add_time) values( ")
.append("'" + tUserBatch.getAccount() + "',")
.append("'" + tUserBatch.getMobile() + "',")
.append("'" + sdf.format(tUserBatch.getAdd_time()) + "');");
*/
String split = ",";
insertSql.append(tUserBatch.getAccount() + split)
.append(tUserBatch.getMobile() + split)
.append(sdf.format(tUserBatch.getAdd_time()));
insertList.add(insertSql.toString());
insertList.add(insertSql.toString());
});
// 写入文件
FileWriter writer = new FileWriter(new File("D:\\Desktop\\tmp\\insert.sql"));
insertList.forEach(insertSql -> {
try {
writer.write(insertSql + "\n");
} catch (IOException e) {
System.out.println("数据写入异常" + insertSql);
throw new RuntimeException(e);
}
});
// 关闭写入流
writer.close();
}
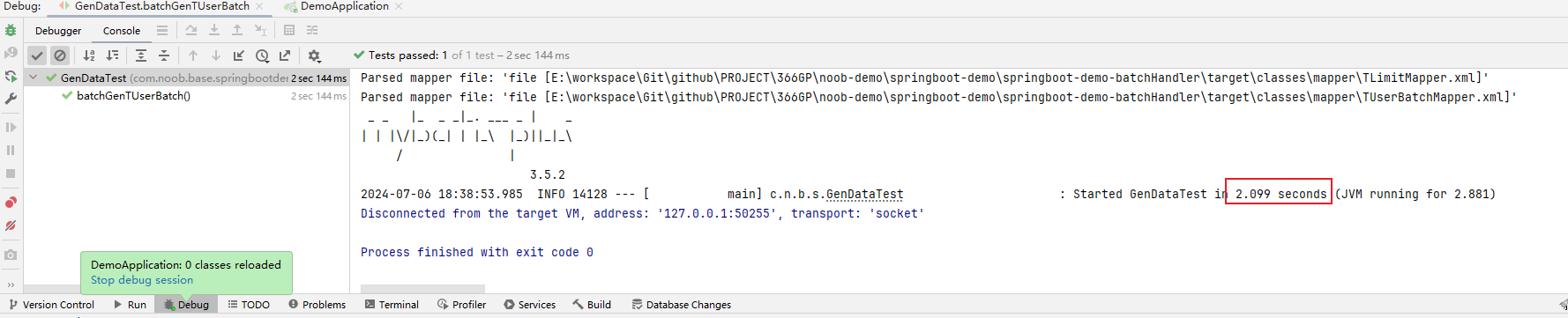
执行生成一个100w的数据文件 insert.sql(120MB),数据量为100w,大概耗时 2s 左右
# 生成的文件格式内容参考(按照逗号分割)
PddV1krf@163.com,15561668801,2024-07-07 16:11:39
# 错误的导出格式(此处文本可以不需要完整的SQL语句,而是可以按照指定规则限定数据分割数据)
# insert into t_user_batch (account,mobile,add_time) values( 'FhfMJX5q@163.com','18813989537','2024-07-06 18:38:54');
SQL 脚本导入
# 1.需检查local_infile变量状态
show variables like 'local_infile';
# 如果为关闭状态需开启
set global local_infile = ON;
# 2.执行指令批量导入数据
# LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\insert.sql' INTO TABLE t_user_batch(account,mobile,add_time);
LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\insert.sql' INTO TABLE t_user_batch
FIELDS TERMINATED BY ','
lines terminated by '\n'
(account,mobile,add_time);
------------------------------------------------------------------------------------------------------------------
# 常见错误1:[Err] 3948 - Loading local data is disabled; this must be enabled on both the client and server sides
- 需检查local_infile变量状态
show variables like 'local_infile';
set global local_infile = ON;
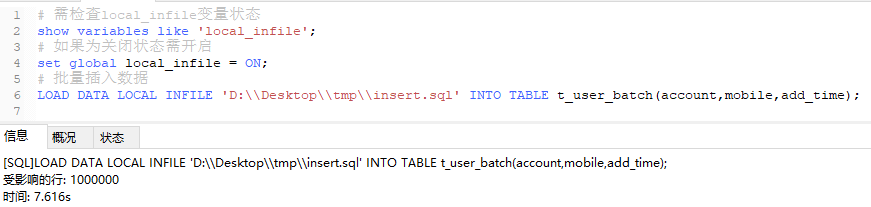
借助指令批量导入100w数据 =》大概需要 8s 左右
综上所述,通过这种指令导入的方式导入100w的数据只需要 10s 左右时间
指令方式导入可能存在的性能缺陷
(1)导入数据问题分析
t_limit 表定义:对比 t_user_batch 表,t_limit 表中定义了多个索引
# 参考示例表
CREATE TABLE t_limit (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
100 w 数据导入:通过指令的方式完成数据导入(基于t_limit 表),测试问题分析
