扩展版RPC框架-序列化器与SPI机制
扩展版RPC框架-序列化器与SPI机制
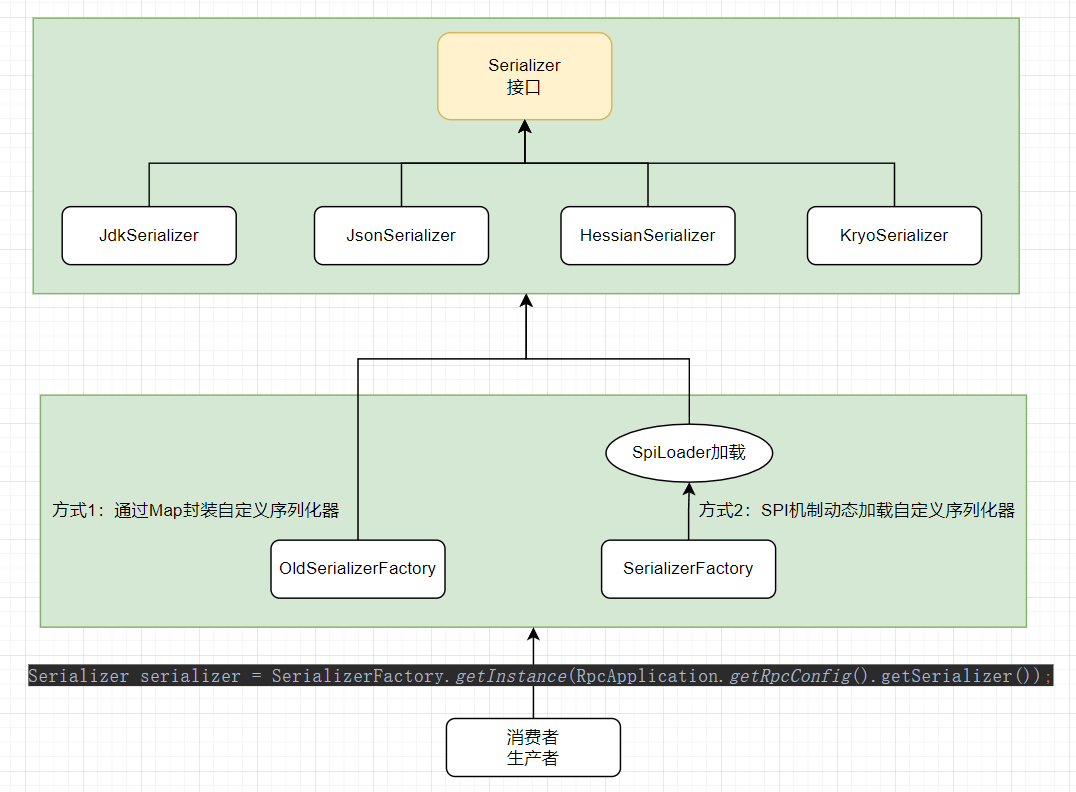
扩展核心
【1】序列化器概念和SPI机制引入
【2】自定义多种序列化器,结合SPI机制动态加载自定义序列化器
【3】提供扩展接口,可实现Serializer接口扩展自定义序列化器,随后将其注册并应用
需求分析
问题分析
序列化器的作用:无论是请求或响应,都会涉及参数的传输。而Java对象是存活在JVM虚拟机中的,如果想在其他位置存储并访问、或者在网络中进行传输,就需要进行序列化和反序列化。
在基础版RPC框架中定义了通用的序列化器接口,并且已经实现了基于Java原生序列化的序列化器。但是对于一个完善的RPC框架,还要思考以下3个问题:
【1】有没有更好的序列化器实现方式?
【2】如何让使用框架的开发者指定使用的序列化器?
【3】如何让使用框架的开发者自己定制序列化器?
