消息队列-①基础篇
消息队列-①基础篇
学习核心
- 消息队列-基础篇
- 核心概念
- 应用场景
- 消息队列学习思路
- 消息队列概念核心、场景应用
- 消息队列实践应用
- 消息队列架构、高可用、高性能
学习资料
Kafka 安装配置教程
消息队列核心概念
1.什么是消息队列?
消息队列(传递消息的队列)遵循先入先出的原则。消息队列具备可靠性、高性能等特点,是大型分布式系统不可缺少的中间件,一般用于异步流程、消息分发、流量削峰等问题,可以通过消息队列实现高性能、高可用、高扩展的架构。
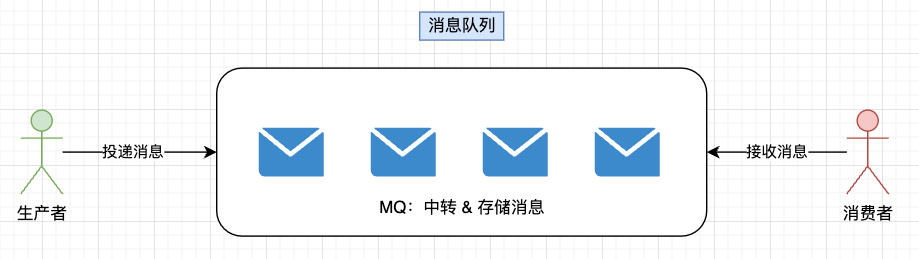
消息队列的重要性
后端技能四大件:编程语言、MySQL、Redis、项目,是后端的必备技能缺一不可。消息队列紧随其后,其重要程度不亚于这四大件。
消息队列是实践类的技术,会应用大于懂原理,在工作中一般而言只要能使用消息队列优化架构就完全够了,即使是面试的话掌握的原理要求也不用像MySQL那么高,因为消息队列解决的问题从结构上来说是比较简单清晰的,就是解决传递消息的问题,结构其实抽象点来就是一个数组,核心能力无非就是收消息、存储消息、消费消息。它不像MySQL要理解底层B+树结构,以及支持复杂的查询能力、例如联表之类的复杂应用。所以消息队列在生产环境,也是很少出现问题的,即使出现问题一般也是找对应的运维处理,对开发者掌握原理的要求就会弱一些。
消息队列技术(分类)
业界比较出名的消息队列有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ。对于这么多消息队列,应该如何选型?如何选择性学习?
如何学习?:毕竟人的精力是有限的,深入学习一种消息队列即可,因为消息队列的使用都是相通的,只要掌握了其中一种消息队列,其他的都是思路复用。
消息队列选型?:而针对消息队列选型时,从实用的角度来分析,正常的团队也只会应用一种熟悉的选型,不会说一个团队里用几种不同的消息队列。因为大多数业务场景无论用哪一种消息队列,都是基本满足需要的,自然哪个用得顺手用哪个;从技术视野广度和深度来看,还是需要对常见队列有个基础的认识,即了解这些消息队列有什么优点或者缺点,做技术栈的横向对比,才能在技术选型时做出合理决策
2.消息队列可以解决什么问题?
消息队列本质是解决消息传递的问题,其它场景都是扩展出来的。
问题思考:一条消息不能直接传递吗?比如服务A不总是能将消息直接传给服务B吗?为啥还要引入一个消息队列?可以结合下述几个案例理解消息队列的引入场景:
【案例1】异步解耦
发送一个通知到短信服务,让短信服务发一条短信给客户,这时候如果要等待短信发完,发送方就会慢,不需要关注结果,就可以实现解耦,解耦的好处后面我们会展开来讲
【案例2】削峰
对于接收方B而言,如果接收方的能力较弱,短时间内无法处理大量的数据,则直接传递消息的方式容易搞崩服务B
比如接收方正常每秒只能处理1000条消息,但是因为搞活动达到瞬间1s有10000条消息打到服务B,服务B处理不过来就容易被搞崩。而通过引入消息队列可以让接收方B按自己的能力来进行协调,把消息压力摊平
【案例3】消息分发
在微服务场景下,如果有一个相同消息要发给10个服务,正常逻辑下就像发送通知一样,依次调用相应的服务发送通知。如果业务扩展新增1个接收服务的话,发布者可能还要调整代码逻辑。
所以现实业务中还有不少场景是没法或者不太适合直接发送消息的。后端领域有一句名言”没什么事是引入一个中间层解决不了的,如果有,那就引入两个“,因此为了解决某些场景下消息传递的问题,选择引入消息队列作为中间层,这就是消息队列的意义。消息队列的应用在实际的业务场景中有着相应的扩展,可以结合相应的场景案例理解消息队列的实践意义
MQ 应用场景
MQ核心:"应用解耦"、"异步提速"、"削峰填谷"、"消息分发",是基于业务场景扩展的概念核心
| 功能(应用场景) | 核心 | 说明 |
|---|---|---|
| 应用解耦 | 针对多服务链路(A->B\C\D)场景 | A可能不需要关注B、C、D的执行结果,只需要传达消息即可 |
| 异步提速 | 针对单个任务执行耗时较长的场景,将同步转异步 | 解耦和异步的最大的区别在于,解耦是业务上本身不需要依赖,而异步则可能需要关注结果(但不会干等结果,而是过段时间再次访问查询结果) |
| 消息分发 | 针对一个服务要向多个服务分发消息的场景 | 引入MQ实现能力复用、业务解耦,具备高扩展性 |
| 削峰填谷 | 针对瞬时流量激增的场景,将瞬时压力平摊到各个时间点 | 异步强调的是单个任务执行耗时较长,可能需要关注执行结果的场景 削峰针对的是单个请求正常,但是在某个时间点请求激增,流量突发服务扛不住的场景 |
(1)应用解耦
场景案例1:发短信场景
例如发短信场景,ServerA给ServerB发送消息,然后ServerB发送短信给客户。很多时候业务是允许ServerA不需要等待ServerB发送完成的响应,只需要传达消息即可。基于这种场景如果采用传统方式,服务A需等待ServerB的响应,就会导致性能变低,还需要关注ServerB的运行结果。
如果可以在业务上消除这种“依赖”,就能获得性能、可靠性等的提升
场景案例2:订单场景(下订单 =》通知其他服务"下单成功",然后其他服务进行处理)
传统方式:当一个子系统的功能需要调用到其他子系统功能服务的时候,如果其他子系统垮掉了,则可能对当前子系统产生影响
