[JAVA]-IO
[JAVA]-IO
[TOC]
1.File类
File类是Java.io包下与平台无关的文件或者目录,也就是如果希望程序中操作文件或者目录,都可以通过操作File类完成需求。不管是文件还是目录都是使用File来操作的
访问文件和目录
参考案例1
public class FileDemo {
public static void main(String[] args) {
/**
* File类代表一个文件或者是一个目录,可以用指定的路径和文件名称创建一个File对象
* 表示加载对应路径下的文件(如果文件不存在则加载失败)
* 需要注意的是此处并不是创建文件,而是指向指定路径的某个文件,
* 如果文件不存在,则不能对其进行部分读写操作,需要通过createNewFile
* 方法在当前目录下创建该文件(但必须确保当前目录是存在的、有效的)
*/
File file = new File("e:/dev/test.txt");
show(file);
}
/**
* 测试File类常用的方法
*/
public static void show(File file)
{
//1.获取文件的名字
System.out.println(file.getName());
//2.得到当前文件的父目录
System.out.println(file.getParent());
//3.获取当前文件的上一级目录
System.out.println(file.getAbsoluteFile().getParent());
/**
* 获取文件的相关属性
*/
//4.文件是否存在
System.out.println(file.exists());
//5.文件是否可执行
System.out.println(file.canExecute());
//6.文件是否可读
System.out.println(file.canRead());
//7.文件是否可写
System.out.println(file.canWrite());
//8.得到文件的长度
System.out.println(file.length());
//9.得到指定内容的路径信息
System.out.println(file.getPath());
//10.判断指定内容是一个文件还是一个文件夹
System.out.println(file.isFile());
System.out.println(file.isDirectory());
/**
* 结果分析:
* 假设当前目录下并没有该文件
* test.txt
* e:\dev
* e:\dev
* 可通过对文件的相关属相进行设置从而得到不同的结果
* false:文件不存在
* false:文件不可执行
* false:文件不可读
* false:文件不可写
* 0:文件长度为0
* e:\filetest\test.txt
* false
* false
* -----------------------------
* 如果当前目录下存在该文件,则输出以下结果:
* test.txt
* e:\dev
* e:\dev
* true:文件存在
* true:文件可执行
* true:文件可读
* true:文件可写
* 0
* e:\dev\test.txt
* true:是一个文件
* false:不是一个文件夹
*/
}
}
参考案例2:
public class FileDemo2 {
public static void main(String[] args) throws Exception {
test();
}
public static void test() throws Exception
{
/**
* 创建文件、目录、遍历相关信息
*/
//1.创建一个文件
File file = new File("e:/ft.txt");
file.createNewFile();
/**
* file.createNewFile();创建一个文件
* 如果当前路径下并没有指定的目录,则无法直接创建文件,如果直接调用上述语句,会报出错误java.io.IOException: 系统找不到指定的路径
* 因此,一定要注意指定文件的路径是否正确,如果没有指定的目录,则需要为其创建相应的一级或者是多级目录
* 但若当前路径下存在指定的目录,则通过createNewFile方法
* 直接在当前指定路径下创建指定的文件
*/
//2.创建一个目录(单级目录)
File catalog = new File("e:\\test");
catalog.mkdir();
/**
* 通过mldir方法在指定的路径下创建了一个名为haha的单级目录
*/
//3.创建多级目录
File mulcatalog = new File("e:/dev/abc/ab/a");
mulcatalog.mkdirs();
//4.删除指定的文件或者目录
System.out.println(file.delete());
System.out.println(catalog.delete());
System.out.println(mulcatalog.delete());
/**
* 删除指定文件输出结果:
* true、true、true
* 可以看到文件ft.txt被删除、单级目录test被删除、
* 多级目录下的最里层的目录a被删除(多级目录的删除是删除指定的那一级目录)
*/
//5.得到指定目录下的所有文件或者是目录(此处遍历某个路径下的文件、目录)
File files = new File("e:\\dev");
String[] list = files.list();
for(String s : list)
{
System.out.println(s);
}
/**
* 结果分析:
* 上述遍历结果只是涉及到当前指定路径的所有文件、所有的目录的遍历,而不会进入到目录中深入遍历
*/
//6.得到所有的磁盘信息
