【JFinal】③JFinal常见开发技巧
【JFinal】③JFinal常见开发技巧
[TOC]
JFinal常见开发技巧和思路
【1】JFina登录拦截验证
参考学习链接:https://blog.csdn.net/happyhfei/article/details/45249007
利用jfinal的缓存插件验证登录,以及空闲超时退出登录。未登录直接请求url将被跳转到登录页。
a.拦截器配置
说明:Interceptor 是全局共享的,所以如果要在其中使用属性需注意线程安全问题
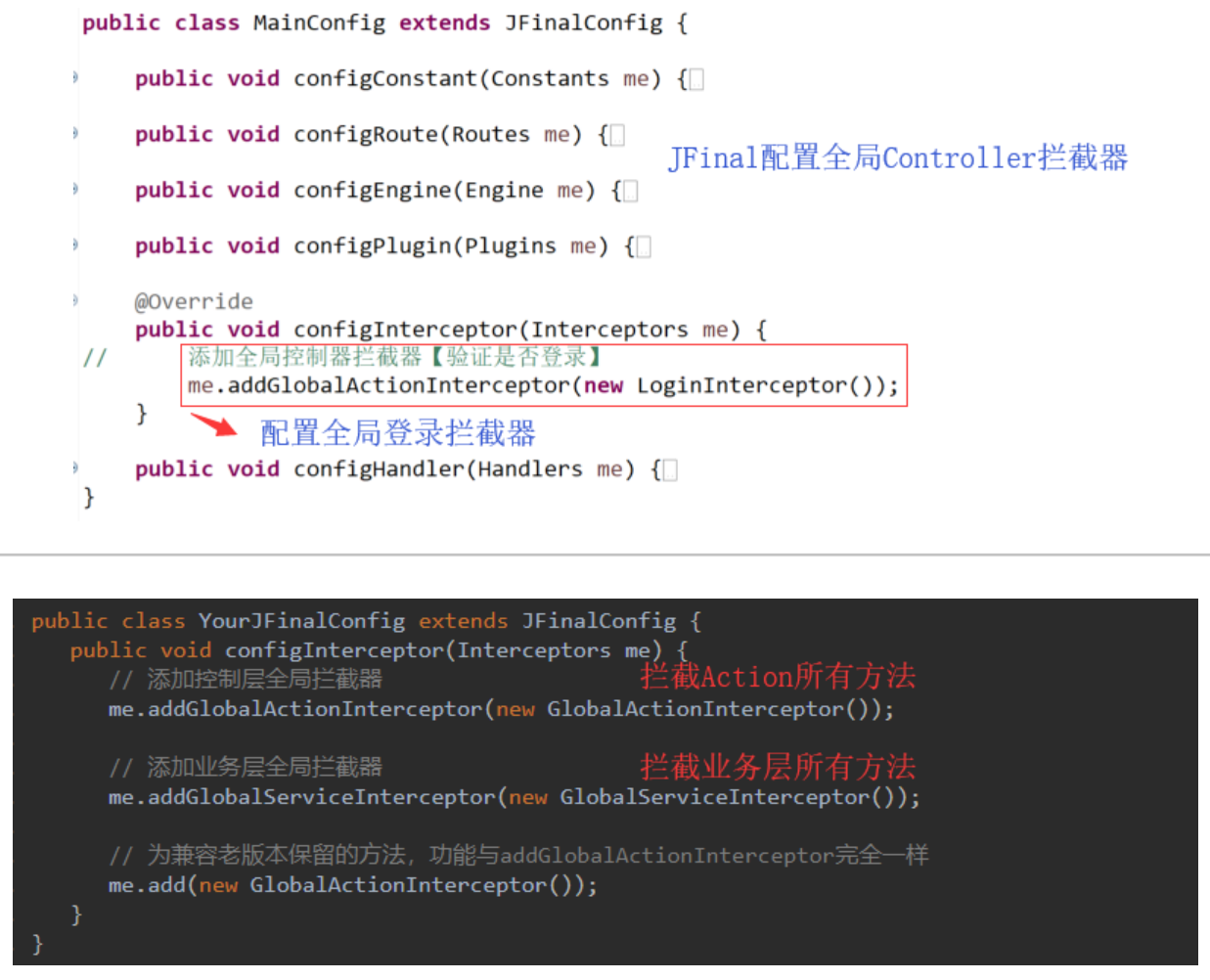
定义登录拦截器LoginInterceptor实现Interceptor(com.jfinal.aop. Interceptor),实现intercept方法,对所有访问接口进行拦截
JFinal配置全局拦截器(在MainConfig的configInterceptor方法中进行配置)
定义权限拦截器AdminInterceptor,对指定的Contoller或者是指定Contoller中的某个接口方法进行拦截(常用注解@Before、@Clear)
Before注解用来对拦截器进行配置,该注解可配置Class、Method级别的拦截器
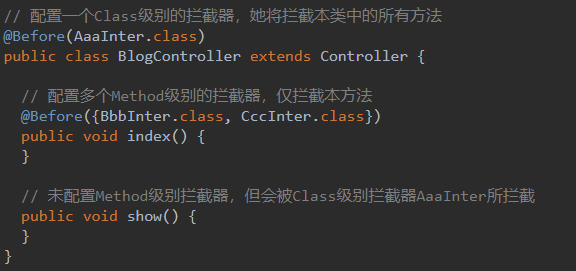
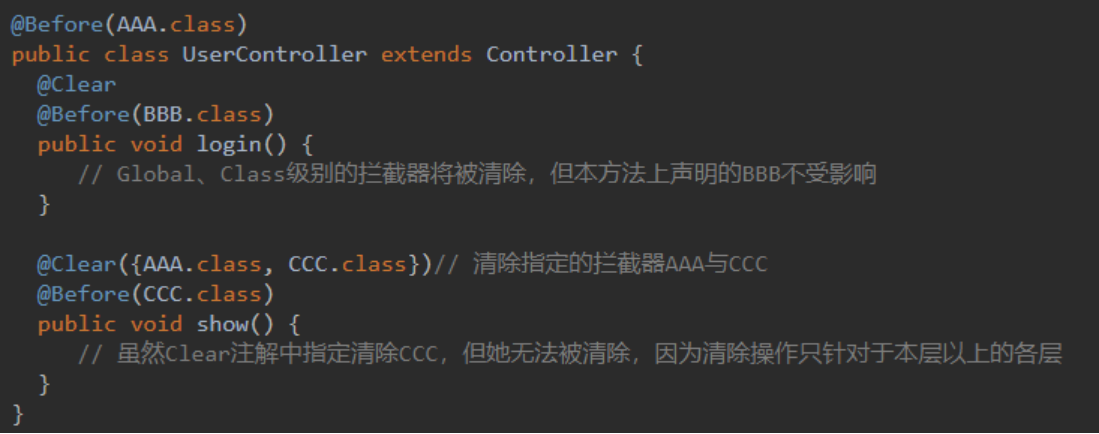
Clear用于清除自身所处层次以上层的拦截器,拦截器从上到下依次分为Global、Routes、Class、Method四个层次,Clear清除拦截器有一定规则需注意:
- 一共有Global、Routes、Class、Method 四层拦截器
- 清除只针对Clear本身所处层的向上所有层,本层与下层不清除
- 不带参数时清除所有拦截器,带参时清除参数指定的拦截器
应用场景:配置权限拦截器,但登录action需要清除该拦截器
b.前后端验证处理
针对用户登录
思路1:拦截器登录用户验证处理,跳转到登录页面

