asyncflow-02-架构设计
asyncflow-02-架构设计
学习核心
- 理解框架整体架构
- flowsvr:server 设计思考(功能 & 接口)
- worker:worker 设计思考(功能 & 接入逻辑)
学习资料
架构设计
环境依赖
- MySQL:存储任务相关信息
- Redis:提供分布式锁,缓存信息加速缓存
1.框架架构
todo :图有点旧 待更新(参考项目立意的架构图)
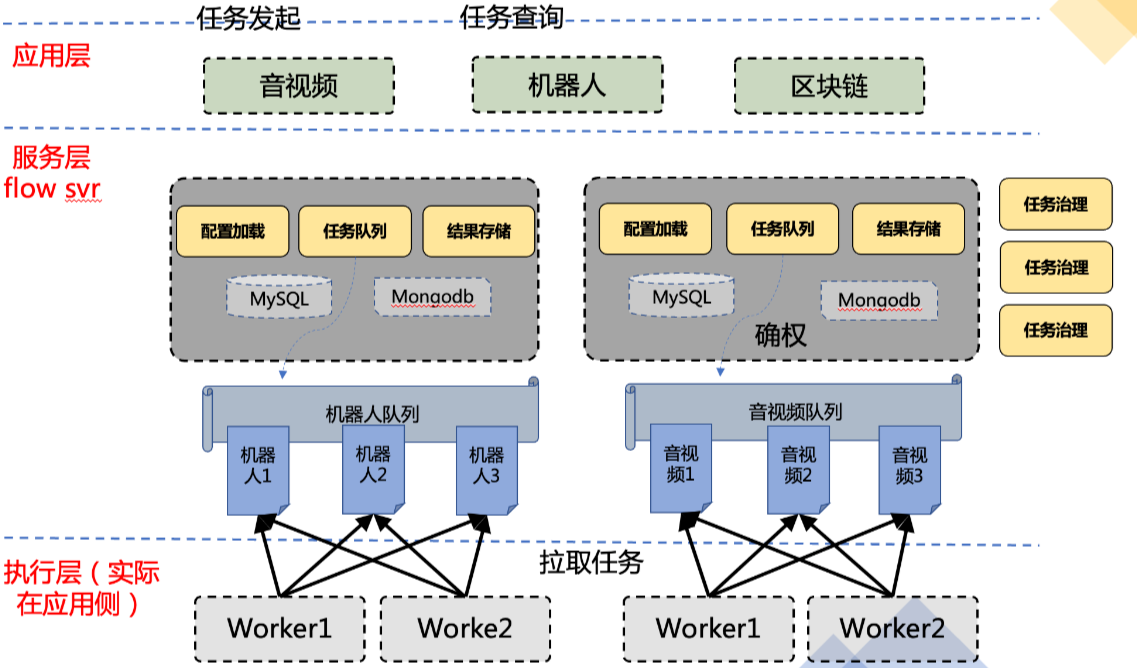
服务设计
- flowsvr服务(server):提供任务相关接口(例如任务创建、查询等),任务治理不作为单独的服务而是作为一个模块放在flowsvr项目中
- worker(worker):worker是用于消费任务的服务,通过flowsvr占据任务并执行,执行后通过flowsvr更新任务状态
- 使用者实现worker之后,自行部署worker
- app(发起任务的应用服务,即客户服务client),测试时可以通过curl或者postman模拟调用发起
- 引入服务通过该flowsvr发送请求,进而创建任务
此处之所以要拆分多个服务,主要还是为了职责分明,拆分的方式也有很多。
服务部署
- 本地部署模式:
- 1个MySQL、1个Redis
- 1个flowsvr
- 1个或多个worker
- 集群部署模式:
- 1个MySQL、1个Redis
- 多个flowsvr pod (部署在腾讯云集群上,通过CLB负载均衡访问)
- 多个worker pod(部署在腾讯云上)
针对集群部署模式,如果服务器资源不足可以简化说明是在一台服务器上部署多个服务进程(例如一台服务器上部署了3个flwosvr进程、3个worker进程),一般集群部署场景都是多机部署概念(多个机器部署,每个服务进程分开部署)
基于此可以进一步扩展docker、k8相关技术栈,K8S Pod 概念核心
概念扩展
何为任务治理?
此处任务治理即开线程轮询去做事情,例如开一个线程按照时间间隔查看数据表有没有达到500w,开一个线程按照时间间隔查看是否存在执行时间太长的异常任务(可采取措施处理异常,例如重置等)
任务治理功能是asyncflow框架提供的模块功能,作为框架使用者不需要单独开发一套
任务治理查看任务是否超时,根据当前时间减去调度信息中的数据更新时间(而非调度时间)
为何引入分布式锁?