基于MQ:MQ相当于一个消息中间件,订单系统只需将用户下单成功的消息传递给MQ,随后其他子系统从MQ中获取到信息,然后各自处理,相互之间不受影响

(2)异步提速
场景案例1:“耗时”场景(异步处理)
如果一个服务接口的处理时间很长,而且无法通过水平扩容来解决(例如无法通过扩容机器),则需要异步处理。
- 例如视频处理场景(涉及到视频下载),受限于网络带宽等因素,扩容无用
- 例如区块链场景(只有单机才能出块),扩容无用
- 例如传统业务流程,需要过10多个微服务,单个请求可能时间不长,但是请求多个微服务需同步等待的话,这个过程就会很难受
基于上述场景分析,用户很难通过同步接口长时间等待结果,因此需要将“同步”转“异步”,例如先将任务丢进消息队列,然后再由消费者慢慢消费,可获得高性能和可靠性
解耦和异步的最大的区别在于,解耦是业务上本身不需要依赖,而异步则可能需要关注结果(但不会干等结果,而是过段时间再次访问查询结果)
场景案例2:电商场景(下订单)
传统方式:用户发起订单,订单系统依次调用其他子系统服务,进而实现其业务逻辑,其响应速度为所有服务调用响应之和
- 例如一开始的电商项目下单涉及到扣库存、下订单,到后期业务发展新增了积分服务、短信通知等功能模块,因此项目的请求链路会越来越长,同步等待整体响应就会越来越慢
基于MQ:用户发起订单通知MQ,则MQ发送消息给各个子系统,每个子系统接收消息并同时处理(异步),相互之间不受影响,整体响应提速
- 引入MQ,可以通过多个模块异步并发执行,以减少请求的等待时间,提升系统总体性能和体验感

(3)流量控制(削峰填谷)
例如一些秒杀活动的瞬时流量如果一次性落在服务上,则服务可能无法承载导致宕机,因此引入MQ作为中间缓冲,平摊请求流量,缓解服务压力
当系统使用处于高峰期,请求瞬间增多,服务器极有可能无法承受负载。(例如:每秒请求5000个,但是系统负载最大处理1000个请求)
在使用了 MQ 之后,可以通过限制消费消息的速度为1000(控制在负载内),将高峰期产生的数据积压在 MQ 中,高峰就被“削”掉了,但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000,直到消费完积压的消息,这就叫做“填谷”。
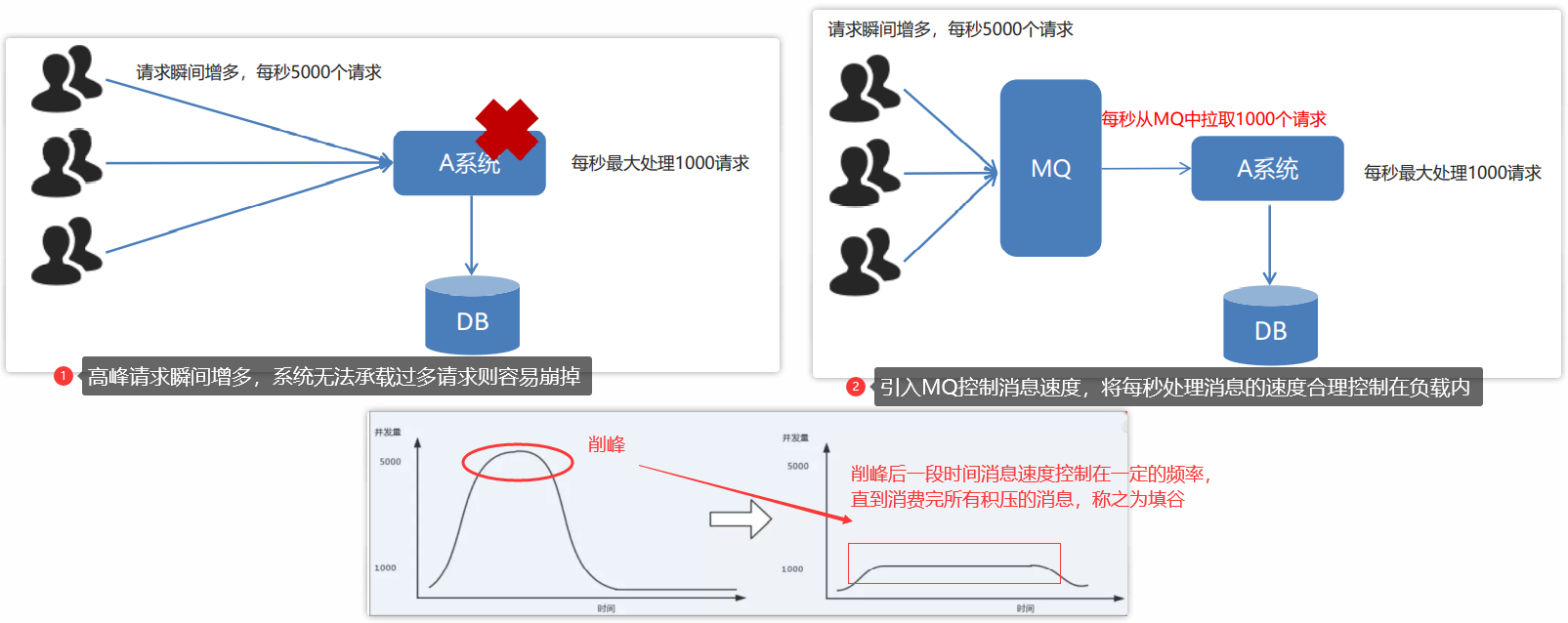
(4)消息分发
假设一个核心服务A,是用来发布某种信号的,发布之后,需要通知到下游服务B、C,这种模式在只有B、C的时候暂时没啥问题。但随着业务需要,可能会有更多的D、E、F接入,这时候A服务就需要更改代码,将消息也传递给这些新加入的节点,每次增加一个新节点,就需要更改一次代码,这个成本和可维护性是很差的
通过引入消息队列,实现能力复用、业务解耦,拥有了高扩展性

3.消息队列的安装配置
Kafka是一个开源的分布式消息引擎/消息中间件,同时Kafka也是一个流处理平台。Kakfa支持以发布/订阅的方式在应用间传递消息,同时并基于消息功能添加了Kafka Connect、Kafka Streams以支持连接其他系统的数据(Elasticsearch、Hadoop等)。Kafka在生产环境下使用通常是集群化部署的,同时也要依赖ZooKeeper集群,这对开发测试环境来说比较重,不过可以通过Docker便捷Kafka单机的方式,节省部署时间以及机器资源
基于Docker部署Kafka单机版,部署成功则可分别启动生产者和消费者进行收发消息测试
启动Kafka Producer
新开一个命令窗口,执行以下命令,启动Kafka Producer,向topic:test发送消息
# 进入容器
docker exec -it kafka-test /bin/bash
# 进入Kafka bin目录
cd /opt/kafka/bin
# 启动Producer
sh kafka-console-producer.sh --broker-list localhost:9092 --topic test
启动Kafka Consumer
新开一个命令窗口,执行以下命令,启动Kafka Consumer,订阅来自topic:test的消息
# 进入容器
docker exec -it kafka-test /bin/bash
# 进入Kafka bin目录
cd /opt/kafka/bin
# 启动Consumer
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
消息队列应用场景
构建Springboot项目,此处示例最简单的kafka应用,完整版本可以结合更完整的整合步骤。简单版本示例参考步骤:
引入kafka依赖
<!-- 引入kafka 相关依赖 --> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>配置kafka参数
# spring相关配置 spring: # kafka 相关配置 kafka: bootstrap-servers: localhost:9092 # 配置kafka连接信息(服务器地址、端口号等)
1.应用解耦
📌场景分析
场景分析
模块A接收前端请求,随后需要调用模块B完成后续事项。一般的流程是模块A需要等待模块B执行完成才能回包给前端,但这种流程很明显回非常依赖模块B的运作情况
如果业务允许,可以思考另一种流程:模块A不用等待模块B处理完成,只需要将信息传递到一个中转站,然后模块B从中转站感知到有任务再去执行即可,而这种中转站就是MQ(达到解耦的作用)