方案分析
1.序列化器实现方式
所追求的“更好的”序列化器,可以是具有更高的性能、或者更小的序列化结果,这样就能够更快地完成RPC的请求和响应。
基础版PRC框架中使用Java原生序列化实现序列化器,但这未必是最好的。市面上还有很多种主流的序列化方式,比如JSON、Hessian、 Kryo、 protobuf 等。
| 序列化方式 | 优点 | 缺点 |
|---|---|---|
| JSON | (1)易读性好,可读性强,便于人类理解和调试 (2)跨语言支持广泛,几乎所有编程语言都有JSON的解析和生成库 | (1)序列化后的数据量相对较大,因为JSON使用文本格式存储数据,需要额外的字符表示键、值和数据结构 (2)不能很好地处理 复杂的数据结构和循环引用,可能导致性能下降或者序列化失败 |
| Hessian | (1)二进制序列化,序列化后的数据量较小,网络传输效率高 (2)支持跨语言,适用于分布式系统中的服务调用 | (1)性能较JSON略低,因为需要将对象转换为二进制格式 (2)对象必须实现Serializable接口,限制了可序列化的对象范围 |
| Kryo | (1)高性能,序列化和反序列化速度快 (2)支持循环引用和自定义列化器,适用于复杂的对象结构 (3)无需实现Serializable接口,可以序列化任意对象 | (1)不跨语言,只适用于Java (2)对象的序列化格式不够友好,不易读懂和调试 |
| protobuf | (1)高效的二进制序列化,列化后的数据量极小 (2)跨语言支持,并且提供了多种语言的实现库 (3)支持版本化和向前I向后兼容性 | (1)配置相对复杂,需要先定义数据结构的消息格式 (2)对象的序列化格式不易读懂,不便于调试 |
2.动态使用序列化器
// 简易版RPC框架使用序列化器
Serializer serializer = new JdkSerializer();
在简易版RPC框架中硬编码了使用的序列化器,如果要使用其他序列化器则需要修改代码。理想情况下可以通过配置文件方式指定使用的序列化器,根据不同的配置获取到对应的序列化器实例即可。参考Dubbo替换序列化协议的方式,其实现思路就是定义一个Map(序列化器名称:对应序列化器实现类对象),然后根据名称获取Map的对象即可。
3.自定义序列化器(引入SPI机制)
如果开发者不想使用框架内置的序列化器,但不能够修改RPC框架编写好的代码。实现思路是:只要自定义的RPC框架能够读取到用户自定义的类路径,然后加载这个类,作为Serializer列化器接口的实现即可,因此可以引入SPI机制实现。
SPI机制:SPI (Service Provider Interface)服务提供接口是Java的机制,主要用于实现模块化开发和插件化扩展。
SPI机制允许服务提供者通过特定的配置文件将自己的实现注册到系统中,然后系统通过反射机制动态加载这些实现,而不需要修改原始框架的代码,从而实现了系统的解耦、提高了可扩展性。
一个典型的SPI应用场景是JDBC (Java 数据库连接库),不同的数据库驱动程序开发者可以使用JDBC库,然后定制自己的数据库驱动程序。
此外,在一些主流Java开发框架中,几乎都使用到了SPI机制,比如Servlet容器、日志框架、 ORM 框架、Spring框架(Java开发者必须掌握)
SPI的实现分为系统实现和自定义实现。
系统实现
Java内已经提供了SPI机制相关的API接口,可以直接使用,这种方式最简单。
【1】在resources 资源目录下创建META-INF/services 目录,创建一个名称为要实现的接口的空文件
【2】文件中填写自己定制的接口实现类的完整路径
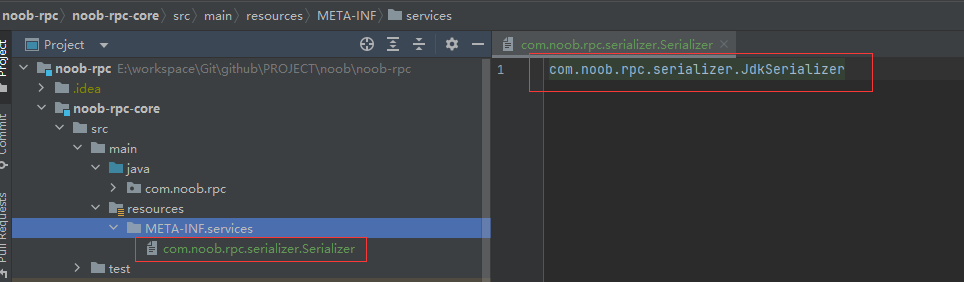
此处需注意文件存放路径、文件名称、内容中的类路径定义(如果配置关联不到则会提示No service provider "xxxxx" found)
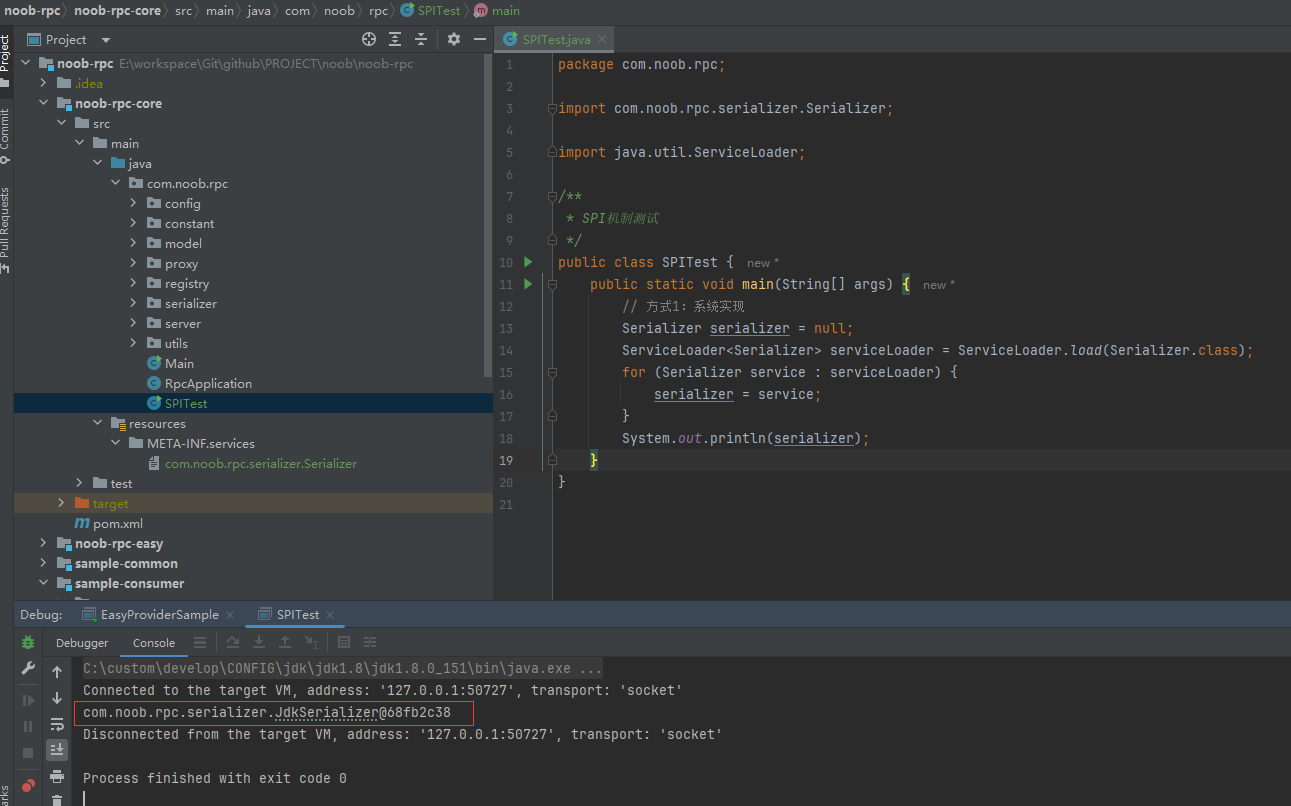
【3】使用系统内置的ServiceLoader动态加载指定接口的实现类
/**
* SPI机制测试
*/
public class SPITest {
public static void main(String[] args) {
// 方式1:系统实现
Serializer serializer = null;
ServiceLoader<Serializer> serviceLoader = ServiceLoader.load(Serializer.class);
for (Serializer service : serviceLoader) {