多个worker可能存在资源竞争问题
2.数据表设计
✨任务配置表(t_schedule_cfg:任务调度配置表)
表定义
任务配置表:存放指定任务类型的配置信息
初始化任务配置(例如初始化下述lark任务配置),该配置指任意一个worker每10s调度一次,每次调度100个任务,每个任务这次调度执行的时间最多30s,系统运行过程中如果出现失败可提供最多3次机会失败,每次失败之后重试时间渐进式增长(翻倍),初始时5s,重试间隔时间最大不超过30s
insert into t_schedule_cfg(task_type, schedule_limit, schedule_interval, max_processing_time,max_retry_num, retry_interval)
values ('Lark', 100, 10, 30, 3, 10);
核心字段说明
- max_processing_time:处于执行中的最大时间(业务设定一个任务执行的最大时间,用于服务治理。例如超出正常执行的最大时间设定则认定任务执行异常,可以考虑采取重置操作)
- 这个时间是业务预估的,所以要尽量避免出现一个任务还处于正常执行中就被判定为异常的情况
- 如果真的出现异常,需考虑重置机制(是整个任务重新开始?还是失败的阶段重新执行?)
补充说明
任务配置表提供默认配置参考,具体的任务调度会采用默认的任务配置信息(可以理解为任务调度会依赖于任务配置表中配置的信息),但是如果一些任务执行比较特殊则可单独配置。
任务配置表的一个条目代表了一类任务的默认配置,但是属于这一类的具体某一个任务用到的是什么配置还是要看任务信息表中对应的条目,前者是后者的泛化,后者是前者的特化。
✨任务信息表(不同任务类型创建不同的任务信息表)
表定义
任务信息表:存放任务的具体数据信息
针对任务信息表的设计,每一类型的任务有一簇任务信息表,如果表中存储的数据大于500w则进行分表操作,例如有一个taskType为lark的任务类型,则构建其任务信息表表为:t_lark_task_1、t_lark_task_2、......t_lark_task_n(所谓一簇则是基于某个任务类型创建一个初始的任务信息表,后续经由分表后生成的一系列的任务信息表)
核心字段说明
id VS task_id:
- id 用作数据主键(一般不对外暴露)
- task_id(任务ID)可以理解为业务ID字段(类似电商场景的订单ID设计概念),任务ID的生成规则参考(uuid+任务类型+表号)
user_id:可以理解为业务关联的用户ID
task_type:任务类型,指的是自定义的任务类型(例如针对机器人、音视频等业务设定的任务类型)
task_stage:阶段名称(例如一个任务有多个阶段,则可分别设定为stage-1、stage-2、stage-3,用于阶段流转:stage-1 =》stage-2 =》stage-3)
max_retry_interval:最大重试间隔(设置了此字段就可以做阶梯间隔重试)
- 比如设置为10(最大间隔10),第1次失败后需要间隔1s才能被调度,第2次2s,第3次4秒,第4次8秒,第5次10s(因为最大是10)
schedule log:调度日志,包含这个任务本次调度的追踪id、耗时等信息(JSON结构存储形式)
- trace_id(追踪ID):在一般的开发中,每次请求或调度一开始都会生成一个唯一的trace_id,用于日志打印跟踪(相同trace_id表示处于相同流程,便于检索和跟踪)
type ScheduleInfo struct { LastData ScheduleData // 最近一次调度信息 HistoryDatas []ScheduleData // 历史调度信息,保留最近5次 } // ScheduleData struct ScheduleData type ScheduleData struct { TraceId string ErrMsg string Cost string }task_context:上下文(一般可以将任务请求放进去,参考如下结构设计)
// Lark任务的上下文 type LarkTaskContext struct { ReqBody *LarkReqBody // 业务请求的请求体 ...//根据业务添加更多字段 }order_time:调度时间,越小调度越优先 (服务于优先级功能实现)