生产场景
【1】发送短信场景:模块A发送消息给模块B,模块B发送短信给客户,对于A而言只需要将消息传达到B即可,不关心B操作(模块间没有强依赖)
【2】工作流场景:例如多级审批场景(流转流程:员工->组长->总监->总经理),对于leader而言,上级审批完是不需要向下级汇报的(消息通知另议),即下级提交审批只需要传达给上级即可(至于上级什么时候审批是他的自由)
【3】订单场景:客户下订单之后可能需要调用多个服务模块处理订单信息(例如库存、支付、物流等),MQ相当于一个消息中间件,订单系统只需将用户下单成功的消息传递给MQ,随后其他子系统从MQ中获取到信息,然后各自处理,相互之间不受影响
👻业务代码示例
基于Springboot 整合kafka模拟测试:
- 传统方式:直接调用接口,模拟服务内部调用、处理逻辑(模拟沉睡10s),等待处理完成响应
- 引入MQ:调用接口,发送消息并响应;消费者监听并消费消息
Service 逻辑
public interface CountService {
public void incrManyTimes(int num);
}
@Service
public class CountServiceImpl implements CountService {
@Override
public void incrManyTimes(int num) {
// 执行原子加操作
AtomicInteger atomicInteger = new AtomicInteger();
int res = 0;
for (int i = 0; i < num; i++) {
// 原子 + 1
res = atomicInteger.incrementAndGet();
}
// 模拟复杂业务逻辑执行时间(沉睡10s)
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 输出结果
System.out.println("最终执行结果:" + res);
}
}
传统方式实现
@RestController
@RequestMapping("/count")
public class CountController {
@Autowired
private CountService countService;
// 传统方式
@PostMapping(value = "/decoupling",consumes = "application/json;charset=utf-8")
public ResponseEntity<String> decoupling(@RequestBody IncrCountReq incrCountReq) {
countService.incrManyTimes(incrCountReq.getNum());
return ResponseEntity.ok("success");
}
}
引入MQ实现
@RestController
@RequestMapping("/kafka/producer")
@Slf4j
public class ProducerController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
CountService countService;
// 引入MQ:此处生产者做发送消息(执行逻辑由消费者实现)
@PostMapping(value = "/decouplingWithMQ",consumes = "application/json;charset=utf-8")
public ResponseEntity<String> decouplingWithMQ(@RequestBody IncrCountReq incrCountReq) {
// 传递消息,发送到kafka消息队列
kafkaTemplate.send("tp-mq-decoupling", JSON.toJSONString(incrCountReq));
return ResponseEntity.ok("success");
}
// 模拟消费者消费
// @KafkaListener(topics = "tp-mq-decoupling",groupId = "TEST_GROUP",concurrency = "1",containerFactory = "kafkaManualAckListenerContainerFactory")
@KafkaListener(topics = "tp-mq-decoupling",groupId = "TEST_GROUP") // 使用Springboot的KafkaListener注册一个kafka消费者
// public void topicConsumer(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
public void topicConsumer(ConsumerRecord<?,?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
// 解析消息
Object msg = message.get();
log.info("接收到的kafka消息:{}",msg);
try{
// 模拟消费消息
