Da-API平台
项目总结
1.项目介绍
项目介绍
基于 React + Spring Boot + Dubbo + Gateway 的 API 接口开放调用平台。
管理员可以接入并发布接口,可视化各接口调用情况;用户可以开通接口调用权限、浏览接口及在线调试,并通过客户端 SDK 轻松调用接口。
项目名称:XX API 开放平台、接口、接口平台、API、接口一站通
在线访问:xxx(建议部署一下,提供可访问的、简短的线上地址)
GitHub:xxx(建议把项目放到代码仓库中,并且在主页文档里补充项目信息)
专业技能
后端
熟悉 Java 知识(如集合类、异常处理),能熟练运用 Lambda 表达式、Hutool、Apache Utils 编程
熟悉 SSM + Spring Boot 开发框架,能够使用 MyBatis Plus + MyBatis X 自动生成基础 CRUD 代码
熟悉 MySQL 数据库及库表设计,能够通过创建索引、Explain 分析等方式优化性能
熟悉常见的业务开发场景:比如API 签名认证、用户权限管理、Spring Boot Starter SDK 开发等
熟悉 Nacos 和 Dubbo RPC 框架,能使用 Spring Cloud Gateway 实现 API 网关、访问控制
熟练使用 Git、IDEA、ChatGPT、Swagger、Navicat 等工具提高开发协作效率
前端
熟悉 React 框架开发,能够根据业务定制前端模板,比如封装全局异常处理逻辑、多环境配置等
熟悉前端代码规范,并能够使用 ESLint + Prettier + TypeScript + Husky 等技术保证前端项目质量。
熟悉 Ant Design、Echarts、Lodash 等组件库和工具的使用
能够使用 Ant Design Pro 框架、Umi OpenAPI 代码生成、VS Code、WebStorm IDE 等开发工具快速开发前端项目
核心要点:
后端
根据业务流程,将整个项目后端划分为 web 系统、模拟接口、公共模块、客户端 SDK、API 网关这 5 个子项目,并使用 Maven 进行多模块依赖管理和打包。
使用 Ant Design Pro 脚手架 + 自建 Spring Boot 项目模板快速构建初始 web 项目,并实现了前后端统一权限管理、多环境切换等基础能力。
基于 MyBatis Plus 框架的 QueryWrapper 实现对 MySQL 数据库的灵活查询,并配合 MyBatis X 插件自动生成后端 CRUD 基础代码,减少重复工作。
前端:后端使用 Swagger + Knife4j 自动生成 OpenAPI 规范的接口文档,前端在此基础上使用插件自动生成接口请求代码,降低前后端协作成本。
为防止接口被恶意调用,设计 API 签名认证算法,为用户分配唯一 ak / sk 以鉴权,保障调用的安全性、可溯源性(指便于统计接口调用次数)。
为解决开发者调用成本过高的问题(须自己使用 HTTP + 封装签名去调用接口,平均 20 行左右代码),基于 Spring Boot Starter 开发了客户端 SDK,一行代码 即可调用接口,提高开发体验。
选用 Spring Cloud Gateway 作为 API 网关,实现了路由转发、访问控制、流量染色,并集中处理签名校验、请求参数校验、接口调用统计等业务逻辑,提高安全性的同时、便于系统开发维护。(更多 API 网关的优点参考:https://blog.csdn.net/guorui_java/article/details/124112897)
为解决多个子系统内代码大量重复的问题,抽象模型层和业务层代码为公共模块,并使用 Dubbo RPC 框架实现子系统间的高性能接口调用(实测单机 qps 达 xx),大幅减少重复代码。
前端
使用 ECharts(或 AntV)可视化库实现了接口调用的分析图表(如饼图),并通过 loading 配置提高加载体验。
为了提高开发效率,选用 Ant Design Pro 脚手架快速搭建基础页面,并对原始模板进行瘦身、抽象为可复用的公共模板,便于后续同类项目的快速研发。
在脚手架自带的 umi-request 请求库基础上进行改造和封装,添加全局请求拦截和全局异常处理逻辑、自动根据项目启动命令来区分环境,减少重复代码、提升项目可维护性。
项目扩展
前端优化项
参考 Swagger(或 Postman)等 API 管理产品实现了 API 文档浏览及在线调用功能,并提供多级联动表单来提升用户输入请求参数 json 的体验。
阅读 Ant Design Pro 的文档,从框架的特性出发、结合自己做的功能去写一些亮点。
后端优化项
如果项目已上线且提供了一些 API 接口,可以说:自主开发了 XX、XX 等 API 接口并接入系统,累积调用次数达 xx 次,且接口调用可用性达 99.999%(4 - 5 个 9 都可以)
客户端 SDK 尽量使用最少的依赖,可以补充提一些 SDK 设计的亮点,比如:基于 Spring Boot Starter,自主设计客户端 SDK,并遵循 xx、xx、xx 等规范,保证了 SDK 的精简、避免依赖冲突。
使用 Docker 或 Docker Compose 来部署项目,可以写:自主编写 Dockerfile,并通过第三方容器托管平台实现自动化镜像构建及容器部署,提高部署上线效率。
思考如何保证接口调用的性能、稳定性和可用性(比如在网关增加限流 / 降级保护)?
思考如何提高开发者接入平台的效率、安全性等,真正地让平台成为开放平台。
可以考虑在微服务网关前搭建 Nginx 网关,通过负载均衡实现更大的并发。
在数据量大的情况下,使用 Spring Scheduler 定时任务离线计算结果集来替代实时查询,提高了后端统计分析的性能,单次查询响应时长从 xx 降低至 xx。
个人评价
有较强的文档阅读能力,曾自主阅读 Spring Cloud Gateway、Dubbo(Ant Design Pro)等官方文档并能够运用到项目中。
有较强的问题解决能力,能够利用 GitHub Issues 区、AI 工具、搜索引擎、Stack Overflow 等自主解决问题
2.项目常见问题
项目相关
【1】请介绍一下本项目的完整业务流程?