- 导出100w t_limit 表SQL语句(数据导出耗时:7s 左右)
- 通过指令导入100w条数据(不知道为何,有时候直接执行耗时比预期多很多,且客户端一度卡住,强制停止会提示失败),需要优化导入配置
# 需确保指令的正确性,如果不小心对照了错误的表,就容易把其他表的数据冲掉(这是一个很严重的开发问题),一定要再三确认导入表的配置
# LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\insertTLimit.sql' INTO TABLE t_limit
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insertTLimit.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
# windows 下执行 执行耗时比预期多,一致卡住,强制停止后提示下述内容
[SQL]LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\insertTLimit.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
[Err] 2013 - Lost connection to MySQL server during query
因此此处不得不思考一个问题,基于LOAD DATA LOCAL INFILE这种方式的适用场景,如果说执行时长超出预期的话,说明在执行过程中还存在一些因素导致耗时很长,分析如下:
- 硬件性能不足:如果服务器的硬件配置不够强大,例如CPU、内存、硬盘等性能较低,导入大量数据时可能会影响性能。
- 网络问题:如果导入数据的文件存储在远程服务器上,那么网络延迟和带宽限制可能会导致导入速度变慢。
- 索引和约束:如果目标表上存在索引和约束,那么在导入数据时会增加额外的验证和更新操作,导致导入速度减慢。
- 数据文件格式:数据文件的格式和编码方式可能与MySQL的配置不匹配,导致导入速度变慢。
- 事务和日志:如果MySQL服务器的事务和日志配置不合理,导入数据时可能会产生大量的日志和回滚操作,影响导入速度
通过优化硬件性能、网络连接、禁用索引和约束、选择合适的数据文件格式与编码方式以及调整事务和日志配置等方式,可以提高MySQL Load Infile的导入速度。当然,具体的解决方案要根据实际情况进行调整,可以结合使用多种方法来达到最佳效果
优化硬件性能:如果服务器硬件性能不足,可以考虑升级硬件或增加服务器数量来提高性能。
优化网络连接:如果导入数据的文件存储在远程服务器上,可以尝试将文件复制到本地服务器上再进行导入,以减少网络延迟和带宽限制。
禁用索引和约束:在导入数据之前,可以考虑禁用目标表上的索引和约束(注意不同存储引擎的处理),导入完成后再重新启用,以减少验证和更新操作,提高导入速度(有些场景的硬核做法是导入数据前只构建纯粹的“单表”,通过先删除掉所有的相关索引,在导入数据后再重新创建,但需注意一旦导入大数据量的数据,索引重新构建也是需要一定的时间成本消耗,需结合实际场景参考使用)
-- 1.针对Myisam类型的表 # 导入前暂时禁用索引和约束,避免额外的检查耗时 ALTER TABLE `table_name` DISABLE KEYS; ALTER TABLE `table_name` DISABLE TRIGGER; # 在导入完成后,记得重新启用索引和约束: ALTER TABLE `table_name` ENABLE KEYS; ALTER TABLE `table_name` ENABLE TRIGGER; -- 2.针对InnoDB类型的表 # 导入数据前关闭唯一性校验 SET UNIQUE_CHECKS=0; # 在导入结束后恢复唯一性校验 SET UNIQUE_CHECKS=1;选择合适的数据文件格式与编码方式:根据MySQL的配置,选择合适的数据文件格式和编码方式,以提高导入速度。一般情况下,使用文本文件格式(如CSV)和UTF-8编码会比较高效
调整事务和日志配置:根据导入数据的特点,可以适当调整MySQL服务器的事务和日志配置,以减少日志和回滚操作。具体的调整方式可以查阅MySQL官方文档
(2)测试方案
导入配置优化方案分析
此处基于场景分析,考虑到测试时对 t_limit 中的涉及字段比较多、且字段设置了比较多的索引,优先优化这个方案看是否可以解决耗时问题,实际测试的时候需要确认插入数据表的存储引擎,选择合适的方案进行数据导入(由于win10 MySQL-8.0.21导入太卡了、此处使用MAC、MySQL5.7.44版本进行测试(WIN版本也可直接测试,此处只是因个人需求切换了一下开发环境))
