④JAVA 常见类
④JAVA 常见类
学习核心
- Object类
- Object类的常见方法有哪些?
- ==和equals的区别是什么?
- 为什么要有hashCode?
- hashCode和equals的区别是什么?
- 为什么重写equals方法的时候必须要重写hashCode方法?
- 浅拷贝和深拷贝的区别?
- 深拷贝有几种实现方式?
- String类
- String、StringBuffer、StringBuilder的区别?
- Java的String类为什么不可变?
Object类
学习资料
1.Object基本概念
Java Object 类是所有类的父类,也就是说 Java 的所有类都继承了 Object,子类可以使用 Object 的所有方法
Object 类位于 java.lang 包中,编译时会自动导入,创建一个类时,如果没有明确继承一个父类,那么它就会自动继承 Object,成为 Object 的子类。Object 类可以显式继承,也可以隐式继承:
// 显式继承
public class Runoob extends Object{
}
// 隐式继承
public class Runoob {
}
Object常用的方法:
equals(Object obj):判断字符串是否相同、可以通过重载判断是否引用同一个对象
finalize():初始化
hashCode():获取对象的内存地址(哈希码)
getClass():获取当前对象所属类的类名
toString():输出对象的内存地址,可通过重载实现输出对象的相关信息
2.equals和hashCode方法
学习资料
equals和==
Java程序中有两种方式是两个变量是否相等。一种是利用==判断,另外一种是使用equals方法来判断。
当使用==进行判断的时候,如果两个变量都是基本类型的变量,并且都是数值类型,则只要两个变量的值相同时,便返回true。但如果两个变量的类型是引用类型,则只有两个变量均指向相同的对象(内存地址)才返回true。
使用equals方法进行判断时则以具体equals方法中实际比较的项目为准(使用equals判断两个字符串是否相等),可通过重写equals方法实现自定义的比较方式
equals和hashCode
hash以及hashCode存在的价值:通过hash计算定位某个值存储的位置。(设想一种情况,如果不通过hash方式直接定位元素的存储位置,则只能按照集合的先后顺序一个个比对询问,这种依次比对方式效率明显低于hash定位的方式。)
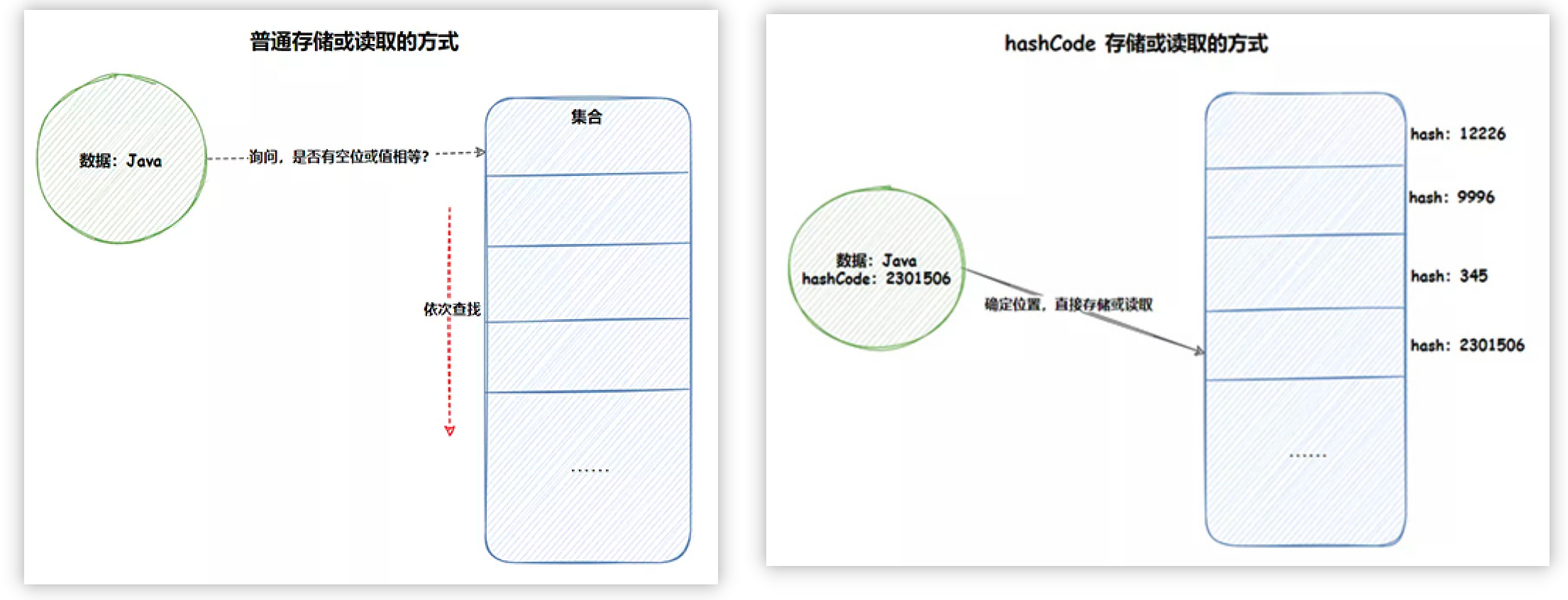
当比较两个对象是否相等时,可以先使用hashCode进行比较,如果比较结果为true,则可以使用equals再次确认两个对象是否相等,如果equals比较结果也返回true,则认为这两个对象相等。Java通过设计hashCode和equals协同的方式来确认两个对象是否相等,进而提升对象比较的效率。
为什么不直接使用hashCode比较就确定两个对象是否相等呢?