假设有一个获取今日天气的接口,管理员可以在 API 开放平台创建并发布该接口。
用户在注册登录后,会分配一对接口调用签名(ak / sk),用户可以在网站上浏览接口文档并进行在线调试,还可以使用客户端 SDK 轻松地在自己的代码中调用接口。
系统后端会校验用户签名的合法性,并统计接口的调用次数,管理员可以在后台查看分析各接口的调用情况。
【2】在开发过程中,遇到过比较复杂的技术问题或挑战吗?如果有,请谈谈你是如何解决这些问题的?
可以从以上任意一道主观的面试题出发去讲。
比如在设计实现 API 签名认证算法时,发现鉴权结果和预期不同 —— ak、sk 明明完全一致,但就是无法通过鉴权。然后通过 debug 的方式,定位到了关键问题是由于中文编码、或者字段大小写不一致导致了签名不同。最后你通过修改中文编码等方式确保客户端和服务端生成的签名一致进行解决。
【3】项目是自己做的吗?为什么做这个项目?你做这个项目的背景(初衷)是什么?
尽可能地帮助和服务更多的用户和开发者,让他们更加方便快捷地获取他们想要的信息和功能。接口开放平台它可以帮助开发者快速接入一些常用的服务,从而提高他们的开发效 率,比如天气服务、随机头像和心灵鸡汤等服务,它们是一些应用或者小程序中常见的功能, 所以提供这些接口可以帮助开发者更加方便地实现这些功能。这些接口也可以让用户在使用应用时获得更加全面的功能和服务,从而提高他们的用户体验。所以我认为接口开放平台是一个有意义的项目,可以为用户和开发者带来更多的便利和价值。尽量上线并提供一些真实的接口服务。
【4】项目架构如何设计
采用前后端分离的架构,前端使用Nginx部署,通过Nginx反向代理将请求转发到web项目
暂时采用了单机部署的模式,未来可能采取水平扩容的方式,增加多台节点,通过Nginx的负载均衡,将请求平均的分发到我的每个节点上,以支撑更高的并发。
web项目使用Spring Boot开发,并连接到了数据库和Redis,数据库使用的是Mysql,主要用来存储用户的信息和接口的信息;通过Redis实现了 分布式session,因为考虑到未来要使用分布式架 构,为了避免使用tomcat保存session有用户登录失效的问题。
注:如果cue到反向代理,水平扩容,负载均衡等技术名词,很多面试官会根据这些名词进行延伸提问(引导面试官往自己熟悉的东西上提问)比如:说说什么是正向代理/反向代理?什么是水 平扩容?什么是负载均衡?你了解哪些负载均衡的算法?
【5】如何做技术选型?开发流程是什么?先实现还是先技术选型
使用SpringBoot是因为通过自动装配能够提高项目的开发效率,还能够很好的整合其他服务。
使用Mysql的原因是因为考虑到未来有用户充值交易,限制调用次数等场景需要用事务保证数据的完整性和一致性。使用Redis的原因是因为可以用来实现分布式session,锁,缓存等功能。因为
Redis是一个单独的中间件,不同客户端可以往同一个Redis或者集群中存放session/加锁,这样就能保证资源能够在分布式服务下都可见。并且由于Redis也是单线程的,同时也支持lua脚本,可以保证并发安全的问题,所以可以很简单的实现分布式锁的功能。
注:自动装配的原理你了解过吗?自动装配是怎么实现的?分布式session的原理?
开发构建思路:先参考了一些已有的产品,根据这些产品,总结出来比较好的功能点,再结合自己想要实现的一些功能特色,去做了一个项目整体设计,有了产品原型后再进行技术选型。使用什么样的技术去解决什么样的业务问题。
【6】为什么要使用网关
这个平台的关键点就在于提供接口服务,要保证接口的可用性和稳定性,所以将接口服务独立部署在另一台机器上,隐藏真实的接口地址及端口,调用接口服务的请求都必须经过网关流量染 色之后..(比如rpc调用获取用户sk,重新生成签名认证等等)之后,将请求转发到真实的接口地址,防止接口被恶意调用、盗刷。
【7】为什么要使用RPC调用?有了解过其他方式吗
因为如果在网关引入数据库的操作的话,不仅会增加项目体积,以及违背了设计原则的单一职责原则,所以考虑通过服务间调用的方式,我了解过有两种方式,第一种是Open feign,原理是 构造了一个HTTP请求,并会添加很多的请求头,body是使用json字符串传输,所以调用效率会比较低,更加适合外部服务间的调用。
RPC是可以基于TCP协议,避免了无用的请求头,以及可以通过将数据序列化为二进制流的形式传输,效率更加高效,更加安全,所以更适用于这个场景。最终选择了Dubbo RPC框架来实现这个功能。
【8】接口调用次数统计和排行如何实现?
通过Mysq|统计,每次调用结束后,网关都会发起一个rpc请求,调用次数+1。
注:这里我会抛出一个设计缺陷,在实际测试过程中,通过jmeter压测工具,会出现调用次数不准的情况,原因是因为没有在业务层面加锁,导致数据库出现并发写的问题。并且并发量大的话,对数据库造成很大的压力。引导面试官问出,那你有什么更好的解决方案吗?
答:如果在业务层面加一个写锁的话,会影响业务的执行效率,所以我想使用Redis去解决,Redis有一个数据结构Zset支持排序,score可以用来存储调用次数,并且Redis是单线程,可以解决并发问题。
注:这里被追问过Zset的底层实现,以及如何将这些数据进行持久化保存,防止Redis宕机导致数据丢失,可以从AOF, RDB展开来讲,或者在后台开启一个定时任务, 定时将这些数据进行落库。
【9】做了什么优化?接口性能如何?
