消息队列-③架构篇
消息队列-③架构篇
学习核心
- 消息队列-架构篇(重点)
- 基于Kafka框架作为学习沉淀
- Kafka 架构(*)
- Kafka整体架构
- 关键点分析:主题Topic、主题分片Partition、服务器节点Broker、生产者Producer、消费者Consumer、消费组再平衡机制
- 架构核心题型
- Kafka 架构(*)
- 基于Kafka框架作为学习沉淀
学习资料
整体架构(把控全局,掌握整体架构)
1.思路阐述
学习思路
要了解一个中间件,是需要有层次感的,如果没有一定经验积累,一上来就去看某个细节的源码,或者通读整个代码都是吃力不讨好的方式。
更为科学的做法是整体把控+逐个击破,先对中间件的整体架构有个了解(大概知道知道它的架子是怎样的,在脑子里形成一个整体的框架,框架中的组成成分和各自的作用),基于这个基础,再对每个组成成分进行剖析,如此一来事半功倍。
2.宏观架构
宏观架构:可以将Kafka宏观看做3层:Producer(生产者)、Server(中转者)、Consumer(消费者)
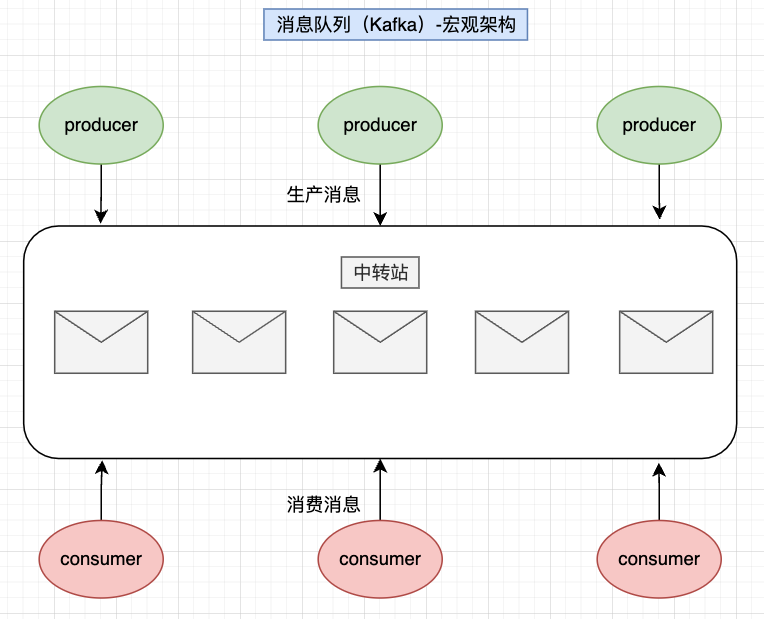
- 生产者(producer):在kafka中,producer负责创建消息并将其发送到kafka服务器(producer是消息源头,将消息发送到特定的主题Topic中,供consumer订阅和消费)
- 中转站(server):server是kafka服务,可以理解为消息中转站。生产者发送消息到server,然后消费者可以从server拉取消息进行消费
- 消费者(consumer):在kafka中,consumer负责订阅主题和消费消息(当producer向server传递消息之后,如果消费者订阅了相应的主题,则消费者会从server中拉取消息进行处理)
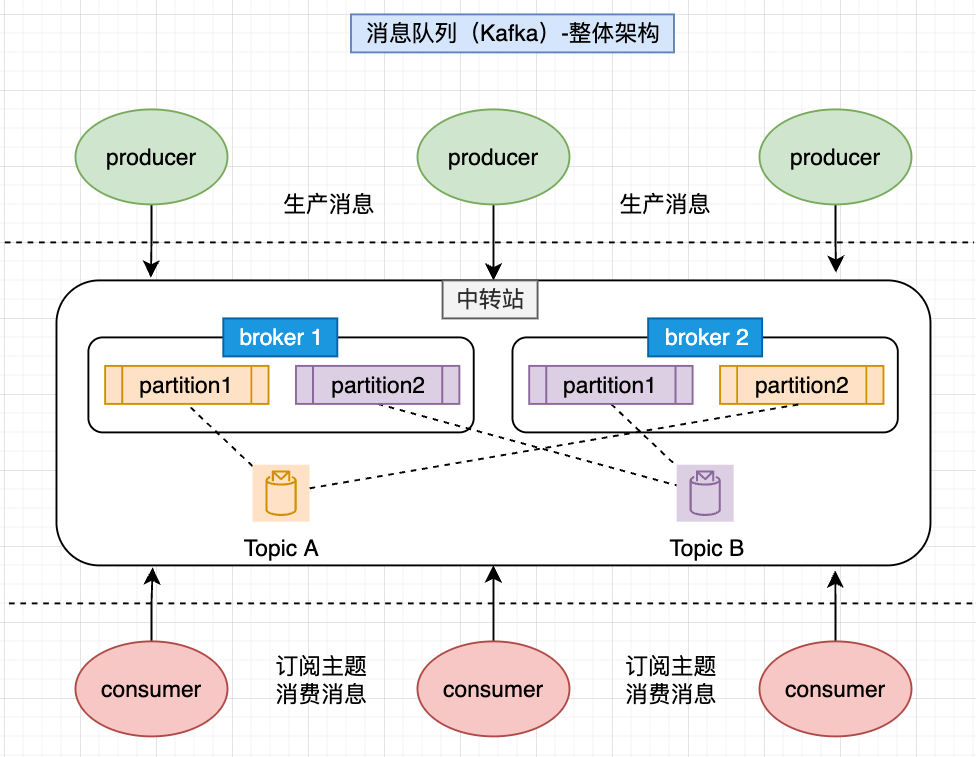
3.整体架构
以Kafka架构学习为参考,此处关注Kafka服务层(中转站),它的组成是比较丰富的,可以关注核心:Broker、Topic、Partition
- Broker:理解为机器或者节点,或者为运行Kafka程序的服务器
- Topic:主题是Kafka中的一个核心概念,它是对消息进行分类的一种方式。生产者将消息发送到特定的主题中,而消费者则通过订阅主题来接收相关的消息。需注意主题是一个逻辑概念,实际上,一个主题可以被分为多个分区(Partition),以实现消息的并行处理和负载均衡,数据是存储在Partition这个级别的
- Partition:分区是Kafka中的一个重要概念,它是主题的物理存储单位。每个分区都是一个有序的、不可变的消息序列,可以被独立地读写。分区在物理上对应一个文件夹及文件夹下面的文件,分区的命名规则为主题名称后接“一”连接符,之后再接分区编号
- 比如
TopicA-1表示主题A的1号分区,每个分区又可以有一至多个副本(Replica),以提高可用性
- 比如
理解了服务层的组成,可以基于宏观架构进一步细化架构细节,基于这些组件构成,共同组成了kafka消息队列的整体架构
- 生产:produce(生产者)
- 存储:server =》broker(服务节点)、topic(主题:逻辑概念)、partition(主题分区:物理存储概念)
- 消费:consumer(消费者)
4.总结分析
基于上述概念分析,对kafka的整体架构有个初步的认识,从宏观架构 =》整体架构的梳理,但其组件内部的具体运作的细节还没有展开,在后续的学习中进行补充,例如思考下述几个问题:
- 生产者到底写入哪个partition?
