MySQL-基础篇
MySQL-基础篇
学习核心
SQL命令
数据库操作:操作数据库(show、use、create等)
查询语句:
- 查询涉及到的操作符:and、or、int、not in、between、like、is null、exists、distinct
- 查询涉及到的子句:where、order by、limit
- 多表查询相关:join(内连接、左连接、右连接)、union(组合查询)
- 高级查询相关:
- 聚合函数:count(总数)、max(最大值)、min(最小值)、sum(综合)、avg(平均值)
- 汇总、分组:group by、having
- 子查询相关:子查询用法和原理分析
增删改语句:
- 增删改相关:insert、update、delete
高阶语法:函数、视图、存储过程、触发器
字段和表结构设计
SQL刷题
学习资料
书籍:MySQL必知必会
TODO:
- order by的工作原理(底层)
- join 工作原理(底层)
- count 工作原理(底层)
- group by 工作原理(底层)
数据库术语
数据库概念
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
- 关系型数据库:RDBMS(Relational Database Management System),建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据,由多张相互连接的二维表组成的数据库
- 非关系型数据库(NoSQL):用于存储和管理非结构化的数据库系统(例如键值存储、文档存储、列族存储、图形存储等)
DBMS VS SQL VS DB
三者之间的关系:DBMS执行SQL,进而操作DB
| 名称 | 全称 | 简称 |
|---|---|---|
| 数据库 | 存储数据的仓库,数据是有组织的进行存储 | DataBase(DB) |
| 数据库管理系统 | 操纵和管理数据库的大型软件 | DataBase Management System(DBMS) |
| SQL:结构化查询语言 | 操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准 | Structured Query Language(SQL) |
RDBMS术语
| 术语 | 说明 |
|---|---|
| 数据库 | 一些关联表的集合(一个关系型数据库由一个或数个表格组成) |
| 数据表 | 数据的矩阵(一个数据库中的表类似一个电子表格) |
| 列 | 一列(数据元素) 包含了相同类型的数据(例如邮政编码的数据) |
| 行 | 一行(元组或记录)是一组相关的数据(例如一条用户订阅的数据) |
| 冗余 | 存储两倍数据,冗余降低了性能,但提高了数据的安全性 |
| 主键 | 主键是唯一的(一个数据表中只能包含一个主键) |
| 外键 | 外键用于关联两个表 |
| 复合键 | 复合键(组合键)将多个列作为一个索引键,一般用于复合索引 |
| 索引 | 类似于书籍的目录,使用索引可快速访问数据库表中的特定信息 索引是对数据库表中一列或多列的值进行排序的一种结构 |
| 参照完整性 | 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性 |
| 表头(header) | 每一列的名称 |
| 列(col) | 具有相同数据类型的数据的集合 |
| 行(row) | 每一行用来描述某条记录的具体信息 |
| 值(value) | 行的具体信息, 每个值必须与该列的数据类型相同 |
| 键(key) | 键的值在当前列中具有唯一性 |
数据库逻辑设计
1.三大范式
核心要义:
- 第一范式要求所有属性都是不可分的基本数据项
- 第二范式解决部分依赖
- 第三范式解决传递依赖
有时候不必过度追求所谓的数据库范式标准,部分场景下适当引入反范式设计来提升性能,在进行数据表结构设计的时候可尽量关注以下几点细节:
- 每张表要设定一个主键(例如自增主键ID、UUID主键、业务自定义生成主键ID)
- 消除冗余数据存在的可能
- 无需过度追求范式标准,适当切入反范式设计场景
第一范式
1NF 对属性原子性:要求属性具有原子性,不可再分解
例如学生(学号,姓名,性别,出生日期),如果认为"出生日期"还可以再分成(出生年、出生月、出生日),它就不是第一范式了,否则是
第二范式
2NF 对记录的唯一性:要求记录有唯一标识(即实体的唯一性),不存在部分依赖
例如数据表:学号、课程号、姓名、学分,这个表体现了两个信息:学生信息、课程信息。由于此处非主键字段必须依赖主键(学分依赖课程号、姓名依赖学号),因此并不符合第二范式
可能存在的问题:依赖过重,数据的CRUD操作对记录影响较大
- 数据冗余:每条记录都含有相同信息
- 删除异常:删除所有学生成绩,就把课程信息全删除了
- 插入异常:学生未选课,无法记录进数据库
- 更新异常:调整课程学分,所有行都调整
正确的拆分做法:学生:student(学号,姓名);课程:course(课程号,学分);选课关系:student_course(学号,课程号,成绩)
第三范式
如果一个关系属于第二范式,并且在**两个(或多个)非主键属性之间不存在函数依赖**(非主键属性之间的函数依赖也称为传递依赖),那么这个关系属于第三范式
3NF是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖
例如数据表:学号, 姓名, 年龄, 学院名称, 学院电话,该表属于第二范式(主键由单个属性组成),其存在依赖传递:(学号) → (姓名)→(所在学院) → (学院电话) ,且可能存在问题:
- 数据冗余:有重复值
- 更新异常:由于有重复的冗余信息,修改时需要通知修改多个字段,否则会出现数据不一致的情况
正确的拆分做法:学生:(学号, 姓名, 年龄, 所在学院);学院:(学院,学院名称, 电话)
消除冗余的关键是解决部份依赖和传递依赖,本质上就是尽可能减少冗余数据,因此在设计数据表结构的时候,可以考虑通过主外键的形式关联存储数据(例如订单表中存放订单关联的用户信息,保存用户ID即可)
反范式化
一般说来,数据库只需满足第三范式(3NF)就行了。
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余,达到以空间换时间的目的
〖例〗:如订单表,“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法
在Rose 2002中,规定列有两种类型:数据列和计算列。“金额”这样的列被称为“计算列”,而“单价”和“数量”这样的列被称为“数据列”
在一些业务场景中,可以通过JSON数类型来实现反范式化,进而提升存储效率
范式化 VS 反范式化
| 优点 | 缺点 | |
|---|---|---|
| 范式化 | 【1】可尽量减少数据冗余 【2】范式化的更新操作会更快、表通常比反范式化小 | 【1】查询时涉及多表关联查找,性能较低 【2】更难进行索引优化 |
| 反范式化 | 【1】可尽量减少表的关联 【2】可更好地进行索引优化 | 【1】存在数据冗余和数据维护异常 【2】对数据地修改需要更多地成本 |
2.自增主键的设计场景
BIG INT自增主键
使用 BIGINT 的自增类型作为主键的设计仅仅适合非核心业务表,比如告警表、日志表等。真正的核心业务表,一定不要用自增键做主键。因为使用BIG INT自增主键可能会存在以下问题:
- 自增回溯问题:低版本MySQL存在自增回溯问题,一些主键ID可能会被重复利用导致异常
- 安全性问题:可以通过访问接口剖析业务主键规则,然后定向攻击系统
- 并发性能问题:自增主键是在服务端产生,并发场景下会导致竞争同一把锁
- 分布式架构场景:自增主键时针对单个服务端,无法确保分布式场景下主键的唯一性
如果非要使用BIG INT策略,则需注意对上述问题的解决
- 针对自增回溯问题,可以通过升级MySQL版本解决(8.0后版本会将每个表的自增值持久化,进而解决自增回溯问题)
- 针对并发性能问题,可以通过设定MySQL参数 innodb_autoinc_lock_mode 设置为2来获取自增值的最大并发性能
- 针对互联网海量并发架构场景,更推荐使用UUID或者业务自定义生成主键
UUID自增主键
UUID(Universally Unique Identifier)代表全局唯一标识 ID。显然,由于全局唯一性,可以把它用来作为数据库的主键select UUID();
根据Version1规范,MySQL中的UUID由以下几部分组成:UUID = 时间低(4字节)- 时间中高+版本(4字节)- 时钟序列 - MAC地址
前 8 个字节中,60 位用于存储时间,4 位用于 UUID 的版本号,其中时间是从 1582-10-15 00:00:00.00 到现在的100ns 的计数。
60 位的时间存储中,其存储分为:
- 时间低位(time-low),占用 12 位;
- 时间中位(time-mid),占用 2 字节,16 位;
- 时间高位(time-high),占用 4 字节,32 位;
需要特别注意的是,在存储时间时,UUID 是根据时间位逆序存储, 也就是低时间低位存放在最前面,高时间位在最后,即 UUID 的前 4 个字节会随着时间的变化而不断“随机”变化,并非单调递增。而非随机值在插入时会产生离散 IO,从而产生性能瓶颈。这也是 UUID 对比自增值最大的弊端。424502e5-2fce-11ef-a54b-18c04d2b57bf
为了解决这个问题,MySQL 8.0 推出了函数 UUID_TO_BIN,它可以把 UUID 字符串:
- 通过参数将时间高位放在最前,解决了 UUID 插入时乱序问题;
- 去掉了无用的字符串”-“,精简存储空间;