因为不同对象的hashCode可能相同,但是hashCode不同的对象一定不相等,所以通过hashCode可以快速初步判断对象是否相等。
1)重写equals方法为什么要一定要重写hashCode?
重写equals方法为什么要一定要重写hashCode?
Object 类中的 equals 方法用于检测一个对象是否等于另外一个对象。在 Object 类中,这个方法将判断两个对象是否具有相同的引用。如果两个对象具有相同的引用,它们一定是相等的。参考Object的equals源码
public boolean equals(Object obj) {
return (this == obj);
}
结合两个对象通过==比较,两个不同的对象通过Object的equals方法比较返回一定是false,但是实际业务场景中判断两个对象相等的条件可能是基于一些基础属性。例如以User用户为例,假设以用户姓名和用户身份证号来唯一确定用户身份,只要用户姓名、身份证号一致就认为是同一个人,因此往往需要通过重写equals方法来自定义规则判断两个对象是否相等。
hashCode:散列码,它是由对象推导出的一个整形值,并且这个值为任意整数(正数、负数)。散列码是没有规律的,如果x、y是两个不同的对象,则x、y的hashCode基本不会相同(也会出现hash碰撞的现象);但如果x、y是两个相等的对象,则x、y的hashCode一定相同。
// Object中的hashCode方法定义
public native int hashCode();
public class HashCodeDemo {
public static void main(String[] args) {
// 两个相等的对象hashCode一定相等;
String s1 = "hello";
String s2 = "hello world";
String s3 = "hello world";
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println(s3.hashCode());
// 两个不同的对象hashCode也可能相同
String s4 = "Aa";
String s5 = "BB";
System.out.println(s4.hashCode());
System.out.println(s5.hashCode());
}
}
// 测试结果
99162322
1794106052
1794106052
2112
2112
基于上述equals和hashCode概念,只是重写equals和hashCode的必要性,还是没有体现为什么在重写equals方法的时候一定要重写hashCode。此处引入Set集合进行分析
// Set集合的普通应用
class SetCommon{
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("JAVA");
set.add("PYTHON");
set.add("MYSQL");
set.add("JAVA");
set.add("REDIS");
System.out.println("SET集合长度:" + set.size());
// 打印集合元素
set.forEach(obj -> System.out.println(obj));
}
}
// 执行结果
SET集合长度:4
JAVA
MYSQL
REDIS
PYTHON
// 执行结果分析
Set中的重复数据已经被“合并”了,Set只能存储非重复元素,字符串相等的对象被当做重复元素被合并
// 定义课程类
class Course{
private String name;
private String code;
public Course(String name, String code){
this.name = name;
this.code = code;
}
public String getCode() {
return code;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "name:" + name + " code:" + code;
}
// 重写equals方法(只要code和name相同,则认为是同一个对象)
@Override
public boolean equals(Object obj) {
// 引用相同返回true
if(this == obj){
return true;
}
// 判断参数是否为null
if(obj == null || getClass() != obj.getClass() ){
return false;
}
// 引用不同进一步判断code、name
Course course = (Course) obj;
return course.getCode().equals(this.getCode()) && course.getName().equals(this.getName());
}
public static void main(String[] args) {
Course c1 = new Course("JAVA","001");
Course c2 = new Course("PYTHON","002");
Course c3 = new Course("MYSQL","003");
Course c4 = new Course("REDIS","004");
Course c5 = new Course("JAVA","001");
Set<Course> set = new HashSet<Course>(){};
set.add(c1);
set.add(c2);
set.add(c3);
set.add(c4);
set.add(c5);
System.out.println("SET集合大小:"+ set.size());
set.forEach(obj -> System.out.println(obj));
}
}
// 执行结果
SET集合大小:5
name:JAVA code:001