- 消费者如何消费一个多分片的主题?
- 多个broker如何进行协作?
- ......
Topic(开门见山)
1.Topic 核心概念
什么是 topic ?
Topic是主题,可以理解为数据分片的一种方式,Kafka基于主题Topic实现业务隔离,避免业务处理逻辑混乱
Topic就是主题,相同业务可以放同一个主题(类比MySQL,一类数据就放在一张表里,而消息队列中,某类数据就可以放入一个主题),可以理解为数据分片的一种方式。
比如秒杀消息放入秒杀主题,比如短信消息放入短信主题,Kafka通过主题实现了业务的隔离,避免业务处理逻辑混乱。从主题A拿到的消息一定是A对应类型的消息,消费者可以做对应的处理,试想如果各式各样的消息混在一起,处理起来得多乱。
topic 存在哪里?
从宏观概念来说 topic 是存储在服务端的(可以理解为存储在broker节点中),但topic是架构的一种逻辑概念,消息是存储在topic的主题分区(partition)中的(partition 是真正的物理存储)
- 单机环境:topic 是存储在服务端(即broker节点)中,topic会划分多个不同分区进行存储
- 集群环境:topic会划分多个不同分区进行存储,一个集群会有多个broker,kafka则会将这些主题分片(partition)跨broker进行存储
2.如何操作Topic(Topic的CRUD)
前置环境:基于Docker构建单机版的Kafka(创建了一个kafka-test 容器,其链接了zookeeper-test)
# 进入容器
docker exec -it kafka-test /bin/bash
# 进入Kafka bin目录,输入相关指令进行测试
cd /opt/kafka/bin
操作【1】创建topic(
--create)
# 创建topic
./kafka-topics.sh --create --bootstrap-server localhost:9092 --topic tp-mytest
-- output
Created topic tp-mytest.
-- 如果再执行一遍,就会提示topic已存在
Error while executing topic command : Topic 'tp-mytest' already exists.
[2024-08-22 01:35:08,540] ERROR org.apache.kafka.common.errors.TopicExistsException: Topic 'tp-mytest' already exists.
(kafka.admin.TopicCommand$)
操作【2】查询topic(
--list、--describe)
# 1.查询topic
./kafka-topics.sh --list --bootstrap-server localhost:9092
-- output
会列举所有的topic
# 2.可以通过命令,查看主题的更多信息
./kafka-topics.sh --describe --bootstrap-server localhost:9092
-- output
Topic: tp-mytest TopicId: Q5SgAwC4Rbeiq2Ew2QCl9g PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: tp-mytest Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
# 3.查看某个主题的信息
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic tp-mytest
操作【3】删除topic(
--delete)
# 删除指定topic
./kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic tp-mytest
# 删除后再次查询确认是否已清理
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic tp-mytest
-- output(Topic 'tp-mytest'已经被删除,查询失败,符合预期)
Error while executing topic command : Topic 'tp-mytest' does not exist as expected
[2024-08-22 01:41:52,246] ERROR java.lang.IllegalArgumentException: Topic 'tp-mytest' does not exist as expected
at kafka.admin.TopicCommand$.kafka$admin$TopicCommand$$ensureTopicExists(TopicCommand.scala:542)
at kafka.admin.TopicCommand$AdminClientTopicService.describeTopic(TopicCommand.scala:317)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:69)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
3.代码中如何使用Topic
上述操作是通过命令行的方式使用topic,实际应用场景中更多是通过代码来操作Topic。在理解Topic组件运作的基础上,只需要确认业务指向哪个主题,做什么操作即可(业务开发的时候,一般不需要提前创建主题,只需要向某个主题发送消息,它会自动创建),参考【消息队列-基础篇】的消息队列场景应用案例,就实现了一个最简单的消息发送、消息消费逻辑,一般不会在kafka服务端去直接操作topic,而是通过编写业务代码进行操作
// 引入MQ:此处生产者做发送消息(执行逻辑由消费者实现)
@PostMapping(value = "/decouplingWithMQ",consumes = "application/json;charset=utf-8")
public ResponseEntity<String> decouplingWithMQ(@RequestBody IncrCountReq incrCountReq) {
// 传递消息,发送到kafka消息队列
kafkaTemplate.send("tp-mq-decoupling", JSON.toJSONString(incrCountReq));
return ResponseEntity.ok("success");
}
// 模拟消费者消费
// @KafkaListener(topics = "tp-mq-decoupling",groupId = "TEST_GROUP",concurrency = "1",containerFactory = "kafkaManualAckListenerContainerFactory")
@KafkaListener(topics = "tp-mq-decoupling",groupId = "TEST_GROUP") // 使用Springboot的KafkaListener注册一个kafka消费者
// public void topicConsumer(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
public void topicConsumer(ConsumerRecord<?,?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
// 解析消息
Object msg = message.get();
log.info("接收到的kafka消息:{}",msg);
try{
// 模拟消费消息
countService.incrManyTimes(JSONObject.parseObject(msg.toString(),IncrCountReq.class).getNum());
log.info("kafka消息消费成功:topic:{} msg:{}",topic,msg);
}catch (Exception e){