- 将字符串其转换为二进制值存储,空间最终从之前的 36 个字节缩短为了 16 字节
# MySQL8.0 提供函数BIN_TO_UUID支持将二进制值反转为UUID字符串
SELECT UUID_TO_BIN('424502e5-2fce-11ef-a54b-18c04d2b57bf',TRUE) as UUID_BIN;
SELECT UUID_TO_BIN(UUID()); // �UY�/��K�M+W� 乱码问题
# 查询乱码问题解决:需要使用支持该格式的表,此处在创建表可使用BINARY(16)类型来存储UUID的二进制格式
CREATE TABLE example (
id BINARY(16)
);
INSERT INTO example values (UUID_TO_BIN(UUID()))
SELECT BIN_TO_UUID(id) FROM example;
# MySQL8.0版本之前没有函数BIN_TO_UUID、UUID_TO_BIN,可通过UDF解决
CREATE FUNCTION MY_UUID_TO_BIN(_uuid BINARY(36))
RETURNS BINARY(16)
LANGUAGE SQL DETERMINISTIC CONTAINS SQL SQL SECURITY INVOKER
RETURN
UNHEX(CONCAT(
SUBSTR(_uuid, 15, 4),
SUBSTR(_uuid, 10, 4),
SUBSTR(_uuid, 1, 8),
SUBSTR(_uuid, 20, 4),
SUBSTR(_uuid, 25) ));
CREATE FUNCTION MY_BIN_TO_UUID(_bin BINARY(16))
RETURNS CHAR(36)
LANGUAGE SQL DETERMINISTIC CONTAINS SQL SQL SECURITY INVOKER
RETURN
LCASE(CONCAT_WS('-',
HEX(SUBSTR(_bin, 5, 4)),
HEX(SUBSTR(_bin, 3, 2)),
HEX(SUBSTR(_bin, 1, 2)),
HEX(SUBSTR(_bin, 9, 2)),
HEX(SUBSTR(_bin, 11)) ));
在游戏行业的用户表结构设计场景中,推荐使用 UUID 作为主键,而不是用自增 ID。因为当发生合服操作时,由于 UUID 全局唯一,用户相关数据可直接进行数据的合并,而自增 ID 却需要额外程序整合两个服务器 ID 相同的数据,这个工作是相当巨大且容易出错的
业务自定义生成主键
UUID 虽好,但是在分布式数据库场景下,主键还需要加入一些额外的信息,这样才能保证后续二级索引的查询效率(具体这部分内容将在后面的分布式章节中进行介绍)。牢记:分布式数据库架构,仅用 UUID 做主键依然是不够的。 所以,对于分布式架构的核心业务表,推荐类似如下的设计,比如:
PK = 时间字段 + 随机码(可选) + 业务信息1 + 业务信息2 ......
电商业务中,订单表是其最为核心的表之一,可以先打开淘宝 App,查询下自己的订单号,可以查到类似如下的订单信息:1550672064762308113,订单号显然是订单表的主键,但并不是自增整形。可以发现所有订单号的后 6 位都是相同的,都为308113:1550672064762308113、1481195847180308113、1431156171142308113、1431146631521308113
可以理解为淘宝订单号的最后 6 位是用户 ID 相关信息,前 14 位是时间相关字段,这样能保证插入的自增性,又能同时保留业务的相关信息作为后期的分布式查询
数据库操作
数据库操作常用命令
| 常用命令 | SQL语句 |
|---|---|
| 查看数据库 | show databases |
| 使用数据库 | use [databaseName] |
| 创建数据库 | create database [databaseName] |
| 查看表 | show tables; |
| sql中导入数据 (执行sql脚本) | source 全路径(指定sql脚本的路径)(路径中不能出现中文) |
| 查看MySQL版本 | select version(); |
| 查看当前使用的数据库 | select database(); |
| 删除数据库 | drop database [if exists] databaseName |
# 1.查看所有数据库
show databases;
# 2.使用指定数据库(MySQL默认提供两个示例数据库:world、sakila)
use world;
show tables; // 查看指定数据库下的所有表
# 3.查看当前MySQL版本
select version();
# 4.查看当前使用的数据库
select database();
# 5.查看创建数据库的信息
show create database world;
SQL语句分类:DDL、DML、DQL、DCL、TCL
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data DefinitionLanguage | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的 |
| TCL | Transaction Control Language | 事务控制语言,用于管理数据库事务 |
DDL : 数据定义语言 (Data Definition Language) ,对表结构进行操作
- create:创建
- alter:修改
- drop:删除
DML : 数据操作语言 (Data Manipulation Language),对表当中的数据进行增删改查 ,操作表中的数据data
- inster :插入
- delete :删除
- update :修改
DQL : 数据查询语言 (Data Query Language)
- select 语句
DCL : 数据控制语言 (Data Control Language)
- 授权:GRANT
- 撤销权限:REVOKE
TCL :事务控制语言(Transaction Control Language)
- 事务提交:commit
- 事务回滚:rollback
1.表管理
表操作
创建表
CREATE TABLE [IF NOT EXISTS] table_name (
column_name data_type [NOT NULL | NULL] [DEFAULT expr],
column_name data_type [NOT NULL | NULL] [DEFAULT expr],
...,
[table_constraints]
) [ENGINE=storage_engine];
删除表
DROP TABLE [IF EXISTS]
table_name [, table_name] ...
修改表
ALTER TABLE table_name
[alter_action options], ...
重命名表
# rename
RENAME TABLE
old_table_name TO new_table_name
[, old_table_name2 TO new_table_name2];
# alter
ALTER TABLE old_table_name
RENAME TO new_table_name;
清空表
TRUNCATE 用于清空一个表(相当于删除并重建表,无法回滚,会重置表的自增值),其速度比delete快(尤其对于大数据操作来说)
TRUNCATE [TABLE] table_name;
列操作
查看表的列信息
# 查看表中所有的列信息
desc table_name;
show columns from table_name;
添加列
ALTER TABLE table_name
ADD [COLUMN] column_definition [FIRST|AFTER existing_column]
[, ADD [COLUMN] column_definition [FIRST|AFTER existing_column]];
# 例:向user表中添加单列
ALTER TABLE user ADD COLUMN age INT NOT NULL DEFAULT 20;
# 例:向user表中添加多列
ALTER TABLE user
ADD COLUMN email VARCHAR(255) NOT NULL,
ADD COLUMN phone VARCHAR(255) NOT NULL;
删除列
ALTER TABLE table_name
DROP [COLUMN] column_name
[, DROP [COLUMN] column_name];
# 例:删除单列
ALTER TABLE user DROP COLUMN age;
# 例:删除多列
ALTER TABLE user
DROP COLUMN email,
DROP COLUMN phone;
自增列
自增列语法
如果需要一个列的值为一个有序的整数序列,可使用自增列。自增列是 MySQL 中的一个特殊的列,该列的值可由 MySQL 服务器自动生成,并且是一个按升序增长的正整数序列。自增列能够被用来为表的新行产生唯一的标识。
- 一个表中只能由一个自增列(自增列的数据类型只能使用整数和浮点数)
- 自增列初始值是1,创建表时可设定自增列初始值,也可更改自增列值
- 记录行删除后,删除的自增列值不能重复使用
- 使用
show create table语句查看自增列的值
# 自增列语法规则
column_name data_type AUTO_INCREMENT
...