name:REDIS code:004
name:PYTHON code:002
name:JAVA code:001
name:MYSQL code:003
// 执行结果分析
根据上述结果分析,理想情况下重写了equals方法,设定code、name校验一致则认为是同一个对象,但是Set并没有识别出代码中定义的JAVA Course是同一个对象,因此不满足自定义业务校验规则
如何解决上述“异常问题”?通过重写hashCode
// 通过重写hashCode解决对象校验不相等“异常”(进一步验证为何重写equals方法的时候要重写hashCode)
@Override
public int hashCode() {
// return -1;
// 调整为对比name、age的hash是否相等
return Objects.hash(name,code);
}
原因分析:前面说到两个对象比较的方式是通过hashCode、equals方法协同校验的,所以当两个对象比较的时候,会先校验hashCode是否相同,当没有重写hashCode的时候,hashCode比较的是两个不同引用地址的对象,则其返回结果是false,则此时不会进入下一步的equals判断(因为hashCode的比较都没有通过),因此此处就算重写了equals方法也是处于“失效”状态(这点可以通过断点进行验证:在不重写hashCode的情况下,对equals方法进行断点,会发现程序不会进入该方法),基于此程序最终判定JAVA的课程这两个对象是不相等的,因此在Set集合中插入就会出现所谓的“异常”(没有按照自定义规则)
为了解决上述“异常”问题,通过重写hashCode进行解决,让程序在比较两个Course对象的时候正常按照hashCode、equals方法进行判断,先比较hash值,如果hashCode相同则进一步比较equals方法,两者均返回true则说明这两个对象相等,则Set会将其判定为重复对象而不会将其加入集合。
例如此处hashCode返回-1的场景也是为了默认“放行”,让其根据自定义的equals规则来校验对象是否相等。
3.clone方法
学习资料
Java中的浅拷贝和深拷贝
Java中的Object类还提供了一个clone的方法,该方法用于帮助其他类实现自我克隆,也就说自我复制。
public class Address {
private String city;
private String street;
public Address() {}
public Address(String city, String street) {
this.city = city;
this.street = street;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
public String toString() {
return city +street ;
}
}
/**
* 如果一个类中要实现克隆,需要实现Cloneable接口
* Cloneable接口是个空接口,是标志性接口
* 如果实现该接口,需要重写clone方法(不需要作任何改动)
* 此处定义User类实现Cloneable接口
*/
public class User implements Cloneable {
private String name;
private int age;
private Address address;
public User()
{
}
public User(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
/**
* 重写clone方法,不需要对原来的内容作任何改动
* 可以返回指定的类型,此处返回User类型
*/
protected User clone() throws CloneNotSupportedException {
return (User)super.clone();
}
}
public class CloneTest {
public static void main(String[] args) throws Exception {
Address address = new Address("A城市","A1街道");
User u1 = new User("xx",18,address);
User u2 = (User) u1.clone();
System.out.println("u1:"+u1.getName()+"--"+u1.getAge()+"--"+u1.getAddress());
System.out.println("u2:"+u2.getName()+"--"+u2.getAge()+"--"+u2.getAddress());
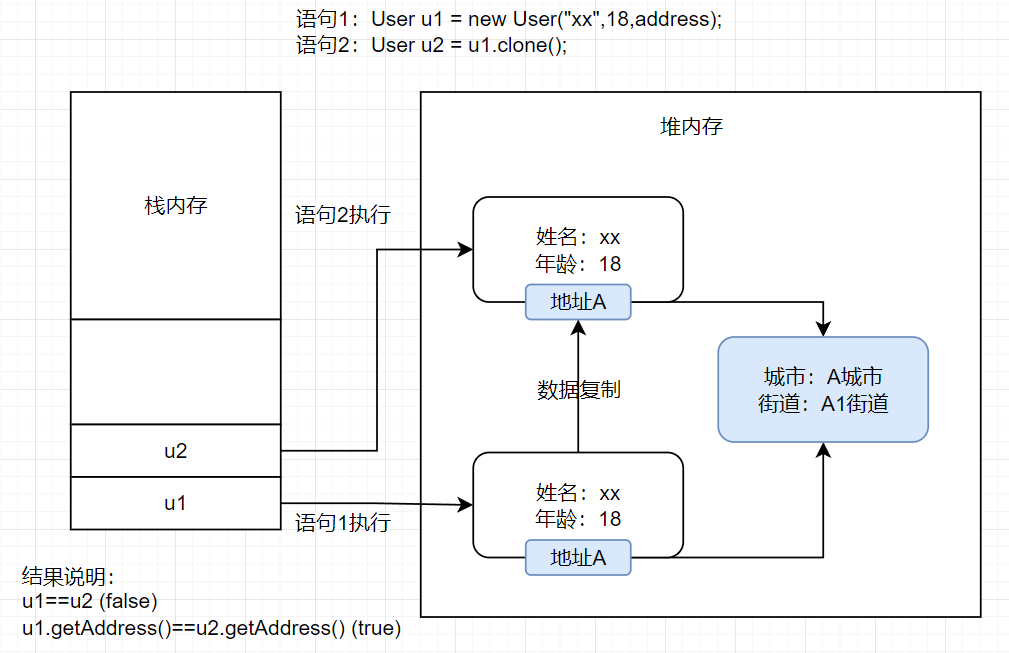
System.out.println(u1==u2);//false
System.out.println(u1.getAddress()==u1.getAddress());//true
/**
* 浅克隆的相关概念:
* 分析:u2是由u1对象克隆而来,因此u1、u2并不是指向同一个对象
* 但两者的信息完全相同(此处为姓名、年龄、地址)
* 克隆的含义是指将数据复制一份,由u2指向这份数据,但这份数据中的
* address指向还是原来的address,因此有
* u1.getAddress()==u1.getAddress()返回的结果为true
* 而u1==u2返回的结果为false
*/
}
}
String类
1.String类
结合String源码定义分析String
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
@Stable
private final byte[] value;
}
- String类被final关键字修饰,表示不可继承String类
- String类的数据存储与一个byte[]类型的数组,这个数组被final修饰,表示String对象不可更改
为什么Java要如此设计String?