e.printStackTrace();
log.error("kafka消息消费失败:topic:{} msg:{}",topic,msg);
}
}
}
主题分片Partition(分而治之)
1.主题分片partition核心概念
partition的引入
基于Topic概念,kafka消息会分发到不同的topic,进而实现业务隔离,避免消息混乱的问题,又能分摊流量,减少单个业务的写入压力。
但是不同业务的数据量级始终不同,就算按照业务维度拆分topic,但一个topic中的消息可能还是会很多,因此需要引入“分而治之”概念。因此kafka架构设计中在topic下划分了partition分区,每个topic下有多个partition分区(分片概念)
分片的好处
(1)提高写入性能:分片使得数据分布在多个Broker上,允许并行处理更多的数据请求,从而提高整体系统的吞吐量
(2)提高消费并发度:因为有多了个分片,那么不同消费者就可以对不同分片进行拉取消费
(3)分片对Kafka的水平扩展的能力提供了支持
(4)一定程度提高了容错性:分片可以提高系统的容错能力。如果一个服务器上的分片发生故障,其他服务器上的分片可以继续处理数据请求,确保系统的高可用性
分片逻辑结构
可以通过命令行查看分片信息,分析可知Partition会使用数字来标记,假设有3个Partition,那分片编号就是从0开始(0、1、2),消息会追加到每个Partition的尾部

注意,同一个Partition里的数据,消息是有序的。即使同一个主题里的消息,如果分布在多个Partition,不同Partition的消息之间也是无序的,这一点直接从这个结构图里也是能看出的
因此kafka对消息有序的保证,也是基于“分区”这个概念点去切入的,对于要求消息有序的业务就放在同一个分区确保消息有序
数据流入哪个分片
一个主题的数据分散成了多个分片,就需要有一种方式来决定消息是写入哪个分片(这点的理解可以对标数据库的分库分表概念),规则如下:
(1)明确指定分区:显式指定分区,发送消息到指定的分区
如果指定了Partition就发送到特定的Partition(一般情况下,业务其实不需要感知Partition,除非有特殊场景,否则不建议直接指定要发送到哪个Partition)
(2)指定分区Key:指定分区key,路由映射分区(路由规则:Hash(key))
如果没有指定Partition,通过指定了一个分区Key,然后根据Key的Hash对Partition数目取模来决定是哪个Partition(即只要发送时指定了相同的Key,那么相关消息一定会发送到相同的Partition)

(3)轮询调度算法:根据现有分区数量,询轮存储
如果没有指定Partition,也没有指定分区Key,就会采用轮询调度算法,即每一次把来自用户的请求轮流分配给Partion。结合上述图示分析,假设现有3个分区,那么消息就会依次轮询存储,例如消息1存Partition0、消息2存Partition1、消息3存Partition2、消息4存Partition0(以此类推......)
结合上述分片存储规则分析,可结合业务场景来灵活配置分片规则:
- 如果是业务对顺序没有要求,那么就可以不指定Partition,也不指定Key,比如发短信这种业务,谁先谁后无所谓;
- 如果业务对顺序有要求,比如先来先到的抢购,那么就可以指定一个唯一Key(例如业务名字当Key),来自同一个业务的消息就放在同一个Partition里,数据在同一个分区中就具备有序性,也就达成了先进先出的目标
分片实践应用:创建多少个分片合适?
一个主题,到底多少个分片比较合适?其实没有一个定数,一切按业务实际情况来规划,此处提供一个简单的思路:
(1)默认设定:默认设置3个分片,大多数业务都是OK的,具体是否有问题,还是经过完善的测试才知道
(2)根据写入TPS预估:根据产品预计的写入TPS来估计,比如需要50000TPS的写入性能,那么先单个分区来测试,看看能达到多少
假设就是10000TPS,可以试试2个分区是否能达到20000TPS,或者设置5个分片来试试看是否达标,当然这里应该也并不是线性增长,具体还是以测试为准
(3)根据消费TPS预估:根据产品预计的消费TPS来估计,假设一个消费者在消费一个分区的情况下性能能达到200/s,但是希望的是20000TPS的消费能力,这里就需要100台消费者才能满足,而对应的分片也需要扩展到100个来进行支持
2.如何操作分片
前置环境:基于Docker构建单机版的Kafka(创建了一个kafka-test 容器,其链接了zookeeper-test)
# 进入容器
docker exec -it kafka-test /bin/bash
# 进入Kafka bin目录,输入相关指令进行测试
cd /opt/kafka/bin
操作【1】创建分片(
--partitions)
# 先创建一个topic,查看它的详细信息
./kafka-topics.sh --create --bootstrap-server localhost:9092 --topic tp-mytest
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic tp-mytest
-- output
Topic: tp-mytest TopicId: 8Y4EcBQNRTK_aHwKRt5gwQ PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: tp-mytest Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
-- 从显示结果分析,默认只有一个Partition分区为【Partition: 0】
# 为一个topic创建多个分片(指定--partitions参数),例如此处为tp-mytest-p主题创建3个分区
./kafka-topics.sh --create --bootstrap-server localhost:9092 --topic tp-mytest-p --partitions 3
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic tp-mytest-p
-- output
Topic: tp-mytest-p TopicId: Pyk--Z5LRiSR6fiqLBlQbQ PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: tp-mytest-p Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: tp-mytest-p Partition: 1 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: tp-mytest-p Partition: 2 Leader: 1001 Replicas: 1001 Isr: 1001
-- 从显示结果分析,为topic创建了3个分区
【操作2】更改分片数量(
--alter)
基于业务场景,原有分片数量可能不足以支撑场景(原有分片个数不足,无法支撑现有数据的流入速度),因此运行过程中可能需要对分片数量进行调整。通过命令更新分片数量。但需注意分片数量只能调大不能调小,调小会抛出错误
# 更改分片数量(例如更改上述tp-mytest,扩展成5个分区)
./kafka-topics.sh --alter --bootstrap-server localhost:9092 --topic tp-mytest --partitions 5
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic tp-mytest
# 试图调小分片数量,例如将原有的5个分区调整为3个分区(抛出异常)
./kafka-topics.sh --alter --bootstrap-server localhost:9092 --topic tp-mytest --partitions 3
-- output
Error while executing topic command : Topic currently has 5 partitions, which is higher than the requested 3.