countService.incrManyTimes(JSONObject.parseObject(msg.toString(),IncrCountReq.class).getNum());
log.info("kafka消息消费成功:topic:{} msg:{}",topic,msg);
}catch (Exception e){
e.printStackTrace();
log.error("kafka消息消费失败:topic:{} msg:{}",topic,msg);
}
}
}
}
curl 测试
# 1.传统方式接口测试
curl -w "\n cost %{time_total}%s" -H "Trace-ID:holic-x" -H "Content-Type:application/json;charset=utf-8" -H "User-ID:001" http://localhost:8081/api/count/decoupling -d '{"num":1000000}'
-- output
success
cost 10.142533s
# 2.引入MQ方式接口测试
curl -w "\n cost %{time_total}%s" -H "Trace-ID:holic-x" -H "Content-Type:application/json;charset=utf-8" -H "User-ID:001" http://localhost:8081/api/kafka/producer/decouplingWithMQ -d '{"num":1000000}'
-- output
success
cost 0.093096%s%
结合上述执行结果分析,刨去10s业务执行逻辑,可以看到引入MQ之后,响应时间从0.1秒级降低到0.01秒级别,降低了一个量级。且随着业务处理逻辑越来越复杂,这个时间响应对比会更加明显。
此处需注意一点,虽然整体处理时间是包括”请求生成消息+消费者处理消息“,看起来整体时间并没有缩短多少,但为什么说性能提升了。这里主要是站在调用者的角度理解,此处是采用”同步转异步“的思路去处理,对于调用者A而言,它并不关心调用服务B后B是怎么处理的,只需要负责消息传达正常即可,所以对比原有的同步等待B响应,其响应耗时大大缩短,因此单位时间内可以接收并处理更多的任务,然后将消息存放到MQ中,让服务B自行进行消费。
此处一方面强调的是"应用解耦"的概念,即服务A不需要依赖于服务B的响应结果,而服务B也不会因为服务A故障而受到影响。另一方面体现的是"异步提速"的概念,将原有同步操作转为异步操作(但与解耦概念不同的是,异步操作场景中服务A可能需要依赖于服务B的响应,虽然也是通过MQ传达消息,然后等待服务B消费消息,但服务A后续还会找时机去确认服务B的响应状态)
总结分析
基于上述测试场景,通过观察引入MQ前后接口的响应时间,可以直观感受到解耦的好处,实际上解耦还具备很多优势:
- 可维护性增加:不用关注下游的返回结果(例如直接调用下游服务则需要相应处理异常等),解耦后只需要关注消息队列调用是否正常即可
- 可靠性增加:服务模块间相互不受影响,就算某个服务挂了也不会影响其他服务的正常执行(例如下游挂了也不影响前面的处理流程,等下游恢复之后又可以正常消费堆积的信息)
- 响应时间变快:结合上述案例分析可以明确感受到
- 模块测试更方面:不用部署下游服务也可以自测业务,除非是一些中间节点强耦合的
综上,解耦本质上是在服务模块调用时,A不需要关注B的事情,也不会受B本身变动的影响
2.削峰填谷
📌场景分析
场景分析
当服务的处理能力(承压能力)有限,无法处理瞬时流量时,则服务容易被搞崩。而通过引入MQ,将要处理的请求放入消息队列中,随后服务根据自身的处理状态慢慢去消费这批任务,将”瞬时请求“平摊到”一段时间“去均匀处理。
常见的场景有:
- 主服务扛不动:瞬时流量请求某个服务,服务的承压能力有限,无法承载
- 下游服务扛不住:瞬时流量请求某个服务A,服务A中需要调用其他的模块服务(B、C等),虽然服务A可以承载瞬时流量压力,但是这批压力同样会给到同一流程的B、C,如果被调用的其他模块服务的承载能力有限或者存在资源限制导致无法处理这些请求,那么可能会搞崩B、C模块
针对上述问题,可以通过引入MQ,将要处理的请求先存放在消息队列中,然后再由相应的服务慢慢消费。基于上述场景,还需考虑MQ应该放在哪个阶段:
- 针对主服务扛不动:MQ放在请求和主服务之间,将接收到的请求放在消息队列,然后相应的主服务慢慢消费
- 针对下游服务扛不动:MQ可以介入的地方有两处,但需结合业务实际来分析MQ放在哪里可以得到最大效能提升
- MQ放在请求和服务A之间,相当于从源头开始进行”削峰“,A可以慢慢处理请求,不会将压力给到B、C,但如此一来也相应限制的A的服务能力
- MQ放在服务A和下游服务(B、C)之间,服务A可以正常承载请求,然后将调用下游服务的请求放在消息队列,让下游服务自行进行消费,如此一来不仅让服务A的服务能力充分发挥,也不会给下游服务造成过大的请求冲击
最常见的一个应用场景就是订单服务场景:例如秒杀抢购下单肯定是要尽可能多的去处理订单,至于订单关联的后续调用操作则可以慢慢执行,因此通常会将MQ放在主服务和下游服务之间,让主服务充分发挥能力的同时减轻下游服务的负担
生产场景分析
(1)秒杀场景优化分析:
一般会用Redis预抢名额,处理之后再发给MySQL,因为一般商品秒杀总数都很少(几百或几千)。即大部分流量都没法在Redis抢到名额,从某种意义上来说,Redis已经实现了流量过滤,所以只会有商品数量大小的请求打到MySQL。正常情况下MySQL接收到的瞬时流量不会太高,比如原本1亿个请求,抢1000个商品,那么最终总共到达MySQL的请求量就在1000左右
但是如果商品数量是2w的话,基于上述设计,则会有2w数据一瞬间秒完打到MySQL,此时MySQL就扛不住了(正常情况下MySQL的负载是5000/s)。对于请求量小于5k的情况,MySQL可以抗。但是如果大于5000的话,就得考虑相应的优化方案了,例如此处可以引入消息队列进行削峰处理
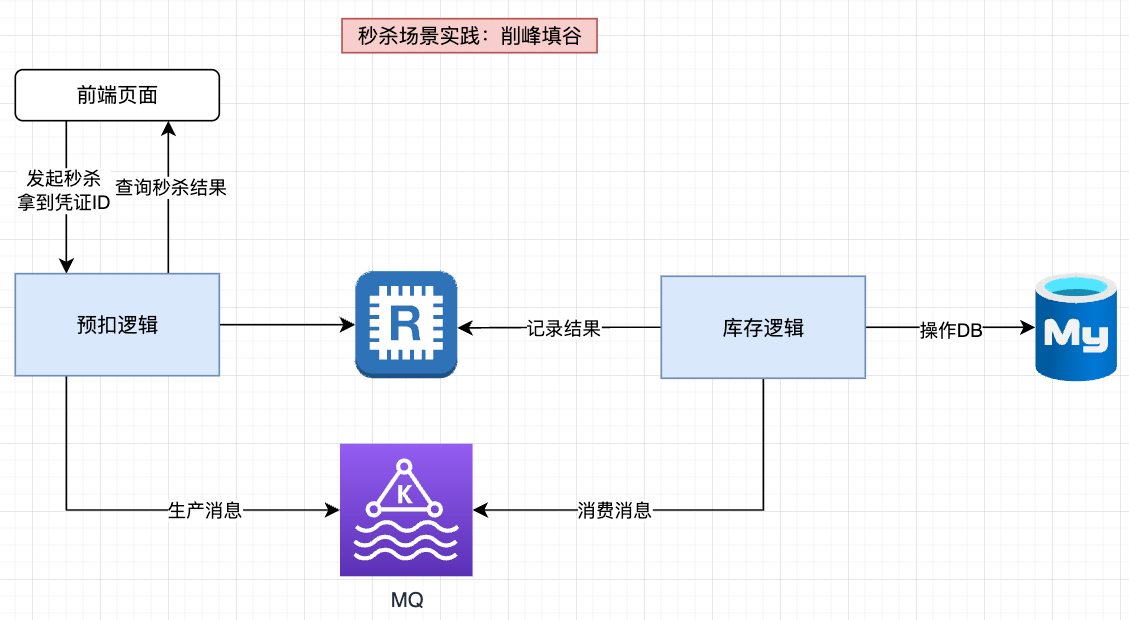
(2)脚本数据统计:例如凌晨数据录入场景中,有些业务会晚上跑脚本,向统计服务发送数据。如果数据量非常大,也需要消息队列进行削峰
👻业务代码示例
基于Springboot 整合kafka模拟测试:(实际MQ的使用逻辑是上述应用解耦中的应用是类似的,只不过此处不是测试单次调用,而是模拟”瞬时流量“多次调用观察响应结果)
- 传统方式:直接调用接口,模拟服务内部调用、处理逻辑(模拟沉睡1s),等待处理完成响应
- 引入MQ:调用接口,发送消息并响应;消费者监听并消费消息
service 下游服务逻辑
/**
* 模拟下游服务
*/
public interface FlowService {
public void handler();
}
@Service
public class FlowServiceImpl implements FlowService {
@Override
public void handler() {
System.out.println("flow service handle ......");
}
}
接口模拟(传统实现方式、引入MQ)
@Slf4j
@RestController
@RequestMapping("/flow")
public class FlowController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private FlowService flowService;
// 传统方式
@GetMapping(value = "/peakClipping")
public ResponseEntity<String> peakClipping() {
// 模拟调用下游服务
flowService.handler();
return ResponseEntity.ok("success");
}
// 引入MQ:此处生产者做发送消息(执行逻辑由消费者实现)
@GetMapping(value = "/peakClippingWithMQ")
public ResponseEntity<String> peakClippingWithMQ() {
String msg = "hello kafka";
// 传递消息,发送到kafka消息队列
kafkaTemplate.send("tp-mq-peakClipping", msg);
return ResponseEntity.ok("success");
}
// 模拟消费者消费
@KafkaListener(topics = "tp-mq-peakClipping",groupId = "TEST_GROUP") // 使用Springboot的KafkaListener注册一个kafka消费者
// public void topicConsumer(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
public void topicConsumer(ConsumerRecord<?,?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
// 解析消息
Object msg = message.get();
log.info("接收到的kafka消息:{}",msg);
try{
// 模拟消费消息
flowService.handler();
// 模拟沉睡1s(假设消费者每秒只能处理1条消息,通过主动sleep模拟这种情况)
TimeUnit.SECONDS.sleep(1);
log.info("kafka消息消费成功:topic:{} msg:{}",topic,msg);
}catch (Exception e){
e.printStackTrace();
log.error("kafka消息消费失败:topic:{} msg:{}",topic,msg);
}
}
}
}
接口测试(模拟瞬时请求)(linux或者mac环境下执行脚本)
- 普通接口测试(
peakClipping_many.sh)
#!/bin/bash
count=1
while [ $count -le 10 ]
do
curl -w "\n cost %{time_total}%s" -H "Trace-ID:holic-x" -H "User-ID:001" http://localhost:8081/api/flow/peakClipping
count=$((count+1))
done
- 引入MQ接口测试(
peakClipping_many_with_mq.sh)
#!/bin/bash
count=1
