Dubbo源码解读与实战
Dubbo源码解读与实战
学习核心
- ① Duboo Serialize 层:序列化算法
- ② Dubbo Remoting 层:核心接口分析,一套兼容所有NIO框架的设计
- ③ Buffer 缓冲区:数据的搬运工
- ④ Transporter 层核心实现:编解码、线程模型
- ⑤ Exchange层:Request-Response 模型
学习资料
① Duboo Serialize 层:序列化算法
学习核心
- 掌握序列化机制基础
- 常见序列化算法
- dubbo 默认的 hessian 算法机制接入剖析(
dubbo-serialization-hessian模块)
1.序列化机制
Java 的序列化操作一般有4个步骤:
① 被序列化对象需要实现
Serializable接口public class Student implements Serializable { private static final long serialVersionUID = 1L; private String name; private int age; private transient StudentUtil studentUtil; } 其中transient 关键字,它的作用就是:在对象序列化过程中忽略被其修饰的成员属性变量。一般情况下,它可以用来修饰一些非数据型的字段以及一些可以通过其他字段计算得到的值。通过合理地使用 transient 关键字,可以降低序列化后的数据量,提高网络传输效率
② 生成序列号
serialVersionUID③ 根据需求决定是否要重写 writeObject()/readObject() 方法,实现自定义序列化
④ 调用 java.io.ObjectOutputStream 的 writeObject()/readObject() 进行序列化与反序列化
Java 本身的序列化操作如此简单,但市面上还依旧出现了各种各样的序列化框架。因为这些第三方序列化框架的速度更快、序列化的效率更高,而且支持跨语言操作。
2.常见序列化算法
Apache Avro 是一种与编程语言无关的序列化格式。Avro 依赖于用户自定义的 Schema,在进行序列化数据的时候,无须多余的开销,就可以快速完成序列化,并且生成的序列化数据也较小。当进行反序列化的时候,需要获取到写入数据时用到的 Schema。在 Kafka、Hadoop 以及 Dubbo 中都可以使用 Avro 作为序列化方案。
FastJson 是阿里开源的 JSON 解析库,可以解析 JSON 格式的字符串。它支持将 Java 对象序列化为 JSON 字符串,反过来从 JSON 字符串也可以反序列化为 Java 对象。FastJson 是 Java 程序员常用到的类库之一,正如其名,“快”是其主要卖点。从官方的测试结果来看,FastJson 确实是最快的,比 Jackson 快 20% 左右,但是近几年 FastJson 的安全漏洞比较多,所以你在选择版本的时候,还是需要谨慎一些。
Fst(全称是 fast-serialization)是一款高性能 Java 对象序列化工具包,100% 兼容 JDK 原生环境,序列化速度大概是JDK 原生序列化的 4~10 倍,序列化后的数据大小是 JDK 原生序列化大小的 1⁄3 左右。目前,Fst 已经更新到 3.x 版本,支持 JDK 14。
Kryo 是一个高效的 Java 序列化/反序列化库,目前 Twitter、Yahoo、Apache 等都在使用该序列化技术,特别是 Spark、Hive 等大数据领域用得较多。Kryo 提供了一套快速、高效和易用的序列化 API。无论是数据库存储,还是网络传输,都可以使用 Kryo 完成 Java 对象的序列化。Kryo 还可以执行自动深拷贝和浅拷贝,支持环形引用。Kryo 的特点是 API 代码简单,序列化速度快,并且序列化之后得到的数据比较小。另外,Kryo 还提供了 NIO 的网络通信库——KryoNet,你若感兴趣的话可以自行查询和了解一下。
Hessian2 序列化是一种支持动态类型、跨语言的序列化协议,Java 对象序列化的二进制流可以被其他语言使用。Hessian2 序列化之后的数据可以进行自描述,不会像 Avro 那样依赖外部的 Schema 描述文件或者接口定义。Hessian2 可以用一个字节表示常用的基础类型,这极大缩短了序列化之后的二进制流。需要注意的是,在 Dubbo 中使用的 Hessian2 序列化并不是原生的 Hessian2 序列化,而是阿里修改过的 Hessian Lite,它是 Dubbo 默认使用的序列化方式。其序列化之后的二进制流大小大约是 Java 序列化的 50%,序列化耗时大约是 Java 序列化的 30%,反序列化耗时大约是 Java 序列化的 20%。
Protobuf(Google Protocol Buffers)是 Google 公司开发的一套灵活、高效、自动化的、用于对结构化数据进行序列化的协议。但相比于常用的 JSON 格式,Protobuf 有更高的转化效率,时间效率和空间效率都是 JSON 的 5 倍左右。Protobuf 可用于通信协议、数据存储等领域,它本身是语言无关、平台无关、可扩展的序列化结构数据格式。目前 Protobuf提供了 C++、Java、Python、Go 等多种语言的 API,gRPC 底层就是使用 Protobuf 实现的序列化。
3.dubbo-serialization