serializer = service;
}
System.out.println(serializer);
}
}
// 通过遍历可以获取到文件中定义的所有类,按需选择即可
自定义实现
系统实现SPI虽然简单,但是如果想定制多个不同的接口实现类,就没办法在框架中指定使用哪一个了, 也就无法实现“通过配置快速指定序列化器”的需求。
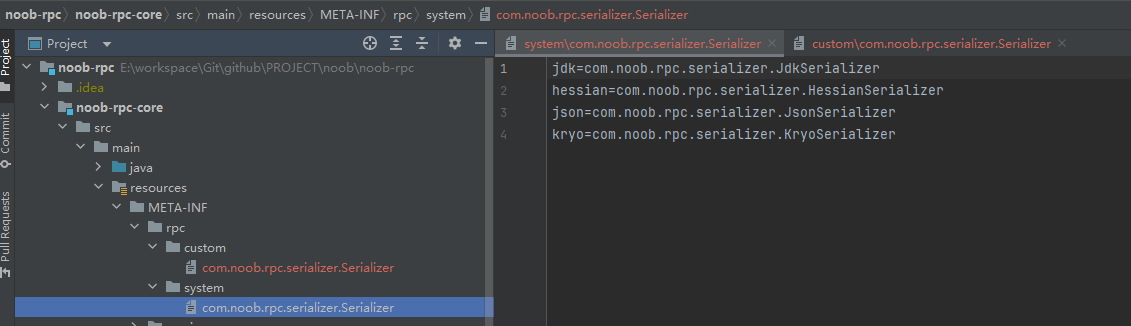
因此需要自己定义SPI机制的实现,只要能够根据配置加载到类即可。比如读取如下配置文件,能够得到一个序列化器名称=>序列化器实现类对象的映射,之后就可以根据用户配置的序列 化器名称动态加载指定实现类对象
jdk=com.noob.rpc.serializer.JdkSerializer
hessian=com.noob.rpc.serializer.HessianSerializer
json=com.noob.rpc.serializer.JsonSerializer
kryo=com.noob.rpc.serializer.KryoSerializer
实现步骤
1.多种序列化器实现、动态使用序列化器
构建步骤说明
【1】pom.xml引入相关依赖
【2】在serializer包中分别实现Json、Kryo、Hessian这三种主流的序列化器(可参考网上信息)
【3】定义序列化器常量SerializerKeys、序列化器工厂SerializerFactory
【4】RpcConfig新增serializer属性,将原有项目的序列化器硬编码方式调整为动态从配置中读取
pom.xml引入相关依赖
<!-- 序列化 -->
<!-- https://mvnrepository.com/artifact/com.caucho/hessian -->
<dependency>
<groupId>com.caucho</groupId>
<artifactId>hessian</artifactId>
<version>4.0.66</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.esotericsoftware/kryo -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.0</version>
</dependency>
在serializer包中分别实现Json、Kryo、Hessian这三种主流的序列化器
/**
* Json 序列化器
*/
public class JsonSerializer implements Serializer {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Override
public <T> byte[] serialize(T obj) throws IOException {
return OBJECT_MAPPER.writeValueAsBytes(obj);
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> classType) throws IOException {
T obj = OBJECT_MAPPER.readValue(bytes, classType);
if (obj instanceof RpcRequest) {
return handleRequest((RpcRequest) obj, classType);
}
if (obj instanceof RpcResponse) {
return handleResponse((RpcResponse) obj, classType);
}
return obj;
}
/**
* 由于 Object 的原始对象会被擦除,导致反序列化时会被作为 LinkedHashMap 无法转换成原始对象,因此这里做了特殊处理
* @param rpcRequest rpc 请求
* @param type 类型
* @return {@link T}
* @throws IOException IO异常
*/
private <T> T handleRequest(RpcRequest rpcRequest, Class<T> type) throws IOException {
Class<?>[] parameterTypes = rpcRequest.getParameterTypes();
Object[] args = rpcRequest.getArgs();
// 循环处理每个参数的类型