File[] root = File.listRoots();
for(File f : root)
{
System.out.println(f);
}
}
}
过滤器
public class FileNameFilterDemo {
/**
* 通过文件过滤器实现得到指定目录下的制定类型的文件
* 文件过滤器:
* 通过Lambda表达式进行相关操作,在列出指定的文件时,根据提供的Lambda表达式进行相应的条件过滤
*/
public static void main(String[] args) {
/**
* 假定在e盘下有许多文件,得到指定目录test下的所有文件
* 过滤出后缀名为‘.java’的文件
*/
File file = new File("e:/dev");
System.out.println(file.getPath()+"下的所有文件展示如下:");
String[] all = file.list();
for(String s : all)
{
System.out.println(s);
}
System.out.println("--------------------------------");
System.out.println("经过过滤之后,所有的'.java'文件显示如下:");
String[] filter = file.list((dir,name)->name.endsWith(".java"));
for(String s : filter)
{
System.out.println(s);
}
}
}
练习:给定一个目录,迭代当前目录下所有的内容,如果是文件夹则进入到文件夹继续迭代
public class FileIteratorTest {
/**
* 练习:
* 给定一个目录,迭代当前目录下所有的内容,
* 如果是文件夹则进入到文件夹继续迭代(体现分级性,列出文件列表)
* 迭代指定的文件夹:如果文件夹内有文件夹则继续进入迭代,直到是文件为止
*/
public static void main(String[] args) {
File file = new File("E:/dev");
show(file,1);
}
public static void show(File file,int deepth)
{
//1.获取当前目录下的每个“文件”,判断其时普通文件还是文件夹
File[] list = file.listFiles();
for(File f : list)
{
if(f.isFile())
{
print(deepth,f);
}
else if(f.isDirectory())
{
/**
* 根据不同的级数输出相应的信息
* 首先要先打印当前的目录的名称,随后通过show迭代进入到其中进行遍历,终将所有的结果输出
* 如果判断出是文件夹,则用一个参数记录当前的级数,采用局部变量避免影响到当前目录下的其它文件的记录
*/
int current = deepth;
print(current,f);
show(f,++current);
}
}
}
public static void print(int count,File f)
{
for(int i=1;i<=count;i++){
System.out.print(" ");
}
System.out.println("|--"+f.getName());
}
}
2.流的分类及基本应用
【1】流的分类
照流的分类的方式,可以将流分为不同的类型,可以从下面几个角度对流进行划分
输入流和输出流:按照流的流向分为输入流和输出流
输入流:只能从流中读取数据,不能向其写入数据
输出流:只能向其写入数据,而不能从中读取数据
Java的输入流的基类主要是由InputStream和Reader组成,输出流的基类主要是由OutputStream和Writer组成
字节流和字符流:按照流操作的数据单元不同分为字节流和字符流
字节流和字符流的用法基本相同,区别在于字节流和字符流操作的数据单元不同
字节流操作的数据单元是8位字节,而字符流操作的数据单元是16位字节
字节流主要是由InputStream和OutputStream组成
字符流主要是由Reader和Writer组成
【2】字节流和字符流
输入流InputStream和Reader
InputStream是所有字节输入流的父类;Reader是所有字符输入流的父类
参考案例:FileReader
public class FileReaderDemo {
/**
* FileReader:字符输入流
*/
public static void main(String[] args) {
// 方式1:单个字符读取
// test("1");
// 方式2:指定字符读取
test("2");
}
public static void test(String oper)
{
//1.加载指定路径下的文件
File file = new File("e:/dev/test.txt");
//2.创建FileReader对象,初始化为null
FileReader fr = null;
//3.为fr分配空间,通过fr读取指定文件中的数据信息
try {
fr = new FileReader(file);
// 读取文本数据
switch (oper){
// a.读取单个字符(每读取一个字符,指针自行往下移动)
case "1":{
char ch1 = (char) fr.read();
char ch2 = (char) fr.read();
char ch3 = (char) fr.read();
System.out.println("ch1:"+ch1+"--ch2:"+ch2+"--ch3:"+ch3);
//依次读取数据
int ch = 0;
while((ch=fr.read())!=-1)
{
System.out.print((char)ch);
}
