🚀SQL慢查询&SQL优化
🚀SQL慢查询&SQL优化
SQL慢查询
排查步骤
【1】定位慢SQL
【2】慢SQL优化
show processlist =》 explain
【1】如何跟踪SQL慢查询
(1)确认是否开启了慢查询日志
show variables like "%slow%";,如未开启:set global slow_query_log = on;(全局session生效,重启MySQL后失效,如要永久生效需修改mysql.ini文件)
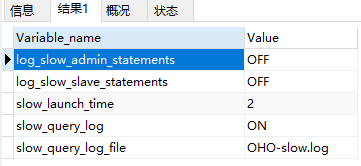
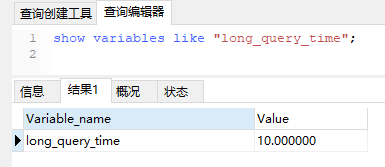
(2)确认慢查询时间限制(当操作时长大于该限制则认其为慢sql)
show variables like "long_query_time";
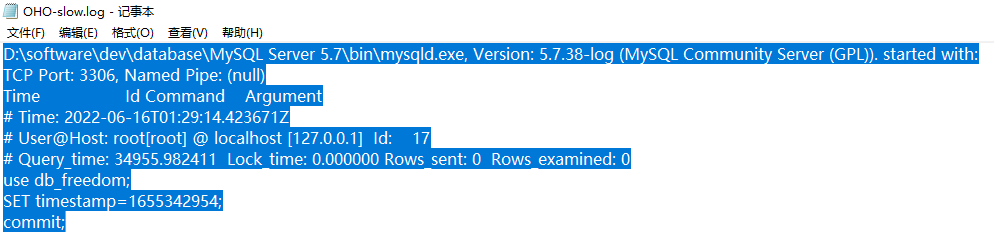
(3)通过慢查询日志(slow_query_log_file)定位具体的慢查询sql
Time :日志记录的时间
User@Host:执行的用户及主机
Query_time:查询耗费时间 Lock_time 锁表时间 Rows_sent 发送给请求方的记录条数 Rows_examined 语句扫描的记录条数
SET timestamp 语句执行的时间点
执行的语句
(4)慢查询跟踪(show status 显示mysql操作信息)
/* 获得mysql的插入次数; */
show status like "com_insert%";
/* 获得mysql的删除次数; */
show status like "com_delete%";
/* 获得mysql的查询次数; */
show status like "com_select%";
/* 获得mysql服务器运行时间; */
show status like "uptime";
/* 获得mysql连接次数; */
show status like 'connections';
/* 服务器启动以来执行时间最长的20条SQL语句; */
(5)explain分析SQL执行计划
explain select * from a;
// 一般跟踪索引相关(例如type、key、ref等)
id:选择标识符
select_type:表示查询的类型
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使⽤的索引
key:表示实际使⽤的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的⾏百分比
Extra:执行情况的描述和说明
【2】如何针对慢查询进行优化
(1)尽量避免子查询
(2)使用limit限制记录条数(例如如果确认只查1条就limit 1,当查找到记录后就不会继续往下而是直接返回)
(3)join连接操作尽量不要join超过三个表,多表关联查询需注意索引的引入
(4)避免select *的语法,而是根据业务需求筛选要输出的字段
(5)避免索引失效的一些场景(最左匹配原则,索引下推、使用聚合函数或者函数运算)
SQL优化
【1】SQL常见优化方案?实际业务场景如何处理SQL?
在做业务的时候,数据层会结合哪方面考虑?如何实现?
从数据定义=》数据存储=》数据检索=》数据维护各个维度扩展
结合实际业务进行数据库设计(表字段、字段类型),针对一些大文本字段、常用字段/不常用字段的一些拆分,业务关联的主外键关系
数据检索方面:结合数据库索引、索引失效场景、中间件缓存相关扩展
【2】SQL优化常用手段,结合实际业务需求进行说明
举例说明:如果一开始程序运行很快,但是一段时间后运行特别慢如何排查?
通过一些系统运行日志排查是否有一些进程阻塞导致系统访问缓慢?然后确认日常的一些编码规范,检查是否在编码过程中用到一些不规范的循环语句或者是一些数据库连接、文件资源连接没有得到及时的释放导致