for (int i = 0; i < parameterTypes.length; i++) {
Class<?> clazz = parameterTypes[i];
// 如果类型不同,则重新处理一下类型
if (!clazz.isAssignableFrom(args[i].getClass())) {
byte[] argBytes = OBJECT_MAPPER.writeValueAsBytes(args[i]);
args[i] = OBJECT_MAPPER.readValue(argBytes, clazz);
}
}
return type.cast(rpcRequest);
}
/**
* 由于 Object 的原始对象会被擦除,导致反序列化时会被作为 LinkedHashMap 无法转换成原始对象,因此这里做了特殊处理
*
* @param rpcResponse rpc 响应
* @param type 类型
* @return {@link T}
* @throws IOException IO异常
*/
private <T> T handleResponse(RpcResponse rpcResponse, Class<T> type) throws IOException {
// 处理响应数据
byte[] dataBytes = OBJECT_MAPPER.writeValueAsBytes(rpcResponse.getData());
rpcResponse.setData(OBJECT_MAPPER.readValue(dataBytes, rpcResponse.getDataType()));
return type.cast(rpcResponse);
}
}
/**
* Kryo 序列化器
*/
public class KryoSerializer implements Serializer {
/**
* kryo 线程不安全,使用 ThreadLocal 保证每个线程只有一个 Kryo
*/
private static final ThreadLocal<Kryo> KRYO_THREAD_LOCAL = ThreadLocal.withInitial(() -> {
Kryo kryo = new Kryo();
// 设置动态动态序列化和反序列化类,不提前注册所有类(可能有安全问题)
kryo.setRegistrationRequired(false);
return kryo;
});
@Override
public <T> byte[] serialize(T obj) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Output output = new Output(byteArrayOutputStream);
KRYO_THREAD_LOCAL.get().writeObject(output, obj);
output.close();
return byteArrayOutputStream.toByteArray();
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> classType) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
Input input = new Input(byteArrayInputStream);
T result = KRYO_THREAD_LOCAL.get().readObject(input, classType);
input.close();
return result;
}
}
/**
* Hessian 序列化器
*/
public class HessianSerializer implements Serializer {
@Override
public <T> byte[] serialize(T object) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
HessianOutput ho = new HessianOutput(bos);
ho.writeObject(object);
return bos.toByteArray();
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> tClass) throws IOException {