此外需排除上面的案例中优化配置的影响(因此在测试的过程中,一开始是发现执行异常的慢,但有时又莫名其妙的变好了,主要原因是因为在前面的优化案例中有些方案是后续查找资料补充的,有些修改变量的环境是针对全局的,所以有时候测着测着就会发现好像环境又好了,无法准确对比优化效果),因此在测试的时候对比组一定要严格控制变量,此处的测试思路调整为:
- 原表没有数据时:默认直接插入、优化配置后插入(单个配置优化、组合配置优化)
- 原表已有数据时:默认直接插入、优化配置后插入(单个配置优化、组合配置优化)
测试的时候注意检查单个配置是否正常生效,且每次执行完成需确认数据是否生成成功,并在测试前通过truncate指令清空表数据
# 查看生成数据
explain select * from t_limit;
# 清空表数据
truncate t_limit;
# 查看锁状态
SELECT * FROM performance_schema.data_locks;
# 查询是否锁表
SHOW OPEN TABLES WHERE in_use >0
# 查看当前进程
show processlist;
其次,由于在测试 t_limit 表数据批量插入的时候,经常等不及就会忍不住手动停止关闭执行,导致一些操作被中断,然后再次执行就直接卡死,考虑是表被锁住了。可以通过检查锁状态确认要操作的表是否被锁住,如果被锁住则进行手动解锁。
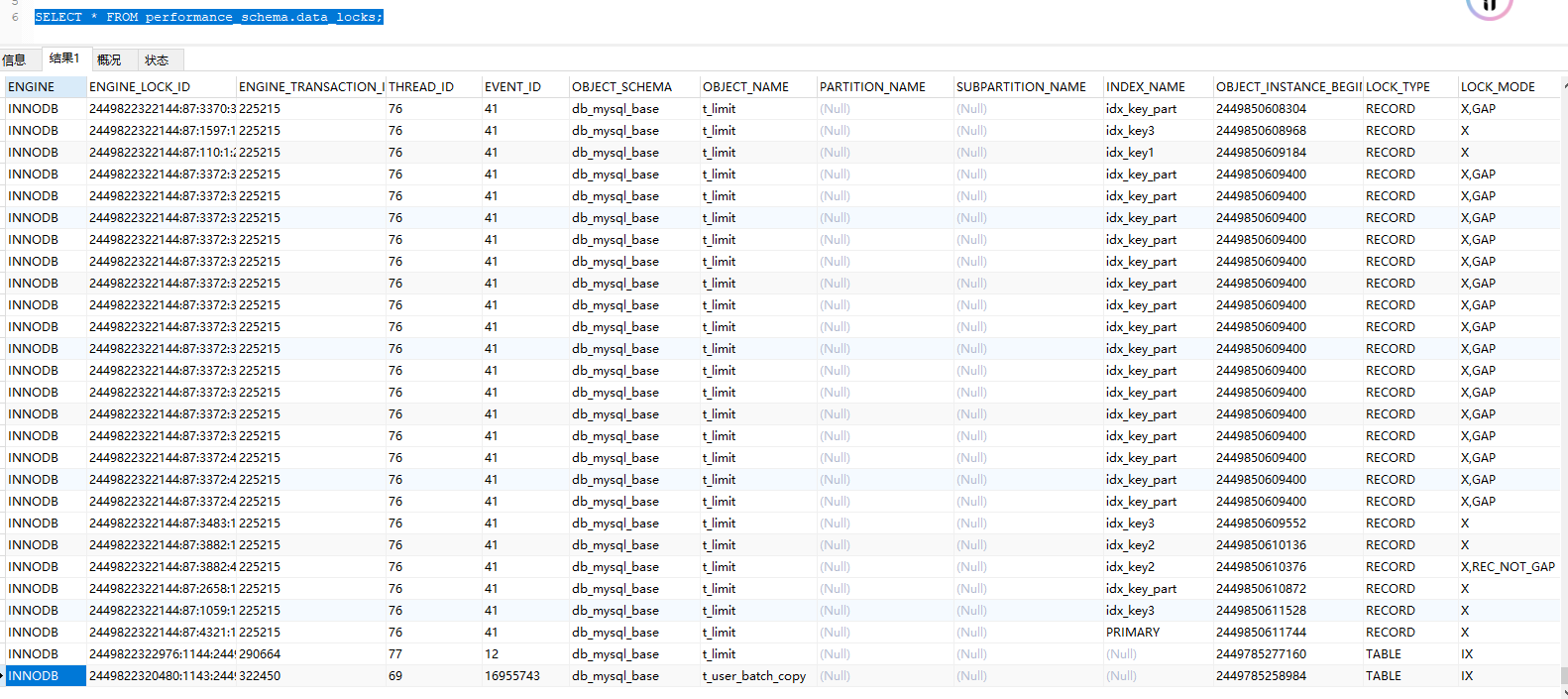
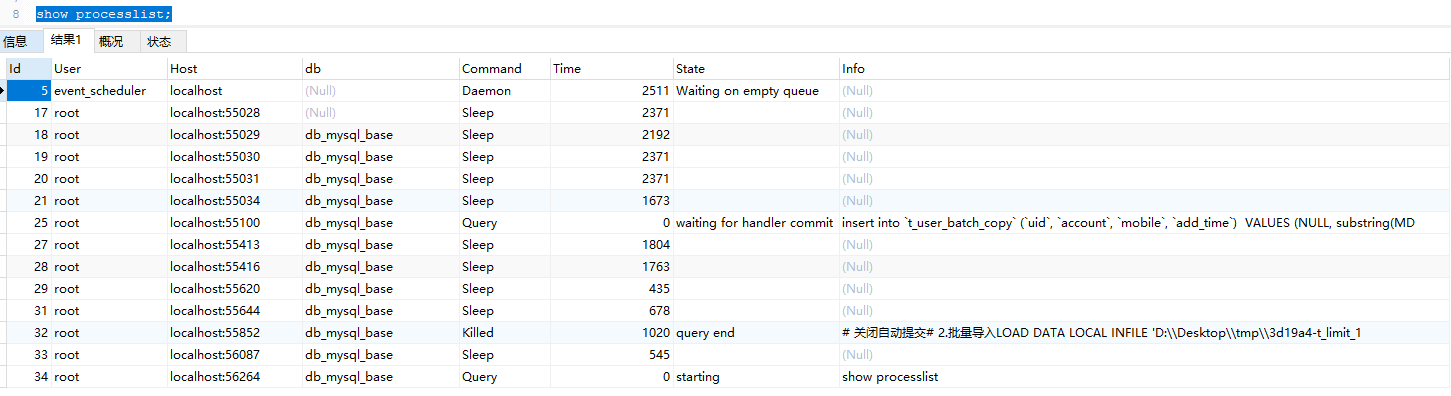
如果直接kill不掉线程,则试着手动重启MySQL服务(手动重启失败的话直接杀掉进程后重启服务)(生产环境不建议这样操作,此处仅仅是为了快速测试采取的终极方案,对于数据库中死锁的处理要掌握的内容绝不仅限于此),如要解决锁问题还需进一步了解锁机制和死锁解决方案。
还有一种检查执行过程是否卡住的技巧,当执行批量导入脚本的时候会发现执行特别慢,这个时候可以开启另一个新的查询窗口执行查询语句explain select * from t_limit;(因为指定的刷盘方式是边写边读,所以每次执行的话正常来说是不断插入数据的,rows也会不断增长),如果发现rows不动了则可确认是否执行完成
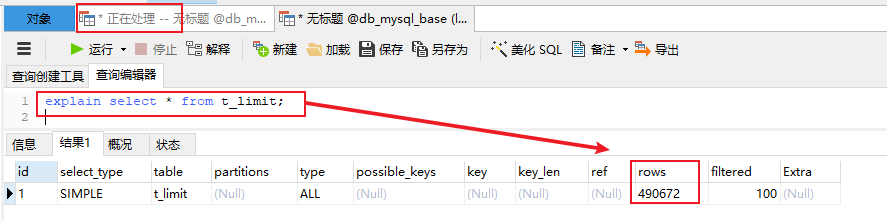
(3)WIN 10 & MySQL-8.0.21版本批量插入性能测试
🏐 优化配置测试
执行脚本
# 1.导入数据前设置优化配置
set global innodb_flush_log_at_trx_commit = 0; # 调整刷盘方式
set bulk_insert_buffer_size = 16 * 1024 * 1024; # 调整为16M
SET UNIQUE_CHECKS= OFF; # 关闭唯一性校验
SET AUTOCOMMIT = OFF; # 关闭自动提交
# 2.批量导入
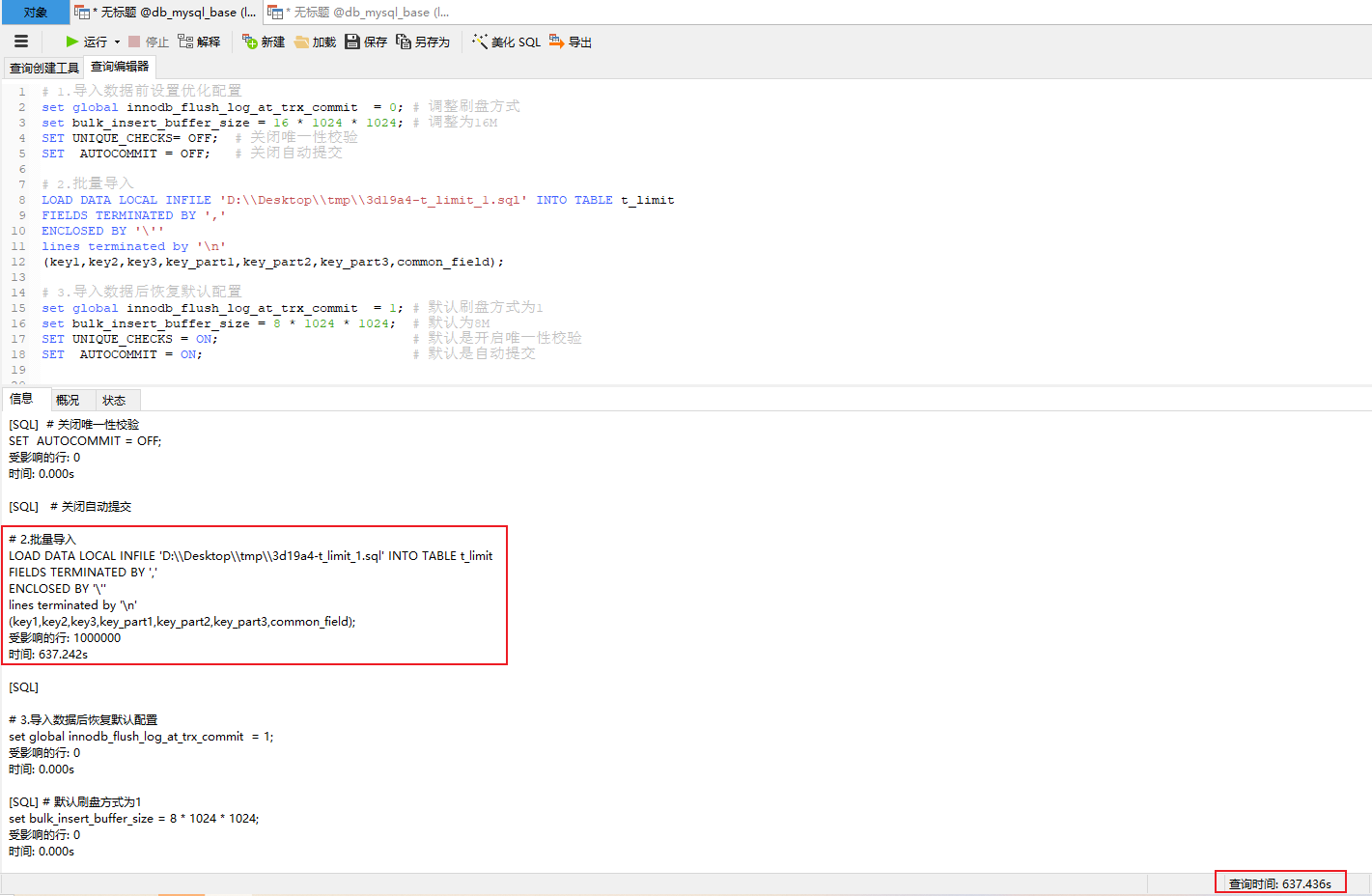
LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\3d19a4-t_limit_1.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
commit;
# 3.导入数据后恢复默认配置
set global innodb_flush_log_at_trx_commit = 1; # 默认刷盘方式为1
set bulk_insert_buffer_size = 8 * 1024 * 1024; # 默认为8M
SET UNIQUE_CHECKS = ON; # 默认是开启唯一性校验
SET AUTOCOMMIT = ON; # 默认是自动提交
执行结果:10min +
由于数据批量操作耗费时间太长,将单批设置为50w,优化配置前执行大概需要245s左右,优化配置后执行大概需要219.3s左右。从数据上来看并没有想象中特别大的提升,包括在后续的基于MAC&MySQL-5.7.44版本中多种场景测试,整体导入时耗好像有减少,但并没有太明显
🏐 删除索引后重建
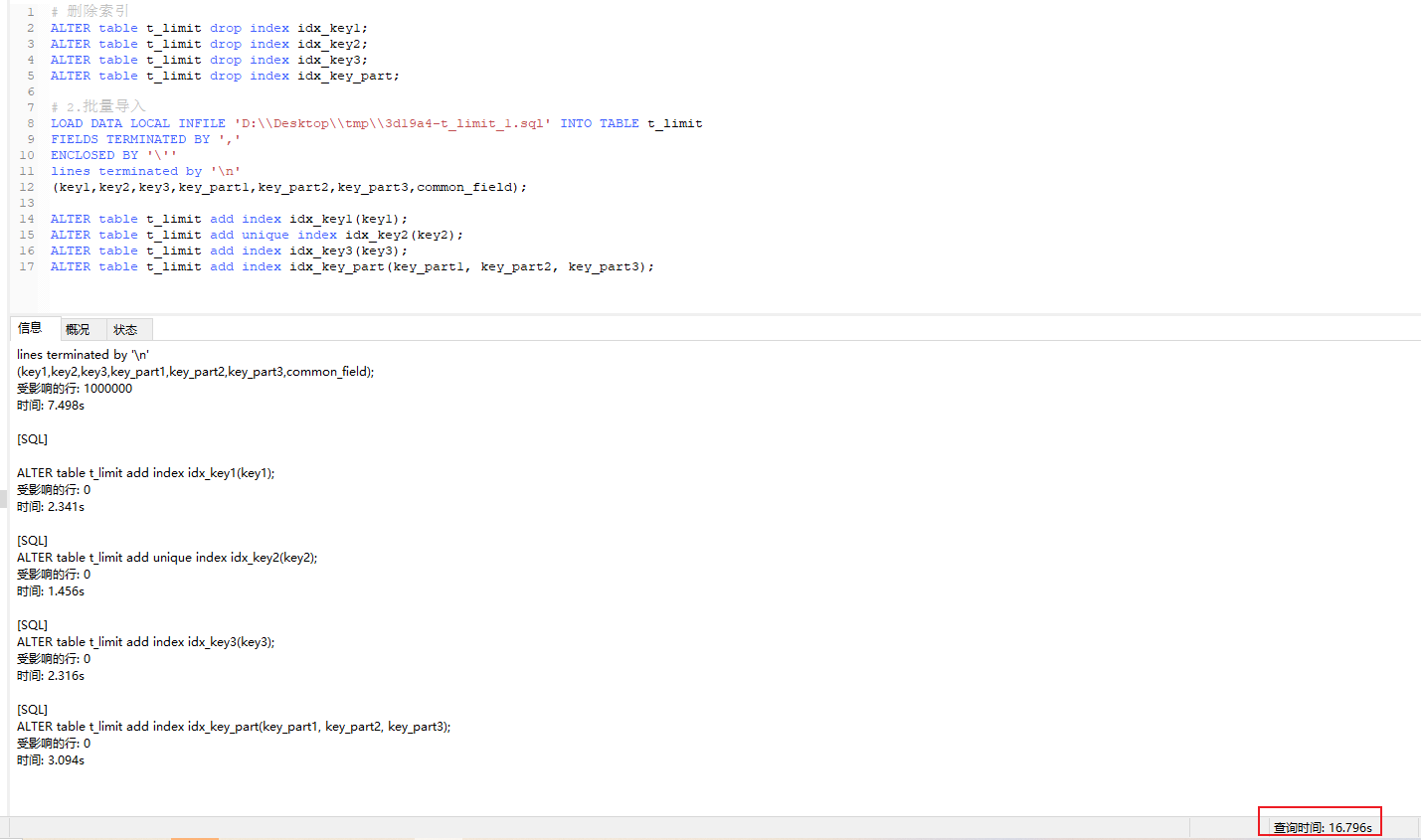
执行脚本
# 删除索引
ALTER table t_limit drop index idx_key1;
ALTER table t_limit drop index idx_key2;
ALTER table t_limit drop index idx_key3;
ALTER table t_limit drop index idx_key_part;
# 2.批量导入
LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\3d19a4-t_limit_1.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