思路2:Controller方法(接口)验证处理,前端验证接口返回参数并作相应处理
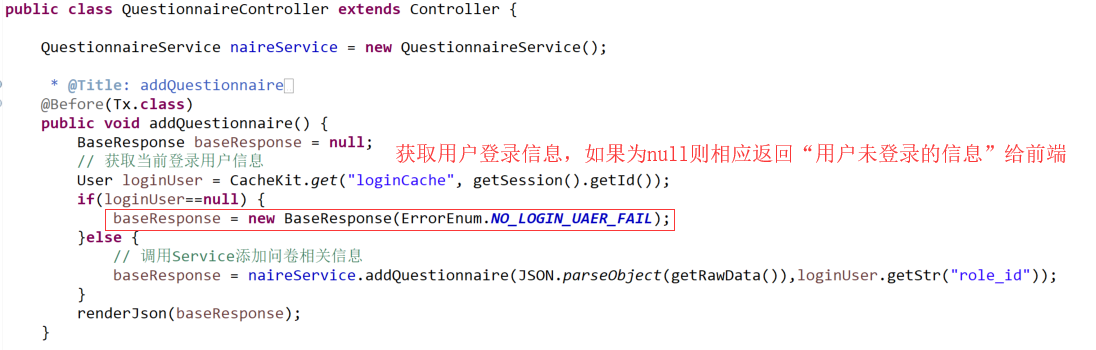
登录权限拦截验证主要针对指定的Class、Method进行拦截,针对特定的功能,当用户请求Controller接口需要进行相应的权限拦截验证,验证通过则放行,否则返回提示给前端。但针对公共的接口需要注意权限管理的范围,需要借助Clear注解进行处理
c.前后端处理参考思路
配置处理:全局拦截器配置、ehcache缓存配置
引入ehache相关jar:

参考配置代码如下:
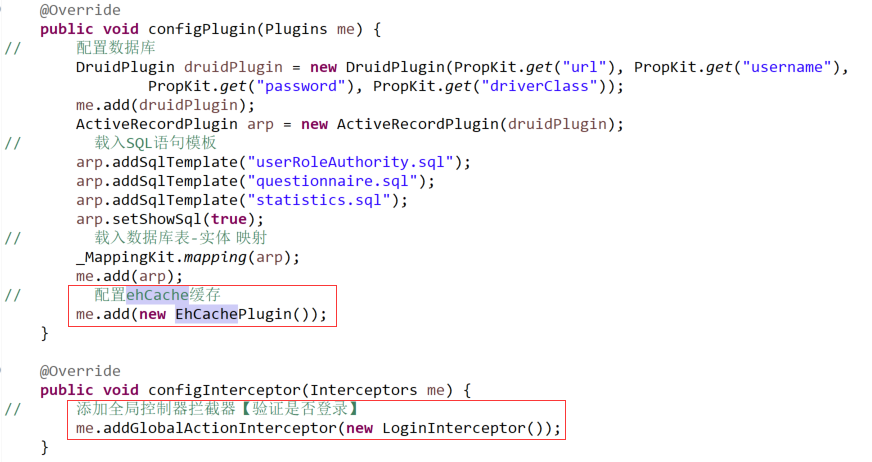
将指定“ehcache.xml”配置文件放置在“src/main/resources”文件夹下
拦截器处理:
对所有请求(除却登录或其他特殊访问接口)进行拦截,予以放行。根据sessionid获得cache中存储的user对象,如果为空表示未登录,或登录超时cache清空。需要重新登录,跳转到登录页。(需要在MainConfig中配置全局拦截器)。参考代码如下:
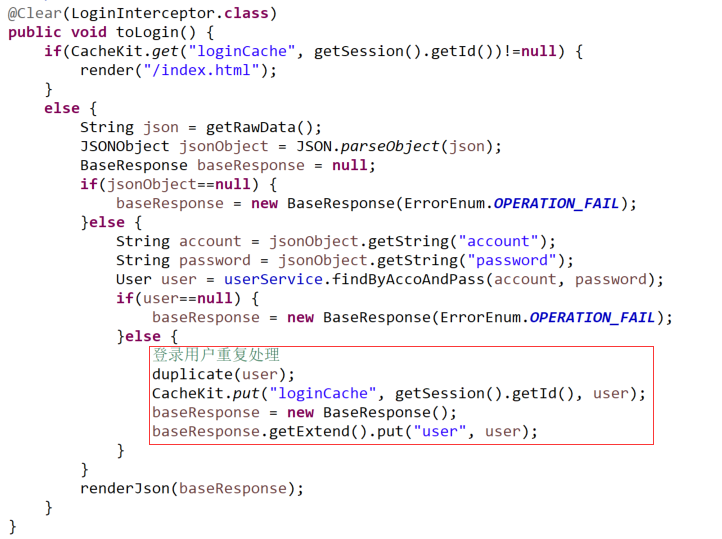

Controller层:
验证登录用户信息,登录成功后保存user对象到缓存,作为以后判断的依据。注意要用session的id作为缓存的key,确保区分不同终端的请求。参考代码如下:

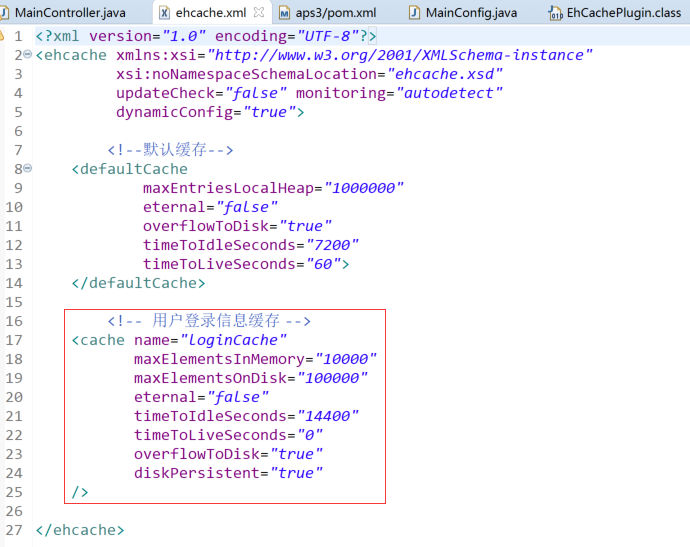
缓存配置文件处理:在src目录下编辑ehcache-shiro.xml文件,
<ehcache>区块中增加如下内容:
<cache name="LoginUserCache"
maxElementsInMemory="10000"
overflowToDisk="false" //数量过大是否保存至磁盘
eternal="false" //是否永久保留
timeToLiveSeconds="6000" //存在时长
timeToIdleSeconds="60"/> //空闲保留时长(60s即为登录空闲超时时长)
d.ehcache缓存机制分析
Ehcache是一个快速的、轻量级的、易于使用的、进程内的缓存。它支持read-only和read/write 缓存,内存和磁盘缓存,是一个非常轻量级的缓存实现,并从1.2之后就支持了集群。其具备如下特点:
快速、简单
多种缓存策略
缓存数据有两级:内存和磁盘,因此无需担心容量问题
缓存数据会在虚拟机重启的过程中写入磁盘
可以通过RMI、可插入API 等方式进行分布式缓存
具有缓存和缓存管理器的侦听接口
支持多缓存管理器实例,以及一个实例的多个缓存区域
提供Hibernate的缓存实现
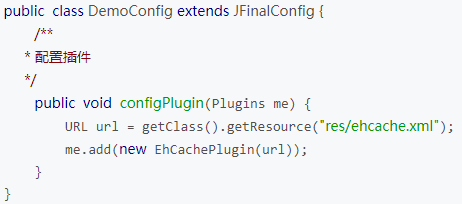
(1)EhCachePlugin
JFinal 已经集成了ehcache缓存,以plugin形式存在,叫“EhCachePlugin”。需要在项目的DemoConfig.java中配置后才能使用:
com.jfinal.plugin.ehcache.EhCachePlugin继承了com.jfinal.plugin.IPlugin接口;在EhCachePlugin中主要是生成cacheManager,并将cacheManager放在CacheKit 中:
在EhCachePlugin中有多个构造函数,都是传递不同类型的ehcache配置文件参数或直接传递CacheManager进行初始化操作

每个Plugin都会有start方法,在项目启动时执行。 EhCachePlugin 在start方法中调用createCacheManager()方法,创建CacheManager;并将CacheManager放在CacheKit中【CacheKit.init(cacheManager)】

(2)CacheKit
com.jfinal.plugin.ehcache.CacheKit是ehcache缓存的操作工具类,在EhCachePlugin中,已经将cacheManager放在CacheKit 中(给CacheKit的cacheManager参数赋值),因此可在项目中通过CacheKit,来使用ehcache缓存技术,参考如下:
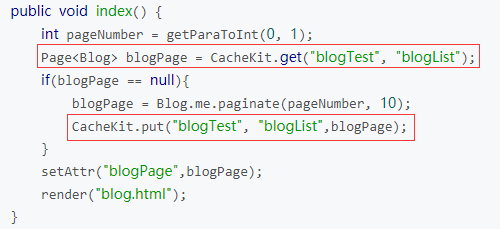
CacheKit 中最重要的两个方法是get(String cacheName, Objectkey)与put(String cacheName,Object key, Object value)。get 方法是从cache中取数据,put方法是将数据放入cache。参数cacheName与ehcache.xml中的<cache name="blogTest" …>name属性值对应; 参数key是指取值用到的key;参数 value 是被缓存的数据。对应上例的ehcache.xml配置如下:

除了以上介绍的get(String cacheName, Objectkey)方法外,CacheKit还提供了CacheKit.get(String, String, IDataLoader)方法,使用方式如下:
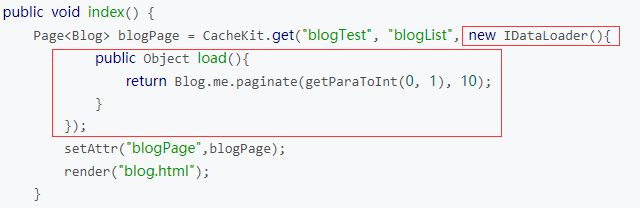
CacheKit.get方法提供了IDataLoader接口,该接口中的load()方法在缓存值不存在时才会被调用。该方法的具体操作流程是:首先以 cacheName=blogTest 以及 key=blogList 为参数去缓存取数据,如果缓存中数据存在就直接返回该数据,不存在则调用 IDataLoader.load()方法来获取数据,并将获取到的数据通过put(cacheName, key, data)放在cache中。
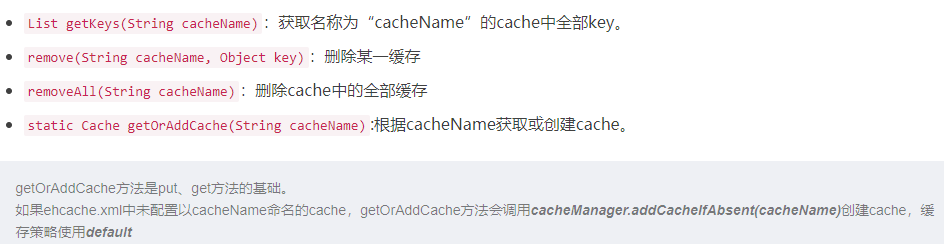
CacheKit中的其他方法:
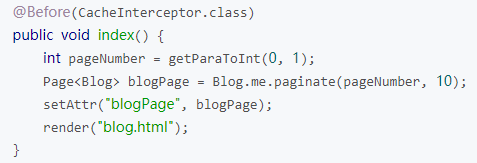
除了工具类外,还可以通过配置拦截器的方式使用ehcache缓存。
CacheInterceptor可以将 action 所需数据全部缓存起来,下次请求到来时如果cache存在则直接使用数据并render,而不会去调用action。此用法可使 action 完全不受 cache 相关代码所污染,即插即用,以下是示例代码:
且可观察运行日志,在第一次访问的时候缓存中没有值因此从数据库中获取并打印sql语句,第二次访问的时候会从缓存中取值并调用
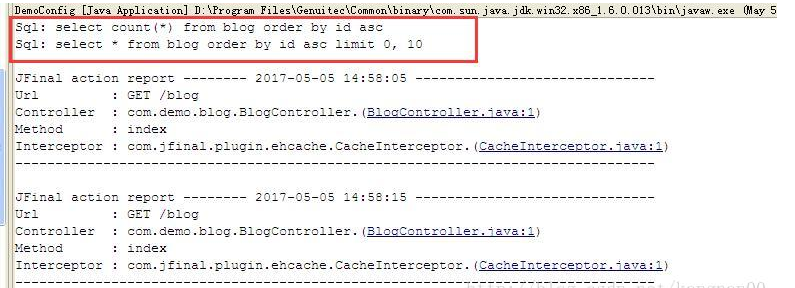
上例中的用法将使用 actionKey作为cacheName(使用具体的url(actionKey+参数)作为cacheKey),在使用之前需要在 ehcache.xml中配置以actionKey命名的cache 如:<cache name="/blog" …>,注意 actionKey 作为cacheName配置时斜杠”/”不能省略(如果没有在ehcache.xml配置对应的cache,系统会使用default,详见CacheKit的getOrAddCache方法)。此外CacheInterceptor 还可以与CacheName注解配合使用,以此来取代默认的 actionKey 作为 cacheName,以下是示例代码:
以上用法需要在ehcache.xml中配置名为bloglist的cache如:<cache name="bloglist" …>
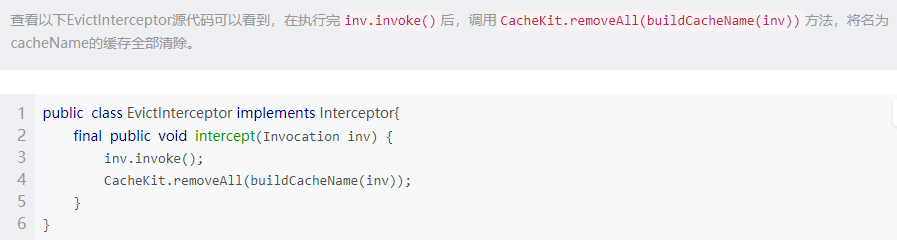
(3)EvictInterceptor
EvictInterceptor 可以根据 CacheName 注解自动清除缓存。以下是示例代码:
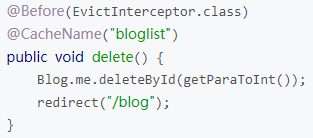
上例中的用法将清除 cacheName 为 blogList 的缓存数据,与其配合的CacheInterceptor 会自动更新 cacheName 为 blogList 的缓存数据。
【2】文件上传、下载
a.文件上传相关:getFile系列方法
(1)文件上传路径问题
此处申请记录相关的附件信息在保存基本的记录时一并存储上传文件指定的保存路径
并在查看文件的时候由按钮触发根据指定路径查找
JFinal文件上传默认在服务器发布路径创建upload目录,如果需要自定义目录
getFile系列的方法,如果saveDirectory 参数以 "/" 或者以 "x:" 打头的话就会将文件保存为磁盘系统的绝对路径,否则会保存到项目中的 upload 下面。如果不想让文件保存在 upload下面,可以在 YourJFinalConfig.configConstant(Constants me)方法中使用:
// me.setUploadedFileSaveDirectory(String)改变默认的文件保存基路径

设置变量savePath的根路径:me.setBaseUploadPath("/");,随后可在getFile系列方法中使用D:/xxx这种形式的根路径,从而实现自定义文件上传路径
针对linux系统,则可使用“/a/b/c”,在有权限的情况下,能够将文件存储到指定的路径;但“/a/b/c”针对window系统则无效,如果window下要使用相对路径则设置上传路径为相对路径“.”或“./”,即:me.setBaseUploadPath(".")或me.setBaseUploadPath("./")
getFile(参数名称,指定存储路径,上传文件限制大小,指定编码格式);
调用getFile系列方法随即则将指定文件存储到指定路径,并返回一个UploadFile对象用以判断文件是否正常上传及获取上传文件的相关属性

必须对返回的对象uploadFile进行null判断,如果为null则可能是上传的文件为空或上传过程中出错,需要做出相应处理。当uploadFile不为null时,则可借助uploadFile.getFile()获取到已上传的文件对象,从而获取相应的文件属性进行数据库相关操作

重点关注的是:“必须先调用getFile系列方法,才能正常获取其他的数据(先调用getFile系列方法后使用其他get系列方法,否则获取的数据为null)”,如果在文件上传的相关交互中需要传入其他参数,则必须统一传入“multipart/form-data”格式的数据,因此后台在正常处理的时候则相应用“get(String str)”方法获取参数值

(2)文件上传限制
getFile方法是直接执行文件上传操作,如果需要限制上传文件并在后台获取到明确的错误信息,则考虑借助拦截器实现,参考方法:把JFinal的上传大小限制调高,然后自定义一个附件大小验证的Interceptor,在Interceptor里定义实际要限制的附件大小或其他属性,若文件验证通过则放行,否则返回具体的错误信息
(3)JFinal文件上传实现与测试
如果要调用getFile系列方法实现文件上传,则其相应上传的数据格式必须指定为“multipart/form-data”,因此此处说明两种方式将数据封装成form-data格式
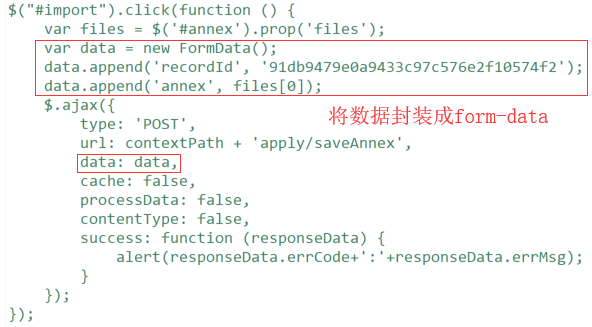
方式1:ajax方式封装提交
html参考:

预览图片信息参考:

js数据封装并交互参考:
方式2:表单方式封装提交

文件上传测试:(POSTMAN)需勾选数据默认上传,否则未勾选数据不会发送
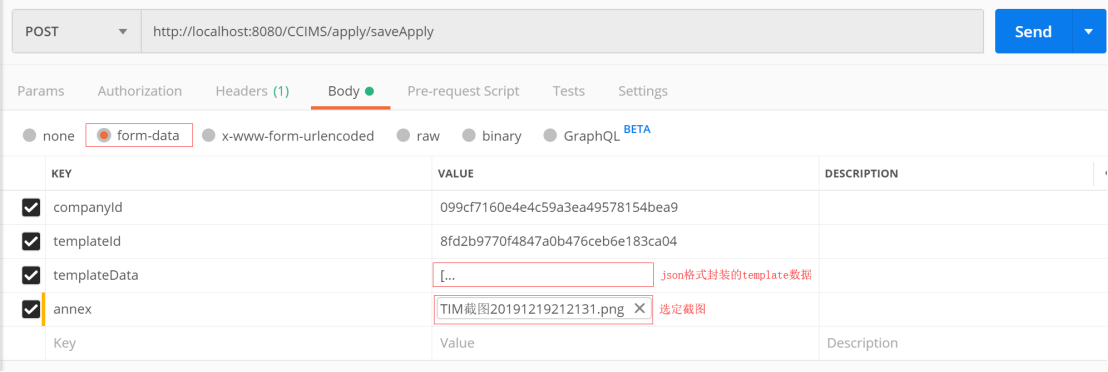
由于文件上传的时候需要和其他的申请记录信息一并保存,考虑到为统一前端代码编写风格,如果将所有数据封装调整成表单形式则工作量巨大,因此此处调整则参考方式1的形式,将要提交的数据统一封装成json格式,随后在js代码中定义一个FormData对象,将所有数据进行打包再传输,从而简化前端代码调整量,参考前端js代码如下:

多文件上传(简单说明):
form的enctype必须是multipart/form-data才可以上传多个文件,ajax通过FormData来上传数据,ajax的cache、processData、contentType均要设置为false。
cache设为false是为了兼容ie8,防止ie8之前版本缓存get请求的处理方式
contentType设置为false原因:https://segmentfault.com/a/1190000007207128
processData:要求为Boolean类型的参数,默认为true。默认情况下,发送的数据将被转换为对象(从技术角度来讲并非字符串)以配合默认内容类型"application/x-www-form-urlencoded"。如果要发送DOM树信息或者其他不希望转换的信息则设置为false
(4)文件上传常见问题
文件上传测试遇到的问题:自定义InputStream与JFinal内置getFile系列方法冲突
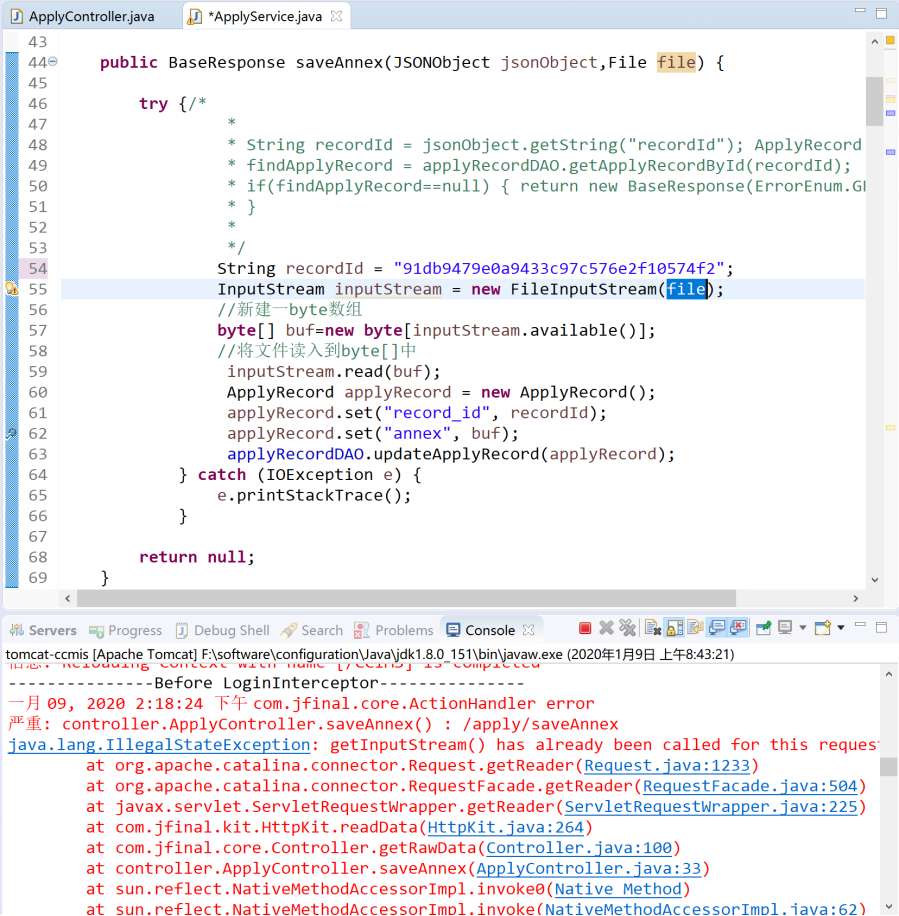
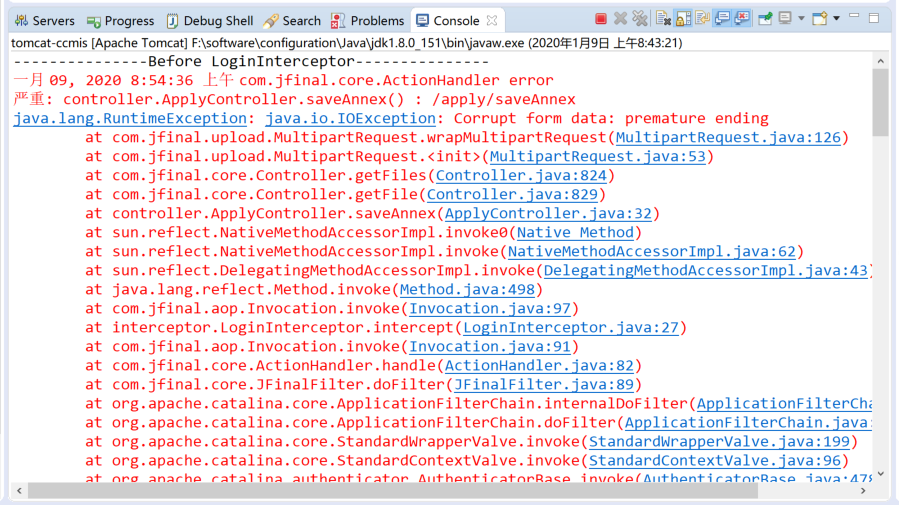
后台数据处理格式限定:
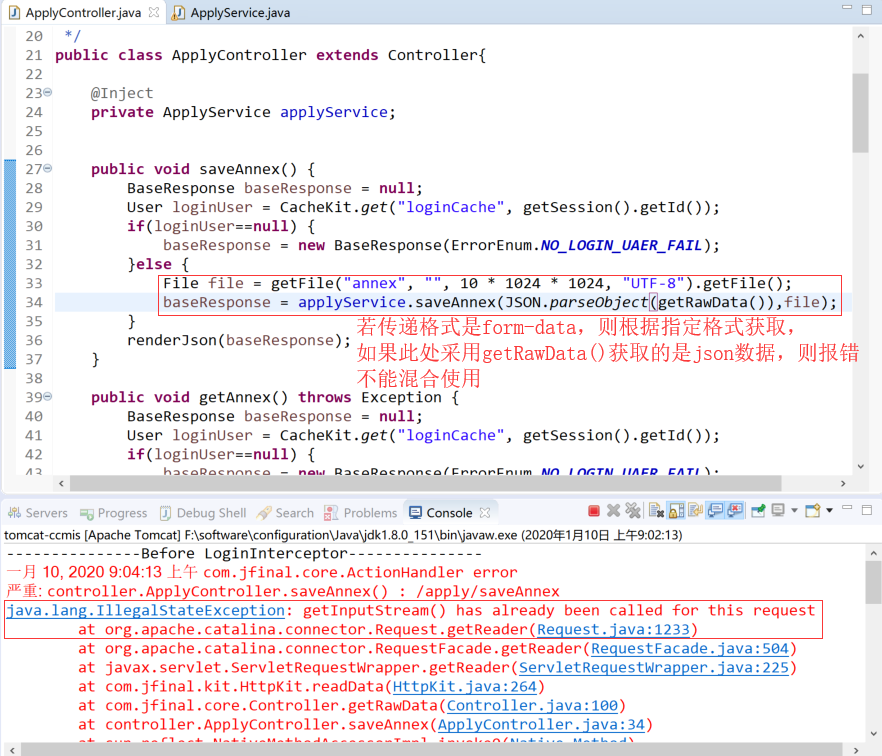
实际业务处理:
每次调用getFile方法,会将当前指定文件上传到指定路径,因此需要考虑实际业务需求和文件存储问题,文件存储按照一定规则限定,不定时清理文件服务器内容
且如果用户重复上传数据,需要将原有的记录删除随后更新数据,以免用户重复更换附件造成文件服务器数据冗余;此外还需出来空文件上传问题(后台做相应空指针异常处理)
(5)JFinal图片数据渲染
考虑问题:Jfinal如何通过io直接将图片显示在页面上?
参考方案:可考虑参考 FileRender 做一个 PictureRender,随后仿照调用方法 render(new PictureRender(图片文件参数)); 在参考 FileRender 时,主要参考 normalRender() 方法里头如何向客户端发送数据。相对于 FileRender,只是向客户端发送图片数据,而不是文件下载,因此要去掉里头的 response.setHeader("Content-disposition"...)(设置文件下载的语句)。随后参考设置好正确的图片文件的 content type
前端图片预览:https://www.ucloud.cn/yun/87248.html
(6)第三方插件实现文件上传
参考链接:https://www.cnblogs.com/chenjy1225/p/9661987.html
uploadify插件:http://www.uploadify.com/
JFinal文件上传参考链接:https://www.jianshu.com/p/d34ce7a10a29
JFinal文件上传、下载、删除、修改文件名:https://www.jianshu.com/p/d34ce7a10a29
前端图片上传及预览(多个文件):https://cloud.tencent.com/developer/article/1446436
b.文件下载相关:renderFile
(1)JFinal文件下载实现与测试
Controller层实现参考:
可能出现的问题:在获取图片或者文件信息的时候,如果使用BufferedInputStream相关处理输出流,然后用renderText返回数据,则后台报错。类似输出流被占用,然后又用renderXXX系列方法操作数据导致出错,直接用render(new FileRender(file))替代输出流操作处理