break;
}
// b.按照指定的字符数读取数据
case "2":{
/**
* 操作步骤:
* 1.创建一个char类型的字符数组buffer
* 2.定义int类型的临时变量hasRead,初始化为0
* 3.将读取到的内容拼接为字符串,进行相应的处理
*/
char[] buffer = new char[3];
int hasRead = 0;
while((hasRead=fr.read(buffer))!=-1)
{
String str = new String(buffer,0,hasRead);
System.out.print(str);
}
/**
* 无论buffer定义的大小为多少,FileReader对象每次读取都是按字符进行读取,而不会产生中文乱码问题
*/
break;
}
default:{
System.out.println("参数指定错误");
break;
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}
finally{
try {
//4.释放打开的资源
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
参考案例:FileInputStream
public class FileInputStreamDemo {
/**
* FileInputStream:字节输入流
*/
public static void main(String[] args) {
try {
test();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void test() throws Exception
{
//1.从指定路径加载文件
File file = new File("e:/dev/test.txt");
//2.利用FileInputStream创建输入流对象(需要处理异常或者是向上一级抛出异常)
FileInputStream fis = new FileInputStream(file);
//3.通过FileInputStream对象读取指定路径下的文件的内容
/**
* 操作步骤:
* a.定义一个字节类型(byte)的数组(每次读取的字节数)
* b.定义一个临时变量hasRead
* c.如果有相应的内容(即返回值不为-1)则输出(获取)
* d.根据需求输出或者是处理相关的内容
*/
byte[] buffer = new byte[3];
int hasRead = 0;// 查找的位置
while((hasRead=fis.read(buffer))!=-1)
{
String str = new String(buffer,0,hasRead);
System.out.print(str);
}
/**
* 由结果分析:
* 如果设置一次性读取的字节数过小,按照每次读取的字节进行读取,则针对中文字符有可能读出来的数据是乱码
*/
}
}
输出流OutputStream和Writer
参考案例:FileWriter
public class FileWriterDemo {
/**
* FileWriter:字符输出流
*/
public static void main(String[] args) {
test();
}
/**
* 步骤分析:
* 1.加载指定路径下的文件
* 2.创建FileReader对象fw,初始化为null
* 3.为fr分配空间,完成数据写入指定文件的操作
* 4.关闭输出流
*/
public static void test()
{
//1.加载指定路径下的文件
File file = new File("e:/dev/write.txt");
//2.创建FileReader对象fr,初始化为null
FileWriter fw = null;
//3.为fr分配空间,完成数据写入指定文件的操作
try {
//为指定的文件创建输出流对象,并实现在后方追加内容
fw = new FileWriter(file,true);
/**
* 写入数据有多种方式:
* a.按照指定的要求,一次写入一个字符串
* b.亦可一次写入指定的字符数的数据
*/
// 写入数据,可自行实现手动换行\r\n
fw.write("hello java...\r\n");
fw.write("冲冲冲...\r\n");
//立即写入
fw.flush();
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
//4.关闭打开的资源
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
参考案例:FileOutputStream
public class FileOutputStreamDemo {
/**
* FileOutputStream:字节输出流
*/
public static void main(String[] args) {
try {
test();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void test() throws Exception
{
/**
* 步骤分析:
* 1.加载指定路径下的文件
* 2.创建FileOutputStream对象fos,初始化为null
* 3.为fos分配空间,完成数据写入指定文件的操作
* 4.关闭输出流
*/
//1.加载指定路径下的文件
File file = new File("e:/dev/write.txt");
//2.创建FileOutputStream对象fos,初始化为null
FileOutputStream fos = null;
//3.为fos分配空间,完成数据写入指定文件的操作
fos = new FileOutputStream(file,true);