ALTER table t_limit add index idx_key1(key1);
ALTER table t_limit add unique index idx_key2(key2);
ALTER table t_limit add index idx_key3(key3);
ALTER table t_limit add index idx_key_part(key_part1, key_part2, key_part3);
执行结果:总体耗时16.8s,其中批量插入:7.498s、4个索引重建先后分别耗时2.341s、1.456s、2.316s
(4)MAC & MySQL-5.7.44版本批量插入性能测试
🏐 优化配置测试
测试场景1:原表没有数据时:数据导入处理测试
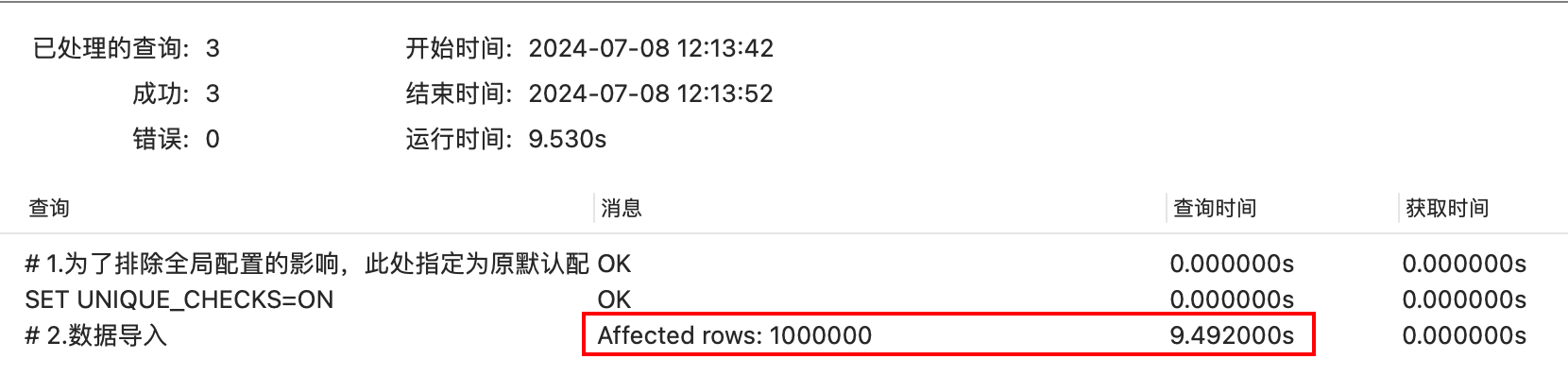
- 方式1:直接导入 =》100w数据导入需9.5s
# 1.为了排除全局配置的影响,此处指定为原默认配置innodb_flush_log_at_trx_commit(默认为1)、UNIQUE_CHECKS(默认开启)
set global innodb_flush_log_at_trx_commit = 1;
SET UNIQUE_CHECKS=ON;
show variables like 'innodb_flush_log_at_trx_commit';
show variables like 'UNIQUE_CHECKS';
# 2.数据导入
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insertTLimit.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
- 方式2:优化配置后导入(修改innodb_flush_log_at_trx_commit参数为0) =》100w数据导入需9.43s
# 1.优化配置:
set global innodb_flush_log_at_trx_commit = 0;
SET UNIQUE_CHECKS=ON;
show variables like 'innodb_flush_log_at_trx_commit';
show variables like 'UNIQUE_CHECKS';
# 2.数据导入
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insertTLimit.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
# 3.恢复配置
set global innodb_flush_log_at_trx_commit = 1;
SET UNIQUE_CHECKS=ON;

- 方式3:优化配置后导入(关闭索引校验)=》100w数据导入需9.38s
# 1.优化配置:
set global innodb_flush_log_at_trx_commit = 1;
SET UNIQUE_CHECKS=OFF;
show variables like 'innodb_flush_log_at_trx_commit';
show variables like 'UNIQUE_CHECKS';
# 2.数据导入
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insertTLimit.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
# 3.恢复配置
set global innodb_flush_log_at_trx_commit = 1;
SET UNIQUE_CHECKS=ON;
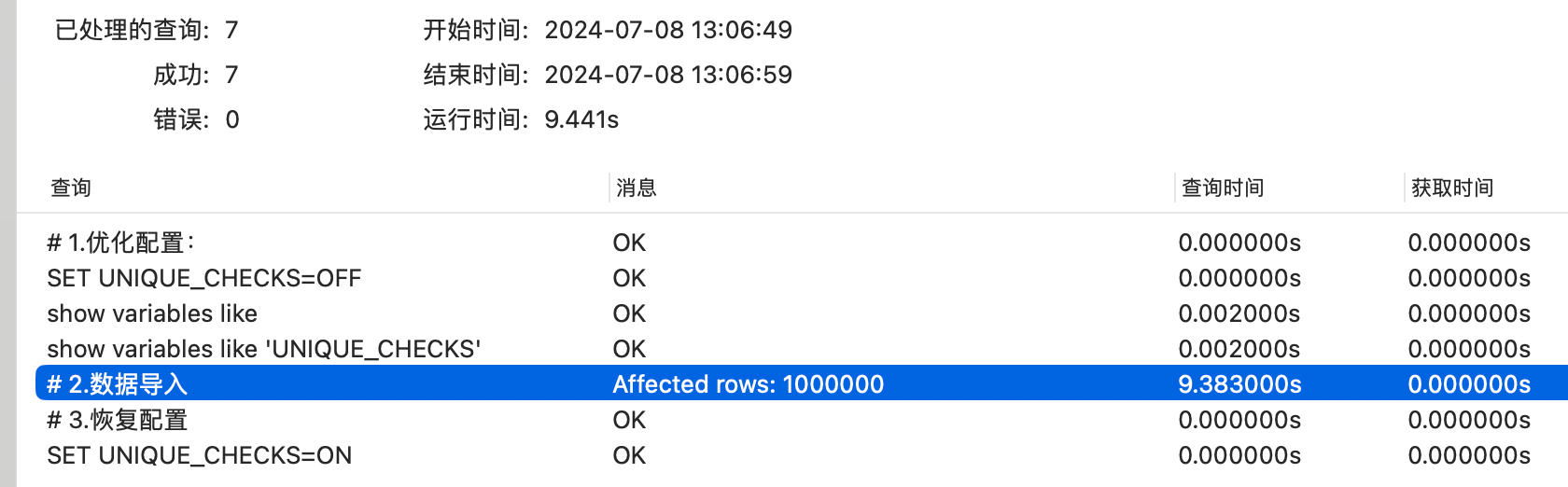
- 方式4:优化配置后导入(设置innodb_flush_log_at_trx_commit参数、关闭索引校验)=》100w数据导入需8.93s
-- 1.数据导入优化配置
# 优化配置:修改innodb_flush_log_at_trx_commit为0
set global innodb_flush_log_at_trx_commit = 0;
# 导入数据前关闭唯一性校验
SET UNIQUE_CHECKS=0;
show variables like 'innodb_flush_log_at_trx_commit';
show variables like 'UNIQUE_CHECKS';
-- 2.执行数据导入操作