html参考:

js数据封装并交互参考:

文件下载测试:
填充相应的链接和数据recordId值,点击send可获取返回的数据,由于jfinal提供的renderFile能实现文件下载,不需要额外
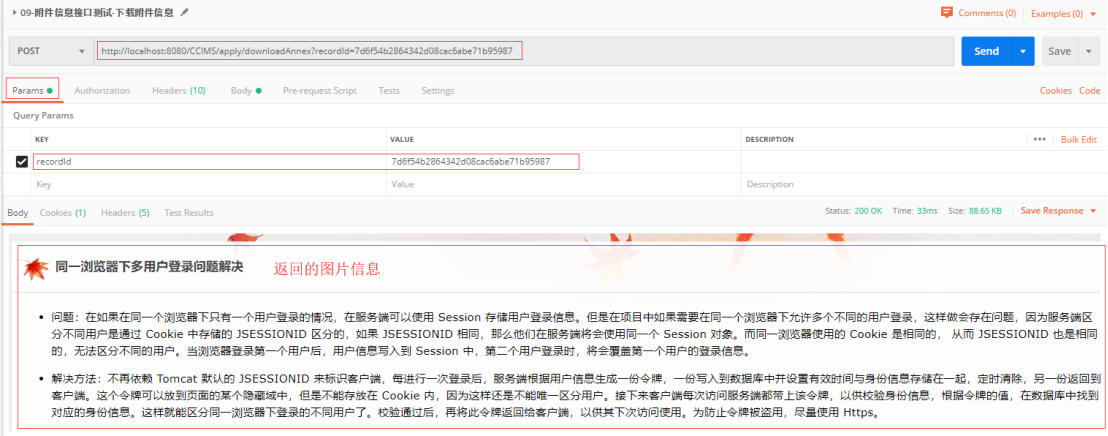
在测试的时候如果直接点击Send,返回的非图片文件难以兼容postman编辑器,则可能出现乱码的情况(如下所示)
则可点击Send按钮右侧的下拉箭头,选择Send and Download,直接将返回的结果保存,从而验证文件下载的正确性

JFinal框架的renderFile文件下载方法并不是对所有的浏览器都能有效兼容(ie浏览器),且可能出现jetty服务器的io流异常:com.jfinal.render.RenderException、org.eclipse.jetty.io.EofException,虽然前台下载文件没问题,但后台却总会报错,所以在项目中需谨慎使用框架自带的下载方法,考虑参考其他方式实现,多检测尝试、查缺补漏
(2)自定义方法实现Excel文件下载

原有实现方式先生成一个file,随后借助JFinal提供的renderFile系列方法下载指定文件,但从长期考虑需要及时清理临时生成的文件。不借助JFinal提供的renderFile系列方法,使用自定义方法实现Excel文件下载:

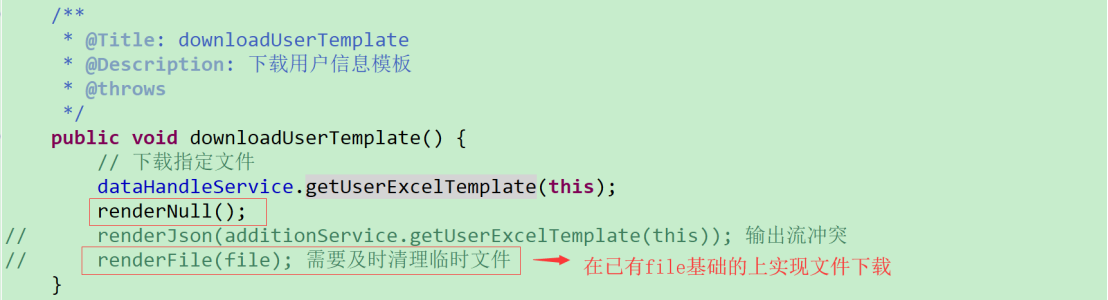
可能遇到的问题:在关闭输出流之后文件正常下载但后台还是报错:getOutputStream() has already been called for this response
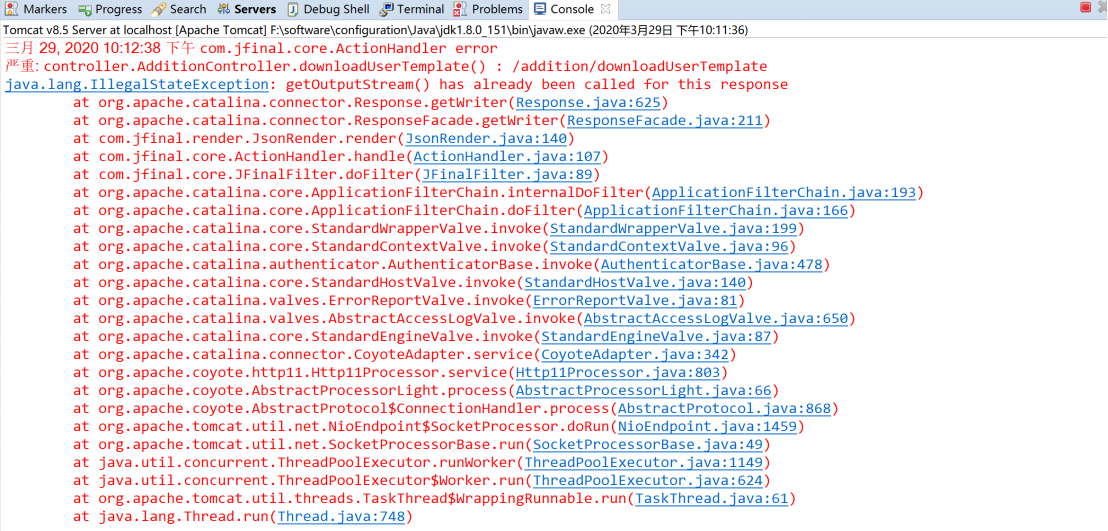
在自定义输出流实现下载文件后,需要与renderNull方法结合使用。如果调用renderJson方法则报上述错误。
【3】数据批量处理操作
JFianl提供了Db系列的批量操作方法,可根据实际不同的需求进行调用
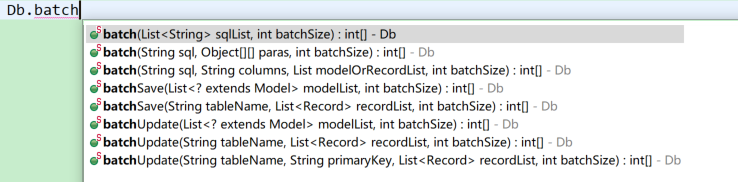
a.批量操作方法介绍
(1)batch系列方法
int[] batch(List<String> sqlList, int batchSize)
说明:
sqlList:封装好的sql语句列表(一般通过拼接参数实现封装)
batchSize:是指多少条数据写一次数据库(与下述batchSize含义一致)
int[] batch(String sql, Object[][] paras, int batchSize)
说明:
sql:预处理(预编译)sql语句(通过占位符‘?’暂替参数)
paras: 以二维数组的形式存储对应参数的值,数组的元素顺序与对应占位符所代表的参数含义要保持一致,避免出现参数混乱的情况
举例:
Db.batch("insert into account(name, cash) values(?, ?)",
new Object[][]{{"James", 888}, {"zhanjin", 888}}, 1000)
int[] batch(String sql, String columns, List modelOrRecordList, int batchSize)
说明:
sql:预处理(预编译)sql语句(通过占位符‘?’暂替参数)
columns:是指预编译sql 中问号占位的地方的参数名称,jfinal 在填充字段值的时候会根据这个名称去 modelOrRecordList 中去取数据,columns字符串中出现的参数顺序需与占位符对应参数含义保持一致
modelOrRecordList:封装的数据列表
举例:
String sql = "update check_record set is_do = ?, questionnaire_id = ?,modify_time=? where appraise_object_id = ?";
int[] result = Db.batch(sql, "isDo,questionnaireId,modifyTime,appraiseObjectId", recordList, batchSize);
此处recordList中的每个对象据相应包含isDo,questionnaireId,modifyTime,appraiseObjectId等相关字段
(2)batchSave系列方法、batchUpdate系列方法
int[] batchSave(List<? extends Model> modelList, int batchSize)
int[] batchUpdate(List<? extends Model> modelList, int batchSize)
说明:
modelList:对应实体类列表数据,与数据库字段一一对应
int[] batchSave(String tableName, List<Record> recordList, int batchSize)
int[] batchUpdate(String tableName, List<Record> recordList, int batchSize)
说明:
tableName:要执行操作的表名
recordList:由于Record是作为数据的载体,是一个通用的对象,其属性的定义与实际调用set方法设定的参数相关。Record作为通用数据载体,能够映射任意对象、任意实体,因此在使用Record对象作为数据载体操作时,需要明确指定表名,以映射指定对象。
除此之外,在没有配置数据库字段“驼峰”映射的情况下,需要确认字段属性是否和数据库中的定义保持一致
int[] batchUpdate(String tableName, String primaryKey, List<Record> recordList, int batchSize)
说明:
tableName、recordList、batchSize属性定义和上述内容基本一致
primaryKey:约定操作的主键名称
b.批量操作常见问题说明
(1)batch操作batchSize设定问题
(2)batch操作返回结果
batch批量操作返回结果说明:根据不同的数据库配置,jfinal批量操作返回的结果可能有所不同。在目前的项目测试中存在如下情况
在mysql中执行:正常执行返回数组,数组中的元素全为1
在oracle中执行:正常执行返回数组,数组中的元素全为-2
针对批量操作结果验证的问题,数组返回的结果针对的是受影响行数,一般是0或者1。Oracle之所以出现‘-2’的情况考虑是oracle对executeBatch并不完全支持,亦或是所使用的的oracle驱动和所访问的oracle版本不兼容所致。如果需要验证DB操作的有效性,判断数据是否操作成功,可参考如下思路:
方式1:循环遍历验证数组元素是否为正常执行后返回的标识
方式2:一般数据操作失败会抛出指定异常,因此可考虑借助try...catch...语句捕获异常抛出异常提示
(3)batchSave或batchUpdate操作出现数据丢失(属性丢失)的情况
batch操作出现数据丢失(属性丢失)的情况:
分析JFinal源码可知,以batchSave(String tableName, List<Record> recordList, int batchSize)为例进行说明:该方法是先从指定的recordList中获取第一条数据record作为参考,随后将record中所包含的属性封装成一个字符串数据(属性列表字符串),完成之后再次调用原始方法batch(String sql, String columns, List modelOrRecordList, int batchSize)执行批量操作。
因此也就验证了当指定的recordList中每个对象属性不完全一致的时候,调用上述的batchSave方法时,操作后的属性设定均以后台拿到的recordList中的第一个record对象的属性为准,如果该record的属性设定较少,后续的record对象若增加了某些指定属性,则在执行的时候就会出现后面的记录中部分属性值数据丢失的情况 。
此外,针对每个sql不一样的情况,建议使用int[] batch(List<String> sqlList, int batchSize)

为了解决上述情况,考虑直接调用原始方法batch(String sql, String columns, List modelOrRecordList, int batchSize)执行批量操作,可自定义columns属性(封装涵盖所需操作的所有属性的字符串列表),以确保数据库操作的字段的完成性,避免属性丢失的情况。
使用oracle保存数据的时候出现无效的索引问题?执行插入操作的时候“无效索引”,考虑是引用了数据库中不存在的字段导致,查看源码分析
【4】JFinal数据库事务处理
分析涵盖范围?处理机制?
【5】JFinal定时任务
a.需求分析
通过简单案例说明JFinal定时任务的配置和使用
需求说明:考虑linux服务器存储容量限制,需要对文件上传限定最大存储容量,避免文件过多造成数据冗余。因此设定定时任务,每个一段时间清理一次文件数据,并限定清理条件:只有当指定存储路径的文件数据超出限定的最大容量方执行清理操作(默认清理举例当前日期最远7天的文件夹数据,且文件已根据指定规则以日期为单位进行存储,例‘2020-01-01’)
定时器任务设定步骤说明:
《1》在pom.xml中引入相关jar(jfinal-quartz或者是cron4j)
《2》创建定时任务相关class,编写定时任务相关方法
《3》引入定时任务相关的配置文件
《4》在JFinal的核心配置文件中加载定时器插件
参考学习链接:
QuartzPlugin:https://www.cnblogs.com/jinTaylor/p/4551879.html
Cron4j:https://blog.csdn.net/qq_35733535/article/details/79131683
动态配置多任务定时器:http://www.jfinal.com/share/15
b.开发步骤说明(此处cron4j为例进行说明)
(1)在pom.xml中引入相关jar

(2)创建定时任务相关class,编写定时任务相关方法
方式1:定义XXXClass实现Runnable接口,重写run方法
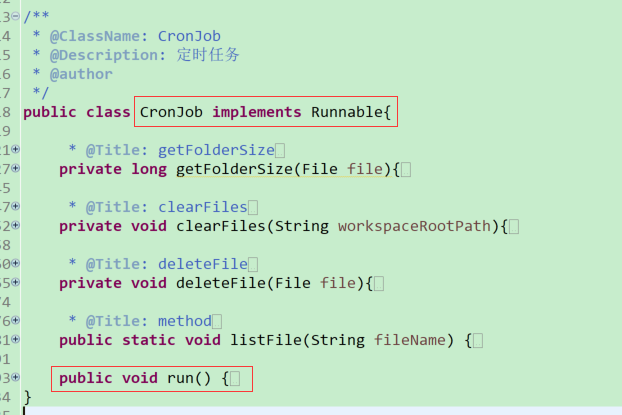
此外还有许多实现方法(例如使用ITask接口的实现类等),下属内容以实现Runnable接口的基础上进行说明
根据上述需求说明,简单编写了定时任务:针对一些基础的属性均设置为配置项,如:指定文件上传的存储路径、限定存储容量大小、清理周期等