# 查看自增列的下一个值(可通过查看建表信息,从建表信息中确认自增列的值)
SHOW CREATE TABLE `user`
# 从数据库信息表中查询自增列的值
SELECT AUTO_INCREMENT
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'testdb'
AND TABLE_NAME = 'user';
# 这种方式有时候并不准确,因为当重置或修改了表的 AUTO_INCREMENT 值之后,这里并不会立刻更新
自定自增列初始值
# 创建用户表,设定自增列默认初始值为1
CREATE TABLE `user` (
`user_id` INT AUTO_INCREMENT,
`name` VARCHAR(45),
PRIMARY KEY (`user_id`)
) AUTO_INCREMENT = 10;
修改自增值
ALTER TABLE `user` AUTO_INCREMENT = 30;
此处需注意自增值设置的有效性:
- 如果设置值小于当前表中自增列的最大值,则最终设置的值还是这个最大值的下一个数值(例如当前表中的最大值为40,则此处设置30不生效,实际还是设置为41)
- 当修改了表的
AUTO_INCREMENT值之后,INFORMATION_SCHEMA.TABLES表中的AUTO_INCREMENT列并不会立刻更新。可以使用SHOW CREATE TABLE语句查看
生成列
生成列概念
MySQL 中,生成列(GENERATED COLUMN)是一个特殊的列,它的值会根据列定义中的表达式自动计算得出,不能直接写入或更新生成列的值。生成列有 2 种类型:
- 虚拟生成列(VIRTUAL):列值不会被存储下来。当读取该列时,MySQL 自动计算该列的值并返回
- 存储生成列(STORED):当插入或修改数据时,MySQL 自动计算该列的值并存储在磁盘上
如果数据经常发生变动,考虑虚拟生成列(不占用存储空间);如果数据在创建后不经常变动,考虑使用存储生成列(插入或修改数据时自动更新并固化到磁盘中)
col_name data_type
[GENERATED ALWAYS] AS (expr) [VIRTUAL | STORED]
[NOT NULL | NULL]
[UNIQUE [KEY]]
[[PRIMARY] KEY]
[COMMENT 'string']
生成列案例
# 构建订单明细表并插入数据
CREATE TABLE order_item (
order_item_id INT AUTO_INCREMENT PRIMARY KEY,
goods VARCHAR(45) NOT NULL,
price DECIMAL NOT NULL,
quantity INT NOT NULL
);
INSERT INTO order_item (goods, price, quantity) VALUES ('Apple', 5, 3), ('Peach', 4, 4);
# 统计总金额:使用别名列
SELECT
goods,
price,
quantity,
(price * quantity) AS total_amount
FROM order_item;
MySQL的生成列功能可以简化上述工作,不需要写复杂的SQL语句,只需要通过生成列来完成
# 生成列
ALTER TABLE order_item
ADD COLUMN total_amount DECIMAL
GENERATED ALWAYS AS (price * quantity) STORED;
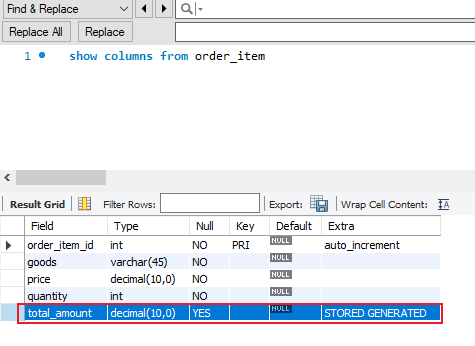
# 查看数据表列信息
show columns from order_item
# 查询订单详情(可看到total_amount列),此处的total_amount由系统根据规则自动生成,不需要手动维护
select * from order_item
生成列的更新:不能直接写入或更新生成列的值(生成列是由已有的列按照指定规则绑定的,不能直接对生成列进行更新)
# 新增一条带有生成列值的数据
INSERT INTO order_item (goods, price, quantity, total_amount) VALUES ('Banana', 6, 4, 24);
=》报错:Error Code: 3105. The value specified for generated column 'total_amount' in table 'order_item' is not allowed.
# 修改生成列值
UPDATE order_item SET total_amount = 30 WHERE goods = 'Apple';
=》报错:Error Code: 3105. The value specified for generated column 'total_amount' in table 'order_item' is not allowed.
2.数据库约束
主键约束(primary key)
主键规则
在关系数据库中,主键是能够唯一标识表中的每一行的一个字段或者多个字段的组合。在 MySQL 中,主键需要遵循以下规则:
- 主键是定义在表上的。一个表不强制定义主键,但最多只能定义一个主键
- 主键可以包含一个列或者多个列
- 主键列的值必须是唯一的。如果主键包含多个列,则这些列的值组合起来必须是唯一的
- 主键列中不能包含
NULL值
如果不遵循上面的规则,则可能会引发以下的错误
- 如果定义了多个主键,会返回错误:
ERROR 1068 (42000): Multiple primary key defined - 如果插入或者更新时有重复的主键值,则会返回类似的错误:
ERROR 1062 (23000): Duplicate entry '1' for key 'user.PRIMARY' - 如果插入了
NULL值,则会返回类似的错误:ERROR 1048 (23000): Column 'id' cannot be null
主键添加
# 方式1:在创建表的时候添加主键
CREATE TABLE user (
id INT PRIMARY KEY,
name VARCHAR(45)
);
# 联合主键创建
CREATE TABLE user (
com_id INT,
user_number INT,
name VARCHAR(45),
PRIMARY KEY(com_id, user_number)
);
# 方式2:创建表后,补充主键
ALTER TABLE user ADD PRIMARY KEY(id);
一个数据表中设定了主键,如果插入了重复或者null的主键字段值则会返回类似如下的错误:ERROR 1062 (23000): Duplicate entry '1' for key 'user.PRIMARY'
主键值的设定
在业务系统中一般不使用业务字段作为主键,虽然它们也是唯一的。建议使用单独的字段作为主键,这主要是出于以下两方面的原因:保密业务数据、方便这些业务字段的修改
为了生成唯一的主键值,通常采用以下方法:
- 方式1:将主键字段设置为
AUTO_INCREMENT,声明为AUTO_INCREMENT的字段会自动生成连续的整数值 - 方式2:使用
UUID()函数,UUID()函数产生一个长度为 36 个字符的字符串,并且永不重复(SELECT UUID();)UUID()适合用在集群环境下。这样即使一个表被分区在多个服务器上,也不会产生相同的主键的记录
- 方式3:使用
UUID_SHORT()函数,UUID_SHORT()函数返回一个 64 位无符号整数并全局唯一(SELECT UUID_SHORT();)
唯一约束(unique)
MySQL 中,可以在一个表上定义很多约束,比如主键约束、外键约束。唯一键也是一个常用的约束,用来保证表中的一列或几列的中的值是唯一的。在很多系统业务场景中都用到唯一键约束,例如:
- 用户表中有登录名或电子邮件列是唯一的
- 产品表中的产品编号列是唯一的
- 订单表中有订单编号列是唯一的
- 每天的统计报表中将 年、月、日 三个列作为组合唯一键
与主键相比,主键用于表示一个行的唯一性,主键的一般采用一个与业务无关的值,比如自增值,UUID 等。而唯一键一般用于约束与业务相关的数据的唯一性。主键和唯一索引都要求值是唯一的,但它们之间存在一些不同:
- 一个表中只能定义一个主键,但是能定义多个唯一索引
- 主键中的值不能为
NULL,而索引中的值可以为NULL - 唯一键允许其中的列接受
NULL值,但NULL值会破坏唯一键约束,即唯一键对NULL值无效
唯一约束管理
# 创建表的时候定义为一列
CREATE TABLE table_name(
...,
column_name data_type UNIQUE,
...