[2024-08-22 02:13:00,811] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: Topic currently has 5 partitions, which is higher than the requested 3.
(kafka.admin.TopicCommand$)
服务器节点(Broker)
1.broker核心概念
结合上述概念可以知道,消息是逻辑上写入topic,实际物理存储是在对应主题分区partition中,而partition实际上是存在于kafka的物理节点上(即“broker”)
broker 是什么?
Broker实际就是一个个Kafka的服务器节点,服务器节点上运行了Kafka必要的应用程序。Broker提供以下功能:
- (1)接收从客户端来的连接
- (2)支持客户端查询Kafka集群的信息,比如集群内其它的broker信息
- (3)接收来自客户端的读写请求
- (4)存储消息(即Kafka的消息是存储在Broker上的,也就是存储在服务器本地)
2.broker 部署模式(单机VS集群)
单机部署 VS 集群模式
如果是单机部署,那么只有一个Broker,如果是集群模式部署,那么一个Kafka集群下面就存在多个Broker,集群无非就是用多个Broker共同协作对外提供整体的服务。抽象一点来说,无论哪种模式都可以看作一个Kafka集群,单机模式实际可以理解为集群模式的特例化(集群模式下Broker只有一个的情况),其它没有区别。
对于单机部署和集群模式的选择,还是看具体的业务场景,如果是小规模应用希望短平快,那么用单机是没有问题的。如果是大规模应用,通常还是会构建多台Broker,无论从性能还是从可靠性而言,都会更有优势(例如Uber在其业务中就部署了上百个Broker来处理数据)
在集群中,一个Broker是通过一个唯一的数字ID来标识自己的身份(例如Broker10、Broker11、Broker12等...)
Broker 和 Partition 的关系
Partition是存放在Broker节点上的,可以从部署模式上分析两者的关系:一个Partition只对应一个Broker,一个Broker可以存放多个Partition
- 如果是单机模式(1个broker),Partition都在同一个Broker上
- 如果是集群模式(多个broker),则Partition会分布到不同的Broker上
需注意,如果Broker的数量少于Partition的数量,可能会有一些Broker承载同一个topic的多个Partition,可以结合Broker的分配规则理解
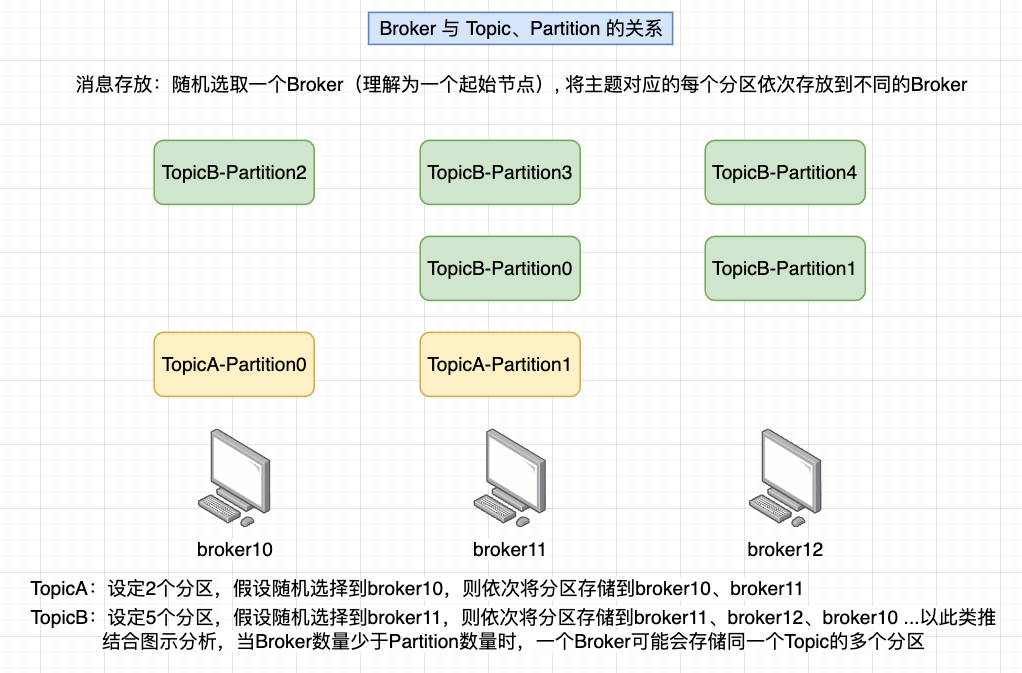
kafka 的存储规则:先随机选择一个broker,然后将topic的分区按顺序依次存放到不同的broker
3.客户端如何连接集群
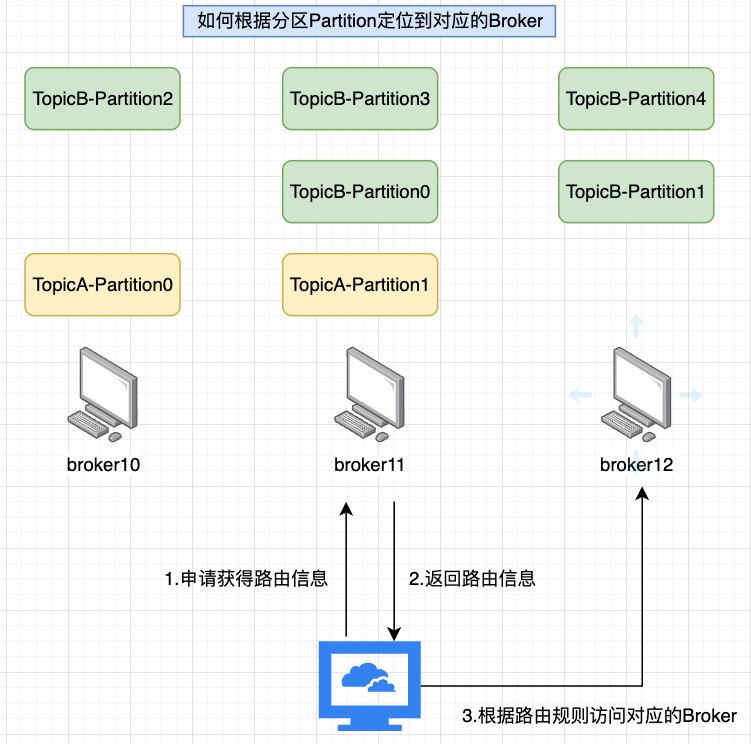
客户端如何找到集群中需要的Broker?
单机情况下连接可以直接通过访问单机地址即可,但是集群下有那么多Broker,怎么找到需要的那台呢?这里其实一般有3种解决问题的思路:
- 方式1:加个代理,由代理来和众Broker打交道;
- 方式2:重定向,即访问其中一台,如果不是目标节点,它会告诉你正确的节点是哪台;(参考Redis的集群模式的重定向思路)
- 方式3:客户端先查询路由,客户端再根据路由表去访问
Kafka 基于 “路由” 来控制集群连接信息
Kafka是基于方式3“路由规则”来实现的,每个Broker都会有其它Broker的信息,也就是说Broker之间是互相知晓的(前提),基于这个前提,客户端连接Kafka集群的流程如下:
(1)访问任意一台Broker
(2)得到所有Broker的信息列表
(3)根据规则连接到具体的Broker(这个规则实际上就是Partition的规则,由生产者算出来是哪个Partition,就发送给这个Partition所在的节点)
生产者(Prodcuer)
1.生产者概念核心
什么是生产者?
Producer即生产者(生产信息的一方),一般就是某个应用、后端服务概念,这个服务会发送消息给Kafka服务端的某个Broker节点,最终消息落到某个主题的某个分片。在实际开发中,这个后端服务会集成Kafka客户端的库来和Kafka打交道,基本上所有的语言,Kafka都有对应的客户端库来支持,比如Java、Go(可以结合前面的代码案例进行理解)
消息发送给哪个Broker?
集群环境下Kafka可能有多个Broker,一个主题Topic下可能有多个分区Partition,这些分区会分布在不同的Broker下,发送消息的时候会发到哪个Broker?
实际上发送消息的时候会根据指定的key(对应要发送到哪个分区),然后根据这个分区可以定位到分区所在的Broker,进而和相应的Broker进行交互
2.生产消息的流程