//向指定文件中写入数据,并实现手动换行
fos.write("haha,fos测试ing\r\n".getBytes());
fos.write("xixi,输出流测试完成\r\n".getBytes());
//立即写入
fos.flush();
//4.关闭输出流,由于此处是将异常抛给上一级进行处理,则无法使用finally语句
}
}
案例分析:文件拷贝
public class FileCopyDemo {
/**
* 练习:
* 利用输入流和输出流实现文件拷贝操作
* 此处用FileInputStream和FileOutputStream实现
* 技巧:
* 如果操作的是纯文本文件,需要使用字符流用以防止出现乱码问题
* 而如果操作的是二进制文件则使用字节流进行处理
*/
/**
* 步骤分析:
* 1.加载指定路径的相关文件
* 2.分别为指定的文件创建输入流和输出流对象
* 3.此处使用字节(byte)类型的数组实现数据的读取和写入
* 4.完成相关操作之后关闭打开的资源
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//加载指定路径的文件来源和目的文件
File from = new File("e:/dev/create.sql");
File to = new File("e:/dev/newCreate.sql");
/**
* 如果目的路径的文件不存在,则通过createNewFile创建指定的文件
*/
if(!to.exists())
{
to.createNewFile();
}
copy(from,to);
}
// 为了方便叙述,此处将涉及到的异常全部抛给上一级进行处理
public static void copy(File from, File to) throws Exception
{
FileInputStream fis = null;
FileOutputStream fos = null;
//为指定的文件分别创建输入流和输出流对象
fis = new FileInputStream(from);
fos = new FileOutputStream(to,true);
byte[] buffer = new byte[1024];
int hasRead = 0;
while((hasRead=fis.read(buffer))!=-1)
{
fos.write(buffer, 0, hasRead);
//立即写入
fos.flush();
}
}
}
3.输入输出体系
【1】输入输出体系介绍
Java的输入流和输出流体系提供了40多个类
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStram | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 打印流 | PrintStream | PrintWriter | ||
| 特殊流 | DataInputStream | DataOutputStream | ||
| 相关的流 | SequenceInputStream(切割合并流)、RandomAccessFile |
【2】访问字符串
public class StringNodeDemo {
/**
* 访问字符串
* StringReader、StringWriter
*/
public static void main(String[] args) {
try {
read();
} catch (Exception e) {
e.printStackTrace();
}
write();
}
public static void read() throws Exception
{
/**
* 通过StringReader对象读取字符串数据
* 并输出相关信息到控制台
*/
String src = "从明天起,做一个幸福的人\n"
+"喂马、劈柴、周游世界\n"
+"从明天起,关心所有的粮食和蔬菜\n"
+"我有一所房子,面朝大海,春暖花开\n"
+"从明天起,和每一个亲人通信\n"
+"告诉他们我的幸福\n";
//1.定义一个字符类型的数组
char[] buffer = new char[32];
int hasRead = 0;
//2.创建StringReader对象,根据指定字符数读取字符串中的内容
StringReader sr = new StringReader(src);
while((hasRead = sr.read(buffer))!=-1)
{
//3.读取字符串数据,将其输出到控制台
System.out.println(new String(buffer,0,hasRead));
}
}
public static void write()
{
/**
* 通过StringWriter对象写入字符串数据
* 并将相关的内容输出到控制台
*/
//直接按照指定的格式写入数据到StringWriter对象中
StringWriter sw = new StringWriter();
sw.write("有一个美丽的新世界,\n");
sw.write("她在远方等我,\n");
sw.write("那里有天真的孩子,\n");
sw.write("还有那姑娘的小酒窝咧!\n");
//输出sw中的数据到控制台
System.out.println(sw.toString());
}
/**
* 输出结果:
* 从明天起,做一个幸福的人
* 喂马、劈柴、周游世界
* 从明天起,关心所
* 有的粮食和蔬菜
* 我有一所房子,面朝大海,春暖花开
* 从明天起,和每
* 一个亲人通信
* 告诉他们我的幸福
* (由于每次读取的字符数为32(较小),每次读取完都会自动换行,
* 可以通过调节每次读取的字符个数来调整内容)
*
* 有一个美丽的新世界,
* 她在远方等我,
* 那里有天真的孩子,
* 还有那姑娘的小酒窝咧!