);
CREATE TABLE table_name(
column_name1 column_definition,
column_name2 column_definition,
...,
[CONSTRAINT constraint_name]
UNIQUE(column_name1,column_name2)
);
# 添加唯一键语法
ALTER TABLE table_name
ADD [CONSTRAINT constraint_name] UNIQUE (column_list);
# 删除唯一键语法(可以使用修改表或者删除索引语句)
ALTER TABLE table_name DROP CONSTRAINT constraint_name
ALTER TABLE table_name DROP INDEX index_name
DROP INDEX index_name ON table_name
外键约束(foreign key)
在关系数据库中,外键用来定义两个实体之间的约束关系,用于保证数据的完整性
以sakila示例数据库的country、city表
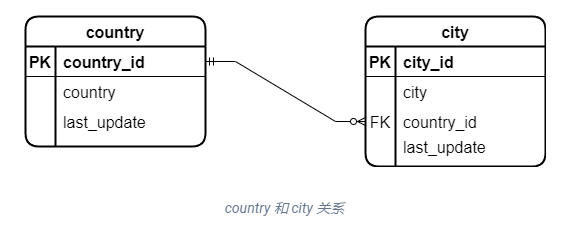
country与city是一对多的关系,一个国家中可以有多个城市,一个城市只能位于一个国家。外键约束用于保证数的完整性和正确性。
例如一个国家已经有了城市,则不能轻易地删除country中地记录,否则就会造成city的数据记录不完整;
同理,也不可为一个city设定不存在的country_id,否则关联数据就是错误的
# 查看city的外键约束(查看其建表信息)
SHOW CREATE TABLE city
添加外键
ALTER TABLE child_table_name
ADD [CONSTRAINT foreign_key_name]
FOREIGN KEY (column))
REFERENCES parent_table_name (column);
外键策略:父表记录操作会对关联子表记录采取什么策略进行处理以确保数据的正确性和完整性
cascade策略:如果外键的ON DELETE和ON UPDATE使用了CASCADE策略(级联操作)- 当父表的行被删除的时候,子表中匹配的行也会被删除
- 当父表的行的键值更新的时候,子表中匹配的行的字段也会被更新
RESTRICT策略:如果外键的ON DELETE和ON UPDATE使用了RESTRICT策略- MySQL 禁止删除父表中与子表匹配的行
- MySQL 禁止删除父表中与子表匹配的行的键的值
SET NULL策略:如果外键的ON DELETE和ON UPDATE使用了SET NULL策略- 当父表的行被删除的时候,子表中匹配的行的列的值被设置为
NULL - 当父表的行的键值被更新的时候,子表中匹配的行的列的值被设置为
NULL
- 当父表的行被删除的时候,子表中匹配的行的列的值被设置为
删除外键
# 语法1:删除外键
ALTER TABLE table_name
DROP FOREIGN KEY foreign_key_name;
# 语法2:删除约束(外键约束)
ALTER TABLE table_name
DROP CONSTRAINT constraint_name;
自引用外键
外键引用关系中,父表和子表用的是同一个表,这种表中的外键被称为子引用外键。例如分类表(树状分类概念),在这个表中,parent_category_id 列是一个外键。它引用了 category 表的 category_id 列。这个表实现了一个无限层级的分类树。一个分类可以有多个子分类,一个子分类可以有 0 个或者 1 个父类
# 分类表
CREATE TABLE category (
category_id INT AUTO_INCREMENT PRIMARY KEY,
category_name VARCHAR(45),
parent_category_id INT,
CONSTRAINT fk_category FOREIGN KEY (parent_category_id)
REFERENCES category (category_id)
ON DELETE RESTRICT
ON UPDATE CASCADE
);
启用或禁用外键约束
# 禁用外键约束
SET foreign_key_checks = 0;
# 启用外键约束
SET foreign_key_checks = 1;
检查约束(check)
对于任何应用,都对数据的正确性有要求。比如,用户的年龄必须是大于零的,用户的登录名中不能包含空格,用户的密码必须满足一定的复杂度,等等。
对于这些要求,虽然可以在应用界面来对用户输入的数据进行验证,但是这并不能替代数据库层面的数据验证,通过数据库层的检查约束可增加应用的安全性。MySQL 提供了 CHECK 约束来保证存储到表中的数据符合指定要求。不符合 CHECK 约束的数据会被拒绝。
直到 MySQL 8.0.16,MySQL 才真正的支持 CHECK 约束(CHECK(expr))。在更早的版本中是通过触发器获取带有with check option的视图来模拟check约束
检查约束的定义
# 方式1:在创建表的时候使用check约束
CREATE TABLE user (
id INT AUTO_INCREMENT PRIMARY KEY,
age INT NOT NULL CHECK(age > 0)
);
CREATE TABLE user (
id INT AUTO_INCREMENT PRIMARY KEY,
age INT NOT NULL,
CONSTRAINT CHECK(age > 0)
);
# 方式2:使用修改表语句的时候为表添加check约束
ALTER TABLE user
ADD CONSTRAINT CHECK(age > 0);
check约束实例
CREATE TABLE user (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(45) NOT NULL,
login_name VARCHAR(45) NOT NULL CHECK(length(login_name) >= 4),
password VARCHAR(45) NOT NULL CHECK(length(password) >= 8),
CONSTRAINT CHECK(login_name <> password)
);
# 建表时构建约束
用户的名称不能为空
登录名的长度不少于 4 个字符
密码的长度不少于 8 个字符
密码不能和登录名相同
3.MySQL 锁表
业务场景分析
假设在一个银行系统中有这样的逻辑:
当用户 A 从自己的银行账户取出 500 元时,用户 A 的余额为 原余额 减去 500。当另一个用户 B 给用户转入 500 元时,用户 A 的余额为 原余额 加上 500。
如果这两个操作同时发生,则可能导致用户 A 的余额是错误的。
MySQL 的锁就是为了解决这种并发问题的。MySQL 支持三种类型的锁:表级锁、行级锁和页面锁。
MySQL 允许在会话中显式地获取表锁,以防止其他会话在需要独占访问表的期间修改表。锁的操作是在当前会话中进行的。一个会话只能为自己获取锁,并只能释放自己的锁。
MySQL 提供了 LOCK TABLES 和 UNLOCK TABLES 语句用于显式地的获取表锁和释放表锁
LOCK TABLES
LOCK TABLES
table_name [READ | WRITE]
[, table_name [READ | WRITE], ...];
- table_name:要锁的表
READ锁用于共享读取表,WRITE锁用于排斥的读写表LOCK TABLES语句在获取新的表锁之前会隐式的释放当前会话持有的所有的表锁
UNLOCK TABLES
# 释放当前会话获取的所有的表锁
UNLOCK TABLES;
4.MySQL 字符集和排序规则
MySQL 支持各种字符集,几乎允许所有字符存储在字符串中
# 查看字符集
SHOW CHARACTER SET;
从 MySQL 8 开始,MySQL 默认的字符集为 utf8mb4,而早期版本的 MySQL 的默认字符集是 latin1。 latin1 字符集只能表示单字节字符,而 utf8mb4 字符集可以表示多字节字符包括表情符合。
MySQL 支持设置不同级别的字符集,包括: 服务器级,数据库级,表级,列级。可以为不同的级别设置不同的字符集。如果需要在不同的字符集之间转换字符串,可使用CONVERT和CAST
服务器级
服务器级字符集和排序规则是所有的数据库的默认的字符集和排序规则,若数据库不是指定,则采用服务器级的设置
查看服务器的字符集和排序规则
# 查看服务器级的字符集
SHOW VARIABLES LIKE "character_set_server";
# 查看服务器级的排序规则
SHOW VARIABLES LIKE "collation_server";
设置服务器的字符集和排序规则
- 方式1:在配置文件中设置(该设置时永久的),修改完成之后重启MySQL服务器使配置生效
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_0900_ai_ci