答:我有一个接口是随机返回土味情话,我在数据库中插入了几千条土味情话,当调用接口时随机 返回一条。在还没有优化前,接口的qps在300左右,但是考虑到这个接口只有读操作,没有增删 改操作,所以我将这张表的存储弓|擎从Innodb改为了MyISAM,接口的qps提升到了1500。 注:被面试官追问为什么改为MyISAM有这么大的性能提升? Innodb和MyISAM有什么区别? 这个问题一定要根据自己实际情况来答,根据自己擅长的方面,比如对查询语句做了索引优化,提 升了接口的性能。 总而言之,面试官会从各个角度去深挖项目的细节,考量你是不是真的自己做的,是不是真的理 解?所以要做到对项目的所有细节都非常的熟悉。当完全理解项目之后,就能够提前预测到面试官 会怎么问,并在面试过程中说出一一些技术名词引导面试官,然后对这些问题,和延伸的知识点能够 完全掌握后,相信-定可以征服面试官。
- API项目使用缓存了吗? (其实我没有用缓存, 然后我就欺骗了面试官,因为之前确实想过怎么实现,就大致讲 了自己的看法:①先缓存不需要传参数,请求返回的结果数据一段时间内都是同一一个结果的数据,那么可以使用! redis直接缓存这些数据,设置过期时间时根据接口的更新时间来设置(比如每一天接口返回- 个不同的数据), 比 如可以使用定时任务+缓存预热的方法在每天凌晨定时缓存,过期时间设置为24H;②通过数据监测或分析统计那些 热点接口,使用业务名:类名:请求url:请求参数的组合作为缓存键,确保每个不同的请求都有唯一的缓存键, 如果结 果是单个值,则可以使用Redis的字符串类型存储;如果结果是一个复 杂的数据结构,则可以使用哈希类型。(这类 设置时过期时间可以稍微短一点, 因为参数不-致性,每个人每次访问的参数都可能不同,可复用性不高,降低 Redis压力),③缓存策略优化,使用L RU或L FU淘汰算法策略,LRF算法是使用双向链表和哈希表来维护缓存访问的 顺序,将最新访问的接口提到前面,留在尾部的就是不经常访问的数据,进行淘汰。LFU淘汰策略是使用堆或者队 列作为数据结构来存储每个接口的访问频率和时间戳,每次访问-个接口时,就将他的访问频率+1,淘汰数据时, 根据访问频率将较低的淘汰,如果访问率相同就按照时间戳将最先被访问的数据淘汰;④为处理恶意请求,即缓存 穿透和雪崩,可以使用缓存空值以及布隆过滤器,或设置随机的缓存失效时间避免缓存同时失效。)
- API项目里SDK开发流程? (就创建项目引入依赖, 然后编写配置类,用@Configuration、 @ConfigurationProperties(" api.client")、@ComponentScan注解标记配置类 ,然后在resources目 录下的MATE-INF 下的spring.factories里加入配置类的包路径,然后在其他项目中引入依赖,在yml里加载依赖的参数。)
- spring.factories是怎么加载SDK的? (这里我回答的是SpringBootApplication注解 下EnableAutoConfiguration注 解下Impor注解,会在项目启动的时候去spring.factories文件中加载配置)
API:尽可能多的帮助和服务用户和开发者,让他们更方便的获取想要的信息和功能,接口开放平台可以帮助开发者快速接入一些常用的服务,比如历史上的今天发生的事情,每日一句英文,随机头像等,这些是小程序或者应用开发中常见的功能,这些接口可以让用用户获取更全面的功能和服务,提高用户体验,所以这是一个很有意义的项目,可以为开发者带来更多的便利和价值。)
后端
【1】你的项目中使用了哪些技术栈?请分别介绍一下 Spring Boot、Dubbo、Gateway 在项目中的作用。
项目技术栈:SSM + Spring Boot、Spring Cloud Gateway、Dubbo、Nacos、MySQL、Redis、MyBatis-Plus、Hutool 工具库。 Spring Boot:用于快速构建基础的后端项目,只需要修改配置文件,就能轻松整合 SSM、MySQL、Redis 等依赖。 Dubbo:分布式 RPC 框架,实现项目中不同模块的高性能相互调用,比如网关服务集中统计接口调用次数时通过 Dubbo 调用接口服务完成次数扣减。 Gateway:作为 API 网关,集中接受客户端的请求,并执行统一的安全认证、请求转发、流量控制、请求日志、公共业务等操作。
【2】将后端项目划分为了多个子项目,请分别介绍这几个子项目的作用、以及它们之间是如何协作和交互的?
API 开放平台分为 5 个子项目(核心模块),分别为:
api-backend:核心业务后端,负责用户和接口管理等核心业务功能
api-gateway:API 网关服务,负责集中的路由转发、统一鉴权、统一业务处理、访问控制等
api-common:公共模块,包括各其他模块中需要复用的方法、工具类、实体类、全局异常等
api-client-sdk:客户端 SDK,封装了对各 API 接口的调用方法,降低开发者的使用成本。
api-interface:提供模拟 API 接口
交互流程:首先管理员创建接口后通过核心业务后端(api-backend)保存到数据库中。用户调用某个接口时,在自己的项目中引入客户端 SDK(api-client-sdk)并通过一行代码发起调用,请求会首先发送到 API 网关(api-gateway)进行用户的鉴权和接口调用统计,然后将请求转发到实际的 API 接口(api-interface)。
【3】请简要介绍 Maven 的基本概念、作用以及如何使用 Maven 进行多模块依赖管理和打包?