*/
}
【3】缓冲流
BufferedXxxx
字节缓冲流 BufferedInputStream 和BufferedOutputStream
字符缓冲流 BufferdReader 和BufferedWriter
使用缓冲流可以高效的读写相关的内容 。当使用缓冲流进行读取文件内容的时候,先尽量的从文件中读取字符串数据,并且放置到缓冲区,然后使用read方法读取内容,会先从缓冲区读取数据,如果缓冲区数据不足,会在从文件中读取,从而提高读写效率。
参考案例:BufferReader
public class BufferReaderDemo {
/**
* 缓冲流分为字节缓冲流和字符缓冲流,用法基本类似
* 字节缓冲流:BufferedIuputStream、BufferedOutputStream
* 字符缓冲流:BufferedReader、BufferedWriter
*/
public static void main(String[] args) {
test();
}
public static void test()
{
File file = new File("e:/dev/test.txt");
//1.创建输入流和缓冲流的对象,并初始化为null
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader(file);
br = new BufferedReader(fr);
//2.每次直接读取一行数据
String line = null;
try {
while((line=br.readLine())!=null)
{
System.out.println(line);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
/**
* 此处只需要关闭缓冲流即可,无需重复关闭fr
* 但如果fr、br均要关闭则需要注意关闭的先后顺序:先关闭fr、再关闭br,否则提示出错
*/
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
参考案例:BufferWriter
public class BufferWriterDemo {
public static void main(String[] args) {
try {
test();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void test() throws Exception
{
File file = new File("e:/dev/test.txt");
FileWriter fw = null;
BufferedWriter bw = null;
fw = new FileWriter(file);
bw = new BufferedWriter(fw);
for(int i=0;i<10;i++)
{
bw.write("加油努力、积极向上、ok的");
bw.newLine();//换行
bw.flush();//立即写入
}
}
}
参考案例:通过缓冲流实现文件的拷贝
public class BufferCopyFileDemo {
public static void main(String[] args) {
File from = new File("E:/dev/test.txt");
File to = new File("e:/target/outtest.txt");
copy(from,to);
}
public static void copy(File from,File to)
{
FileInputStream fis = null;
BufferedInputStream bis = null;
FileOutputStream fos = null;
BufferedOutputStream bos = null;
try {
fis = new FileInputStream(from);
bis = new BufferedInputStream(fis);
fos = new FileOutputStream(to);
bos = new BufferedOutputStream(fos);
//定义字节数组
byte[] buffer = new byte[1024*1024];
int hasRead = 0;
try {
while((hasRead=bis.read(buffer))!=-1)
{
bos.write(buffer, 0, hasRead);
bos.flush();//立即写入
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}finally{
//关闭打开的资源
try {
bis.close();
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
【4】装饰者模式(设计模式)
装饰者模式概念
装饰者模式:动态的将职责附加到对象上,如果需要对类进行功能的扩展,装饰者模式能提供比继承更加良好的设计原则
- 多用组合 少用继承
- 类的设计是对扩展开放,对修改关闭
Person基类
class Person
{
public void eat()
{
System.out.println("吃饭...");
}
}
newPerson:通过extends进行基类方法扩展
class newPerson extends Person
{
public void eat()
{
System.out.println("饭前开胃酒...");
super.eat();
System.out.println("饭后甜点...");
System.out.println("饭后休闲...");
}
}
newWrapperPerson:通过装饰者模式构建方法扩展
class newWrapperPerson
{
/**
* 装饰者模式:
* 1.定义一个私有的装饰对象
* 2.提供一个带参数的构造函数初始化该对象
* 3.根据需求补充相应的功能
*/
private Person p;
public newWrapperPerson(Person p)
{
this.p = p;
}
public void eat()
{
System.out.println("开始吃饭、聊天...喝喝小酒...");
p.eat();
System.out.println("饭后甜点...");
System.out.println("饭后休闲...");
System.out.println("吃饭结束...");
}
}
public class WrapperDemo {
/*
* 使用装饰者模式的特点:
* 1.装饰者中的构造函数 必须接受被装饰的类
* 2.装饰的类和被装饰的类应该属于同一个体系
*/
public static void main(String[] args) {
newWrapperPerson nwp = new newWrapperPerson(new Person());
nwp.eat();
}
}
IO中的装饰者模式
# 装饰者模式是为了解决给类的功能增强而出现的
-- a.对Writer根据不同的业务进行划分