Dubbo 为了支持多种序列化算法,单独抽象了一层 Serialize 层,在整个 Dubbo 架构中处于最底层,对应的模块是 dubbo-serialization 模块
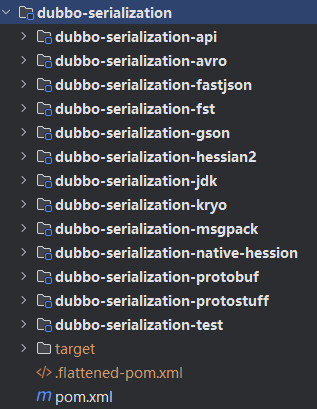
dubbo-serialization-api模块:定义了dubbo序列化层的核心接口。其中最核心的是Serialization这个扩展接口(被@SPI接口修饰),默认扩展实现是 Hessian2Serialization
@SPI("hessian2") // 被@SPI注解修饰,默认是使用hessian2序列化算法
public interface Serialization {
// 获取ContentType的ID值,是一个byte类型的值,唯一确定一个算法
byte getContentTypeId();
// 每一种序列化算法都对应一个ContentType,该方法用于获取ContentType
String getContentType();
// 创建一个ObjectOutput对象,ObjectOutput负责实现序列化的功能,即将Java对象转化为字节序列
@Adaptive
ObjectOutput serialize(URL url, OutputStream output) throws IOException;
// 创建一个ObjectInput对象,ObjectInput负责实现反序列化的功能,即将字节序列转换成Java对象
@Adaptive
ObjectInput deserialize(URL url, InputStream input) throws IOException;
}
Dubbo 提供了多个Serialization 接口实现,用于接入各种各样的序列化算法
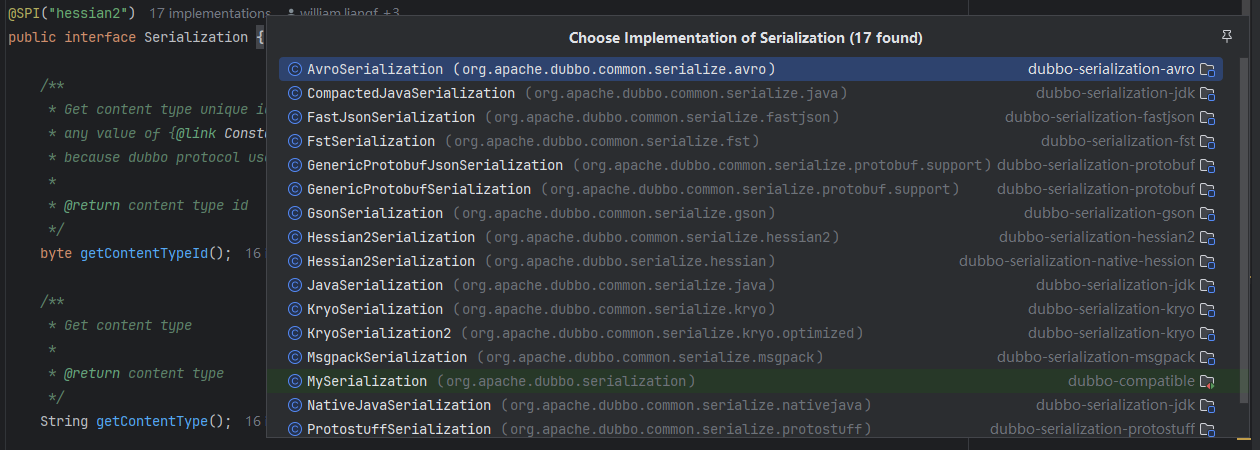
以默认的hessian2 序列化方式为例进行剖析:
public class Hessian2Serialization implements Serialization {
@Override
public byte getContentTypeId() {
return HESSIAN2_SERIALIZATION_ID; // hessian2的ContentType ID
}
@Override
public String getContentType() {
return "x-application/hessian2";// hessian2的ContentType
}
@Override
public ObjectOutput serialize(URL url, OutputStream out) throws IOException {
return new Hessian2ObjectOutput(out); // 创建ObjectOutput对象
}
@Override
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new Hessian2ObjectInput(is); // 创建ObjectInput对象
}
}
Hessian2Serialization 中的 serialize() 方法创建的 ObjectOutput 接口实现为 Hessian2ObjectOutput,继承关系如下图所示:
在 DataOutput 接口中定义了序列化 Java 中各种数据类型的相应方法,如下图所示,其中有序列化 boolean、short、int、long 等基础类型的方法,也有序列化 String、byte[] 的方法。而ObjectOutput 接口继承了 DataOutput 接口,并在其基础之上,添加了序列化对象的功能,具体定义如下图所示,其中的 writeThrowable()、writeEvent() 和 writeAttachments() 方法都是调用 writeObject() 方法实现的
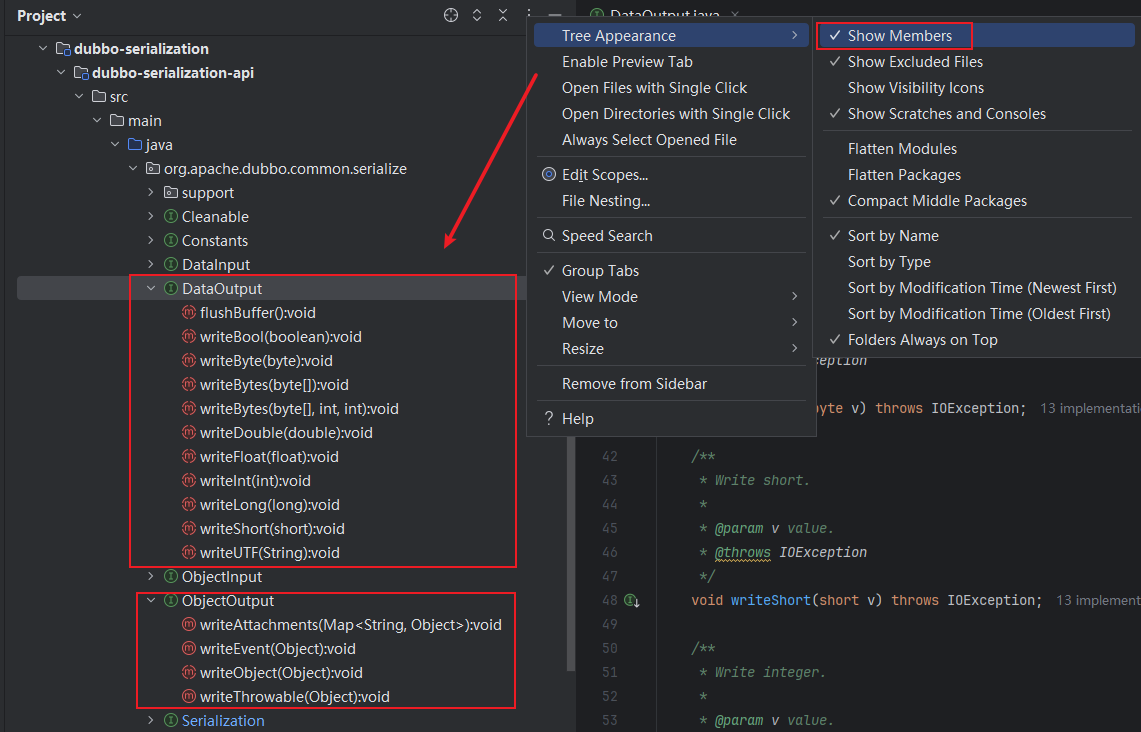
Hessian2ObjectOutput 中会封装一个 Hessian2Output 对象,需要注意,这个对象是 ThreadLocal 的,与线程绑定。在 DataOutput 接口以及 ObjectOutput 接口中,序列化各类型数据的方法都会委托给 Hessian2Output 对象的相应方法完成,实现如下
/**
* Hessian2 object output implementation
*/
public class Hessian2ObjectOutput implements ObjectOutput {
private static ThreadLocal<Hessian2Output> OUTPUT_TL = ThreadLocal.withInitial(() -> {
// 初始化Hessian2Output对象
Hessian2Output h2o = new Hessian2Output(null);
h2o.setSerializerFactory(Hessian2SerializerFactory.SERIALIZER_FACTORY);
h2o.setCloseStreamOnClose(true);
return h2o;
});
private final Hessian2Output mH2o;
public Hessian2ObjectOutput(OutputStream os) {
mH2o = OUTPUT_TL.get(); // 触发OUTPUT_TL的初始化