Maven 是一个开源的构建工具,用于管理 Java 项目的构建、依赖管理和项目生命周期。
本项目的所有依赖都是由 Maven 进行管理的,每个子项目都有自己的 pom.xml 进行管理。首先使用 mvn install 命令将 common 公共模块在本地打包,然后在其他子项目的 pom.xml 中引入该模块即可复用代码。每个子项目可以独立通过 mvn package 命令进行打包和部署。
Maven 还支持子父依赖多模块管理,通过 modules 配置给父项目指定子模块,从而实现统一的公共依赖和依赖版本定义。
【4】如何使用 MyBatis Plus 框架的 QueryWrapper 实现了对 MySQL 的灵活查询?
MyBatis-Plus 是 MyBatis 的增强版框架,允许用户通过编程的方式构建复杂的查询条件,无需编写繁琐的 SQL 语句。
在本项目中,使用 MyBatis-Plus 的 QueryWrapper 查询条件构造器,通过链式调用的方式,灵活构造接口信息表的查询条件,比如使用 like 方法指定根据描述模糊查询、比如 orderBy 指定查询排序规则等,示例代码如下
QueryWrapper<InterfaceInfo> qw = new QueryWrapper<>();
qw.like(StringUtils.isNotBlank(description), "description", description);
qw.orderBy(StringUtils.isNotBlank(sortField),
sortOrder.equals(CommonConstant.SORT_ORDER_ASC),
sortField);
除了 QueryWrapper 外,MyBatis-Plus 还提供了 LambdaQueryWrapper,支持使用 Lambda 表达式来定义查询条件,更灵活。
【5】什么是 OpenAPI 规范?它有什么作用或好处?
OpenAPI 规范是一种用于定义和描述 API 的开放标准,比如用 JSON 来描述 API 的请求地址、请求参数、请求类型、响应信息等。
通过遵循 OpenAPI 规范的接口描述信息,可以实现接口文档的自动生成、客户端和服务端代码的自动生成等,提高开发测试效率。
在项目中,使用 Knife4j + Swagger 自动生成 OpenAPI 规范的接口定义和可交互的接口文档,无需手动编写接口文档;并且在前端通过 Umi OpenAPI 插件根据 OpenAPI 接口文档自动生成了请求后端的代码,大幅提高开发效率。
【6】在项目中使用了 Swagger + Knife4j 自动生成接口文档,请谈谈 Swagger 和 Knife4j 的作用和它们对项目开发的影响
Swagger 是一个用于自动构建和生成可交互接口文档的工具集。使用 Swagger 接口文档生成工具后,我不需要在开发完项目后手动编写一套接口文档,而是直接交由系统自动根据 Controller 接口层的代码自动生成文档,大幅节省时间。
使用 Swagger 生成的接口文档不仅能够分组查看请求参数和响应,还支持灵活的在线调试,可以直接通过界面发送请求来测试接口,提高开发调试效率。
此外,引入 Swagger 后,可以得到基于 OpenAPI 规范的接口定义 JSON,可以配合第三方工具来根据 JSON 自动生成前端请求代码、自动生成客户端调用 SDK 等。
Knife4j 是 Swagger 的增强版,能够生成更美观的 API 接口文档,并且提供了离线文档导出、接口分组排序等增强功能。(参考官网:https://doc.xiaominfo.com/docs/features)
【7】什么是 API 签名认证算法?它有什么作用?你又是如何实现它的?
API 签名认证算法是一种用于验证 API 请求的合法性和完整性的安全机制。
给接口使用 API 签名认证算法,可以增强 API 的安全性,防止未经授权的用户访问、防止恶意用户篡改请求数据。 实现步骤如下:
(1)生成密钥对:给每个用户生成唯一的密钥对(accessKey 和 secretKey),并保存到数据库中,仅用户本人可查看自己的密钥对。
(2)请求方生成签名: 请求方(客户端)使用 secretKey 对请求参数和数据进行签名,签名的内容包括请求参数、时间戳、随机数等,签名加密算法此处选择 MD5。
(3)请求方发送请求:请求方将请求参数、签名、用户标识一起发送给 API 提供者,通常会把签名等元信息放到请求头参数中传递,注意千万不要传递 secretKey。
(4)API 提供者验证签名:在 API 网关中,通过请求头获取到用户标识,根据标识到数据库中查找该用户对应的 accessKey 和 secretKey,并使用相同的签名算法生成签名,和请求中的签名进行比对,如果签名一致,则 API 提供者可以信任请求方,可以进行后续操作。
【8】在项目中使用了 Spring Cloud Gateway 作为 API 网关,请解释一下 API 网关的应用场景,以及它在项目中的实际应用?
API 网关的主要应用场景:路由转发、统一鉴权认证、负载均衡、访问控制、流量染色、集中限流、统一监控和日志记录、全局跨域解决等。
在本项目中,使用 API 网关:
1)统一鉴权认证:应用 API 签名认证算法校验用户请求的合法性
2)公共业务逻辑:对每个接口的调用进行集中的统计
3)路由转发:前端发送请求到 API 网关,通过网关转发到实际的 API 接口
4)流量染色:给经过网关的请求加上特定的请求头参数,便于让实际的 API 服务确定请求来源及合法性
【9】如何基于 Spring Boot Starter 开发了客户端 SDK 的,讲述一下实现过程?
0)首先明确客户端 SDK 的定位和功能,不要把 SDK 设计得过于繁重
1)引入相关依赖。如 spring-boot-configuration-processor、spring-boot-autoconfigure 等,用于开启自动导入以及给出配置文件的编辑提示
2)编写配置类,用于创建一个客户端 Bean 对象。给配置类添加 @ConfigurationProperties(prefix = "noob.client") 注解,用于自动从 Spring Boot 配置文件中读取配置
3)注册配置类。在 resources/META_INF/spring.factories 文件中填写自动加载的配置类包路径
4)开发 SDK。像开发 Spring Boot 业务系统一样编写 SDK 功能代码
5)使用 SDK。在本地用 mvn install 命令打包 SDK,其他本地项目引入 SDK 即可使用
6)发布 SDK。在 Maven 中央仓库发布 SDK 包,其他开发者可通过 Maven 包索引在自己的项目中引入 SDK 并使用
【10】用户如何使用你开发的客户端 SDK?讲述一下流程
1)在 API 开放平台进行注册登录,获取到开发者密钥 ak、sk
2)下载 SDK 代码到本地,或者从 Maven 中央仓库引入 pom 依赖
3)在项目的 application.yml 配置文件中填写客户端配置,比如 ak、sk 等
4)项目启动时,会自动创建一个客户端调用对象,可以直接在项目中注入该对象并使用
【11】有哪些客户端 SDK 的设计技巧?