# 数据导入
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insertTLimit.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
-- 3.恢复配置
# 在导入结束后恢复配置
set global innodb_flush_log_at_trx_commit = 1;
# 在导入结束后恢复唯一性校验
SET UNIQUE_CHECKS=1;
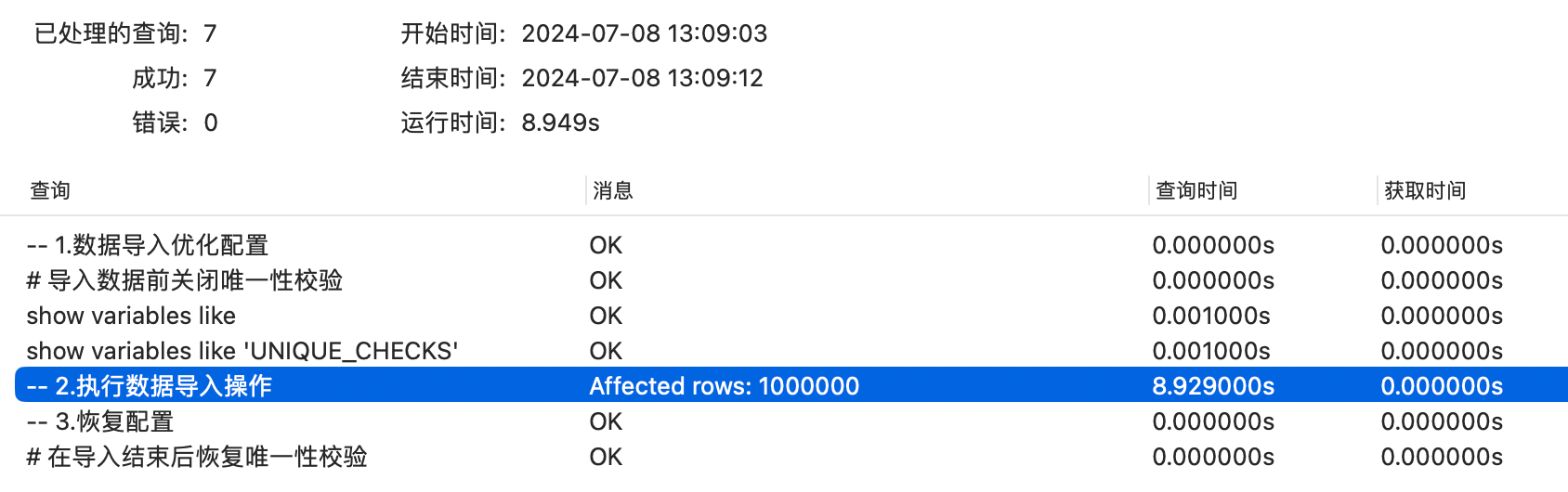
综合上述结果可以看到,虽然设定了相关配置,但是数据导入的性能好像并没有得到特别明显的提升,接下来测试一下如果要导入的表中本来就存在数据的场景进行分析(为避免唯一字段冲突,需通过生成多份数据文本进行测试),测试思路还是基于上述场景,此处省略测试的脚本文件说明(参考场景1的测试脚本,调整要导入的数据文本路径即可),直接展示测试结果
测试场景2:t_limit 表已有100w数据,再插入100w数据(准备两个sql文件测试:insertTLimit01.sql(1-100w)insertTLimit02.sql(100w-200w))
- 方式1:直接导入 =》追加100w数据导入需38.94s
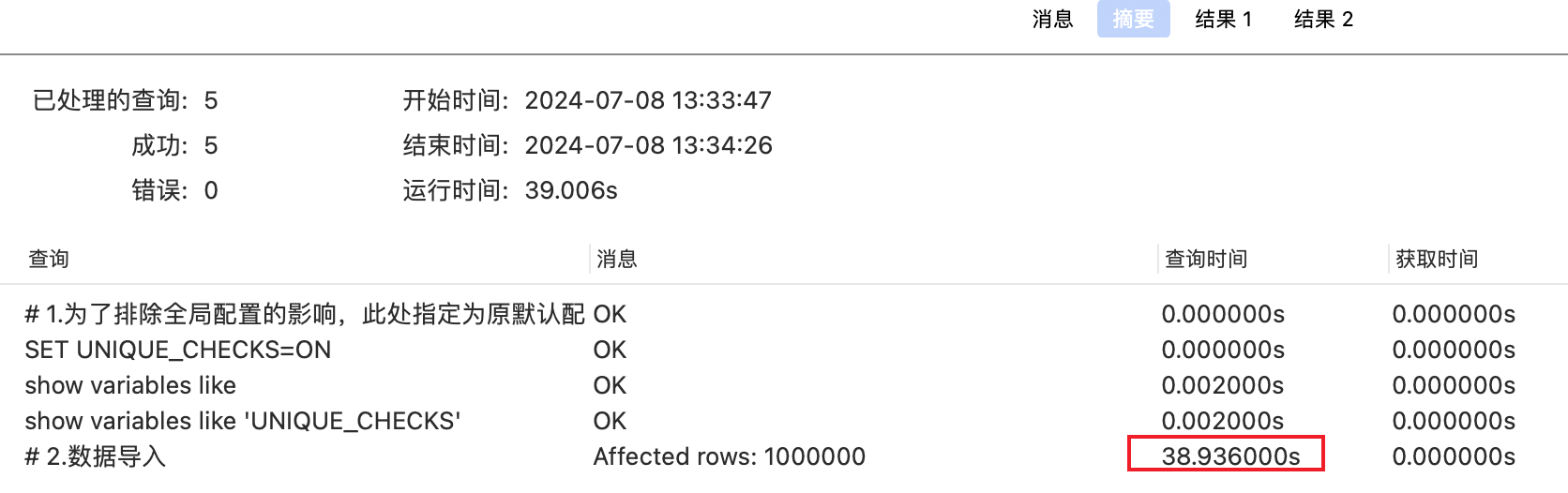
- 方式2:优化配置后导入(修改innodb_flush_log_at_trx_commit参数为0) =》追加100w数据导入需38.17s

- 方式3:优化配置后导入(关闭索引校验)=》追加100w数据导入需38.20s

- 方式4:优化配置后导入(设置innodb_flush_log_at_trx_commit参数、关闭索引校验)=》追加100w数据导入需37.80s
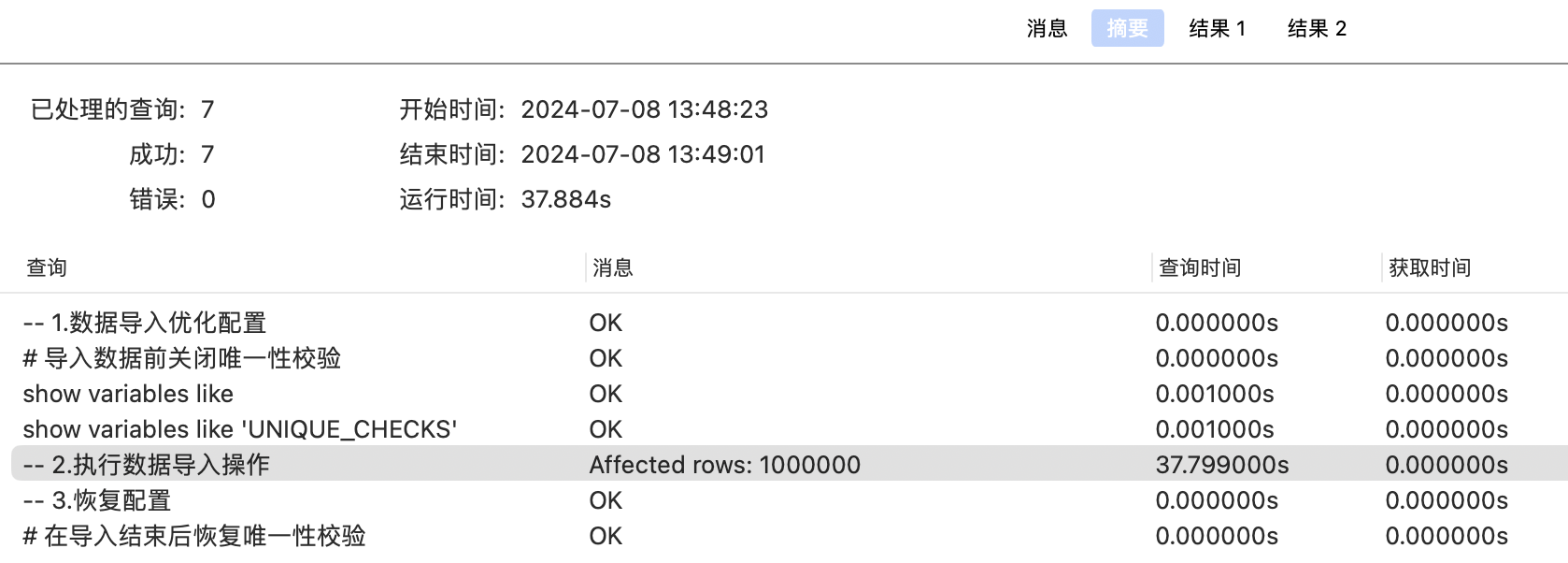
🏐 删除索引后重建
构建思路:先导入数据,后创建索引(思路参考下述5000w的案例导入)
测试环境:MAC & MySQL-5.7.44
基于这种方案是建表的时候将所有相关索引进行删除,然后待数据导入之后再重新创建索引。
# 删除索引
ALTER table t_limit drop index idx_key1;
ALTER table t_limit drop index idx_key2;
ALTER table t_limit drop index idx_key3;
ALTER table t_limit drop index idx_key_part;
# 2.批量导入
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insertTLimit01.sql' INTO TABLE t_limit
FIELDS TERMINATED BY ','
ENCLOSED BY '\''
lines terminated by '\n'
(key1,key2,key3,key_part1,key_part2,key_part3,common_field);
ALTER table t_limit add index idx_key1(key1);
ALTER table t_limit add unique index idx_key2(key2);
ALTER table t_limit add index idx_key3(key3);
ALTER table t_limit add index idx_key_part(key_part1, key_part2, key_part3);
100w 的数据导入测试
数据生成说明:pageNum(文件编号:第几个文件,从1开始)、pageSize(单批记录大小)
- 第1个100w:http://localhost:8101/api/exportInsertTLimitSQL?pageNum=1&pageSize=1000000
- 第2个100w:http://localhost:8101/api/exportInsertTLimitSQL?pageNum=2&pageSize=1000000
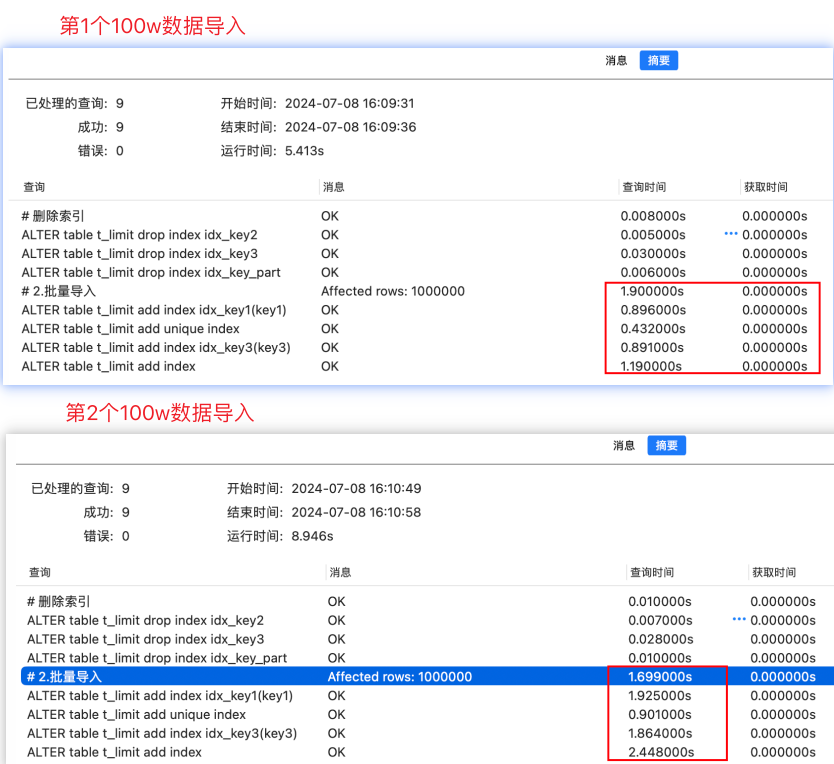
结合测试结果进行分析:虽然每次单次导入数据的时间持恒,但是索引重建的时间占据大头
- 第1个100w数据导入:总耗时5.41s,数据导入耗时1.9s,索引重建占据大部分时间
- 第2个100w数据导入:总耗时8.946s,数据导入耗时1.7s,索引重建占据大部分时间
1000w 的数据导入测试
数据生成说明:pageNum(文件编号:第几个文件,从1开始)、pageSize(单批记录大小)
- 第1个1000w:http://localhost:8101/api/exportInsertTLimitSQL?pageNum=1&pageSize=10000000