mH2o.init(os); // 初始化mH2o字段
}
@Override
public void writeObject(Object obj) throws IOException {
mH2o.writeObject(obj);
}
... // 省略序列化其他类型数据的方法
public OutputStream getOutputStream() throws IOException {
return mH2o.getBytesOutputStream();
}
}
同理,分析Hessian2ObjectInput,其具体实现实际和Hessian2ObjectOutput实现类似,只不过此处是基于反序列化的概念。 在 DataInput 接口中实现了反序列化各种类型的方法,在 ObjectInput 接口中提供了反序列化 Java 对象的功能,在 Hessian2ObjectInput 中会将所有反序列化的实现委托为 Hessian2Input。
类似地,其他序列化算法的设计思路也是基于这种设计模式构建,在了解了基础的Hessian序列化算法机制接入实现,可以举一反三去查阅其他算法的实现
② Dubbo Remoting 层:核心接口分析,一套兼容所有NIO框架的设计
学习核心
- dubbo-remoting 层 核心
- dubbo-remoting-api 核心架构分析(传输层核心接口)
- dubbo-remoting-* 子模块(对照不同通信组件(第三方网络库)的实现)
Dubbo 并没有自己实现一套完整的网络库,而是使用现有的、相对成熟的第三方网络库,例如,Netty、Mina 或是 Grizzly 等 NIO 框架。我们可以根据自己的实际场景和需求修改配置,选择底层使用的 NIO 框架
1.dubbo-remoting 基础架构
dubbo-remoting 包括 dubbo-remoting-api 接口模块 和其他子模块实现,其中每个子模块对应一个第三方NIO框架(例如dubbo-remoting-netty4子模块使用的是Netty4实现Dubbo的远程通信;dubbo-remoting-grizzly子模块使用的是Grizzly实现Dubbo的远程通信;包括借助Zookeeper实现注册中心的时候也有提到dubbo-remoting-zookeeper中使用Apache Curator实现和Zookeeper的交互)
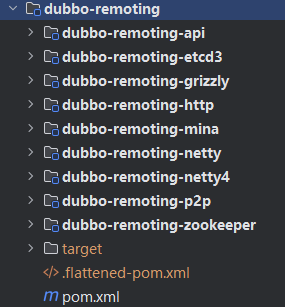
2.dubbo-remoting-api 模块
dubbo-remoting-api模块是其他dubbo-remoting-*子模块的顶层抽象,他提供了通信交互的基本接口,其他dubbo-remoting-*子模块都是依赖于第三方NIO库实现dubbo-remoting-api模块
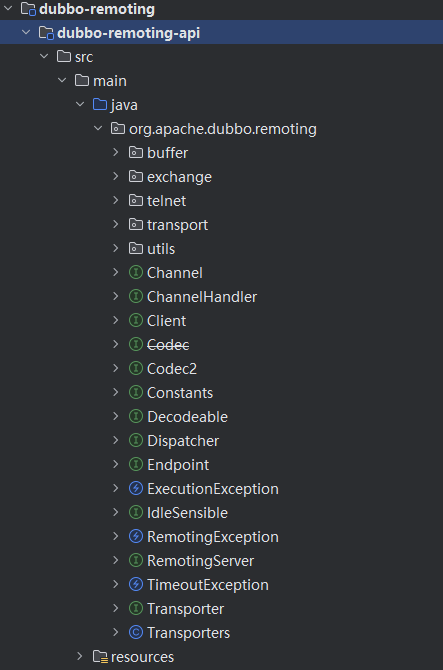
dubbo-remoting-api模块中各个包的功能:
- buffer 包:定义了缓冲区相关的接口、抽象类以及实现类。缓冲区在NIO框架中是一个不可或缺的角色,在各个 NIO 框架中都有自己的缓冲区实现。这里的 buffer 包在更高的层面,抽象了各个 NIO 框架的缓冲区,同时也提供了一些基础实现。
- exchange 包:抽象了 Request 和 Response 两个概念,并为其添加很多特性。这是整个远程调用非常核心的部分
- transport 包:对网络传输层的抽象,但它只负责抽象单向消息的传输,即请求消息由 Client 端发出,Server 端接收;响应消息由 Server 端发出,Client端接收。有很多网络库可以实现网络传输的功能,例如 Netty、Grizzly 等, transport 包是在这些网络库上层的一层抽象。
- 其他接口:Endpoint、Channel、Transporter、Dispatcher 等顶层接口放到了org.apache.dubbo.remoting 这个包,这些接口是 Dubbo Remoting 的核心接口
(1)传输层核心接口
在 Dubbo 中会抽象出一个“端点(Endpoint)”的概念,可以通过一个 ip 和 port 唯一确定一个端点,两个端点之间会创建 TCP 连接,可以双向传输数据。Dubbo 将 Endpoint 之间的 TCP 连接抽象为通道(Channel),将发起请求的 Endpoint 抽象为客户端(Client),将接收请求的 Endpoint 抽象为服务端(Server)。这些抽象出来的概念,也是整个 dubbo-remoting-api 模块的基础
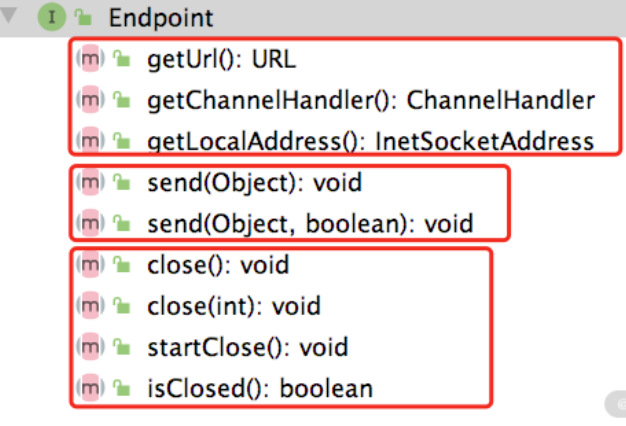
get*()方法是获得 Endpoint 本身的一些属性,其中包括获取 Endpoint 的本地地址、关联的 URL 信息以及底层 Channel 关联的 ChannelHandlersend()方法负责数据发送(有两个send()重载方法)close()方法: close() 方法的重载以及 startClose() 方法用于关闭底层 Channel ,isClosed() 方法用于检测底层 Channel 是否已关闭
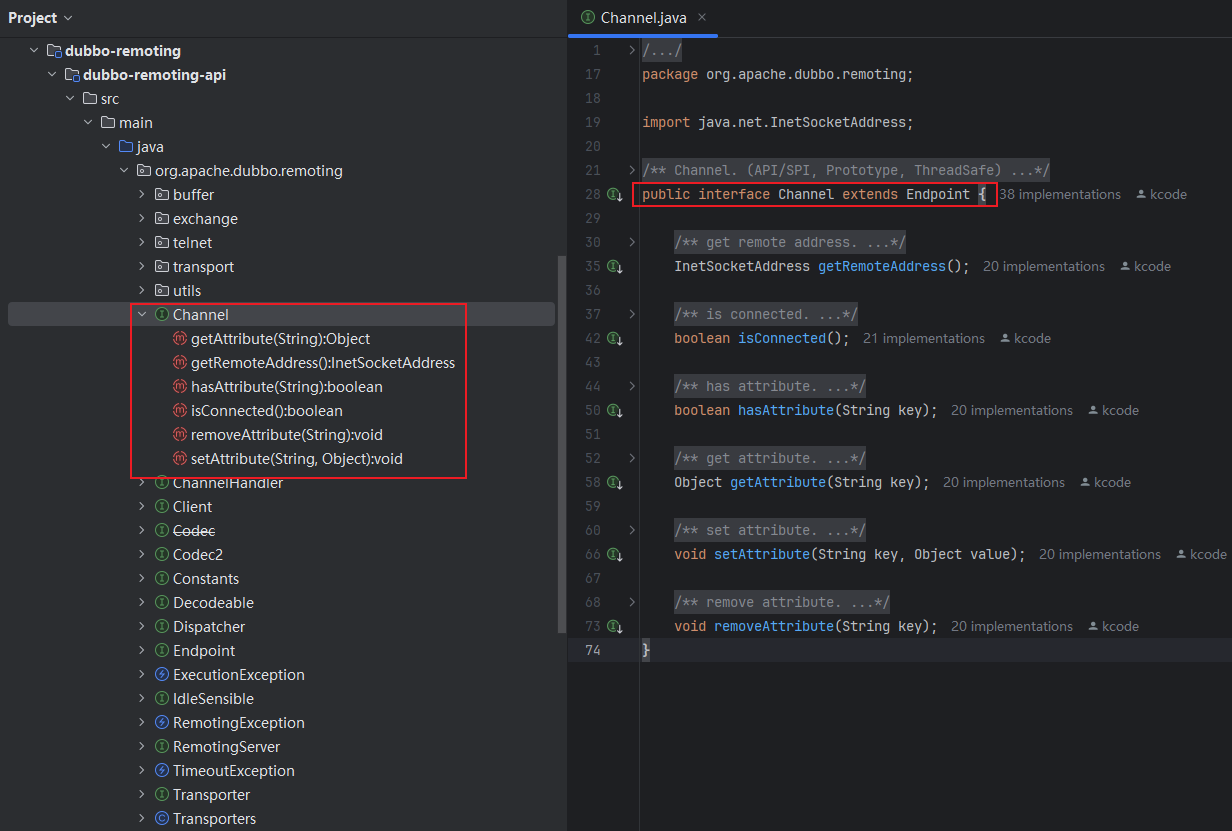
Channel 是对两个 Endpoint 连接的抽象,好比连接两个位置的传送带,两个 Endpoint 传输的消息就好比传送带上的货物,消息发送端会往 Channel 写入消息,而接收端会从 Channel 读取消息。这与前面介绍的 Netty 中的 Channel 基本一致