客户端 SDK 的目的是帮助开发者更轻松地使用系统提供的功能,因此在设计 SDK 时,要从开发者出发,提升开发者的调用体验。
可以从易用性、可理解性、可扩展性、高效稳定几个角度出发,多结合自己开发 SDK 的经历去回答,具体请见这篇文章:大厂 SDK 设计技巧 。
【12】什么是 RPC?为什么要使用 Dubbo RPC 框架,它有什么优势?
RPC(Remote Procedure Call,远程过程调用)是一种用于实现分布式系统通信的协议和技术。它允许一个计算机程序调用另一个地址的函数或方法,就像本地函数调用一样,而不需要开发者显式地处理底层网络通信和数据序列化等问题。
Dubbo 是基于 Java 的高性能、轻量级的开源 RPC 框架,便于开发者轻松实现分布式系统和微服务架构。此外,Dubbo 还提供了服务治理等功能。
Dubbo RPC 框架的优势,简单来说就是性能高、协议多、功能强、生态好、易扩展。
具体的优势如下:
性能优秀:Dubbo 经过高度优化,具有出色的性能表现,适用于高并发和低延迟的场景。
多协议支持:Dubbo 支持多种通信协议,可以根据不同的需求选择合适的协议,提供灵活性。
服务治理:Dubbo 提供了丰富的服务治理功能,包括负载均衡、路由、容错处理等,有助于构建可靠的分布式系统。
生态系统:Dubbo 有广泛的生态系统和社区支持,提供了大量扩展和插件,满足各种应用场景的需求。
可扩展性:Dubbo 的架构设计允许开发者轻松扩展和定制功能,以适应不同的业务需求。
【13】在项目中是如何使用 Dubbo RPC 框架的,讲述一下使用流程?
在正式运用 Dubbo 到项目前,先阅读 Dubbo 的官方文档,按照快速启动文档跑通了基础的 RPC 调用 Demo,明确了注册中心、Maven 包等各依赖的版本号。
先在本地启动 Nacos 注册中心
然后在服务提供者和服务调用者项目引入 Dubbo 依赖(尽量引入相同的依赖和配置)、编写 Nacos 的连接配置、并且在项目启动类通过 @EnableDubbo 注解开启 Dubbo 支持。
编写服务提供者和服务调用客户端类,分别加上 @DubboService 和 @DubboReference 注解
优先启动服务提供者项目,在 Nacos 控制台观察到服务注册信息,再启动服务调用者项目
【14】公共模块抽象模型层和业务层代码,请解释一下模型层和业务层的概念,并说明抽象公共模块的目的和好处
模型层(Model):包括数据模型、实体类、业务封装对象等,一般不包含业务逻辑。
业务层(Service):包含了应用程序的业务逻辑和处理规则,一般会用到模型层的代码。
抽象公共模块的主要目的是为了复用代码。尤其是在微服务项目中,通常要把独立于业务的请求响应封装对象、全局异常处理类、常量、公共的数据模型抽象为公共模块,提供给各业务服务引入,便于项目的维护和理解。
【15】API 网关实现了流量染色技术,请介绍一下流量染色的概念、以及它的作用?
流量染色是指根据请求的属性对请求进行分类和标记,从而进行特定的处理。
3 个关键概念:
1)请求分类:在请求层面的流量染色中,将请求分为不同的类别或组,通常基于请求的特性、内容、来源、用户身份等因素来进行分类。
2)请求标记:每个请求被标记为属于特定的类别或组,这个标记可以是请求头中的特定字段、请求参数、或其他识别请求的方式。
3)处理策略:为每个请求类别定义特定的处理策略,包括资源分配、访问控制、限流、缓存策略、安全性等。
在本项目中,所有的外部请求都要先经过 Gateway 网关,由网关给请求加上特定的请求头参数(比如 Source = MyAPI),便于让下游的 API 服务确定请求来源及合法性。
【16】dubbo + nacos 的实际意义大吗?不是可以直接用父子项目解决即可吗?
微服务拆分:Dubbo 是一种 RPC 框架,它允许你将系统拆分成微服务,每个微服务负责一个具体的业务功能。这样做的好处是,可以实现服务的解耦,提高系统的可维护性和可扩展性。
服务注册与发现:Nacos 是一种服务注册与发现组件,它可以和 Dubbo 配合使用,实现微服务之间的动态服务发现和负载均衡。这样,当服务数量众多时,服务之间的依赖关系可以更加灵活和动态。
服务治理:Nacos 不仅仅提供服务注册和发现的功能,它还提供了更全面的服务治理功能,包括配置管理、动态配置服务、服务监控等,这对于大型分布式系统的稳定运行至关重要。
跨项目调用:虽然在 SpringBoot 中父子项目可以直接调用方法,但在实际的分布式系统中,服务之间的调用往往是跨网络的,这涉及到网络延迟、数据一致性、容错处理等一系列问题,这些都是 Dubbo 和 Nacos 需要解决的问题。
生产环境的考虑:在生产环境中,不仅仅要考虑如何实现功能,还要考虑如何保证系统的稳定性、可伸缩性和可维护性。Dubbo 和 Nacos 为这些考虑提供了支持。
前端
【1】介绍你在项目中使用的 React 框架的优势和适用场景?