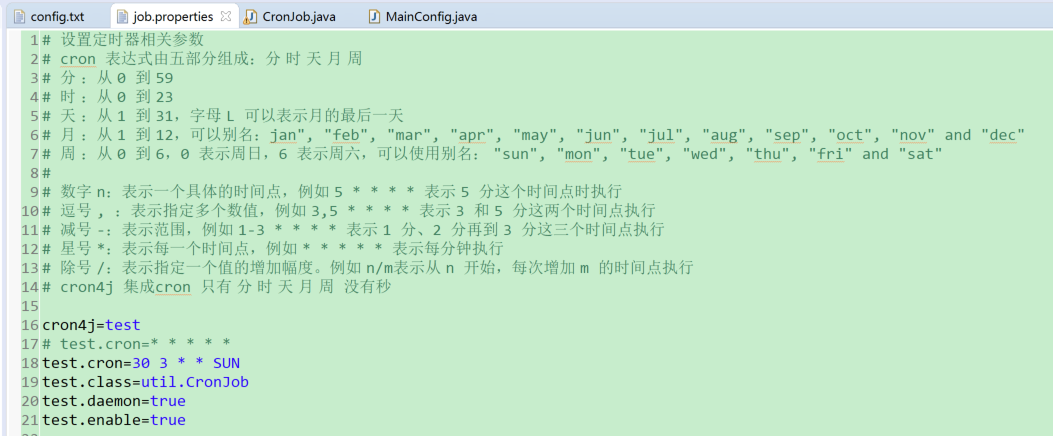
(3)引入定时任务相关的配置文件
此处在resource中创建配置文件,配置好相关参数:
cron4j= jobName (自定义定时任务名称)
jobName.cron: cron表达式(用于设定定时器执行的周期),具体可参考jfinal官方文档
jobName.class:定时器任务所在类路径(包名(包含路径).类名)即要调度的目标java类
jobName.daemon:被调度的任务线程是否为守护线程(了解守护线程相关概念)
jobName.enable:定时器是否开启(默认为开启状态)
在线cron表达式工具箱:http://www.toolzl.com/tools/croncreate.html
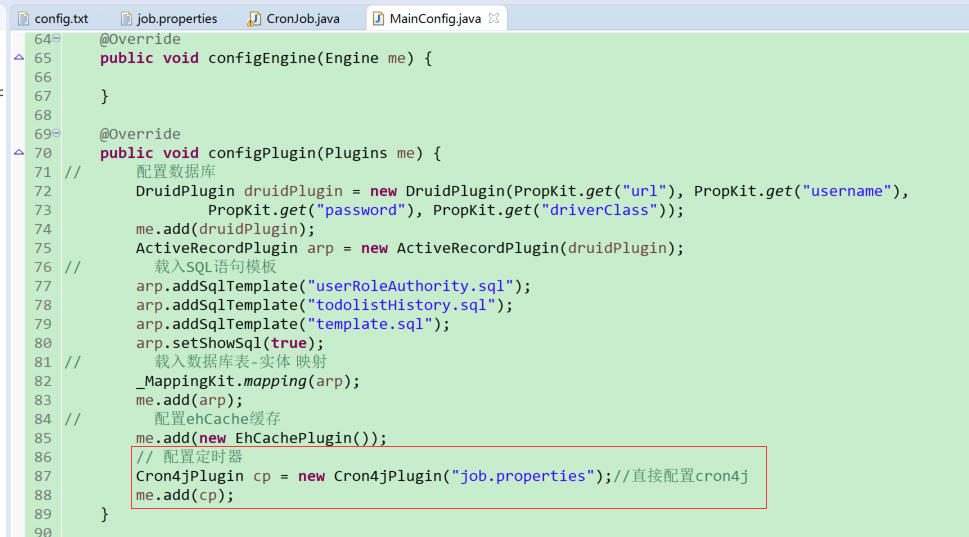
(4)在JFinal的核心配置文件中加载定时器插件
在主配置文件中引入cron4j相关配置文件并加载Cron4jPlugin插件
c.扩展:多定时任务、外部配置
configName(configName为示例中配置项 cron4j=task1, task2 中的 "cron4j",configName相当于就是Cron4jPlugin寻找的配置入口)指定taskName,多个taskName可以逗号分隔,而每个taskName指定具体的task,每个具体的task有四项配置:cron、class、deamon、enable,每个配置以taskName打头
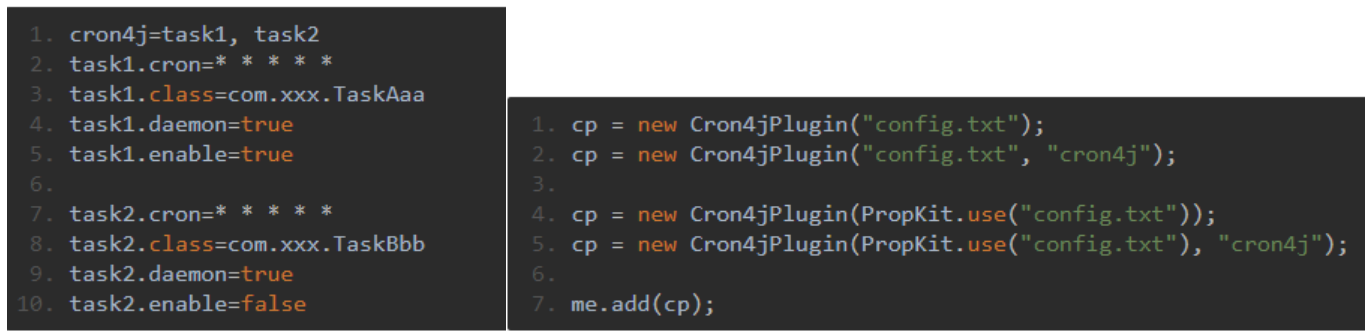
以上代码中,前四行代码是利用配置文件创建Cron4jPlugin对象的四种方式,其区别在于是否用PropKit指定加载某个配置文件、是否指定了configName,如果没有指定configName则默认为“cron4j”
d.常见定时器开发问题
定时任务的每次调度都是独立的,上次调度是否抛出异常、是否执行完,都与本次调度无关
(1)定时任务启动无效
配置文件失效或者是配置不成功原因、或者是定时任务不触发操作可参考下述方法:
排查1:cron表达式配置存在问题
参考jfinal官网说明:
cron 表达式用于定制调度规则。与 quartz 的 cron 表达式不同,Cron4jPlugin 的 cron 表达式最多只允许五部分,每部分用空格分隔开来,这五部分从左到右依次表示分、时、天、月、周。(与网络流传的7部分表达式定义规则有所差异)
cron4j在表达式中使用除号指定增加幅度时与linux稍有不同。例如在linux中表达式 10/3 * * * * 的含义是从第10分钟开始,每隔三分钟调度一次,而在cron4j中需要使用 10-59/3 * * * * 来表达。避免这个常见错误的技巧是:当需要使用除号指定增加幅度时,始终指定其范围。基于上面的技巧,每隔2分钟调度一次的表达式为:0-59/2 * * * * 或者 */2 * * * * , 而不能是0/2 * * * *
排查2:配置文件未及时更新到发布路径
可设置cron表达式为错误的表达式,如果配置文件正常更新则系统在启动的时候会抛出校验表达式出错的异常,反之说明配置文件未正常更新。如果配置文件未正常更新,可用maven更新项目
排查3:检查properties配置文件是否包含空格属性
由于此处配置文件设定后缀为properties,在编写配置文件的时候极有可能出现空格的情况,由于properties文件出现了key或者value值前后含有空格的情况,导致实际读取的配置数据有所差异,系统启动不报错,但定时任务迟迟未响应,从而导致出错。
可借助相关方法去除空格带来的影响,也建议使用xxx.txt类型文件保存配置数据,避免‘空格’带来不必要的影响
(2)测试定时任务有效性时,修改系统时间后,定时任务并未按照预期执行
问题描述:
以启动系统时间为准,如果在系统启动后修改系统时间,定时任务失效
如果在系统启动前先修改好系统时间,随后再次启动可以看到定时任务被触发,但是之后再修改系统时间,定时任务是无法被触发的,可能和程序内部运行机制相关
定时任务大概分三类:
java自带的Timer+TimerTask
基于注解式的实现 @Scheduled(…)
定时任务框架 如quartz 、cron4j
定时任务执行时间的配置有两种,分别为cron表达式(绝对时间)、fixedRate(相对时间)
cron表达式中会涉及到绝对时间比如:每天凌晨2点执行 。那么它计算执行时间的方式是通过系统时间算出来的,也就是说如果用cron表达式来配置的话那么你更改系统时间就会影响到你的定时任务,举个简单的例子:比如第一次执行任务的时间为9:00,执行间隔为1小时一次;那么下次执行的时间应该是10:00而如果你修改系统时间就可能会造成定时任务的失效;
而fixedRate相对时间的意思是:计算执行时间的方式是根据项目启动的时间来算出来的,是从项目启动时间开始计算的。比如:第一次执行任务的时间为9:00,执行间隔为1小时一次;那么下次执行的时间应该是一个小时以后。也就是说它是通过记录你上次任务执行了多久来判断下次任务的触发时机。它不关心你的系统时间是多少。所以这种方式能够很好的解决我们更改系统时间的需求。
根据上述描述,可以总结出:cron表达式与服务器系统时间相关,在项目启动后一旦手动修改了服务器系统时间,则定时任务便会失效,此时需要重启系统;而fixedRate则与项目启动时间相关,与服务器系统时间无关。因此cron可用于配置任意时间执行定时任务的场景,而fixedRate的判断机制是通过相对时间来确定,可用于其他相关的场景(例如项目启动后每隔多长时间执行一次xxx操作)。
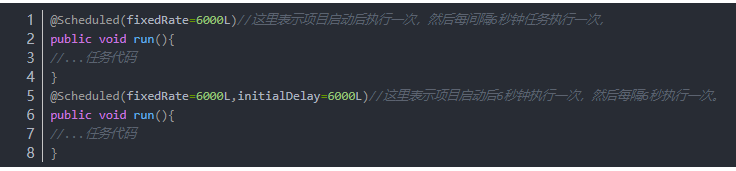
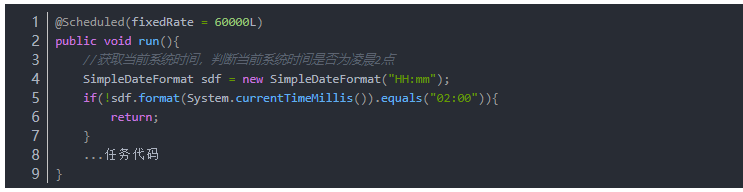
亦可考虑进一步优化,使得定时任务时间配置灵活,又不受服务器系统时间的影响导致失效的限制。参考网上案例说明:在定时任务触发的时候验证当前系统时间,以进一步确定操作是否继续执行
(3)windows下定时任务正常执行,linux下定时任务并发执行多次
问题描述:
在windows下定时任务正常执行,在linux下却出现系统启动后定时任务并发多次的情况