while [ $count -le 10 ]
do
curl -w "\n cost %{time_total}%s" -H "Trace-ID:holic-x" -H "User-ID:001" http://localhost:8081/api/flow/peakClippingWithMQ
count=$((count+1))
done
结果测试
从上述结果分析,执行脚本1s内会发送10次请求。
- 传统普通接口:所有的请求压力会同样打到下游服务FlowService
- 引入MQ:服务正常接收请求,不是直接调用下游服务进行处理,而是将请求转到消息队列,然后由kafka消费者进行处理(此处模拟消费者每秒只能处理一条消息)
总结分析
削峰的本质是减少对"下游"的流量冲击,更安全、更可控,拥有更高的承载能力
削峰是用于突发的瞬时流量,而不是持续流量,如果说流量一直很大,单机处理性能达到瓶颈,最后还是需要业务服务水平扩容去支持
如何理解?=》例如流量一直持续很大,那么上游服务就会一直接收请求然后传到MQ中,当消费者能力不足就会导致MQ不断堆积新的任务,因此就会出现”单机性能处理达到瓶颈“的问题,需要通过水平扩容以支撑更高的处理性能(例如多加几个消费者处理任务等)
3.消息队列分发
📌场景分析
场景分析
一个模块A需要同时发送同一条消息给模块B、C、D,传统模式依次发送消息即可,但是如果新增消息接收节点的话,则模块A的业务逻辑可能需要进行更新适配,就会带来可扩展性和维护性差的问题
实际业务场景
(1)信息更新场景
比如某个用户信息更新了,而B、C、D三个模块都需要缓存这个信息,那么用户信息更新之后就可以发一条信息到消息队列,B、C、D只要订阅了相关主题,就都可以收到这条信息
(2)数据分析场景
假设一个用户请求进到模块A,这类请求非常重要,需要找3个不同的风控模块B、C、D去处理,待3家都认为没问题才放行,此时也可以发一条信息到消息队列,B、C、D只要订阅了相关主题,就都可以收到这条信息并进行反馈,模块A接收到这三家反馈之后进而确认是否予以放行
👻业务代码示例
Service 逻辑
public interface NoticeService {
public void notice(String svr,String msg);
}
@Service
public class NoticeServiceImpl implements NoticeService {
@Override
public void notice(String svr, String msg) {
System.out.println(" 发送消息 msg:" + msg + " 通知:" + svr);
switch (svr){
case "svrB":
handleBySvrB(msg);
break;
case "svrC":
handleBySvrC(msg);
break;
case "svrD":
handleBySvrD(msg);
break;
}
}
// 模拟服务B、C、D模块
private void handleBySvrB(String msg){
System.out.println("SvrB received msg:" + msg);
}
private void handleBySvrC(String msg){
System.out.println("SvrB received msg:" + msg);
}
private void handleBySvrD(String msg){
System.out.println("SvrB received msg:" + msg);
}
}
controller 接口测试
@Slf4j
@RestController
@RequestMapping("/dispatch")
public class DispatchController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private NoticeService noticeService;
// 传统方式
@GetMapping(value = "/notice")
public ResponseEntity<String> notice() {
String msg = "Hello kafka";
// 依次通知各个服务节点
noticeService.notice("svrB",msg);
noticeService.notice("svrC",msg);
noticeService.notice("svrD",msg);
// ..... 更多节点接入
return ResponseEntity.ok("success");
}
// 引入MQ:此处生产者做发送消息(执行逻辑由消费者实现)
@GetMapping(value = "/noticeWithMQ")
public ResponseEntity<String> noticeWithMQ() {
String msg = "hello kafka";
// 传递消息,发送到kafka消息队列
kafkaTemplate.send("tp-mq-dispatch", msg);
return ResponseEntity.ok("success");
}
}
消费者模拟
此处补充了一个containerFactory概念,是用于自定义kafka配置的,此处可以引用自行构建的Bean(此处简单示例,结合业务场景进行配置)