✨任务位置表(t_schedule_pos:任务调度位置表)
表定义
任务位置表用于辅助分表功能的实现,其主要用于记录当前任务消费和任务创建的位置,这些数据会根据分表策略的执行进行更新
核心字段说明
- schedule_begin_pos:用于记录下次调度往哪个表拉取数据(任务调度/消费时要操作的表号)
- schedule_end_pos:用于记录下次创建任务往哪个表存放(任务新建时要操作的表号)
例如此处初始化创建都是1号表,任务新建和任务调度操作的都是1号表
表设计概念核心
任务类型和任务信息表的关系:不同任务类型的任务数据是存放在同一张表还是拆表存储?两种方式的选择优势
思路1-【拆表存储】:一个任务类型就对应一个任务信息表(针对不同业务设定不同任务类型,并构建相应的任务信息表)=》起到”隔离“作用,类似”企业租户“的概念设计,表隔离(不同业务创建不同的任务信息表),虽存在维护成本,但可扩展性强。且分开的好处在于不同业务类型不会互相干扰。引入这种设计是考虑到任务类型毕竟有限,维护成本可控
思路2-【单表存储】:所有的任务信息都存储在一个任务信息表中,通过不同任务类型区分业务 =》更为通用,便于客户端快速接入服务。但是将所有业务数据都堆到一张表中也存在一定的限制(例如无法业务隔离,如果某个业务的不当操作导致锁表,则可能影响到其他业务)。且基于公司层面考虑,将信息统一到一个任务表是为了便于其他业务侧接入,减少项目维护成本
3.状态流转
将任务状态划分为等待中、执行中、成功、失败:
- 中间态:等待中、执行中,根据不同情况可以跳转到其他状态
- 终态:成功、失败,终态不会再改变(除非直接操作数据库或者通过后台管理接口直接修改任务状态)

- 任务状态解读
- 任务等待中(任务等待某个 worker的调度);
- 任务执行中(任务正在被某个 worker 处理);
- 任务失败(任务执行失败后经过多次重试,已经达到最大的调用次数但还是没有成功);
- 任务成功(任务执行成功);
server 设计思考(功能 & 接口)
1.接口设计
接口请求基路径baseUrl:http://127.0.0.1:8081/api
taskType的设定取决于业务实现,目前初步提供了任务类型为“Lark”的任务实现,其调度逻辑是会根据任务配置的taskType、taskStage去匹配到对应的任务实现类的指定方法来进行调用(基于反射实现方法调用)
获取任务配置列表信息
接口实例
- 请求地址:
/task_schedule_cfg/list - 接口方法:POST
- 请求参数:无
- 响应体:
{
"msg": "ok",
"code": 0,
"result": {
"scheduleCfgList": [
{
"task_type": "Lark",
"schedule_limit": 100,
"schedule_interval": 10,
"max_processing_time": 30,
"max_retry_num": 3,
"retry_interval": 10,
"create_time": null,
"modify_time": null
}
]
}
}
创建任务
接口实例
请求地址:
/task/createTask接口方法:POST
请求参数:json
{ "taskData": { "userId": "noob", "taskType": "Lark", "taskStage": "sendmsg", "scheduleLog": "{}", "taskContext": "{\"ReqBody\":{\"Msg\":\"nice to meet u\",\"FromAddr\":\"fish\",\"ToAddr\":\"cat\"},\"UserId\":\"\"}" } }响应体:
{ "msg": "ok", "code": 0, "result": { "taskId": "211899957840445440_lark_task_1" } }
根据任务ID获取任务信息
接口实例
请求地址:/task/getTask
接口方法:GET
请求参数:params
参数 参考值 说明 taskId 211896101907726336_lark_task_1 任务ID 响应体:
{
"msg": "ok",
"code": 0,
"result": {
"taskData": {