步骤1:构建消息 =》即将要发送的内容,打包成一个Kafka的消息结构;
步骤2:序列化消息 =》序列化消息为二进制内容,以在网络中传输;
步骤3:分区选择 =》即计算要发到哪个Partition,发送消息到该Partition对应的Broker;
构建消息(关注“消息结构”)
消息是在生产者这一端产生的,也就是生产消息的第一步,此处重点关注消息具体的格式:

所谓消息,最终就是一个封装好的数据结构,Kafka每一条消息都对应了这么一个结构
- Key:根据Key的Hash对Partition数目取模来决定存入哪个Partition(只要发送时指定了相同的Key,相关消息会发送到相同的Partition),Key一般而言都是字符串,最终都会被序列化为二进制
- Value:要发送的具体内容,Value最终都会被序列化为二进制
- Compression Type:压缩类型(压缩算法类型),决定了用哪种算法压缩Kafka消息(参考枚举值有none、gzip、lz4、snappy等)
- Headers:可以通过这个字段传递额外的Header(传递一些自定义的key-value对,比如想传递TracelD)
- Partition+offset:这个字段生产出来时候是空的,发送到Kafka的服务端后,会写入具体的分区的偏移,主题+分区+偏移其实就唯一对应了一条消息
- Timestamp:时间戳,记录消息的时间
序列化消息(关注“序列化”规则)
序列化即将消息从常规类型,变成二进制类型,以在网络中传输,以下图为例:
- Key对象,会根据Key本身的类型,用不同的序列化工具进行序列化(比如INT =》INT序列化器,STRING =》STRING序列化器),最终被转化为了二进制数据
- Value对象,也是经过序列化,最终被转化为了二进制数据
发送模式
Java的SDK提供了3种不同的发送模式选择:同步发送、发送即忘、异步发送
方式1:同步发送
同步发送,等待响应后处理,会阻塞调用线程,可自行捕获处理异常
方式2:发送即忘(fire-and-forgot)
最简单的发送方式,不会等待kafka的响应,也不处理可能存在的异常
方式3:异步发送
- 发送完成后就去做其他事情了,不会阻塞调用线程,可以通过注册回调函数来处理发送的结果或异常
@Component
@Slf4j
public class KafkaProvider {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
// 发送模式
public void send() {
String msg = "hello kafka";
// 方式1:同步模式
try{
kafkaTemplate.send("tp-test",msg);
}catch (Exception e){
e.printStackTrace();
}
// 方式2:发送即忘
kafkaTemplate.send("tp-test",msg);
// 方式3:异步模式
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("tp-test",msg);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
log.info("send success msg:{},with offset:{}", msg, result.getRecordMetadata().offset());
}
@Override
public void onFailure(Throwable ex) {
log.error("send fail msg:{},with offset:{}", msg, ex.getMessage());
}
});
}
}
3种发送模式的优缺点分析(实际就是“可靠性”、“性能”分析,以及对应适配的场景)
同步发送:
- 优点:确保消息发送成功,调用者可以处理发送失败的情况
- 缺点:会阻塞调用线程,可能会影响性能
- 适用场景:适用于对消息传输可靠性有要求的场景,例如需要确保事务性操作的消息发送成功
发送即忘:
- 优点:性能高,调用者不需要等待 Kafka 服务器的响应
- 缺点:无法确保消息的可靠传输
- 适用场景:通常用于日志记录等对消息传输可靠性要求不高的场景
异步发送:
- 优点:异步发送方式结合了前两者的优点,不阻塞调用线程,同时允许调用者处理发送结果或异常
- 适用场景:适用于对消息传输可靠性有要求,同时希望保持高性能的场景
| 发送模式 | 可靠性 | 性能 | 适用场景 |
|---|---|---|---|
| 同步发送 | 可确保消息发送成功 | 会阻塞调用线程,可能会影响性能 | 对数据一致性要求较高的场景 |
| 发送即忘 | 不等待响应也不处理异常,无法确保消息是否发送成功 | 性能高,不需要等待kafka响应 | 对性能要求较高的场景 |
| 异步发送 | 调用者可处理异步结果或异常 | 不会阻塞线程,性能较高 | 在高性能和可靠性之间取得平衡 |