/**
* 手动自定义 kafka 消费者 ContainerFactory 配置demo
*/
@Configuration
//@EnableConfigurationProperties(KafkaProperties.class)
public class KafkaConsumerConfig {
@Autowired
private KafkaProperties properties;
// @Value("${监听服务地址}")
// private List<String> myServers;
// @Bean("kafkaManualAckListenerContainerFactory")
@Bean("myKafkaContainerFactory")
// @ConditionalOnBean(ConcurrentKafkaListenerContainerFactoryConfigurer.class)
public ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, consumerFactory());
return factory;
}
//获得创建消费者工厂
public ConsumerFactory<Object, Object> consumerFactory() {
KafkaProperties myKafkaProperties = JSON.parseObject(JSON.toJSONString(this.properties), KafkaProperties.class);
//对模板 properties 进行定制化
//....
//例如:定制servers
// myKafkaProperties.setBootstrapServers(myServers);
return new DefaultKafkaConsumerFactory<>(myKafkaProperties.buildConsumerProperties());
}
}
此处模块B、C、D就是相应的消费者,归属于不同的组
@Slf4j
@Component
public class DispatchConsumer {
// ------------------ 模拟消费者消费(此时消费者应对应不同的service处理消息) ------------------------
// 使用Springboot的KafkaListener注册一个kafka消费者
@KafkaListener(topics = "tp-mq-dispatch",groupId = "TEST_GROUP1",concurrency = "1",containerFactory = "myKafkaContainerFactory")
public void topicConsumerB(ConsumerRecord<?,?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
// 解析消息
Object msg = message.get();
log.info("接收到的kafka消息:{}",msg);
try{
// 模拟消费消息
System.out.println("SvrB received msg:" + msg);
log.info("kafka消息消费成功:topic:{} msg:{}",topic,msg);
}catch (Exception e){
e.printStackTrace();
log.error("kafka消息消费失败:topic:{} msg:{}",topic,msg);
}
}
}
// 使用Springboot的KafkaListener注册一个kafka消费者
@KafkaListener(topics = "tp-mq-dispatch",groupId = "TEST_GROUP2",concurrency = "1",containerFactory = "myKafkaContainerFactory")
public void topicConsumerC(ConsumerRecord<?,?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
// 解析消息
Object msg = message.get();
log.info("接收到的kafka消息:{}",msg);
try{
// 模拟消费消息
System.out.println("SvrC received msg:" + msg);
log.info("kafka消息消费成功:topic:{} msg:{}",topic,msg);
}catch (Exception e){
e.printStackTrace();
log.error("kafka消息消费失败:topic:{} msg:{}",topic,msg);
}
}
}
// 使用Springboot的KafkaListener注册一个kafka消费者
@KafkaListener(topics = "tp-mq-dispatch",groupId = "TEST_GROUP3",concurrency = "1",containerFactory = "myKafkaContainerFactory")