Channel 接口定义:Channel 继承了 Endpoint 接口(具备开关状态以及发送数据的能力)
ChannelHandler:ChannelHandler 是注册在Channel上的消息处理器
ChannelHandler 是注册在 Channel 上的消息处理器(ChannelHandler 接口被 @SPI 注解修饰,表示该接口是一个扩展点),在 Netty 中也有类似的抽象。下图展示了 ChannelHandler 接口的定义,在 ChannelHandler 中可以处理 Channel 的连接建立以及连接断开事件,还可以处理读取到的数据、发送的数据以及捕获到的异常。从这些方法的命名可以看到,它们都是动词的过去式,说明相应事件已经发生过了

Code2:编解码处理相关
Netty中有一类特殊的ChannelHandler专门负责实现编解码功能,进而实现字节数据与有意义的消息之间的转换或者消息之间的转换,此处dubbo-remoting-api中也有相似的抽象
@SPI
public interface Codec2 {
@Adaptive({Constants.CODEC_KEY})
void encode(Channel channel, ChannelBuffer buffer, Object message) throws IOException;
@Adaptive({Constants.CODEC_KEY})
Object decode(Channel channel, ChannelBuffer buffer) throws IOException;
enum DecodeResult {
NEED_MORE_INPUT, SKIP_SOME_INPUT
}
}
基于源码分析可知,Codec2 接口被 @SPI 接口修饰了,表示该接口是一个扩展接口,同时其 encode() 方法和 decode() 方法都被 @Adaptive 注解修饰,也就会生成适配器类,其中会根据 URL 中的 codec 值确定具体的扩展实现类
DecodeResult这个枚举是在处理 TCP 传输时粘包和拆包使用的,例如,当前能读取到的数据不足以构成一个消息时,就会使用 NEED_MORE_INPUT 这个枚举
Client 和 RemotingServer 接口 分别抽象了客户端和服务端,Dubbo 在 Client 和 Server 之上又封装了一层Transporter 接口
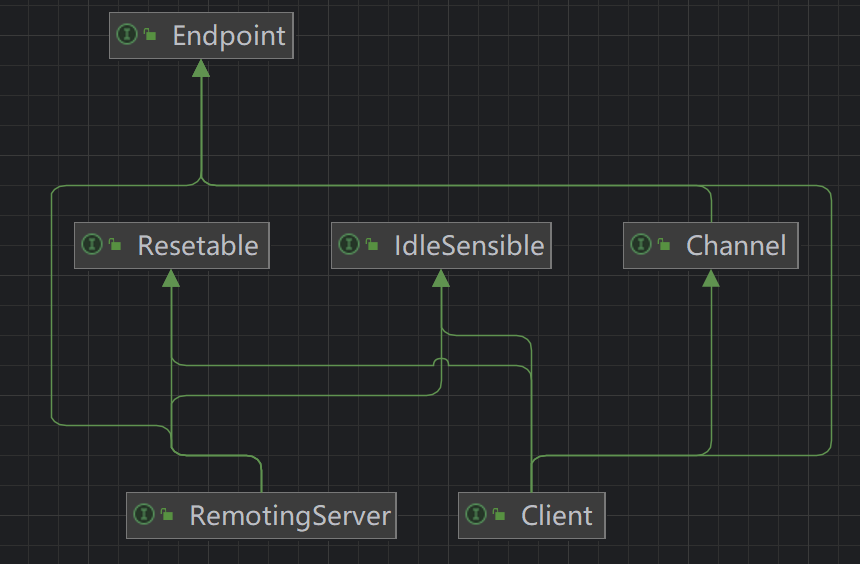
Client 和 Server 本身都是 Endpoint,只不过在语义上区分了请求和响应的职责,两者都具备发送的能力,所以都继承了 Endpoint 接口。Client 和 Server 的主要区别是 Client 只能关联一个 Channel,而 Server 可以接收多个 Client 发起的 Channel 连接。所以在 RemotingServer 接口中定义了查询 Channel 的相关方法,如下图所示:

Dubbo 在 Client 和 Server 之上又封装了一层Transporter 接口,其具体定义如下
@SPI("netty")
public interface Transporter {
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
RemotingServer bind(URL url, ChannelHandler handler) throws RemotingException;
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}
Transporter 接口上有 @SPI 注解,它是一个扩展接口,默认使用“netty”这个扩展名,@Adaptive 注解的出现表示动态生成适配器类,会先后根据“server”“transporter”的值确定 RemotingServer 的扩展实现类,先后根据“client”“transporter”的值确定 Client 接口的扩展实现。Transporter 接口实现类参考说明如下:
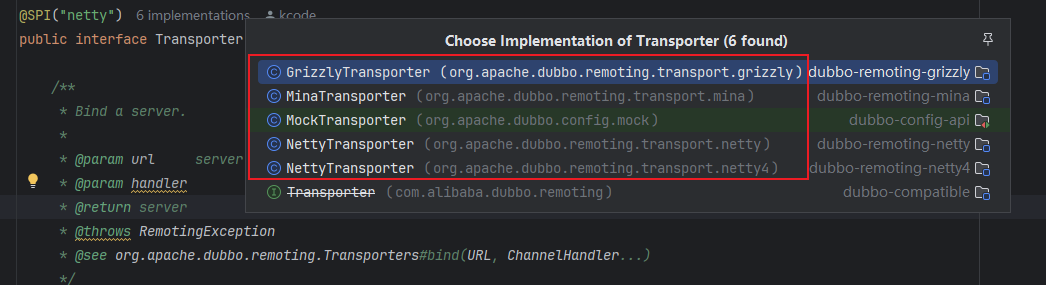
这些 Transporter 接口实现返回的 Client 和 RemotingServer 具体是什么呢?如下图所示,返回的是 NIO 库对应的 RemotingServer 实现和 Client 实现
Transporter 这一层抽象出来的接口,与 Netty 的核心接口是非常相似的。那为什么要单独抽象出 Transporter层,而不是像简易版 RPC 框架那样,直接让上层使用 Netty 呢?
其实这个问题的答案也呼之欲出了,Netty、Mina、Grizzly 这个 NIO 库对外接口和使用方式不一样,如果在上层直接依赖了 Netty 或是 Grizzly,就依赖了具体的 NIO 库实现,而不是依赖一个有传输能力的抽象,后续要切换实现的话,就需要修改依赖和接入的相关代码,非常容易改出 Bug。这也不符合设计模式中的开放-封闭原则。
有了 Transporter 层之后,我们可以通过 Dubbo SPI 修改使用的具体 Transporter 扩展实现,从而切换到不同的 Client 和 RemotingServer 实现,达到底层 NIO 库切换的目的,而且无须修改任何代码。即使有更先进的 NIO 库出现,也只需要开发相应的 dubbo-remoting-* 实现模块提供 Transporter、Client、RemotingServer 等核心接口的实现,即可接入,完全符合开放-封闭原则