"userId": "noob",
"taskId": "211896101907726336_lark_task_1",
"taskType": "lark",
"taskStage": "sendmsg",
"status": 2,
"crtRetryNum": 0,
"maxRetryNum": 3,
"maxRetryInterval": 10,
"scheduleLog": "",
"taskContext": "{\"ReqBody\":{\"Msg\":\"nice to meet u\",\"FromAddr\":\"fish\",\"ToAddr\":\"cat\"},\"UserId\":\"\"}",
"createTime": 1723022367534,
"modifyTime": 1723023186312
}
}
}
根据参数检索任务列表
接口实例
请求地址:
/task/getTaskList接口方法:GET
请求参数:params
参数 参考值 说明 taskType lark 任务类型 status 1 任务状态 limit 10 检索条数 响应体:
{
"msg": "ok",
"code": 0,
"result": {
"taskList": [
{
"userId": "noob",
"taskId": "211896147017465856_lark_task_1",
"taskType": "lark",
"taskStage": "sendmsg",
"status": 1,
"crtRetryNum": 0,
"maxRetryNum": 3,
"maxRetryInterval": 10,
"scheduleLog": "",
"taskContext": "{\"ReqBody\":{\"Msg\":\"nice to meet u\",\"FromAddr\":\"fish\",\"ToAddr\":\"cat\"},\"UserId\":\"\"}",
"createTime": 1723022378289,
"modifyTime": 1723022378289
}
]
}
}
占据任务
接口实例
请求地址:/task/hold_task
接口方法:POST
请求参数:params
参数 参考值 说明 taskType lark 任务类型 status 1 任务状态 limit 10 检索条数 响应体:返回占据到的任务列表
{ "msg": "ok", "code": 0, "result": { "taskList": [ { "userId": "noob", "taskId": "211976471437115392_lark_task_1", "taskType": "lark", "taskStage": "sendMessage", "status": 2, "crtRetryNum": 0, "maxRetryNum": 3, "maxRetryInterval": 10, "scheduleLog": "{}", "taskContext": "{}", "createTime": 1723041529123, "modifyTime": 1723041602039 } ] } }
更新任务信息
接口实例
请求地址:/task/setTask
接口方法:POST
请求参数:
{ "taskId": "211896101907726336_lark_task_1", "taskStage": "sendmsg", "status": 2, "scheduleLog": "{\"ReqBody\":{\"Msg\":\"nice to meet u\",\"FromAddr\":\"fish\",\"ToAddr\":\"cat\"},\"UserId\":\"\"}", "taskContext": "{\"ReqBody\":{\"Msg\":\"nice to meet u\",\"FromAddr\":\"fish\",\"ToAddr\":\"cat\"},\"UserId\":\"\"}", "orderTime": 612579324307, "priority": 34, "crtRetryNum": 24, "maxRetryNum": 50, "maxRetryInterval": 88 }响应体:
{ "msg": "ok", "code": 0, "result": null }
获取用户关联的任务列表(筛选状态)
接口实例
请求地址:
/task/getUserTaskList接口方法:GET
请求参数:params
参数 参考值 说明 userId noob 用户ID statusList 1 任务状态 响应体:
{
"msg": "ok",
"code": 0,
"result": {
"taskList": []
}
}
2.重点流程说明
优先级说明:在每个阶段可修改更新任务信息,例如任务到了阶段2,可以将任务优先级降低,可以尽量使所有任务都到阶段2再执行阶段2的任务,以满足一些场景需求
setTask接口是worker执行多阶段任务时用于更新task的信息
任务配置
根据不同任务类型创建一个默认配置,后续任务调度相关会校验配置信息
创建任务
创建任务流程由client触发,请求到flowsvr,调用创建任务接口。流程分析如下:
- client请求:client发起创建任务请求(这个client请求可能是前端触发、也可能是某个后端服务请求触发)
- flowsvr响应:flowsvr接收请求后进行响应处理(检查参数、创建执行任务):即生成一条任务记录(具体插入规则取决于业务逻辑设定)
- 回包:flowsvr响应请求,返回响应信息给client
占据任务
占据任务流程由worker触发,请求到flowsvr,调用占据任务接口。流程分析如下:
- worker请求:worker发起占据任务请求
- flowsvr响应:flowsvr接收请求后进行响应处理,按照指定规则从数据库中拉取一批任务,将这批任务设置为”执行中“,填充返回包(填充响应信息)
- 回包:flowsvr响应请求,返回响应信息给worker
任务调度
任务调度流程分析如下:
- 【1】启动任务调度
- 【2】根据任务间隔来触发调度函数
- 【3】获取锁
- 【4】调用hold tasks接口占据任务,获取到要执行的任务列表
- 【5】释放锁
- 【6】并发执行任务
- 【7】等待下次调度,跳转到第2步
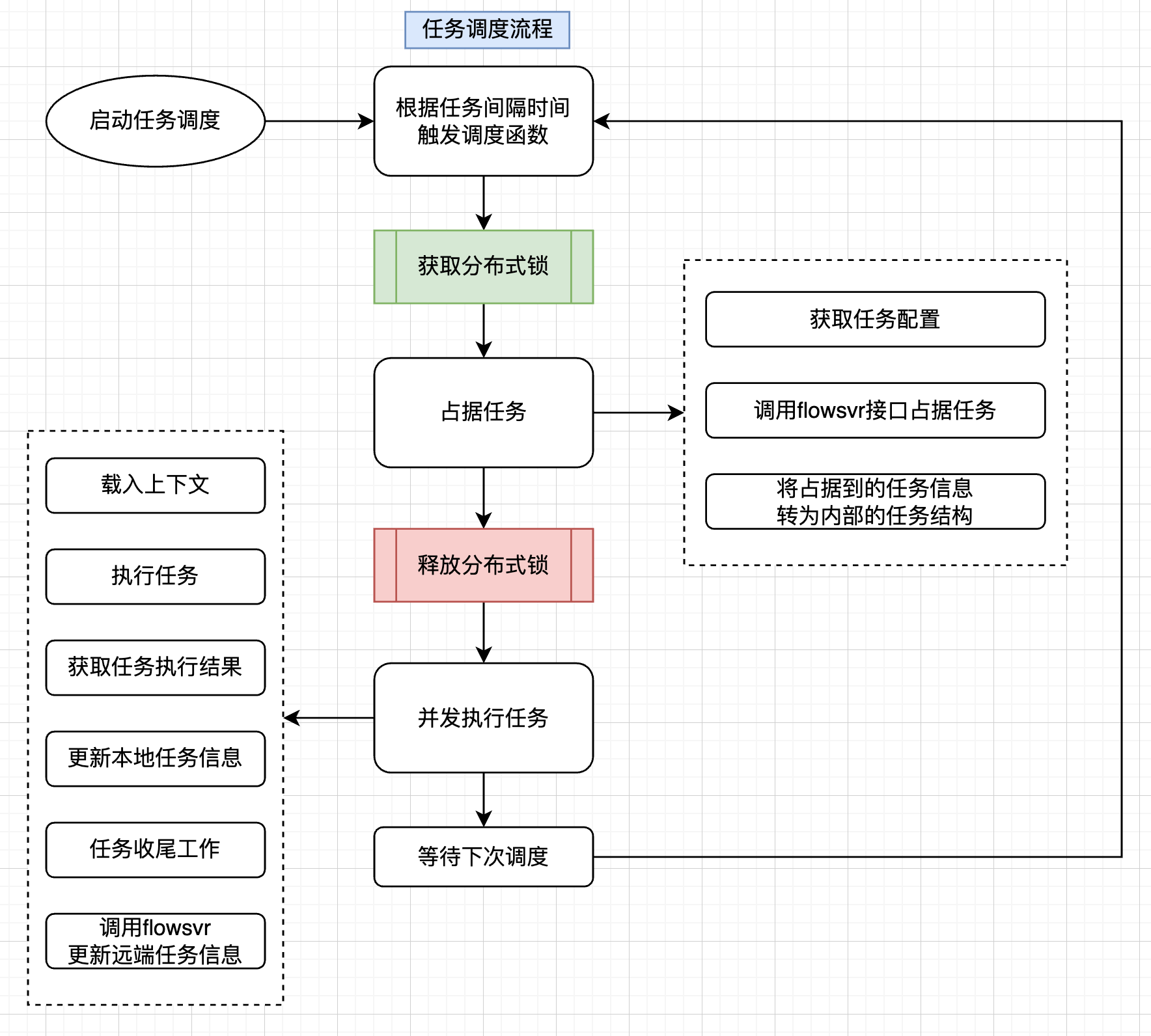
任务调度流程解析
任务是多阶段任务,执行是指一个worker将任务的各个阶段全部执行完毕再更新任务状态?还是只需要执行任务的一个阶段 后续阶段等待再次调度?=》常见的处理方式是待一个阶段完成就扔回去等待再次下一个阶段的调度,这样做的目的是为了让其他任务也有机会被调度,而不至于被一个任务一直占着资源(如果要等一个任务所有阶段都完成的话,一旦这个任务某个阶段执行失败不断重试就会堵住其他任务的执行了)
Redis 分布式锁的引入主要是针对同一个类型的任务调度资源锁定?=》框架支持多worker部署,引入Redis分布式锁是为了避免“多机竞争问题”,通过Redis分布式锁,抢占锁成功的worker可以拉取一批任务,待占据完成则释放锁,随后慢慢执行这批任务。基于worker多机部署的模式,一个worker抢到锁,则其他worker就直接等待下次调度机会
为什么是占据任务之后就释放分布式锁呢?此时任务还没执行完,这时候这批任务被其他worker 占据了怎么办呢 =》 此处占据任务之后任务状态被修改(将任务状态从"等待中"修改为"执行中"),状态更新成功后其他worker是拉取不到这些执行中的任务的(所以此处释放锁是可行的),调度的核心是:先抢占资源(更新任务状态),然后慢慢执行,执行失败就丢回去
“转化为内部的任务结构”概念 =》将mysql 的json数据 解析到代码的结构体中
更新本地任务信息 VS 更新远端任务信息:本地就是代码的结构体(根据任务需要的信息进行定义)、远端就是通过flowsvr接口更新mysql数据库
worker 设计思考(功能&接入逻辑)
worker 定位:worker 指的是进程,对应1个springboot 项目,一个进程中可以开启多个线程并发执行任务
worker 接入:需开发者写好worker的执行逻辑(引入相关依赖,实现接口方法填充业务逻辑)
worker 占据任务:worker定时获取任务(调用flowsvr接口占据并获取任务),如果存在多个worker获取任务,使用分布式锁来解决竞争问题
分析worker 处理某个任务的内容
worker设计细节
问题1:一个worker只能执行一种任务类型的任务还是可以执行多种不同任务类型的任务?