public void topicConsumerD(ConsumerRecord<?,?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if(message.isPresent()){
// 解析消息
Object msg = message.get();
log.info("接收到的kafka消息:{}",msg);
try{
// 模拟消费消息
System.out.println("SvrD received msg:" + msg);
log.info("kafka消息消费成功:topic:{} msg:{}",topic,msg);
}catch (Exception e){
e.printStackTrace();
log.error("kafka消息消费失败:topic:{} msg:{}",topic,msg);
}
}
}
}
模拟测试
# 1.传统方式接口测试
curl -w "\n cost %{time_total}%s" -H "Trace-ID:holic-x" -H "User-ID:001" http://localhost:8081/api/dispatch/notice
# 2.引入MQ方式接口测试
curl -w "\n cost %{time_total}%s" -H "Trace-ID:holic-x" -H "User-ID:001" http://localhost:8081/api/dispatch/noticeWithMQ
传统方式下如果新增”消息接收节点“,则需要相应迭代开发通知服务的逻辑
引入MQ后,通知服务只需要将消息传递到MQ中,订阅了相应topic的服务模块会相应监听,一旦有新的消息则会进行相应处理(此处svrB、svrC、svrD对应不同的groupId表示隶属不同分组,可以处理相应的消息,而对于同一个分组的节点不同重复消费同一条信息),可以观察到同一条消息被多个消费者消费了(结合控制台输出分析),当有新的节点加入时,只需要订阅相应的topic即可,做到模块解耦(服务版本迭代各自不会相互影响)、分发(功能复用)
从整体分析上看,消息分发可以理解为群发场景下的解耦方案(MQ的功能都是基于业务场景扩展出来的,有很多种玩法,关注重点核心即可)
4.消息队列选型
在上述场景案例中都是基于kafka作为演示,但实际上还有很多消息队列可供选择。因此要结合实际业务场景选择合适的队列去适配。于个人而言,选型思路分析可以如下:为什么选择kafka?为什么不用xxx?
其实大多是场景中选用主流消息队列基本够用,因此在选择上考虑结合项目需求和业务场景去做考量
- 项目需求:对性能和可靠性有要求(例如要支持5000QPS),基于Kafka和RocketMQ分布式的高可用特性,可以作为参考
- 功能扩展需求:队列的其他功能暂时不作为重要的考量点
- 团队技术栈:加上团队此前已经有比较成熟的技术体系,选择选择xxx
业界比较出名的消息队列有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ、Pulsar。ZeroMQ过于轻量,主要用于学习,实际不会用于生产,此处主要以Kafka、RocketMQ、Pulsar、RabbitMQ、ActiveMQ 进行不同维度的对比
| 考虑因素 | Kafka | RocketMQ | Pulsar | RabbitMQ | ActiveMQ |
|---|---|---|---|---|---|
| 单机吞吐 | 10w级 | 10w级 | 10w级 | 万级 | 万级 |
| 高可用 | 分布式 | 分布式 | 分布式 | 主从 | 主从 |
| 消息回溯 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 时效性 | 毫秒级 | 毫秒级 | 毫秒级 | 微秒级 | 微秒级 |
| 延时消息 | 不支持 | 支持 | 支持 | 支持 | 支持 |
| 重试队列 | 不支持 | 支持 | 支持 | 支持 | 支持 |
| 消费语义 | 至少一次 | 至少一次 | 至少一次 | 至少一次 | 至少一次 |
| 支持主题数 | 百级 | 千级 | 百万级 | 百万级 | 千级 |
| 管理界面 | 中等 | 中等 | 中等 | 中等 | 中等 |
消息选型(选型参考要结合业务场景进行择选)
例如要支持天猫双十一类超大型的秒杀活动(一锤子买卖概念),对于管理界面、消息回溯的要求并不太高,主要关注”吞吐量“,所以优先选Kafka和RocketMQ这种更高吞吐的
例如要做一个公司的中台,对外提供能力,那可能会有很多主题接入,因此考虑支持的主题数,像Kafka(百级的)就不太符合要求,可以根据情况考虑千级的RocketMQ,甚至百万级的RabbitMQ
例如金融类业务场景,重点考虑的就是稳定性、安全性,则分布式部署的Kafka和Rocket就更有优势
例如一些延时的业务场景特别多,则考虑是否天然支持延时消息,这种情况下Kafka实现起来麻烦点
针对”时效性“,RabbitMQ以微秒的时效作为招牌,但实际上”毫秒和微秒“在绝大多数情况下,感知上并没有多大区别,加上网络带来的波动,这一点在生产过程中,反而不会作为重要的考量
其它的特性,如消息确认、消息回溯也经常作为考量的场景,但管理界面的话视公司而定了,毕竟公司内部有自己的运维体系,不作为重要考量