Transporters 它不是一个接口,而是门面类,其中封装了 Transporter 对象的创建(通过 Dubbo SPI)以及 ChannelHandler 的处理
/**
* Transporter facade. (API, Static, ThreadSafe)
*/
public class Transporters {
static {
// check duplicate jar package
Version.checkDuplicate(Transporters.class);
Version.checkDuplicate(RemotingException.class);
}
private Transporters() {
}
public static RemotingServer bind(String url, ChannelHandler... handler) throws RemotingException {
return bind(URL.valueOf(url), handler);
}
public static RemotingServer bind(URL url, ChannelHandler... handlers) throws RemotingException {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
if (handlers == null || handlers.length == 0) {
throw new IllegalArgumentException("handlers == null");
}
ChannelHandler handler;
if (handlers.length == 1) {
handler = handlers[0];
} else {
handler = new ChannelHandlerDispatcher(handlers);
}
return getTransporter().bind(url, handler);
}
public static Client connect(String url, ChannelHandler... handler) throws RemotingException {
return connect(URL.valueOf(url), handler);
}
public static Client connect(URL url, ChannelHandler... handlers) throws RemotingException {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
ChannelHandler handler;
if (handlers == null || handlers.length == 0) {
handler = new ChannelHandlerAdapter();
} else if (handlers.length == 1) {
handler = handlers[0];
} else {
handler = new ChannelHandlerDispatcher(handlers);
}
return getTransporter().connect(url, handler);
}
public static Transporter getTransporter() {
return ExtensionLoader.getExtensionLoader(Transporter.class).getAdaptiveExtension();
}
}
在创建 Client 和 RemotingServer 的时候,可以指定多个 ChannelHandler 绑定到 Channel 来处理其中传输的数据。Transporters.connect() 方法和 bind() 方法中,会将多个 ChannelHandler 封装成一个 ChannelHandlerDispatcher 对象。
ChannelHandlerDispatcher 也是 ChannelHandler 接口的实现类之一,维护了一个 CopyOnWriteArraySet 集合,它所有的 ChannelHandler 接口实现都会调用其中每个 ChannelHandler 元素的相应方法。另外,ChannelHandlerDispatcher 还提供了增删该 ChannelHandler 集合的相关方法。
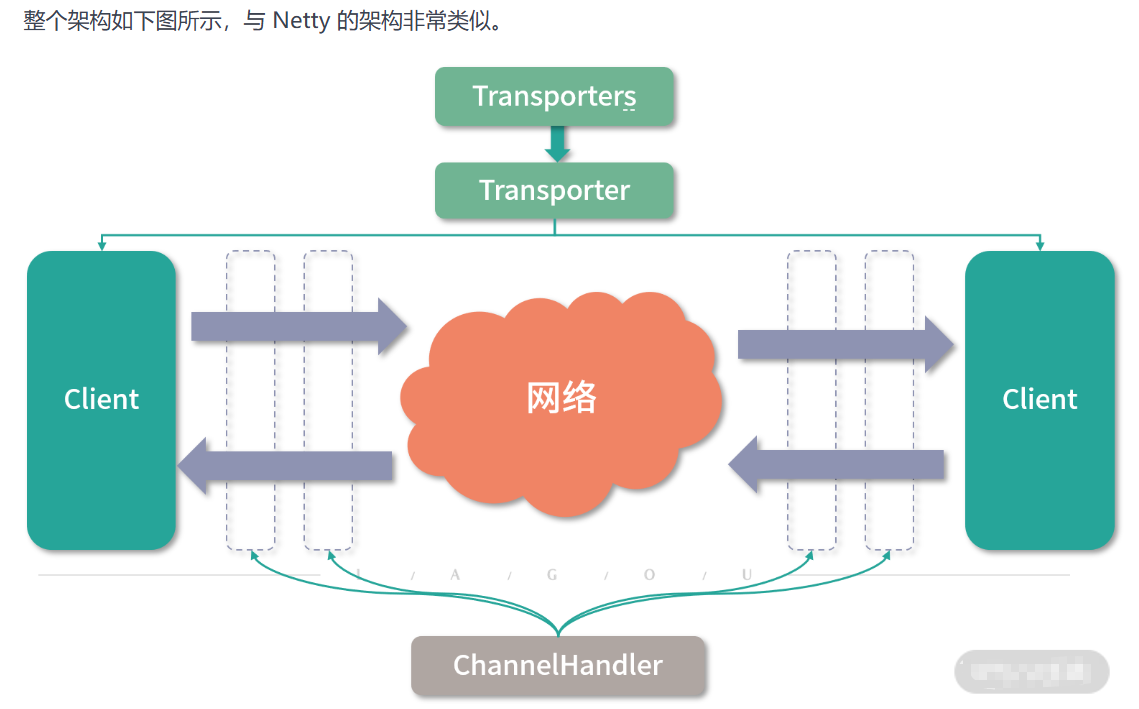
到此为止,Dubbo Transport 层的核心接口就介绍完了,这里简单总结一下:
- Endpoint 接口抽象了“端点”的概念,这是所有抽象接口的基础。
- 上层使用方会通过 Transporters 门面类获取到 Transporter 的具体扩展实现,然后通过 Transporter 拿到相应的 Client 和 RemotingServer 实现,就可以建立(或接收)Channel 与远端进行交互了。
- 无论是 Client 还是 RemotingServer,都会使用 ChannelHandler 处理 Channel 中传输的数据,其中负责编解码的 ChannelHandler 被抽象出为 Codec2 接口。