- 方式2:启动服务器时指定字符集和排序规则
mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_0900_ai_ci
- 方式3:在命令行修改字符集和排序规则(只对当前会话有效)
SET character_set_server = utf8mb4;
SET collation_server = utf8mb4_0900_ai_ci;
数据库级
数据库级的字符集和排序规则只对当前数据库生效,这也是数据库中的表的默认的字符集和排序规则
# 查看当前数据库的字符集和排序规则
SELECT @@character_set_database, @@collation_database;
# 查看指定数据库的字符集和排序规则
SHOW CREATE DATABASE testdb;
# 设置数据库级字符集和排序规则
- 方式1:创建数据库的时候通过 CHARACTER SET、COLLATE 子句指定字符集、排序规则
CREATE DATABASE database_name
[CHARACTER SET charset_name]
[COLLATE collation_name];
- 方式2:通过以下 ALTER DATABASE 修改数据库的字符集、排序规则
ALTER DATABASE database_name
[CHARACTER SET charset_name]
[COLLATE collation_name];
表级
# 查看一个表的字符集和排序规则
-方式1:从建表信息中跟踪
SHOW CREATE TABLE t1;
- 方式2:SHOW TABLE STATUS 语句查看一个表的字符集和排序规则
SHOW TABLE STATUS FROM testdb LIKE 't1';
- 方式3:从 information_schema.TABLES 表中查看一个表的字符集和排序规则
SELECT TABLE_COLLATION
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = "testdb"
AND TABLE_NAME = "t1"
# 设置一个表的字符集和排序规则
- 方式1:在创建表的时候通过CHARACTER SET、COLLATE 子句指定字符集、排序规则
CREATE TABLE table_name (column_list)
[CHARACTER SET charset_name]
[COLLATE collation_name]
- 方式2:通过 ALTER DATABASE 修改数据库的字符集、排序规则
ALTER TABLE table_name
[CHARACTER SET charset_name]
[COLLATE collation_name]
列级
# 查看列的字符集和排序规则
- 方式1:为列设置独立的字符集和排序规则
col_name data_type
[CHARACTER SET charset_name]
[COLLATE collation_name]
- 方式2:使用 ALTER TABLE 语句为列设置单独的字符集和排序规则
ALTER TABLE t1
MODIFY c4 VARCHAR(20)
CHARACTER SET 'utf8'
COLLATE 'utf8_bin';
# 要查看列的字符集和排序规则
SELECT CHARACTER_SET_NAME,
COLLATION_NAME
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = "testdb"
AND TABLE_NAME = "t1"
AND COLUMN_NAME = "c4";
语法基础
1.查询语句
查询操作关键字
- 查询涉及到的操作符:and、or、int、not in、between、like、is null、exists、distinct
- 查询涉及到的子句:where、order by、limit
- 多表查询相关:join(内连接、左连接、右连接)、union(组合查询)
- 高级查询相关:
- 聚合函数:count(总数)、max(最大值)、min(最小值)、sum(综合)、avg(平均值)
- 汇总、分组:group by、having
- 子查询相关:子查询用法和原理分析
基础查询
(1)基础查询
基础查询
以sakila数据库中的数据表为示例进行练习
# 选择数据库
use sakila;
# 查询单个字段
select first_name from actor;
# 查询多个字段
select actor_id,first_name from actor;
# 查询所有字段
select * from actor;
# 别名(给查询列指定返回列名)
select actor_id actorId,first_name "firstName",last_name "名",last_update from actor;
select first_name,last_name,concat(first_name,',',last_name) `full_name` from actor
没有from的select
在 MySQL 中,某些情况下要检索的数据不存在于任何表中,可以省略 FROM 子句
# 查询表达式示例
SELECT expression_list
# 查询当前系统时间
select now();
# 数值计算
select 1+1;
虚拟表dual
# 从虚拟表查询数据
select expression_list from dual;
# 查询当前系统时间
select now() from dual;
# 数值计算
select 1+1 from dual;
(2)条件查询
where 子句
其中【query_condition】是查询条件,通过where子句筛选出满足条件的记录。where除了用在select语句中,还可用在update、delete子句中,用于更新或者操作指定条件的行
SELECT
columns_list
FROM
table_name
WHERE
query_condition;
条件查询示例:以
sakila数据库为例
# 查询符合指定字段的数据记录
select * from actor where last_name = 'CHASE'
# 使用and组合多个条件查询
select * from actor where last_name = 'CHASE' and first_name = 'ED'
# 使用or组合多个条件查询
select * from actor where last_name = 'CHASE' or first_name = 'ED'
比较运算符
| 比较运算符 | 说明 | 举例 |
|---|---|---|
= | 等于 | age = 18 |
<> | 不等于 | age <> 18 |
!= | 不等于 | age != 18 |
> | 大于,通常用于比较数字或者日期 | age > 18 |
>= | 大于等于,通常用于比较数字或者日期 | age >= 18 |
< | 小于,通常用于比较数字或者日期 | age < 18 |
<= | 小于等于,通常用于比较数字或者日期 | age <= 18 |
IN | 判断值是否在一个集合中 | age IN (18, 19) |
NOT IN | 判断值是否不在一个集合中 | age NOT IN (18, 19) |
BETWEEN | 判断值是否介于两个数中间 | age BETWEEN 16 AND 18 |
LIKE | 模糊匹配 | name LIKE 'A%' |
IS NULL | 是否为 NULL | name IS NULL |
IS NOT NULL | 是否不为 NULL | name IS NOT NULL |
# 组合查询
select * from actor where last_name = 'DAVIS' AND actor_id < 100;
select * from actor where last_name = 'DAVIS' or last_name = 'DAVIS';
# 运算符优先级(一般情况下and优先于or,建议使用括号()限定优先级,不要死记硬背)
select 1 or 0 and 0; // res:1
select (1 or 0) and 0; // res:0
| AND | 1 | 0 | NULL |
|---|---|---|---|
1 | 0 | 0 | NULL |
0 | 0 | 0 | 0 |
NULL | NULL | 0 | NULL |
| OR | 1 | 0 | NULL |
|---|---|---|---|
1 | 1 | 1 | 1 |
0 | 1 | 0 | NULL |
NULL | 1 | NULL | NULL |
in 运算符
in 运算符来检查一个字段或值是否包含在一个集合中,如果值包含在集合中返回 1,否则返回 0
expression IN (value1, value2, ...)