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
HessianInput hi = new HessianInput(bis);
return (T) hi.readObject(tClass);
}
}
定义序列化器常量SerializerKeys、序列化器工厂SerializerFactory
/**
* 序列化器键名常量
*/
public interface SerializerKeys {
String JDK = "jdk";
String JSON = "json";
String KRYO = "kryo";
String HESSIAN = "hessian";
}
/**
* 序列化器工厂(工厂模式,用于获取序列化器对象)
*/
public class SerializerFactory {
/**
* 序列化映射(用于实现单例)
*/
private static final Map<String, Serializer> KEY_SERIALIZER_MAP = new HashMap<String, Serializer>
() {{
put(SerializerKeys.JDK, new JdkSerializer());
put(SerializerKeys.JSON, new JsonSerializer());
put(SerializerKeys.KRYO, new KryoSerializer());
put(SerializerKeys.HESSIAN, new HessianSerializer());
}};
/**
* 默认序列化器
*/
private static final Serializer DEFAULT_SERIALIZER = new JdkSerializer();
/**
* 获取实例
*
* @param key
* @return
*/
public static Serializer getInstance(String key) {
return KEY_SERIALIZER_MAP.getOrDefault(key, DEFAULT_SERIALIZER);
}
}
RpcConfig新增serializer属性,将原有项目的序列化器硬编码方式调整为动态从配置中读取
@Data
public class RpcConfig {
/**
* 序列化器
*/
private String serializer = SerializerKeys.JDK;
}
// 硬编码方式:指定序列化器
final Serializer serializer = new JdkSerializer();
// 方式2:动态获取序列化器
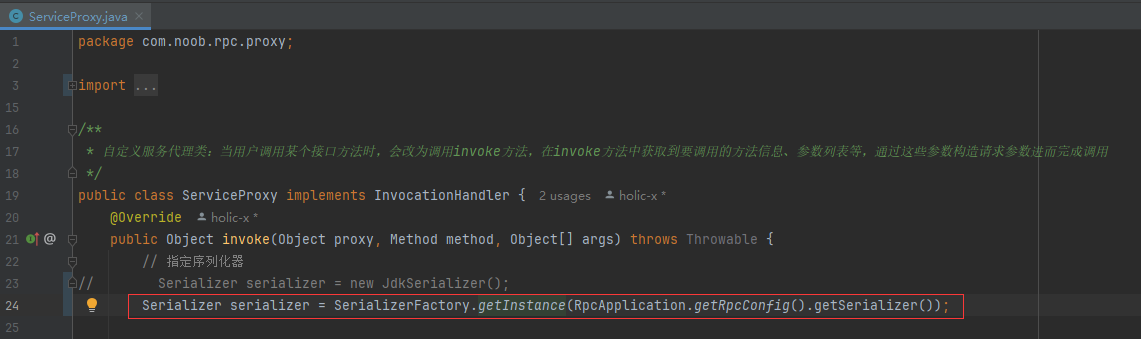
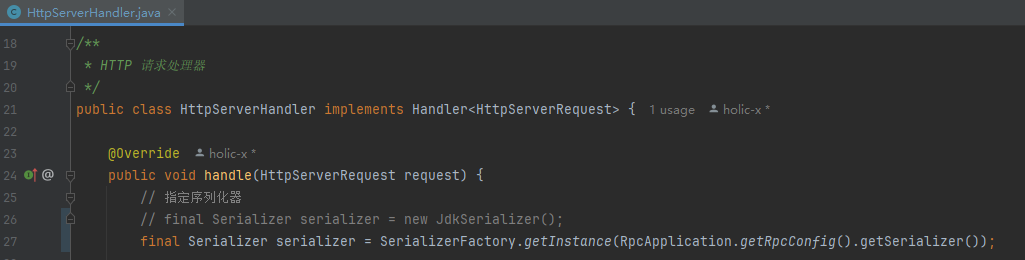
final Serializer serializer = SerializerFactory.getInstance(RpcApplication.getRpcConfig().getSerializer());
2.自定义序列化器
使用自定义的SPI机制实现,支持用户自定义序列化器并指定键名
(1)指定SPI配置目录
系统内置的SPI机制会加载resources 资源目录下的META-INF/services目录,那自定义的序列化器可以如法炮制,改为读取META-INF/rpc目录
还可以将SPI配置再分为系统内置SPI和用户自定义SPI,即目录如下:
用户自定义SPI:META-INF/rpc/custom。 用户可以在该目录下新建配置,加载自定义的实现类
系统内置SPI:META-INF/rpc/system。 RPC框架自带的实现类,比如之前开发好的JdkSerializer
基于这个配置概念,所有接口的实现类都可以通过SPI动态加载,不用在代码中硬编码Map来维护实现类。编写一个系统扩展配置文件,内容为之前写好的序列化器。
(2)编写SpiLoader加载器(可复用)
类似一个工具类,提供读取配置并加载实现类的方法,其构建核心步骤为:
- 用Map来存储已加载的配置信息键名=>实现类
- 扫描指定路径,读取每个配置文件,获取到键名=>实现类信息并存储在Map中。
- 定义获取实例方法,根据用户传入的接口和键名,从Map中找到对应的实现类,然后通过反射获取到实现类对象。可以维护一个对象实例缓存,创建过一次的对象从缓存中读取即可。
/**
* SPI 加载器
* 自定义实现,支持键值对映射
*/
@Slf4j
public class SpiLoader {
/**