Transporter层整体架构图示分析如下:
③ Buffer 缓冲区:数据的搬运工
学习核心
- dubbo-remoting 模块中 buffers 包中的核心实现
- ChannelBuffer接口(顶层接口),了解ChannelBuffer提供的核心功能和运作原理
- ChannleBuffer的多种实现(HeapChannelBuffer、DynamicChannelBuffer、ByteBufferBackedChannelBuffer)
- ChannelBuffer相关对象创建工厂(xxxChannelBufferFactory)、ChannelBuffers 工具类、在ChannelBuffer之上封装的InputStream和OutputStream
Buffer 是一种字节容器,在 Netty 等 NIO 框架中都有类似的设计,例如,Java NIO 中的ByteBuffer、Netty4 中的 ByteBuf。Dubbo 抽象出了 ChannelBuffer 接口对底层 NIO 框架中的 Buffer 设计进行统一,其子类如下图所示(ChannelBuffer继承关系图)
1.ChannelBuffer接口
ChannelBuffer 接口的设计与 Netty4 中 ByteBuf 抽象类的设计基本一致,也有 readerIndex 和 writerIndex 指针的概念,如下所示,它们的核心方法也是如出一辙。
- getBytes()、setBytes() 方法:从参数指定的位置读、写当前 ChannelBuffer,不会修改 readerIndex 和 writerIndex 指针的位置。
- readBytes() 、writeBytes() 方法:也是读、写当前 ChannelBuffer,但是 readBytes() 方法会从 readerIndex 指针开始读取数据,并移动 readerIndex 指针;writeBytes() 方法会从 writerIndex 指针位置开始写入数据,并移动 writerIndex 指针。
- markReaderIndex()、markWriterIndex() 方法:记录当前 readerIndex 指针和 writerIndex 指针的位置,一般会和 resetReaderIndex()、resetWriterIndex() 方法配套使用。resetReaderIndex() 方法会将 readerIndex 指针重置到 markReaderIndex() 方法标记的位置,resetwriterIndex() 方法同理。
- capacity()、clear()、copy() 等辅助方法用来获取 ChannelBuffer 容量以及实现清理、拷贝数据的功能,这里不再赘述。
- factory() 方法:该方法返回创建 ChannelBuffer 的工厂对象,ChannelBufferFactory 中定义了多个 getBuffer() 方法重载来创建 ChannelBuffer,如下图所示,这些 ChannelBufferFactory的实现都是单例的(ChannelBufferFactory继承关系图如下)
AbstractChannelBuffer 抽象类实现了 ChannelBuffer 接口的大部分方法,其核心是维护了以下四个索引
- readerIndex、writerIndex(int 类型):通过 readBytes() 方法及其重载读取数据时,会后移 readerIndex 索引;通过 writeBytes() 方法及其重载写入数据的时候,会后移 writerIndex 索引。
- markedReaderIndex、markedWriterIndex(int 类型):实现记录 readerIndex(writerIndex)以及回滚 readerIndex(writerIndex)的功能,前面我们已经介绍过markReaderIndex() 方法、resetReaderIndex() 方法以及 markWriterIndex() 方法、resetWriterIndex() 方法,可以对比学习。
AbstractChannelBuffer 中 readBytes() 和 writeBytes() 方法的各个重载最终会通过 getBytes() 方法和 setBytes() 方法实现数据的读写,这些方法在 AbstractChannelBuffer 子类中实现。下面以读写一个 byte 数组为例,进行介绍
public void readBytes(byte[] dst, int dstIndex, int length) {
// 检测可读字节数是否足够
checkReadableBytes(length);
// 将readerIndex之后的length个字节数读取到dst数组中dstIndex~dstIndex+length的位置
getBytes(readerIndex, dst, dstIndex, length);
// 将readerIndex后移length个字节
readerIndex += length;
}
public void writeBytes(byte[] src, int srcIndex, int length) {
// 将src数组中srcIndex~srcIndex+length的数据写入当前buffer中writerIndex~writerIndex+length的位置
setBytes(writerIndex, src, srcIndex, length);