考虑与linux中的tomcat配置文件server.xml相关(server.xml解读)
(4)linux中无法正常读取文件大小
问题描述:
根据上述需求编写定时器,在windows下正常执行,放到linux服务器下却出现无法读取文件夹内容、大小的问题
排查1:检查设定的文件的路径是否正确
windows和linux的文件路径差异在于“分隔符”的方向不同,因此可借助File.sperator
如果文件路径设定不正确,后台报错“No such file or directory”
在排查过程中可打印拼接的路径语句进行验证,除此之外,File类中有许多类似sperator的与系统相关的静态字段。在程序设计中需更多地考虑系统在不同操作系统的服务器上运行的兼容性,因此在编写代码的时候需要灵活用到一些系统配置相关的参数,用以兼容程序在不同服务器上的运行。
排查2:检查文件夹或文件的命名是否存在乱码现象
问题描述:为了测试定时任务的执行效果,通过ftp从本地的windows传输多个文件夹到linux服务器的指定路径。在ftp中查看文件正常显示,并未出现乱码问题,但是在linux通过linux指令查看文件却发现一些含有中文的文件出现了乱码问题。此外,通过系统程序正常上传的文件并未出现乱码问题,也能够正常计算文件大小。
问题分析:Windows 的文件名中文编码默认为GBK,压缩或者上传后,文件名还会是GBK编码,而Linux中默认文件名编码为UTF8,由于编码不一致所以导致了文件名乱码的问题。由此可知,文件大小不能正常读取的原因还有可能是因为直接通过ftp将windows中的文件直接传给linux,导致出现中文乱码问题,从而间接影响到文件大小不能正常读取。
问题解决:
通过echo $LANG指令查看当前linux系统支持编码
通过指令打印并检查指定路径的文件名是否出现中文乱码的情况
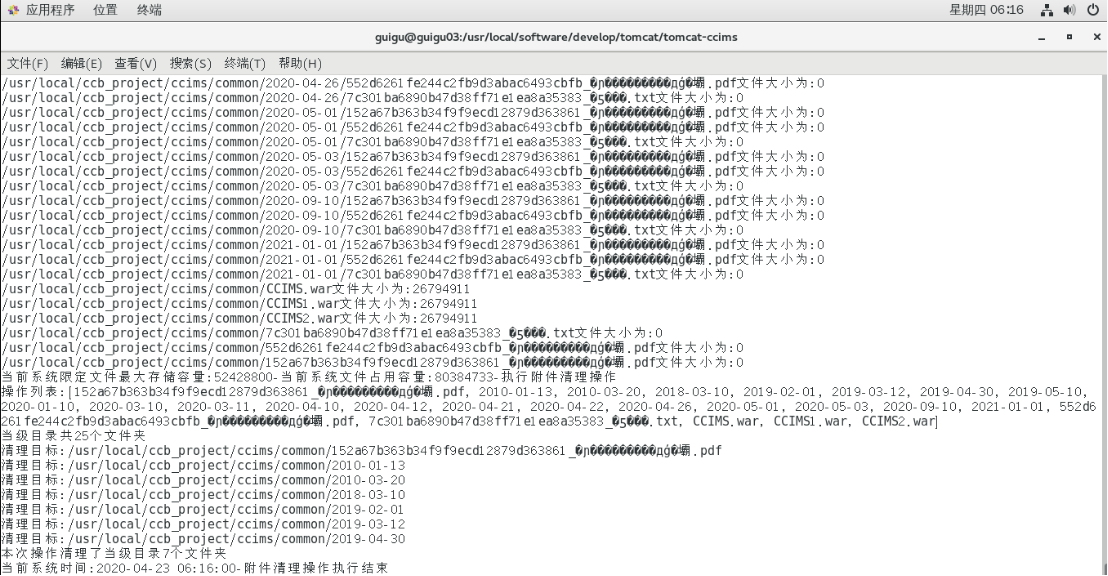
解决方式1:可以考虑通过修改/etc/profile配置文件中的默认编码集合(需要注意空格问题可能导致配置不能生成,或指令执行错误)
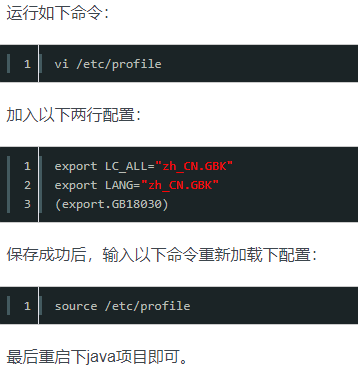
vim /etc/profile、source /etc/profile(配置文件即刻生效)
参考链接:https://www.cnblogs.com/steven-snow/p/9467166.html
解决方式2:在linux中批量变更指定文件的编码集(该方式需要引入convmv指令)
yum install convmv
convmv -f gbk -t utf-8 -r --notest /home/wwwroot
参数说明如下:
-r 递归处理子文件夹
-notest 真正进行操作,默认情况下是不对文件进行真实操作
-list 显示所有支持的编码
-unescap 可以做一下转义,比如把%20变成空格
-i 交互模式(询问每一个转换,防止误操作)
linux下有许多方便的小工具来转换编码:文本内容转换 iconv、文件名转换 convmv、mp3标签转换 python-mutagen