- 第2个1000w:http://localhost:8101/api/exportInsertTLimitSQL?pageNum=2&pageSize=10000000
执行上述脚本(调整导入的文件路径、名称),确认数据插入操作。两次导入的执行结果分析如下:
- 第1次导入:总耗时54.41s,SQL插入耗时16.96s
- 第2次导入:总耗时94.30s,SQL插入耗时16.43s
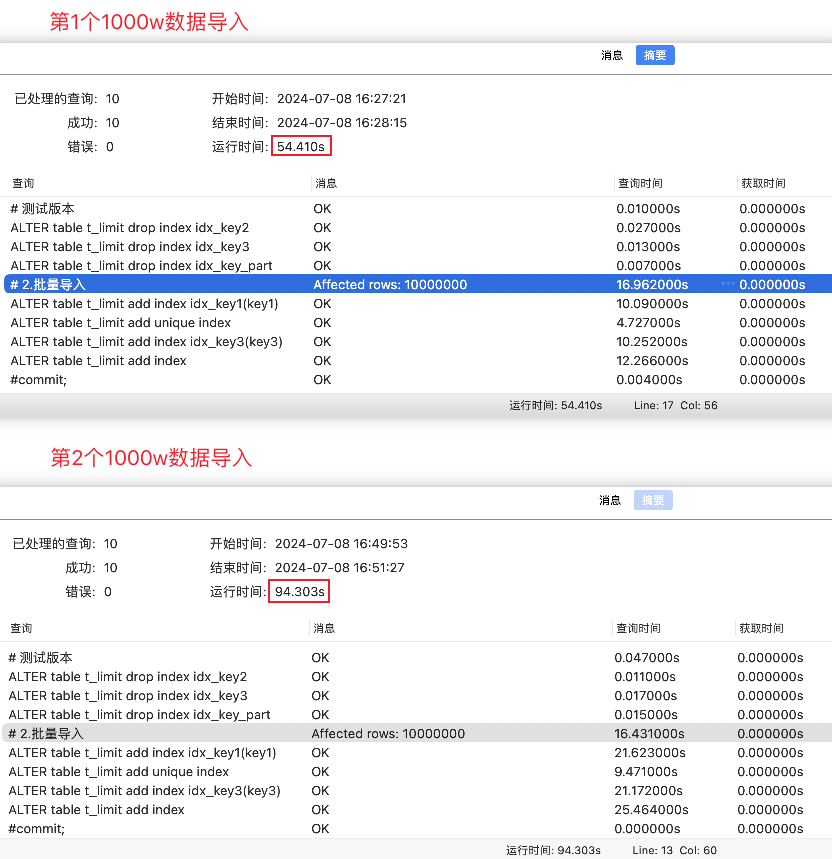
基于上述结果测试可知,实际上通过”重建索引“这个思路来辅助大批量数据导入的场景中需要注意:
- 尽量按照一定顺序导入数据(例如按照主键顺序等)
- 必须满足索引需求
- 一般场景下是数据怎么导出来就怎么导进去即可
- 如果是自造数据则关注一些索引的需求,因为执行顺序是先删除索引、导入数据、重建索引,所以在插入数据的时候并不会做校验,如果因为自造数据和索引定义冲突,那么在重建索引的时候就会报错
其次可以观察到当来到数据导入后期(当不断分批往表中插入数据,表中数据量不断增加时),实际上数据导入的成本消耗中索引重建已经占据了大头,而真正执行单次导入的消耗成本反而是持恒的(它只和单次导入的数据量有关,这点可以通过后面5000w的数据案例进行验证)。目前只是1000w的数据测试,当数据表的数据量达到一定的量级时,可想而知这个索引重建的成本消耗是多么恐怖
5000w数据处理(基于t_user_batch表)
分批生成数据代码参考GenBatchDataTest => batchGenTUserBatchToSQL()
# 1.需检查local_infile变量状态
show variables like 'local_infile';
# 如果为关闭状态需开启
set global local_infile = ON;
# 2.执行指令批量导入数据
# LOAD DATA LOCAL INFILE 'D:\\Desktop\\tmp\\insert.sql' INTO TABLE t_user_batch(account,mobile,add_time);
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/insert.sql' INTO TABLE t_user_batch
FIELDS TERMINATED BY ','
lines terminated by '\n'
(account,mobile,add_time);
WIN10 & MySQL-8.0.21 测试结果
数据导出:如果一次性导出5000w的数据会很卡(涉及到资源占用的问题,它的执行耗时也并不是10 * 50这么简单),因此对于大数据量的导出也是采取分批的思路导出,将5000w的数据分拆到多个文件中存储然后执行。参考下述,如果一次性导入5000w数据到单个文件,就会出现程序整个卡死,并最终抛出OOM异常

- 直接导出5000w条数据,卡死,并抛出OOM
- 批量导出5000w条数据耗时:36s 每批处理数量为:100w; 单个文件导入7.269s,需要导入50个文件 =》6.66 min
- 批量导出5000w条数据耗时:42s 每批处理数量为:200w; 单个文件导入14.882s,需要导入25个文件 =》6.90 min
- 批量导出5000w条数据耗时:68s 每批处理数量为:500w; 单个文件导入37.905s,需要导入10个文件 =》7.45 min
- 批量导出5000w条数据耗时:82s 每批处理数量为:1000w;单个文件导入88.826s,需要导入5个文件 =》8.77 min
结合上述实践结果分析,并不是单批数量导出越多越好,单个文件如果过大,程序处理需要占用大量资源,如果超过限制则可能会抛出OOM异常。因此要结合实际场景应用和资源配置选择合适的分批大小来达到最优的性能。除此之外,虽然单个导入需要一定时间,可以看到批量导入的效率基本持衡(中间没有太大的耗时跨度,基本是和数据导入量成一定比例),因此一方面是考虑模拟优化生成数据耗时(这部分其实也不占大头,且分批size小则意味着需要处理的文件数量也多,反之分批size大则意味着需要处理的文件数量少,如此看来这部分的时间差基本可以忽略不计),一方面则是考虑如何进一步优化数据批量导入的效率(如果说在不考虑其他硬件配置调整的情况下,只能尽量通过调整MySQL参数来达到优化数据导入效率的目的)
MAC & MySQL-5.7.44 测试结果
- 批量导出5000w条数据耗时:43s 每批处理数量为:100w; 单个文件导入耗时(1.3s - 1.7s),需要导入50个文件 =》平均耗时 1.97 min
- 批量导出5000w条数据耗时:41s 每批处理数量为:200w; 单个文件导入(2.8s-3.0s),需要导入25个文件 =》平均耗时 1.89 min