// 将writeIndex后移length个字节
writerIndex += length;
}
2.Buffer 各实现类解析
(1)HeapChannelBuffer
HeapChannelBuffer 是基于字节数组的 ChannelBuffer 实现,我们可以看到其中有一个 array(byte[]数组)字段,它就是 HeapChannelBuffer 存储数据的地方。HeapChannelBuffer 的 setBytes() 以及 getBytes() 方法实现是调用 System.arraycopy() 方法完成数组操作的,具体实现如下
@Override
public void getBytes(int index, byte[] dst, int dstIndex, int length) {
System.arraycopy(array, index, dst, dstIndex, length);
}
@Override
public void setBytes(int index, byte[] src, int srcIndex, int length) {
System.arraycopy(src, srcIndex, array, index, length);
}
HeapChannelBuffer 对应的 ChannelBufferFactory 实现是 `HeapChannelBufferFactory,其 getBuffer() 方法会通过 ChannelBuffers 这个工具类创建一个指定大小 HeapChannelBuffer 对象,下面简单介绍两个 getBuffer() 方法重载
@Override
public ChannelBuffer getBuffer(int capacity) {
// 新建一个HeapChannelBuffer,底层的会新建一个长度为capacity的byte数组
return ChannelBuffers.buffer(capacity);
}
@Override
public ChannelBuffer getBuffer(byte[] array, int offset, int length) {
// 新建一个HeapChannelBuffer,并且会拷贝array数组中offset~offset+length 的数据到新HeapChannelBuffer中
return ChannelBuffers.wrappedBuffer(array, offset, length);
}
(2)DynamicChannelBuffer
DynamicChannelBuffer 可以认为是其他 ChannelBuffer 的装饰器,它可以为其他 ChannelBuffer 添加动态扩展容量的功能。DynamicChannelBuffer 中有两个核心字段:
- buffer(ChannelBuffer 类型),是被修饰的 ChannelBuffer,默认为 HeapChannelBuffer
- factory(ChannelBufferFactory 类型),用于创建被修饰的 HeapChannelBuffer 对象的 ChannelBufferFactory 工厂,默认为 HeapChannelBufferFactory
DynamicChannelBuffer 需要关注的是 ensureWritableBytes() 方法,该方法实现了动态扩容的功能,在每次写入数据之前,都需要调用该方法确定当前可用空间是否足够。ensureWritableBytes() 方法如果检测到底层 ChannelBuffer 对象的空间不足,则会创建一个新的 ChannelBuffer(空间扩大为原来的两倍),然后将原来 ChannelBuffer 中的数据拷贝到新 ChannelBuffer 中,最后将 buffer 字段指向新 ChannelBuffer 对象,完成整个扩容操作。ensureWritableBytes() 方法的具体实现如下:
@Override
public void ensureWritableBytes(int minWritableBytes) {
if (minWritableBytes <= writableBytes()) {
return;
}
int newCapacity;
if (capacity() == 0) {
newCapacity = 1;
} else {
newCapacity = capacity();
}
int minNewCapacity = writerIndex() + minWritableBytes;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
ChannelBuffer newBuffer = factory().getBuffer(newCapacity);
newBuffer.writeBytes(buffer, 0, writerIndex());
buffer = newBuffer;
}
(3)ByteBufferBackedChannelBuffer
ByteBufferBackedChannelBuffer 是基于 Java NIO 中 ByteBuffer 的 ChannelBuffer 实现,其中的方法基本都是通过组合 ByteBuffer 的 API 实现的。下面以 getBytes() 方法和 setBytes() 方法的一个重载为例,进行分析:
@Override