# in 运算符构建的表达式等价于多个or构建的简化版本
name IN ('Alice', 'Tim', 'Jack')
name = 'Alice' OR name = 'Tim' OR name = 'Jack'
# in 示例
select * from actor where last_name in ('DAVIS','ALLEN')
# in 运算规则:当左侧和右侧都不是 NULL 时,右侧值列表中包含左侧的值时返回 1,否则返回 0
SELECT 1 IN (1, 2), 3 IN (1, 2), 'A' IN ('A', 'B'), 'C' IN ('A', 'B');
+-------------+-------------+-------------------+-------------------+
| 1 IN (1, 2) | 3 IN (1, 2) | 'A' IN ('A', 'B') | 'C' IN ('A', 'B') |
+-------------+-------------+-------------------+-------------------+
| 1 | 0 | 1 | 0 |
+-------------+-------------+-------------------+-------------------+
# in 运算规则:当左侧操作数为 NULL,返回 NULL
SELECT NULL IN (1, 2), NULL IN (1, 2, NULL);
+----------------+----------------------+
| NULL IN (1, 2) | NULL IN (1, 2, NULL) |
+----------------+----------------------+
| NULL | NULL |
+----------------+----------------------+
# in 运算规则:当右侧值列表含有 NULL,如果包括左侧的非 NULL 值,返回 1,否则返回 NULL
SELECT 1 IN (1, NULL), 2 IN (1, NULL);
+----------------+----------------+
| 1 IN (1, NULL) | 2 IN (1, NULL) |
+----------------+----------------+
| 1 | NULL |
+----------------+----------------+
not in:是in的否定操作符,用于否定一个操作(其用法和in类似),筛选出左侧值不包含在右侧值列表的记录
# not in 示例
select * from actor where last_name not in ('DAVIS','ALLEN')
betweent 运算符(三目运算符)
# between and 三目运算符
expression between min AND max
expression >= min AND expression <= max
# not between
expression NOT BETWEEN min AND max
expression < min OR expression > max
# between示例
SELECT
film_id, title, replacement_cost
FROM
film
WHERE
replacement_cost < 10 OR replacement_cost > 50;
like 运算符(数据过滤)
# like 数据过滤
expression LIKE pattern
expression 可以是一个字段名、值或其他的表达式(比如函数调用、运算等)
pattern 是一个字符串模式。MySQL 字符串模式支持两个通配符: % 和 _
%匹配零或多个任意字符_匹配单个任意字符- 如果需要匹配通配符,则需要使用
\转义字符,如\%和\_ - 使用通配符匹配文本时,不区分字母大小写
如果 expression 与 pattern 匹配,LIKE 运算符返回 1,否则返回 0
# like 数据过滤 示例
# 查找匹配first_name 以字符P开头的所有演员
select * from actor where first_name like 'P%';
# 查找匹配first_name 以字符ES结尾的所有演员
select * from actor where first_name like '%ES';
# 查找匹配first_name 包括指定字符的所有演员
select * from actor where first_name like '%AM%';
# 查找 first_name 以字符串AY结尾的且长度为3个字符的所有演员(此处使用_匹配单个字符)
select * from actor where first_name like '_AY';
# 查找first_name不包括指定字符的所有演员
select * from actor where first_name not like '%AM%';
is null 单目运算符
is null 用于测试一个值是否为null;is not null 是其否定运算
# is null\is not null 语法规则
expression IS NULL
expression IS NOT NULL
# is null\is not null 示例
SELECT
NULL IS NULL,
0 IS NULL,
1 IS NULL,
(NULL IN (NULL)) IS NULL,
(1+1) IS NULL;
# 返回结果:1 0 0 1 0
exists 单目运算符
exists 单目运算符,需要一个子查询作为参数
exists运算规则:如果子查询至少匹配返回一条数据,则其计算结果为true,否则返回falseexists运算时,一旦子查询找到匹配的行,该运算就会立刻返回(对于提高查询性能很有帮助)exists不关心查询中的列数量或名称,只在乎子查询是否返回数据行(即不管是select *,select 1,select column_list都不影响其运算结果,关键在于子查询返回的数据行)not exists:是exists的否定操作
# exist
SELECT column_name
FROM table_name
WHERE EXISTS(subquery);
# exists示例
# 查找language的语种信息,检索其在film表中存在相关语种的信息
SELECT *
FROM language
WHERE EXISTS(
SELECT *
FROM film
WHERE film.language_id = language.language_id
);
# 检索结果显示:在language表中,只有指定语种(例如English)才拥有关联的影片
language_id name last_update
1 English 2006-02-15 05:02:19
# 检索在language表中没有关联影片信息的语种
SELECT *
FROM language
WHERE NOT EXISTS(
SELECT *
FROM film
WHERE film.language_id = language.language_id
);
language_id name last_update
2 Italian 2006-02-15 05:02:19
3 Japanese 2006-02-15 05:02:19
4 Mandarin 2006-02-15 05:02:19
5 French 2006-02-15 05:02:19
6 German 2006-02-15 05:02:19
# exists 并不关心返回的查询结果中的列的名称或者数量,只关心是否返回数据行
# exists子查询中的select 1、select *、select column_list 效果是等同的
SELECT *
FROM language
WHERE EXISTS(
SELECT *
FROM film
WHERE film.language_id = language.language_id
);
SELECT *
FROM language
WHERE EXISTS(
SELECT 1
FROM film
WHERE film.language_id = language.language_id
);
SELECT *
FROM language
WHERE EXISTS(
SELECT language_id
FROM film
WHERE film.language_id = language.language_id
);
# 有时候exists可以使用in来平替
SELECT *
FROM language
WHERE EXISTS(
SELECT *
FROM film
WHERE film.language_id = language.language_id
);
# 对应in版本
# 先理解检索的条件:检索出language表中存在关联影片信息的语种内容
# 则可先把对应影片信息的所有语种(去重)信息先检索出来,随后检索language表中的语种是否存在于其中
select *
from language
where language_id in (select distinct language_id from film)
子查询中使用table语句:MySQL8.0.19及之后版本新增的语法规则
SELECT column1 FROM t1 WHERE EXISTS (TABLE t2);
SELECT column1 FROM t1 WHERE EXISTS (SELECT * FROM t2);
order by排序
使用order by可以指定一个或多个排序字段
asc升序(默认是asc)、desc降序- 当指定多个列时,按照字段顺序定义排序规则
- 可自定义排序规则:order by+case when子句、order by+field()函数
- 升序排序时,
NULL在非 NULL 值之前;降序排序时,NULL在非 NULL 值之后
# order by 语法规则
SELECT
column1, column2, ...
FROM
table_name
[WHERE clause]
ORDER BY
column1 [ASC|DESC],
column2 [ASC|DESC],
...;
# order by 示例
# 查找所有演员信息(先以first_name降序、后以last_name升序)
select * from actor order by first_name desc,last_name asc
有时候单纯的按照字段的值排序并不能满足要求,需要自定义排序规则(可结合case关键字进行排序)
# 需求分析:根据影片的等级按照的 'G', 'PG', 'PG-13', 'R', 'NC-17' 顺序对影片进行排序
# 方式1:order by + case when 组合使用
SELECT
film_id, title, rating
FROM
film
ORDER BY CASE rating
WHEN 'G' THEN 1
WHEN 'PG' THEN 2
WHEN 'PG-13' THEN 3
WHEN 'R' THEN 4
WHEN 'NC-17' THEN 5
END;
# 方式2:order by + FIELD() 函数组合使用
SELECT
film_id, title, rating
FROM
film
ORDER BY FIELD(rating,'G', 'PG', 'PG-13', 'R', 'NC-17')
// 参考结果
film_id, title, rating
2 ACE GOLDFINGER G
4 AFFAIR PREJUDICE G
5 AFRICAN EGG G
limit关键字
limit:使用limit子句来限定select语句返回的行数量
# limit 语法规则:row_count 返回的最大行数、offset 指定要返回的第一行的偏移量
LIMIT [offset,] row_count;
LIMIT row_count OFFSET offset;
# limit 参考示例
limit 5; # 等价于 limit 0,5
limit 2,5; # 在原始结果集中跳过2个记录行,从第3个记录行开始,返回5个记录行
limit 5 offset 3;
# 查询示例
# 返回 film 表中等级为 G 的片长最长的 10 部影片
SELECT
film_id, title, length
FROM
film
WHERE
rating = 'G'
ORDER BY length DESC
LIMIT 10;
分页查询
例如有1000条数据,引入分页概念,每页查询100条数据(引入分页用于减轻单次检索的压力)
# 首页查找(偏移量为0可省略)
select * from film limit 100;
# 查找第2页(按照分页大小为100计算,第2页的第一条记录为101,则偏移量为100)
select * from film limit 100,100;
distinct去除重复行
- 使用
distinct关键字过滤重复字段的数据 - 可以指定多个字段进行重复过滤(放在select语句:对返回的记录过滤掉重复记录)
# distinct 语法规则
SELECT DISTINCT columns_list
FROM table_name
# 示例:查找actor表中的所有姓氏(不重复)
select distinct last_name from actor;
# 示例:查找actor表中的所有姓氏、名字(姓氏、名字组合不重复)
select distinct last_name,first_name from actor;
# 查找actor表中的所有姓氏、名字(姓氏、名字组合不重复)
select distinct last_name,first_name from actor;
# 分组确认记录结果是否去重
select count(*) from (select last_name,first_name from actor) as a; // 200
select count(*) from (select distinct last_name,first_name from actor) as a; // 199