- 批量导出5000w条数据耗时:34s 每批处理数量为:500w; 单个文件导入(6.4s-6.7s),需要导入10个文件 =》平均耗时 1.66 min
- 批量导出5000w条数据耗时:34s 每批处理数量为:1000w;单个文件导入(12.7s-12.9s),需要导入5个文件 =》平均耗时 1.63 min
为什么t_user_batch批量插入每次导入同样的数据量都是执行时间都是差不多的?主要是因为t_user_batch够简单,除了主键自增它并没有其他的索引,因此也无需额外指定设置禁用唯一性校验等,每次直接执行指令导入相同数据量的前提下执行时间都是差不多的,因此它的耗时可以用【单个文件耗时】*【文件个数】来进行估算。
# 优化后配置:此处t_user_batch比较简单,执行优化后配置和优化前的效果是类似的,本质上没有多大提升
# 1.导入数据前设置优化配置
set global innodb_flush_log_at_trx_commit = 0; # 调整刷盘方式
set bulk_insert_buffer_size = 16 * 1024 * 1024; # 调整为16M
SET UNIQUE_CHECKS= OFF; # 关闭唯一性校验
SET AUTOCOMMIT = OFF; # 关闭自动提交
# 2.批量导入
LOAD DATA LOCAL INFILE '/Users/holic-x/tmp/f407b8-insertUserBatch5.sql' INTO TABLE t_user_batch
FIELDS TERMINATED BY ','
lines terminated by '\n'
(account,mobile,add_time);
commit;
# 3.导入数据后恢复默认配置
set global innodb_flush_log_at_trx_commit = 1; # 默认刷盘方式为1
set bulk_insert_buffer_size = 8 * 1024 * 1024; # 默认为8M
SET UNIQUE_CHECKS = ON; # 默认是开启唯一性校验
SET AUTOCOMMIT = ON; # 默认是自动提交
3.借助客户端导入
例如此处可借助Navicat导入不同类型的文本数据,例如一般数据处理场景下在服务器端通过数据采集的方式将数据存储到文本中,然后通过特定符号(一般是唯一符号、不影响业务字段的符号)将每个实体属性进行分割,然后再从中获取相应的业务字段进行处理。
此处可以调整【方案2】中的数据导出方法,导出特定格式的文本文件,然后通过Navicat客户端进行导入操作(按照相应的导入向导)
public void batchGenTUserBatchToTxt() throws Exception {
List<TUserBatch> tUserBatchList = RandomGenEntityUtil.genTUserBatch(1000000);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 封装SQL文本信息
List<String> insertList = new ArrayList<>();
String split = ",";
tUserBatchList.forEach(tUserBatch -> {
// 拼接SQL语句
StringBuffer insertSql = new StringBuffer();
// 主键自增
insertSql.append(tUserBatch.getAccount() + split)
.append(tUserBatch.getMobile() + split)
.append(sdf.format(tUserBatch.getAdd_time()));
insertList.add(insertSql.toString());
});
// 写入文件
FileWriter writer = new FileWriter(new File("D:\\Desktop\\tmp\\insert.txt"));
insertList.forEach(insertSql -> {
try {
writer.write(insertSql + "\n");
} catch (IOException e) {
System.out.println("数据写入异常" + insertSql);
throw new RuntimeException(e);
}
});
// 关闭写入流
writer.close();
}
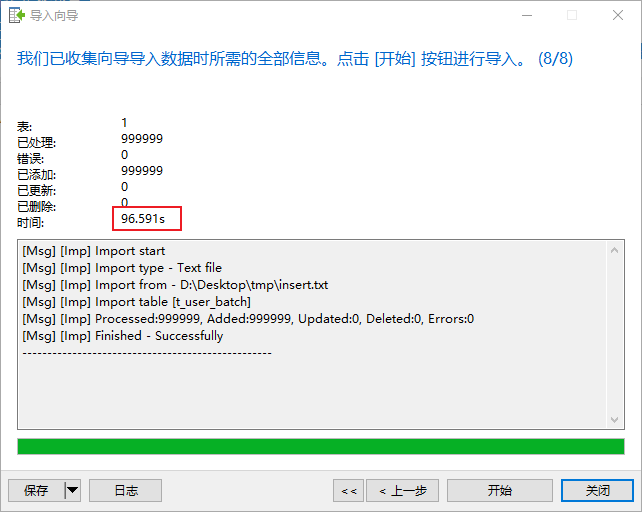
测试结果:利用Navicat 客户端导入数据的方式,插入100w的数据大概需要 96s
MyBatis-Plus数据批量(程序处理)