* 存储已加载的类:接口名 =>(key => 实现类)
*/
private static final Map<String, Map<String, Class<?>>> loaderMap = new ConcurrentHashMap<>();
/**
* 对象实例缓存(避免重复 new),类路径 => 对象实例,单例模式
*/
private static final Map<String, Object> instanceCache = new ConcurrentHashMap<>();
/**
* 系统 SPI 目录
*/
private static final String RPC_SYSTEM_SPI_DIR = "META-INF/rpc/system/";
/**
* 用户自定义 SPI 目录
*/
private static final String RPC_CUSTOM_SPI_DIR = "META-INF/rpc/custom/";
/**
* 扫描路径
*/
private static final String[] SCAN_DIRS = new String[]{RPC_SYSTEM_SPI_DIR, RPC_CUSTOM_SPI_DIR};
/**
* 动态加载的类列表
*/
private static final List<Class<?>> LOAD_CLASS_LIST = Arrays.asList(Serializer.class);
/**
* 加载所有类型
*/
public static void loadAll() {
log.info("加载所有 SPI");
for (Class<?> aClass : LOAD_CLASS_LIST) {
load(aClass);
}
}
/**
* 获取某个接口的实例
*
* @param tClass
* @param key
* @param <T>
* @return
*/
public static <T> T getInstance(Class<?> tClass, String key) {
String tClassName = tClass.getName();
Map<String, Class<?>> keyClassMap = loaderMap.get(tClassName);
if (keyClassMap == null) {
throw new RuntimeException(String.format("SpiLoader 未加载 %s 类型", tClassName));
}
if (!keyClassMap.containsKey(key)) {
throw new RuntimeException(String.format("SpiLoader 的 %s 不存在 key=%s 的类型", tClassName, key));
}
// 获取到要加载的实现类型
Class<?> implClass = keyClassMap.get(key);
// 从实例缓存中加载指定类型的实例
String implClassName = implClass.getName();
if (!instanceCache.containsKey(implClassName)) {
try {
instanceCache.put(implClassName, implClass.newInstance());
} catch (InstantiationException | IllegalAccessException e) {
String errorMsg = String.format("%s 类实例化失败", implClassName);
throw new RuntimeException(errorMsg, e);
}
}
return (T) instanceCache.get(implClassName);
}
/**
* 加载某个类型
*
* @param loadClass
* @throws IOException
*/
public static Map<String, Class<?>> load(Class<?> loadClass) {
log.info("加载类型为 {} 的 SPI", loadClass.getName());
// 扫描路径,用户自定义的 SPI 优先级高于系统 SPI
Map<String, Class<?>> keyClassMap = new HashMap<>();
for (String scanDir : SCAN_DIRS) {