# 说明存在1条重复记录被剔除了,可以用group by确认去重是否成功
select count(*) from (select last_name,first_name from actor group by last_name,first_name) as a;// 199
# 统计分组结果记录数(检索出存在重复的记录)
select last_name,first_name,count(*)
from actor group by last_name,first_name
having count(*) >1;
distinct与null: 当DISTINCT遇到NULL值时,只保留一个NULL值
# 案例:该SQL执行返回3条NULL记录
SELECT *
FROM (
SELECT NULL
UNION ALL
SELECT NULL
UNION ALL
SELECT NULL
) t;
# 使用distinct关键字之后,最终只返回1条NULL记录
SELECT distinct *
FROM (
SELECT NULL
UNION ALL
SELECT NULL
UNION ALL
SELECT NULL
) t;
# distinct校验是根据返回的行记录进行匹配,而不是单个字段概念(例如此处每一行虽然带有NULL字段,但是行记录都不同,因此不是重复数据)
SELECT distinct *
FROM (
SELECT NULL,1 from dual
UNION ALL
SELECT NULL,2 from dual
UNION ALL
SELECT NULL,3 from dual
) t;
多表查询
(1)JOIN
JOIN 语句用于将数据库中的两个表或者多个表组合起来:内连接、左连接、右连接、交叉连接
在实际业务场景中会通过构建主外键关系来构建多个数据表的关联,将一个基本信息拆解为多个表,通过联结(JOIN)整合多个表的信息构建正确的数据信息输出。(例如最常见的一个用户可拥有多个订单信息、每个订单信息又可拆分为多个订单明细,可能涉及地址信息等内容)
场景案例:学生表、学生成绩表
# 创建数据库用于构建测试案例
create database db_mysql_base;
use db_mysql_base;
# 创建数据表
CREATE TABLE `student` (
`student_id` int NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`student_id`)
);
CREATE TABLE `student_score` (
`student_id` int NOT NULL,
`subject` varchar(45) NOT NULL,
`score` int NOT NULL
);
# 初始化数据
INSERT INTO `student` (`student_id`, `name`)
VALUES (1,'Tim'),(2,'Jim'),(3,'Lucy');
INSERT INTO `student_score` (`student_id`, `subject`, `score`)
VALUES (1,'English',90),(1,'Math',80),(2,'English',85),
(2,'Math',88),(5,'English',92);
# 校验数据是否插入成功
select * from student;
select * from student_score;
交叉连接
交叉连接返回两个集合的笛卡尔积,即两个表中的所有的行的所有可能的组合。这相当于内连接没有连接条件或者连接条件永远为真。
如果一个有 m 行的表和另一个有 n 行的表,它们交叉连接将返回 m * n 行数据(分为显式的交叉连接和隐式的交叉连接)
# 显式交叉连接
select student.*,student_score.*
from student cross join student_score
# 隐式交叉连接
select student.*,student_score.*
from student,student_score
内连接
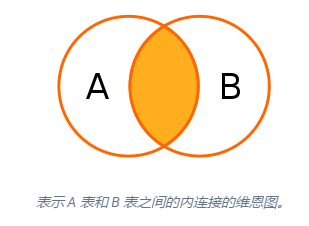
内连接:将第一个表的每一行与第二个表的每一行进行比较,如果满足给定的连接条件,则将两个表的行组合在一起作为结果集中的一行。内连接相当于加了过滤条件的交叉连接
select s.*,sc.*
from student s inner join student_score sc on s.student_id = sc.student_id
# 等价where语句
select s.*,sc.*
from student s,student_score sc
where s.student_id = sc.student_id
# 两个表都是用同样的字段student_id,可以使用using查询
select s.*,sc.*
from student s inner join student_score sc using(student_id)
左连接
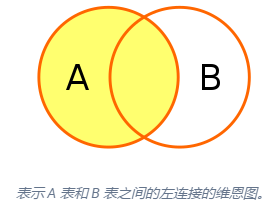
左连接:以左表的数据行为基础,根据连接匹配右表的每一行,如果匹配成功则将左表和右表的行组合成新的数据行返回;如果匹配不成功则将左表的行和 NULL 值组合成新的数据行返回
select s.*,sc.*
from student s left join student_score sc on s.student_id = sc.student_id
# 两个表都是用同样的字段student_id,可以使用using查询
select s.*,sc.*
from student s left join student_score sc using(student_id)
右连接
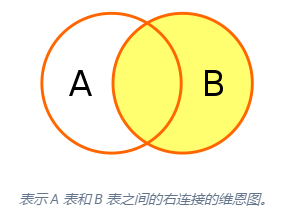
右连接:右连接与左连接处理逻辑相反,右连接以右表的数据行为基础,根据条件匹配左表中的数据。如果匹配不到左表中的数据,则左表中的列为 NULL 值
select s.*,sc.*
from student s right join student_score sc on s.student_id = sc.student_id
# 两个表都是用同样的字段student_id,可以使用using查询
select s.*,sc.*
from student s right join student_score sc using(student_id)
# 上述右连接等价于下述左连接结果
select s.*,sc.*
from student_score sc left join student s using(student_id)
(2)union (并)
集合操作符:UNION、INTERSECT、MINUS,MySQL目前只支持UNION。
使用union操作符来合并两个select语句的结果集,而不返回任何的重复行(返回唯一记录值的结果集)
- 当对两个结果集进行union运算时,要保证每个结果集具有相同的列数(与字段名称无关,只需列数一样即可),否则就会产生错误
- 参与
UNION运算的结果集只要列数一样就可以,返回结果集的列名采用第一个结果集的列名
# 集合操作语法规则
SELECT statement
UNION [DISTINCT | ALL]
SELECT statement
案例准备:创建测试表并插入数据
# 创建测试表并插入数据
CREATE TABLE a (v INT);
CREATE TABLE b (v INT);
CREATE TABLE c (v INT);
INSERT INTO a VALUES (1), (2), (NULL), (NULL);
INSERT INTO b VALUES (2), (2), (NULL);
INSERT INTO c VALUES (3), (2);
# union运算(将两个表的结果集合进行union运算,过滤掉重复数据,返回一个唯一记录值的结果集)
SELECT * FROM a
UNION
SELECT * FROM b;
# 多表union运算
SELECT * FROM a
UNION
SELECT * FROM b
UNION
SELECT * FROM c;
# union all:保留多个结果集中的所有行
SELECT * FROM a
UNION ALL
SELECT * FROM b
UNION ALL
SELECT * FROM c;
# 组合运算(先将a、b进行union计算,去除重复记录,随后将结果集再和表c执行union all运算)
SELECT * FROM a
UNION
SELECT * FROM b
UNION ALL
SELECT * FROM c;
# union 错误示例(union运算操作的两个结果集必须有相同的列数,否则报错)
select 1 union select 2,3
# Error Code: 1222. The used SELECT statements have a different number of columns 0.016 sec
# union运算与返回列内容无关,只要结果集列数一样即可,默认返回采用第一个结果集的列名(可自定义列名)
select 1 union select 2
+---+
| 1 |
+---+
| 1 |
| 2 |
+---+
高级查询
(1)group by
GROUP BY 子句用于将结果集根据指定的字段或者表达式进行分组,常用于统计数据的场景。例如:
- 按班级求取平均成绩
- 按学生汇总某个人的总分
- 按年或者月份统计销售额
- 按国家或者地区统计用户数量
# group by 语法规则
SELECT column1[, column2, ...], aggregate_function(ci)
FROM table
[WHERE clause]
GROUP BY column1[, column2, ...];
[HAVING clause]
- column1、column2 ... 是分组字段,aggregate_function是聚合函数
- select 后的字段必须是分组字段中的字段
- where 子句是可选的,用于过滤结果集中数据
- having 子句是可选的,用于过滤分组数据
use sakila;
# group by示例
# 检索演员表的last_name的分组数据
select last_name from actor group by last_name;
# 上述操作结果可以用下述distinct语句替换
select distinct last_name from actor;
(2)聚合函数
聚合函数包括:
SUM():求总和AVG():求平均数MIN():求最小值MAX():求最大值COUNT():计数
group by、聚合函数 组合应用
# 检索actor表中的所有姓氏和对应次数统计
select last_name,count(*)
from actor
group by last_name
order by count(*) desc;
# 上述案例中执行顺序说明如下:
# 1.先使用group by子句按照last_name字段对数据进行分组
# 2.然后使用聚合函数count(*)汇总每个姓氏的行数
# 3.最后使用order by子句按照count(*)进行降序排序
group by、limit、聚合函数 组合应用
# 返回总消费金额排名前 10 位的客户
select customer_id,sum(amount) total
from payment
group by customer_id
order by sum(amount) desc
limit 0,10
# 上述案例中执行顺序说明如下:
# 1.先使用group by子句按照customer_id字段对数据进行分组
# 2.然后使用聚合函数sum(amount)汇总每个客户的消费金额
# 3.最后使用order by子句按照sum(amount)进行降序排序
# 4.最后使用limit返回top10
group by、having、聚合函数 组合应用
# 返回总消费总金额在180以上的客户
select customer_id,sum(amount) total
from payment
group by customer_id
having total > 180
order by total desc
# 上述案例中执行顺序说明如下:
# 1.先使用group by子句按照customer_id字段对数据进行分组
# 2.然后使用聚合函数sum(amount)汇总每个客户的消费金额
# 3.使用having过滤获取到total(客户消费总金额)大于180的记录
# 4.最后使用order by子句按照sum(amount)进行降序排序
子查询
子查询是嵌套一个语句中的查询语句,也被称为内部查询,子查询经常用在 WHERE 子句中
SELECT *
FROM language
WHERE EXISTS(
SELECT *
FROM film
WHERE film.language_id = language.language_id
);
# in
select *
from language
where language_id in(
select distinct language_id
from film
);
当一个子查询位于from子句中的时候,这个子查询被成为派生表,MySQL规定任何from子句中的表都必须具有一个名字,因此派生表也要为其指定别名
SELECT *
FROM (
SELECT last_name,
COUNT(*) count
FROM actor
GROUP BY last_name
) t
WHERE t.last_name LIKE 'A%';
2.增删改语句
增删改操作关键字
- 增删改相关:insert、update、delete
insert:新增
# 单行数据插入
INSERT INTO table_name (column_1, column_2, ...) VALUES (value_1, value_2, ...);
# 多行数据插入
INSERT INTO table_name (column_1, column_2, ...)