3种发送模式的实践建议
- 同步发送:适用于需要确保消息成功发送的场景,尤其是对数据一致性要求较高的场景
- 发送即忘:适用于不需要对发送结果进行处理的场景,尤其是对性能要求较高的场景
- 异步发送:适用于需要在高性能和可靠性之间取得平衡的场景。可以在需要时处理发送失败的情况通过选择适合的发送方式,可以在保证系统性能的同时,满足不同业务场景下对消息传递可靠性的要求
消费者(Consumer)
1.消费者核心概念
消费者是消息队列非常重要的一环,其复杂性也大于生产者,毕竟生产者只是生产消息(相对简单),而消费者则要考虑消费频率、消息提交、以及组队消费
消费者(消费/读取Kafka消息的应用或服务),和生产者一样,消费者也需要集成Kafka客户端库然后通过接口向Broker去获取消费

结合图示分析“消费”特点:
- 不同消费者可以在同一时间对同一主题进行消费
- 相同消费者可以同一时间从同一主题的不同分片读取信息
- 如果一个消费者,同时消费多个分片下,无法保证消息之间的先后顺序
- 如果一个消费者,只消费一个分片,消费顺序即生产顺序,符合队列的先入先出特性
默认情况下,Kafka的消费者只会消费连接之后新产生的消息,如果想消费历史消息,是需要传递参数指定的
2.核心概念分析
消费消息是推还是拉?
Kafka的消费者使用的**拉模式(循环拉取模式)**来获取信息,也就是说每次消费者是发消息到Kafka的Broker来获取信息,而不是由Kafka的Broker主动推送
选择拉模式的主要原因还是为了让消费者可以按自身情况来控制消费速度,根据系统资源利用情况(如 CPU、内存等)、业务需要等因素合理拉取消息,避免因消息处理速度不合理带来的资源浪费或过载。
可以通过调节max.poll.records(参数设置用于限制每次调用 poll返回的消息数)来调节消费者拉取的频率,结合实际业务场景进行设定
- 如果消息处理逻辑较轻量且快速,可以增大这个值以提高吞吐量
- 如果消息处理逻辑较复杂且耗时较长,可以减小该值以减少每次拉取的消息数量,防止处理超时
max.poll.records是每次拉取的个数,但是多久拉取一次呢? 实际上,Kafka消费者是循环拉取模式(即当这批拉取的消息都处理完了,才会继续去拉取下一批)
此处还有一个参数max.poll.interval.ms(不要误认为是拉取间隔配置,其实并不是),参数定义了消费者调用轮询方法的最大允许间隔时间(以毫秒为单位)。如果消费者在这段时间内没有发起拉取,Kafka 会认为消费者已失效,并触发再平衡操作,将该消费者的分区重新分配给其他消费者
消费者OFFSET
每条消息在Kafka中会有Partition ID(分区号)以及OFFSET(偏移),通过这两个信息就可以定位到一条消息。消费者组消费消息之后会提交它在某个Partition对应的OFFSET,这样子下一次就可以从下个位置(OFFSET+1)开始消费
提交的动作可以是自动周期性进行,也就是每个周期会提交最新的已处理消息。结合图示分析,例如消费了5这个位置的消息,也做了对应的提交,所以Commited offset也是5,下一次消费的就是6这个位置的消息

注意,提交操作是和Kafka Broker打交道,所以消费者是不会直接去访问Broker上的topic的,而是通过broker来实现。同时,如果一个指定的offset被确认,那么它之前的信息就相当于都确认了,下次消费是从它的下一条消息开始消费
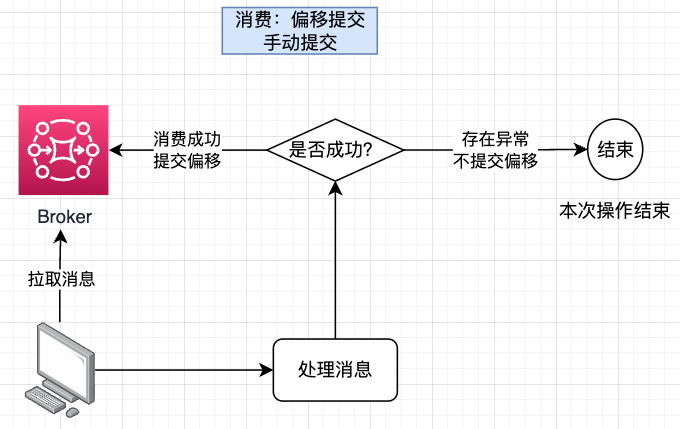
主动提交 VS 被动提交
在“at least once”消费语义的场景学习中有提到,在消费环节可以通过偏移量提交来保证“消息不丢失”,提交偏移有两种方式:自动提交和主动提交
消费者可以自动周期性提交Offset,也可以由消费者业务代码自己控制提交时机,主动调用函数来提交(手动提交)
这两种方式的区别主要是基于对“可靠性”的考虑,如果是自动提交并不会等待消息消费完成,可能导致事情还没做完就提交,如果服务崩溃则可能导致消息丢失问题。而针对手动提交,会等待确认消息消费成功,然后由业务代码控制提交时机
消费者组(Consumer Group)
除了单纯的Consumer,Kafka还支持消费组的功能。消费组是一个消息队列比较常见的功能,消费组其实就是把一些消费者组织起来,一同工作,它们像一个团队一样,协同作战。
消费者组创建(
--group)
# 进入容器
docker exec -it kafka-test /bin/bash
# 进入Kafka bin目录
cd /opt/kafka/bin
# 1.启动provider
sh kafka-console-producer.sh --broker-list localhost:9092 --topic tp-mytest
# 2.启动Consumer Group
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --group mygroup --topic tp-mytest