React 是主流的前端开发框架。用的人多、性能很好、生态成熟
优势:
组件化开发: React 的核心概念是组件化开发,将UI拆分为独立的可重用组件,使代码更易于理解、维护和测试。
虚拟 DOM: React引入了虚拟DOM的概念,通过在内存中维护虚拟DOM树,最小化了实际DOM操作,提高了性能和响应速度。
单向数据流: React采用了单向数据流模型,使数据流动可控,易于跟踪和调试。
生态系统:React拥有丰富的生态系统,包括大量的第三方库和组件,可以加速开发并提供各种解决方案。
跨平台支持: React可以用于构建Web应用、移动应用(React Native)、桌面应用(Electron)等,使得开发团队可以在不同平台上共享代码和技能。
社区支持: React拥有庞大的开发者社区和活跃的维护团队,可以获得大量的教程、文档和支持。
适用场景:
单页面应用(SPA): React非常适合构建单页面应用,其中所有交互都在同一个页面中完成,无需每次加载新页面。
大规模应用: React 的性能和可维护性使其成为开发大规模应用的理想选择,特别是需要多人协作的项目。
跨平台开发: 如果需要同时支持Web、iOS和Android,可以使用React和React Native来共享代码和技能。
服务端渲染(SSR): React可以用于服务器端渲染,提高应用的性能和搜索引擎优化(SEO)。
【2】项目中为什么选择了 Ant Design Pro 脚手架?谈谈对 Ant Design Pro 的使用体会和优缺点。
为了提高开发效率。
Ant Design Pro 是一个开箱即用的企业级前端应用开发脚手架,基于 React 和 Ant Design 构建,能够通过命令行选项的方式,快速创建一个包含示例页面、全局通用布局、权限管理、路由管理、国际化、前端工程化的默认项目。我只需要在此基础上编写和业务相关的页面即可,大幅节省时间。 Ant Design Pro 虽然功能强大且方便,但是对新手不够友好,一方面是项目功能太多,理解项目中的代码文件、系统阅读官方文档都要花费不少时间;另一方面是框架封装的代码较多,如果现有的功能不满足要求,自己定制开发新能力的成本较大。而且 Ant Design Pro 框架更新迭代太快,阅读文档和安装依赖时一定要选择指定的版本,否则可能就会出现依赖冲突、代码不兼容的情况。
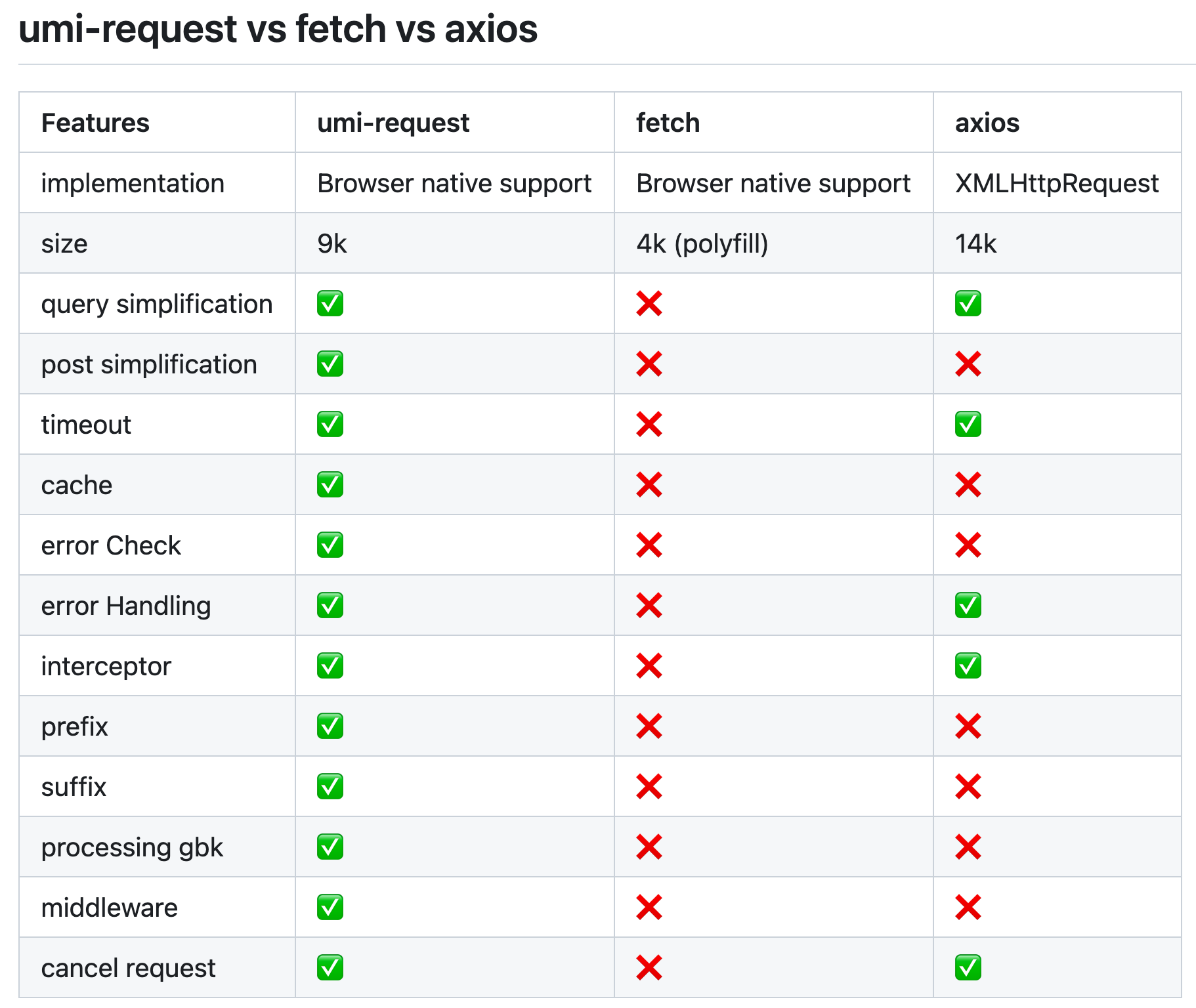
【3】umi-request 请求库和其他前端常见的请求库(比如 Axios)有什么区别?