VALUES (value_1, value_2, ...),
(value_1, value_2, ...),
......;
insert 修饰符
MySQL 中, INSERT 语句支持 4 个修饰符:
LOW_PRIORITY: 如果指定了LOW_PRIORITY修饰符,MySQL 服务器将延迟执行INSERT操作直到没有客户端对表进行读操作LOW_PRIORITY修饰符影响那些只支持表级锁的存储引擎,比如:MyISAM,MEMORY, 和MERGEHIGH_PRIORITY: 如果你指定了HIGH_PRIORITY修饰符,它会覆盖掉服务器启动时的--low-priority-updates选项HIGH_PRIORITY修饰符影响那些只支持表级锁的存储引擎,比如:MyISAM,MEMORY, 和MERGE。IGNORE: 如果指定了IGNORE修饰符,MySQL 服务器会在执行INSERT操作期间忽略那些可忽略的错误。这些错误最终会作为WARNING返回DELAYED: 这个修饰符已经在 MySQL 5.6 版本中弃用,将来会被删除。在 MySQL 8.0 中,这个修饰符可用但会被忽略
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
INTO table_name
...
insert 限制
在 MySQL 中,max_allowed_packet 配置了服务器和客户端任何单个消息大小的上限。这同样适用于 SELECT 语句。当一个 SELECT 语句的大小超过 max_allowed_packet 值时,服务器就会给出一个错误
# 查看当前服务器上的max_allowed_packet配置
show variables like '%max_allowed_packet%';
update:修改
UPDATE 语句可以更新表中的一行或者多行数据,可以更新表中的一个或者多个字段(列)
update 操作和 delete 操作类似,在实际业务场景中要注意限定操作条件,避免直接全量操作
# 单列或多列修改
UPDATE [IGNORE] table_name
SET
column_name1 = value1,
column_name2 = value2,
...
[WHERE clause];
# 使用表达式更新(使用 UPDATE 更新时,字段的值可以设置为表达式的运算结果,比如函数或其他的运算)
UPDATE customer
SET email = REPLACE(email, 'sakilacustomer.org', 'sjkjc.com');
# 使用子查询更新
UPDATE customer
SET store_id = (
SELECT store_id
FROM store
ORDER BY RAND()
LIMIT 1
)
WHERE store_id IS NULL;
update 修饰符
MySQL 中, UPDATE 语句支持 2 个修饰符:
LOW_PRIORITY: 如果你指定了LOW_PRIORITY修饰符,MySQL 服务器将延迟执行UPDATE操作直到没有客户端对表进行读操作。LOW_PRIORITY修饰符影响那些只支持表级锁的存储引擎,比如:MyISAM,MEMORY, 和MERGE。IGNORE: 如果你指定了IGNORE修饰符,MySQL 服务器会在执行UPDATE操作期间忽略那些可忽略的错误。这些错误最终会作为WARNING返回
UPDATE [LOW_PRIORITY] [IGNORE] table_name SET column_name = value
delete:删除
delete语句用于从表中删除满足条件的记录行。
需注意在日常开发的是要一定要结合实际场景限定删除条件,否则会容易误删所有数据
# 单表删除
DELETE FROM table_name
[WHERE clause]
[ORDER BY ...]
[LIMIT row_count]
# 清空表
truncate table_name;
# 多表删除(多表删除不能使用limit、order by子句)
# 删除 t1 和 t2 表中满足条件的行
DELETE t1, t2
FROM t1 INNER JOIN t2
WHERE t1.id = t2.id;
# 删除 t1 表中满足条件的行
DELETE t1
FROM t1 INNER JOIN t2
WHERE t1.id = t2.id;
# 删除时使用 LEFT JOIN
DELETE t1
FROM
t1 LEFT JOIN t2 ON t1.id = t2.id
WHERE t2.id IS NULL;
delete 修饰符
MySQL 中, DELETE 语句支持 3 个修饰符:
LOW_PRIORITY: 如果指定了LOW_PRIORITY修饰符,MySQL 服务器将延迟执行DELETE操作直到没有客户端对表进行读操作。这个修饰符影响那些只支持表级锁的存储引擎,比如:MyISAM,MEMORY, 和MERGE。QUICK: 如果指定了QUICK修饰符,MyISAM存储引擎不会在DELETE操作期间合并索引。这在某种程度上会加快DELETE操作。IGNORE: 如果指定了IGNORE修饰符,MySQL 服务器会在执行DELETE操作期间忽略那些可忽略的错误。这些错误最终会作为WARNING返回
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM table_name
replace:插入(会替换重复的旧行)
向表中插入数据,除了使用 INSERT 语句,还可以使用 REPLACE 语句(REPLACE 语句不在标准 SQL 的范畴)
REPLACE 语句和 INSERT 语句很像,它们的不同之处在于,当插入过程中出现了重复的主键或者重复的唯一索引的时候,INSERT 语句会产生一个错误,而 REPLACE 语句则先删除旧的行,再插入新的行。
REPLACE [INTO] table_name (column_1, column_2, ...)
VALUES (value_11, value_12, ...),
(value_21, value_22, ...)
...;
REPLACE 语句还可以使用 SET 关键词,这只适用于操作单行。语法如下:
REPLACE [INTO] table_name
SET column1 = value1,
column2 = value2,
...;
这种用法与 UPDATE 语句的相似,但也是不同的。 UPDATE 只更新符合条件的行的指定字段的值,未指定的字段保留原值。REPLACE 则会删掉旧行,再插入新行,REPLACE 语句中未指定的字段则为默认值或者 NULL。如果想要正常使用 REPLACE,当前操作的用户必须对表具有 INSERT 和 DELETE 权限。
3.MySQL高阶语法
MySQL高阶语法
- 函数、视图、存储过程、触发器(todo)