- 保证String对象的安全性(避免String被篡改)
- 保证hash值不会频繁变更
- 实现字符串常量池
字符串对象的创建方式有2种:
- 方式1:通过字符串常量的方式创建:
String s = "abc"; - 方式2:通过new关键字创建:
String s = new String("abc");
使用方式1创建字符串对象的时候,JVM首先会检查该对象是否在字符串常量池中,如果存在则返回对象引用,否则将会在字符串常量池中创建新的字符串(目的是减少同一个值的字符串对象的重复创建,节约内存)
使用方式2这种方式,首先在编译类文件时,“abc”常量字符串将会放入常量结构中,在类加载的时候“abc”将会在常量池中创建;其次在调用new的时候,JVM命令会调用String的构造函数,同时引用常量池中的“abc”字符串,在堆内存中创建一个String对象;最后再通过s引用这个String对象。
String的性能考量
- 字符串拼接(字符串常量拼接、字符串变量拼接)
- 字符串常量的拼接,编译器会将其优化为一个常量字符串
- 字符串变量的拼接,编译器会将其优化为StringBuilder的方式
// 字符串拼接
class StringSplice{
public static void main(String[] args) {
// 1.字符串常量拼接(编译器将其优化为一个常量字符串)
String str = "hello" + "world";
System.out.println(str);
// 2.字符串变量拼接(编译器将其优化为StringBuilder的方式)
String s = "";
for (int i = 0; i < 10; i++) {
// 等价于 s = new StringBuilder(s).append(i).toString();
s = s + i;
}
}
}
基于上述方式2中对字符串变量的拼接,每次循环都会生成一个StringBuilder实例,会降低系统的性能。
字符串拼接的正确方案
- 针对字符串拼接:优先考虑
StringBuilder的append方法代替使用+号 - 并发编程中涉及到线程安全问题则使用StringBuffer(但StringBuffer是线程安全的,涉及到锁竞争,性能上来说比StringBuilder要差一点)
- 针对字符串拼接:优先考虑
字符串切割
- String的
split()方法,结合正则表达式使用可以实现强大的分割功能;(但是正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题,很可能导致 CPU 居高不下) - 可以考虑使用
String.indexOf()方法代替split()完成字符串分割
- String的
String.intern
在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用,这样一开始的对象就可以被回收掉。
在字符串常量中,默认会将对象放入常量池;在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。
如果调用 intern 方法,会去查看字符串常量池中是否有等于该对象的字符串,如果没有,就在常量池中新增该对象,并返回该对象引用;如果有,就返回常量池中的字符串引用。堆内存中原有的对象由于没有引用指向它,将会通过垃圾回收器回收。
使用 intern 方法需要注意:一定要结合实际场景。因为常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担
2.String、StringBuffer、StringBuilder
String类与StringBuffer类、StringBuider类都是用于存储字符串类型的数据,但String类(不可变类)存储的是不可变的字符串序列(即一个String对象被创建之后,包含在这个字符串对象的字符序列不能够被改变,直到该对象被销毁、被垃圾回收都不会改变),而StringBuffer类、StringBuilder类存储的是可变的字符串序列,可通过该类对应提供的append/insert/reverse/setCharAt等方法改变对应字符串对象的字符序列。但StringBuffer是线程安全的,StringBuilder是线程不安全的
结合数据存储、性能、线程安全、操作等方面对比