测试:provider 终端中发送数据,然后确认consumer终端是否可以正常接收消息并处理
一个消费组由一个唯一的groupid来标识(在消费者一侧指定),拥有相同groupid的消费者就属于同一个消费组。一个消费组中的消费者消费同一个Topic,每个消费者可以承接这个Topic一部分Partition的消息,基于此消费能力就实现了水平扩展
可以理解为一个业务(一个Topic)业务下有很多子业务(划分了不同分区Partition),一个消费组可以理解为这个业务项目组的成员,消费即处理任务,可以承接这个业务的部分任务。
- 同一个消费组中,每个分片只会分配给一个消费者
- 同一个消费组中,消费者可以被指派多个分片
- 不同消费组可以同一时间消费同一个主题
为什么要引入消费组?
实际上可以通过程序直接指定某个Consumer消费某个分片,也是可以实现并发消费的。但是对比消费组方案,其存在几个问题:
- 当不使用消费者组时,Kafka不会自动管理分区和消费者之间的关系,需要手动指定消费者要消费的分区,这就意味着如果Partition数量变了,消费者代码就得跟着升级,没法做到自动切换
- 消费组只用关心主题维度,而不用关心分片维度,对于使用者而言,很大程度降低了理解和应用难度,比如秒杀场景,使用者只需要知道自己要处理秒杀相关的主题,他底下有几个分片,则是对使用者是透明的,这就是封装的魅力
- 本质上就是要组织几个消费者一起工作,没想象那么简单,还有很多问题要考虑,而消费组相当于把这些脏活累活都做了,封装成这么一个完善的功能,直接给用户使用
基于此分析,可以知道消费者组是存在自动切换的逻辑的,这个机制在Kafka中有个特有名词(Rebalance-再平衡)
消费者组分区分配策略
一个消费者组里有多个消费者,分区是按什么规则来分配给这些消费者的呢?可以关注消费端partition.assignment.strategy这个配置,这个参数就是分区的策略,它有如下几种选择:
- (1)Range Assignor:基于范围的分配策略,将分区按照范围分配给消费者
- (2)RoundRobin Assignor:基于轮询的分配策略,分区均匀地分配给消费者
- (3)Sticky Assignor:优先保持当前的分配状态,并尽量减少在再平衡过程中的分区移动
- (4)CooperativeStickyAssignor:和Sticky Assignor的策略是一样,区别在于未受变动的消费者可以继续消费主题
消费组再平衡机制(拥抱变化)
1.Rebalance机制
消费者组一个核心作用,就是可以动态维护一个消费者组织,让它们看似如同一个整体一般去进行消费,如果在消费过程中,发生消费者的变化,比如新增消费者、减少消费者,消费者组都会通过再平衡这个功能,使其最终能继续正常运行,履行消费工作。
在 Kafka中,消费者组再平衡是一个关键机制,用于管理和分配主题分区给消费者组中的各个消费者。再平衡过程可以确保数据负载在消费者之间均匀分布,并在消费者加入或离开时自动调整分区的分配。
当kafka遇到如下三种情况的时候,kafka会触发Rebalance机制:(主题分区变化、消费者节点增删都会引起kafka触发再平衡机制)
(1)新消费者加入:当一个新的消费者加入消费者组时,Kafka需要重新分配分区,以包括新的消费者
(2)消费者离开:当一个消费者离开(无论是正常关闭还是崩溃)时,需要重新分配该消费者负责的分区给其他消费者
(3)主题分区变化:当主题的分区数量发生变化时(例如增删分区),Kafka需要重新分配这些分区

2.Rebalance步骤
Rebalance 步骤
(1)暂停消费:在再平衡过程中,消费者会暂停对消息的消费,以防止在重新分配期间发生数据丢失或重复
(2)触发再平衡:由消费者组协调器(通常是Kafka集群中的一个Broker)触发再平衡
(3)重新分配分区:协调器根据当前消费者组的成员重新分配主题的分区
(4)通知消费者:重新分配完成后,协调器会通知所有消费者新的分配情况
(5)恢复消费:消费者收到新的分配后,恢复消费,开始处理被分配到的新分区
基于上述步骤分析,可以看到【步骤1】中消费者会短暂地暂停消息消费,这可能导致服务中断和延迟。对此,Kafka提供了多种策略(消费者组分区分配策略)来解决这个问题
消费者组分区分配策略(
partition.assignment.strategy)
- (1)Range Assignor:基于范围的分配策略,将分区按照范围分配给消费者
- (2)RoundRobin Assignor:基于轮询的分配策略,分区均匀地分配给消费者
- (3)Sticky Assignor:优先保持当前的分配状态,并尽量减少在再平衡过程中的分区移动
- (4)CooperativeStickyAssignor:和Sticky Assignor的策略是一样,区别在于未受变动的消费者可以继续消费主题
从再平衡的视角,这几种分区策略从大方面考察可以将其分为两个阵营:Eager Rebalance、Incremental Rebalance