public void getBytes(int index, byte[] dst, int dstIndex, int length) {
ByteBuffer data = buffer.duplicate();
try {
// 移动ByteBuffer中的指针
data.limit(index + length).position(index);
} catch (IllegalArgumentException e) {
throw new IndexOutOfBoundsException();
}
// 通过ByteBuffer的get()方法实现读取
data.get(dst, dstIndex, length);
}
@Override
public void setBytes(int index, byte[] src, int srcIndex, int length) {
ByteBuffer data = buffer.duplicate();
// 移动ByteBuffer中的指针
data.limit(index + length).position(index);
// 将数据写入底层的ByteBuffer中
data.put(src, srcIndex, length);
}
(4)NettyBackedChannelBuffer
NettyBackedChannelBuffer 是基于 Netty 中 ByteBuf 的 ChannelBuffer 实现,Netty 中的 ByteBuf 内部维护了 readerIndex 和 writerIndex 以及 markedReaderIndex、markedWriterIndex 这四个索引,所以 NettyBackedChannelBuffer 没有再继承 AbstractChannelBuffer 抽象类,而是直接实现了 ChannelBuffer 接口。
NettyBackedChannelBuffer 对 ChannelBuffer 接口的实现都是调用底层封装的 Netty ByteBuf 实现的
3.相关Stream以及门面类
在 ChannelBuffer 基础上,Dubbo 提供了一套输入输出流
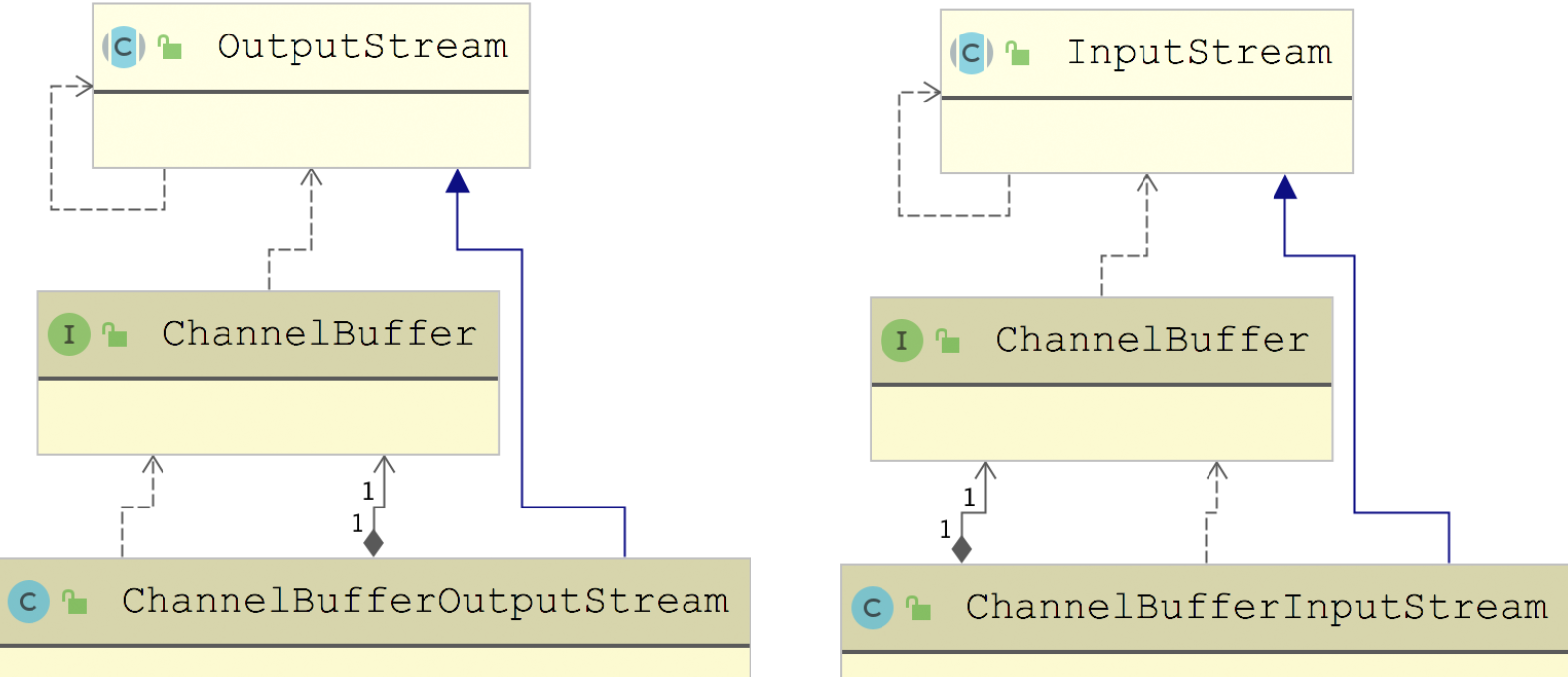
ChannelBufferInputStream 底层封装了一个 ChannelBuffer,其实现 InputStream 接口的 read*() 方法全部都是从 ChannelBuffer 中读取数据。ChannelBufferInputStream 中还维护了一个 startIndex 和一个endIndex 索引,作为读取数据的起止位置。ChannelBufferOutputStream 与 ChannelBufferInputStream 类似,会向底层的 ChannelBuffer 写入数据
可以了解下 ChannelBuffers 这个门面类,下图展示了 ChannelBuffers 这个门面类的所有方法:
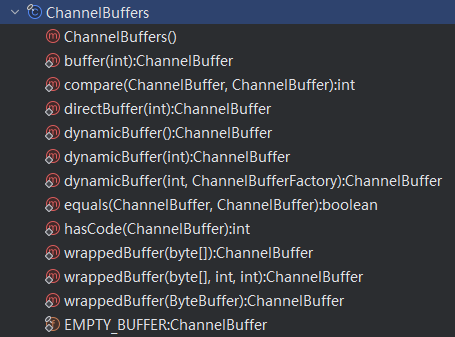
对这些方法进行分类,可归纳出如下这些方法:
- dynamicBuffer() 方法:创建 DynamicChannelBuffer 对象,初始化大小由第一个参数指定,默认为 256
- buffer() 方法:创建指定大小的 HeapChannelBuffer 对象
- wrappedBuffer() 方法:将传入的 byte[] 数字封装成 HeapChannelBuffer 对象
- directBuffer() 方法:创建 ByteBufferBackedChannelBuffer 对象,需要注意的是,底层的 ByteBuffer 使用的堆外内存,需要特别关注堆外内存的管理
- equals() 方法:用于比较两个 ChannelBuffer 是否相同,其中会逐个比较两个 ChannelBuffer 中的前 7 个可读字节,只有两者完全一致,才算两个 ChannelBuffer 相同。其核心实现如下示例代码:
public static boolean equals(ChannelBuffer bufferA, ChannelBuffer bufferB) {
final int aLen = bufferA.readableBytes();
if (aLen != bufferB.readableBytes()) {
return false; // 比较两个ChannelBuffer的可读字节数
}
final int byteCount = aLen & 7; // 只比较前7个字节
int aIndex = bufferA.readerIndex();
int bIndex = bufferB.readerIndex();
for (int i = byteCount; i > 0; i--) {
if (bufferA.getByte(aIndex) != bufferB.getByte(bIndex)) {
return false; // 前7个字节发现不同,则返回false
}
aIndex++;
bIndex++;
}
return true;
}
- compare() 方法:用于比较两个 ChannelBuffer 的大小,会逐个比较两个 ChannelBuffer 中的全部可读字节,具体实现与 equals() 方法类似
④ Transporter 层核心实现:编解码、线程模型
学习核心
⑤ Exchange层:Request-Response 模型
学习核心