umi-request 是一个基于 fetch 进行封装的请求库,专为 umi 框架(React 开发框架)设计,能够和 umi 框架更好的集成,比如在 umi 项目中直接通过配置文件更改请求的全局配置。 此外,还支持很多上层的特性,比如 api 超时处理、api 请求缓存、通用的错误处理、中间件支持、post 请求参数提交的简化等。
官方文档给出的对比表格
【4】对 umi-request 请求库进行改造和封装,能否详细说明你添加的全局请求拦截和全局异常处理逻辑是如何实现的?
通过定义 requestInterceptors 实现全局请求拦截器,在其中可以设置全局的请求头,并且通过 console.log 打印请求信息。
通过定义 errorHandler 实现全局异常处理,在其中通过 console.error 打印错误信息,然后可以通过组件库的 Message 组件给用户错误提示,或者将错误抛出给外层代码处理。
【5】项目中使用了 ECharts 可视化库来实现接口调用的分析图表,请解释一下 ECharts 的主要功能,以及你是如何在项目中使用 ECharts 的?
ECharts 是一个开源的数据可视化库,开发者只需要传入图表配置和数据,就能得到精美的交互式数据可视化图表。
选用 ECharts 主要是因为它的生态广、兼容性强、图表丰富,并且官网还提供了 Playground 页面来调试图表的样式。
在项目中,使用 ECharts 的饼图来展示各接口的总调用次数占比。
【6】如何实现前端多环境的?如何区分本地和生产环境的请求域名?
项目使用了 umi 框架,本地开发调试时执行 start 命令,会自动传入 NODE_ENV 参数为 development;生产环境 build 时 NODE_ENV 参数则为 production。 可以在前端的请求配置文件中,通过判断 process.env.NODE_ENV 是否为 production 来指定不同的请求域名。 此外,不同的项目(框架)都有不同的配置文件,umi 的配置文件是 config.ts,可以在配置文件后添加对应的环境名称后缀来区分开发环境和生产环境,比如:
开发环境:config.dev.ts
生产环境:config.prod.ts
公共配置:config.ts 不带后缀
参考文档:https://umijs.org/zh-CN/docs/deployment
【7】什么是 React 组件的生命周期,以及生命周期函数的执行顺序是怎样的?
React 组件的生命周期指的是组件在不同阶段(或生命周期阶段)内执行的一系列特定函数。这些生命周期函数允许你在组件的不同生命周期阶段执行特定的操作,例如初始化组件、处理数据、更新UI等。在 React 16.3 版本之后,生命周期函数分为三类:
1)挂载阶段(Mounting):这是组件被创建并插入到DOM中的阶段。在挂载阶段,有三个生命周期函数:
constructor(): 构造函数,用于初始化组件的状态和绑定事件处理程序。在组件生命周期中只会被调用一次。
render(): 渲染函数,用于生成虚拟DOM。它在组件挂载之前和每次更新时都会被调用。
componentDidMount(): 组件挂载后立即调用。通常用于执行DOM操作、网络请求、订阅事件等初始化操作。
2)更新阶段(Updating):这是组件重新渲染并更新到DOM中的阶段。在更新阶段,有两个生命周期函数:
shouldComponentUpdate(nextProps, nextState): 用于决定组件是否应该更新。默认情况下,它返回true,但你可以根据新的props和state与当前的props和state进行比较,来决定是否需要更新组件。
componentDidUpdate(prevProps, prevState): 组件更新后调用,通常用于执行与DOM相关的操作、网络请求、订阅事件等。
3)卸载阶段(Unmounting):这是组件从DOM中移除的阶段。在卸载阶段,只有一个生命周期函数:
componentWillUnmount(): 组件即将被卸载时调用。通常用于清理工作,如取消订阅、清除定时器等。
此外,React 16.3 版本后引入了一些新的生命周期函数,例如getDerivedStateFromProps和getSnapshotBeforeUpdate,用于更好地管理组件的状态和副作用。
生命周期函数的执行顺序如下:
1)挂载阶段:
constructor()
render()
componentDidMount()
2)更新阶段:
shouldComponentUpdate(nextProps, nextState)
render()
componentDidUpdate(prevProps, prevState)
3)卸载阶段:
componentWillUnmount()
需要注意的是,React 17 及以后的版本中,部分生命周期函数被标记为不推荐使用,并有可能在未来的版本中被移除。因此,在新项目中建议使用更现代的生命周期方法,如componentDidCatch、getDerivedStateFromProps等,以更好地处理组件的状态和副作用。
【8】在 React 中,什么是 Virtual DOM?它的作用是什么?与真实 DOM 相比,Virtual DOM 有什么优势?