3.Rebalance策略
Eager Rebalance(急切的再平衡)
Range Assignor、RoundRobin Assignor、Sticky Assignor都属于Eager Rebalance,可以理解为“急切的再平衡”
它的模式核心是“STW”(stop the world),即一旦触发再平衡,所有消费者就会停止从kafka进行消费,并放弃其分区的成员资格,在这个过程中,整个消费者组会停止处理,因此也成为“STW”事件。但是这种模式是具有一定副作用的:
- 消费者闲置:消费被迫中断,再平衡期间消费者无所事事(处于空闲状态)
- 再平衡影响原有分区格局:当再平衡结束之后,这些消费者后面会重新加入消费者组并获得新的分区分配,但不一定“取回”先前分配给他们的分区,也就是说原来的格局可能全变了

Incremental Rebalance(增量的再平衡)
CooperativeStickyAssignor是2.3版本之后引入一种的优化方案,在此模式下,只有部分分区会从某个消费者移动到另外一个消费者,其它不受重新平衡影响的 Kafka 消费者可以继续处理数据而不会中断。
当然,这样一次执行下来可能分配个数是不均匀的,所以整个消费者组可以经历多次重新平衡,直到找到稳定的分配,因此称为增量重新平衡,可以理解为一点一点地来寻求重平衡。相比于急切重平衡,优点在于消费不会全部暂停,且消费者的分配关系变动较小,当然付出的代价就是完成再平衡的时间可能会更久一些。

4.Group Coordinator(扩展理解)
Group Coordinator是Kafka中负责管理消费者组的协调器,协调器运行在Broker服务器上。Coordinator是Rebalance机制中非常重要的一个角色。每个消费组都会有一个Coordinator,Coordinator负责管理组内的消费者和偏移量管理
消费者管理
每一个Broker节点在启动时,都会创建和开启相应的Group Coordinator 组件(Coordinator是存在于每个Broker上的组件)。每个Consumer Group都有自己的groupid,根据groupid的Hash来决定具体是哪个Broker上的Coordinator为其服务,具体而言是如下机制:
- 当消费者启动时,它会通过向Kafka集群发送请求查找其对应的Group Coordinator
- 一旦找到Group Coordinator,消费者会向其发送加入消费者组请求,以加入消费者组
- Group Coordinator 在收到消费者的加入请求后,会选择一个消费者作为Leader,并向其发送SvncGroup请求,以完成分区分配
- Group Coordinator 负责接收消费者的心跳消息,以检测消费者的存活状态。如果一个消费者在指定的时间内没有发送心跳,Coordinator会认为该消费者已经失效,并触发再平衡。这个时间是可以配置的,如果该值太大,那么Coordinator需要非常长时间才能检测到消费者异常,建议这个时间是在10s以内
偏移量管理
除了消费者管理之外,Group Coordinator还负责管理消费者组的偏移量提交到存储。消费者可以定期提交自己消费到的偏移量,Coordinator会将这些偏移量存储在Kafka的内部主题( consumer offsets)中
内部主题就是说Kafka自己建的主题,而不是用户创建的主题。通过这个记录,等消费者重启之后才能找到之前消费到哪里了,从断点继续消费,这样就可以避免重复消费之前的数据
5.再平衡的影响
基于上述分析,可以理解为再平衡是针对集群变化的自动调节机制,要注意的事,频繁触发再平衡是会带来一些影响的:
(1)重复消费:如果某个消费者离开消费组时还没来得及提交Offset,当再平衡之后,接盘对应分区的消费者就会重复消费,浪费资源。
(2)性能变差:再平衡是需要相对复杂的流程去实施的,在实施再平衡的这个过程中,消费速度也会受到影响
所以,需要避免频繁的再平衡,即尽量避免触发再平衡:
- 分区数量变化:如果是增加分区减少分区这种业务需求上的,一般没法避免,并且一般这种变动不会是频繁
- 消费者数量变化:此处可以避免“误判”误判带来的再平衡,比如某个消费者明明没死(因为网络波动,心跳超时导致被踢出消费组),等会儿心跳恢复了又进去消费组,一进一出就容易带来频繁再平衡。
参数关注
session.timeout.ms:一次session的连接超时时间,如果超过这个时间没心跳就会判定消费组超时,触发再平衡。如果想避免误判,可以将这个值适当调大(5s、10s)heartbeat.interval.ms:心跳时间- 如果设置过大,容易频繁触发再平衡(例如
session.timeout.ms为10s、heartbeat.interval.ms也为10s,则很容易超时),一般保证在超时时间之内,至少有3-5次心跳机会(例如可以设置为3s、4s、5s)
- 如果设置过大,容易频繁触发再平衡(例如