框架的实现是通过worker占据任务、执行任务,引入Redis分布式锁解决并发时共享资源占用问题。对于任务的拉取取决于任务的排序机制(通过order_time 和 优先级、重试机制得到一个时间值,这个值会作为任务拉取的排序依据),框架支持对单个任务类型的拉取,也支持对多个不同任务类型的拉取,这取决于业务逻辑的实现:
- 如果拉取单个任务类型:从指定任务类型的表中拉取任务,然后执行
- 如果拉取多个不同任务类型:一个worker是一个进程,如果需要处理不同任务类型的话,可以开启多个线程,每个线程拉取一批相同任务类型的数据然后执行
可以简单理解为,框架支持同一个worker处理单个或多个任务类型的任务,一个worker就是一个进程,同一个执行多个任务类型的任务则相当于开启不同的线程去处理不同类型的任务,这个可由具体的业务实现来决定
问题2:多个任务类型如何拉取执行处理,是for循环中再for多个任务类型?(例如有两个task_type、分别为lark1、lark2)asyncflow如何处理?
比较合理的设计场景是一类任务就使用一组独立的worker,达到完全解耦、互不影响的目的。
但实际上为了部署简单,也可能会在一组worker里面处理多种类型的任务,实际上无非是最外层多起几个线程,和其他处理一个的逻辑一样的
测试待确认问题
待定问题:通过 postman 调用hold tasks 占据任务这个接口他会将 status 从1改为 2,但是为啥返回的集合中的任务的status 还是1(这里调用完接口返回的集合是给 worker 的吧?),我从代码中看了一下,先是获取符合条件的数据存入集合 filterlist 中去,然后再收集每个数据的 id 到集合 ids 中去,然后根据这些 id去修改数据的状态为 2也就是进行中,他最后返回给 worker 的是之前查出来符合条件的 filterlist集合中的数据,相当于是在修改status 之前查的数据库,所以返回给 worker 的数据的 status 为1,那为什么不在修改之后再查一遍,这样返回给 worker 的数据的status 就为2了,这个 status对 worker 执行应该也是有影响的吧?
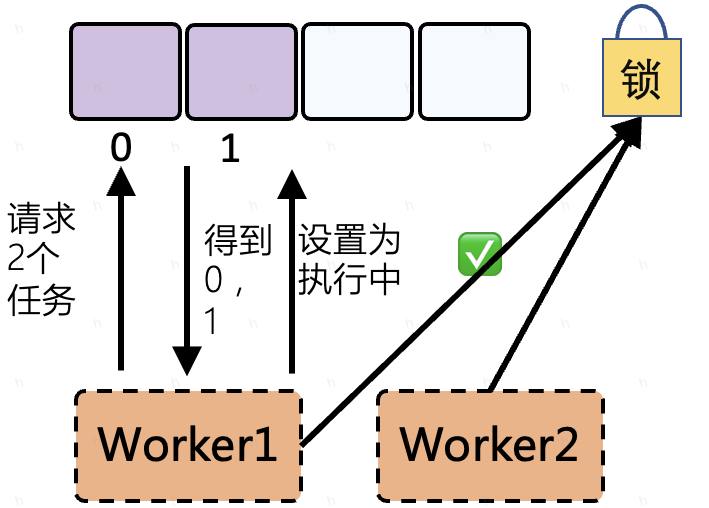
p.doSomething 逻辑是自定义的,复杂逻辑可以包装成调用接口的方式(例如调用腾讯云第三方服务等),如果是简单逻辑可以直接写在此处(具体看业务开发者自由支配)
只有每次新增一种任务类型才会需要扩展开发
首先理解项目怎么用?然后拆解剖析其实现