Virtual DOM(虚拟 DOM)是React中的一个关键概念,它是一个轻量级的内存中表示真实 DOM 树的数据结构,其作用是优化页面渲染性能和提高开发效率。
Virtual DOM 的作用和优势如下:
1)性能优化:
快速更新: 当组件的状态发生变化时,React首先创建一个虚拟DOM树,然后将新旧虚拟DOM树进行比较(称为协调或调和),找出需要更新的部分,并将这些更新一次性批量操作到真实DOM中,而不是每次都直接操作真实DOM。这样可以减少真实DOM操作的次数,提高性能。
批处理更新: React会将多个状态更新合并为一个更新,以减少重排(reflow)和重绘(repaint)的开销,从而提高渲染效率。
2)跨平台支持:Virtual DOM的设计使得React不仅可以用于Web开发,还可以用于构建移动应用(React Native)和桌面应用(Electron),因为虚拟DOM树与平台无关。
3)提高开发效率:使用虚拟DOM可以使开发人员更容易管理和维护UI组件,因为它将UI的状态和视图分离,并提供了声明式的UI编程模型,使得UI的开发更直观和可预测。
4)减少直接DOM操作:直接操作真实DOM通常会导致性能问题,而Virtual DOM可以帮助开发人员避免直接DOM操作,从而提高代码的可维护性。
5)跨浏览器兼容性:虚拟DOM使得React可以处理不同浏览器之间的差异,开发人员无需担心不同浏览器的兼容性问题。
【9】在前端开发中,如何处理跨域请求?请描述常见的跨域解决方案以及它们的优缺点。
可以使用 JSONP 或者配置代理服务器来实现。比如在 Ant Design Pro 框架中,提供了一个 proxy 配置,可以直接开启对后端服务器的代理,从而解决跨域。
JSONP 的优点是简单易用,缺点是仅支持 GET 请求,且容易受到跨站脚本攻击。真实业务场景中,更推荐在服务端解决跨域,前端本地开发时通过代理绕过跨域即可。
【10】解释一下 React Hooks,并举例说明如何使用 useState 和 useEffect 这两个常用的 Hooks。
React Hooks 是 React 16.8 版本引入的一项功能,它们允许函数组件(无状态组件)使用状态管理和其他 React 特性,以前这些功能只能在类组件中使用。React Hooks 的目标是使组件的状态逻辑更容易复用、理解和测试。两个最常用的 React Hooks 是 useState 和 useEffect。
1)useState Hook:
useState Hook 用于在函数组件中添加状态管理。它返回一个状态变量和一个更新该变量的函数,可以用来在函数组件中管理和更新状态。
import React, { useState } from 'react';
function Counter() {
// 使用useState来声明一个状态变量count,初始值为0
const [count, setCount] = useState(0);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
<button onClick={() => setCount(count - 1)}>Decrement</button>
</div>
);
}
在上面的示例中,useState Hook 用于创建一个名为 count 的状态变量和一个名为 setCount 的函数。通过 setCount 函数,可以更新 count 的值。每次点击按钮时,count 的值会更新,并重新渲染组件。
2)useEffect Hook:
useEffect Hook 用于在函数组件中执行副作用操作,例如数据获取、订阅事件、手动管理 DOM 等。它接受两个参数,第一个参数是一个函数,用于执行副作用操作,第二个参数是一个数组,用于指定依赖项。 示例:
import React, { useState, useEffect } from 'react';
function DataFetching() {
const [data, setData] = useState([]);
useEffect(() => {
// 在组件挂载后,使用fetch API获取数据
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => setData(data))
.catch((error) => console.error('Error:', error));
}, []); // 空数组表示只在组件挂载后执行一次
return (
<div>
<h2>Posts</h2>
<ul>
{data.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
</div>
);
}
在上面的示例中,useEffect Hook 用于在组件挂载后执行数据获取操作。我们指定了一个空数组作为第二个参数,这表示副作用操作只在组件挂载后执行一次。如果指定了依赖项数组,useEffect 将在依赖项发生变化时重新执行。
【11】在前端开发中,如何优化网页的加载性能和渲染性能?请提供一些常见的优化策略和技巧?
优化网页的加载性能和渲染性能是前端开发中的关键任务之一,它可以提高用户体验并降低网站的跳出率。以下是一些常见的优化策略和技巧:
1)优化图片:
使用适当的图片格式:选择合适的图片格式(如WebP、JPEG、PNG)以减小文件大小。
压缩图片:使用压缩工具或在线服务来减小图片文件的大小。
使用响应式图片:为不同屏幕大小提供不同尺寸的图片,以避免加载过大的图片。
2)使用CDN(内容分发网络):
将静态资源(如CSS、JavaScript、图片等)托管到CDN上,加速资源的加载。
CDN可以将内容缓存到全球各地的服务器上,减少距离造成的延迟。
3)懒加载和预加载:
使用懒加载技术延迟加载图片和其他资源,只有当用户滚动到可见区域时才加载。
使用<link rel="preload">标签预加载关键资源,以提前下载可能需要的资源。
4)压缩和合并文件:
压缩JavaScript和CSS文件,减小文件大小。
合并多个CSS或JavaScript文件为一个,减少HTTP请求次数。
Ant Design Pro 使用 Webpack 打包工具,会自动对代码文件进行打包合并。
5)使用浏览器缓存:
使用 HTTP缓存头(如Cache-Control和ETag)来允许浏览器缓存资源。
使用 Service Worker 来创建离线应用程序,使用户在离线状态下也能访问网站。
6)减少重排和重绘:
避免频繁修改DOM,可以使用文档片段(DocumentFragment)进行批量操作。
使用CSS动画而不是JavaScript来实现动画效果,以减少重排和重绘。
7)代码分割(Code Splitting):
将应用程序拆分为多个模块或块,按需加载模块,减小初始加载时间。
使用工具如 Webpack 的import()语法来实现代码分割。
Ant Design Pro 支持在项目的全局配置文件中配置按需加载。
8)使用异步加载:
将非关键的JavaScript代码标记为异步加载,以防止它们阻塞页面加载。
使用<script async>标签来异步加载脚本。
9)前端框架和库的优化:使用轻量级的前端框架或库,以减少不必要的代码。
Ant Design Pro 其实是一个比较重的开发框架,更适合中后台管理系统。
10)监控和性能分析:
使用工具如 Google PageSpeed Insights、Lighthouse 等来检查和分析性能问题。
使用性能监控工具来实时追踪网站的性能指标,以便及时优化。 注意,性能优化是一个持续的过程,需要不断地监测、测试和调整,以确保网站保持高性能。