List<URL> resources = ResourceUtil.getResources(scanDir + loadClass.getName());
// 读取每个资源文件
for (URL resource : resources) {
try {
InputStreamReader inputStreamReader = new InputStreamReader(resource.openStream());
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
String[] strArray = line.split("=");
if (strArray.length > 1) {
String key = strArray[0];
String className = strArray[1];
keyClassMap.put(key, Class.forName(className));
}
}
} catch (Exception e) {
log.error("spi resource load error", e);
}
}
}
loaderMap.put(loadClass.getName(), keyClassMap);
return keyClassMap;
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
loadAll();
System.out.println(loaderMap);
Serializer serializer = getInstance(Serializer.class, "jdk");
System.out.println(serializer);
}
}
(3)重构序列化器工厂
使用静态代码块,在工厂首次加载时,就会调用SpiLoader的load方法加载序列化器接口的所有实现类,之后就可以通过调用getnstance方法获取指定的实现类对象。
/**
* 序列化器工厂(工厂模式,用于获取序列化器对象)
*/
public class SerializerFactory {
static {
SpiLoader.load(Serializer.class);
}
/**
* 默认序列化器
*/
private static final Serializer DEFAULT_SERIALIZER = new JdkSerializer();
/**
* 获取实例
*
* @param key
* @return
*/
public static Serializer getInstance(String key) {
return SpiLoader.getInstance(Serializer.class, key);
}
}
(4)测试
SPI加载测试
修改custom、system中的SPI配置文件,任意指定键名和实现类路径,验证是否可以正常加载。分别测试
- 分别测试正常(存在key)和异常(不存在key)的情况
- 测试key相同时,自定义配置能否覆盖系统配置
public static void main(String[] args) throws IOException, ClassNotFoundException {
loadAll();
System.out.println(loaderMap);
Serializer serializer = getInstance(Serializer.class, "jdk");
System.out.println(serializer);
}
完整测试
(1)修改消费者、生产者示例项目中的配置文件,指定不同的序列化器进行测试
rpc.serializer=hessian
(2)依次启动生产者、消费者,验证是否可以完成RPC请求和响应
(5)自定义序列化器
基于上述实现,如果后续想要实现自定义序列化器,只需要参考如下步骤:
- 编写自定义序列化器CustomSerializer实现Serializer接口
- 在custom目录下编写SPI配置文件,加载自己的实现类
- 在resource/application.properties配置可以设定为自定义的序列化器名称
扩展说明
(1)实现更多不同协议的序列化器
参考思路:由于序例化器是单例,要注意序列化器的线程安全性(比如Kryo列化库) ,可以使用ThreadLocal
(2)序列化器工厂可以使用懒加载(懒汉式单例)的方式创建序列化器实例
参考思路:目前是通过static静态代码块初始化的
(3)SPI Loader支持懒加载,获取实例时才加载对应的类
参考思路:可以使用双检索单例模式