构建方案:借助程序完成数据批量插入操作(此处以java为示例参考)
参考数据表
# 参考示例表
CREATE TABLE t_limit (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
MyBatis-Plus数据批量插入到MySQL:基于t_limit表
构建Springboot项目,引入MyBatis-Plus框架,基于框架自动生成代码,借助其批量插入功能完成数据插入操作
@RequestMapping("/batchInsertTLimit1")
@ResponseBody
public String batchInsertTLimit1() {
long start = System.currentTimeMillis();
List<TLimit> limits = RandomGenEntityUtil.genTLimit(1000000);
// 批量插入(默认单次批量提交1000条数据)
// tLimitService.saveBatch(limits);
// 批量插入(指定batchSize为10000)
tLimitService.saveBatch(limits,50000);
long end = System.currentTimeMillis();
System.out.println("数据批量插入耗时:" + (end - start) / 1000 + "s");
return "success";
}
单线程插入10w条数据,MyBatis的数据批量插入是分批操作,在不介入事务管理,会将记录主动分批执行(每次批量插入操作插入1000条数据)都会插入并提交),耗时:35s
单线程插入100w条数据,单批操作:1000条数据,耗时:931s
插入100w条数据,可通过适当加大分批size来提升批量插入效率:tLimitService.saveBatch(limits,50000);,耗时:772s
在测试批量插入100w 远程MySQL服务器(腾讯云服务)的时候,发现就算是单次批量插入1000条,执行的速度也是非常慢的(可能是有其他因素阻塞,后续对于远程的MySQL服务的数据插入需要进一步测试),因此在实际业务场景中不仅仅要考虑批量数据的处理,还要考虑其他外在因素(例如网络连接等等)的影响
数据批量操作总结
综合上述数据批量操作方案测试结果说明,主要介绍了4种MySQL批量数据导入(即模拟数据生成)的方式,每种方案都有其各自的适用场景和导入优化的方案,此处简单对每个方式进行总结:
- 方式1:存储过程
- 数据模拟生成:通过MySQL函数模拟生成随机数据
- 存储过程调用:调用存储过程实现数据批量插入
- 优化:在函数调用消耗成本一定的场景下,可通过设定优化配置提升数据批量导入效率(例如禁用唯一性校验、禁用自动提交、设定刷盘方式、加大批量插入缓存等)
- 方式2:通过
LOAD DATA LOCAL INFILE:- 数据模拟生成:通过JAVA程序或者其他语言模拟批量生成数据
LOAD DATA LOCAL INFILE:它是MySQL提供的批量插入指令,它的批量插入效率会比单条insert语句执行要高。场景中也可通过优化配置来提升数据批量导入效率,其优化思路可以有两种:- 调整相关优化配置=》插入数据=》复原相关优化配置(大部分的参考方案是通过先禁用索引、导入数据、后启用索引,但实际上好像并没有起到多大的效率提升,据部分资料支撑,该命令在导入数据时,并不会自动地忽略索引,也就是说即使使用了
LOAD DATA LOCAL INFILE命令导入数据,数据库在导入过程中仍然会对新插入的数据行进行索引更新,进而导致数据批量导入巨慢) - 删除索引=》插入数据=》重建索引 (推荐方案)
- 调整相关优化配置=》插入数据=》复原相关优化配置(大部分的参考方案是通过先禁用索引、导入数据、后启用索引,但实际上好像并没有起到多大的效率提升,据部分资料支撑,该命令在导入数据时,并不会自动地忽略索引,也就是说即使使用了
- 方式3:客户端导入
- 数据模拟生成:通过JAVA程序或者其他语言模拟批量生成数据
- 借助Navicat等客户端工具提供的可视化功能入口完成数据批量导入(需要解析文件、导入文件),导入效果反而没有方式1、方式2灵活有效
- 方式4:借助程序代码批量生成数据并导入(此处通过构建springboot + MyBatis-plus 项目,调用批量新增方法模拟数据批量生成)
- 可通过指定batchSize来定义单次批量导入的大小,但需注意毕竟涉及到程序交互,其批量生成数据并导入还会受到一些资源或者网络调用等方面的影响
综上所述,对于造数据的场景而言,建议可以借助自己数据的程序语言模拟生成数据(从上述实践结果分析如果是使用MySQL函数,其执行效率远不如JAVA代码模拟生成数据),然后结合MySQL的批量数据导入方案搭配使用