Writer
|------TextWriter
|------MediaWriter
|------ImageWriter
-- b.随着业务功能的提升,需要对Writer再次改写:-- 利用缓冲提升性能
Writer
|------TextWriter
|------BufferedTextWriter
|------MediaWriter
|-----BufferedMediaWriter
|------ImageWriter
|------BufferedImageWriter
-- c.业务进一步提升需求,需要对Writer提高容错性和完整性:-- 利用差异传输
Writer
|-----TextWriter
|------BufferedTextWriter
|------InfoExceptionBufferedTextWrite
|------MediaWriter
|------BufferedMediaWriter
|------InfoExceptionBufferedMediaWriter
|------ImageWriter
|------BufferedImageWriter
|------InfoExceptionBufferedImageWriter
* 可以利用装饰者模式 解决继承来实现功能增强的这种行为
* Writer
* |---TextWriter
* |---MediaWriter
* |---ImageWriter
* |---BufferedWriter
* |--InfoExceptionWriter
class BufferedWriter extends Writer{
private TextWriter textWriter;
public BufferedWriter( TextWriter textWriter){
this.textWriter=textWriter;
}
}
案例说明:
给定一个目录 然后列出当前目录下所有的文件
public class ListAllFile {
/**
* 给定一个目录 然后列出当前目录下所有的文件
*/
public static void main(String[] args) {
File file = new File("e:/dev");
show(file);
}
public static void show(File file)
{
/*列出名称
String[] list = file.list();
for(String s : list)
{
System.out.println(s);
}
*/
File[] files = file.listFiles();
for(File f : files)
{
if(f.isDirectory())
System.out.println("文件夹--"+f.getPath());
else if(f.isFile())
System.out.println("普通文件--"+f.getPath());
}
}
}
删除一个指定的目录包括目录中所有的内容
public class DeleteFile {
/**
* 多级目录无法直接删除,需要通过遍历迭代删除
* 删除一个指定的目录包括目录中所有的内容
* a.在遍历的过程中实现删除
* b.通过遍历将指定目录下的文件加入集合,然后删除集合中指定路径的文件
*/
public static void main(String[] args) {
File file = new File("e:/abcd");
//方式1:遍历时删除
// delete(file);
//方式2:添加至指定集合后删除
deleteList(file);
del();
}
/**
* 方式1:在遍历的过程中进行删除
* 判断是否为文件,如果为文件则直接删除
* 如果是文件夹则迭代删除,最终删除当前目录
*/
public static void delete(File file)
{
if (file.isFile()) {
// 如果是普通文件则直接删除
file.delete();
} else {
//如果是文件夹则进行迭代删除
//首先得到当前所有文件的路径
String[] childFilePaths = file.list();
for (String childFilePath : childFilePaths) {
File childFile = new File(file.getAbsolutePath() + "/" + childFilePath);
delete(childFile);
}
//最终删除当前目录
file.delete();
}
}
/**
* 方式2:
* 先创建一个存放文件的列表
* 将遍历的所有文件、目录放入该列表中
* 删除列表中指定的所有文件即可
*/
public static ArrayList<File> al = new ArrayList<>();
public static void deleteList(File file)
{
//1.得到当前路径下的所有文件
File[] files = file.listFiles();
//2.通过ArrayList对象存放所有的文件
for(File f : files)
{
if(f.isFile())
al.add(f);
else if(f.isDirectory())
{
deleteList(f);
al.add(f);
}
}
//最终添加当前目录
al.add(file);
}
public static void del()
{
for(int i=0;i<al.size();i++)
{
al.get(i).delete();
}
}
}
给定一个目录,列出当前目录下指定类型的文件,然后输出到一个文件中
public class ListAllFiles {
public static void main(String[] args) {
File file = new File("e:/dev");
show(file,1);
}
public static void show(File file,int deepth)
{
File[] files = file.listFiles();
for(File f : files)
{
if(f.isFile())
print(f,deepth);
else if(f.isDirectory())
{
//定义临时变量接收当前的级数
int current = deepth;
print(f,current);
current++;
show(f,current);
}
}
}
public static void print(File file,int deepth)
{
//根据不同的级数打印内容
for(int i=1;i<=deepth;i++)
System.out.print(" ");
System.out.println("|--"+file.getName());
}
}
【5】转换流
输入流和输出流体系中提供了两个特殊的流,用于实现字节流转换为字符流
InputStreamReader、OutputStreamWriter
- InputStreamReader:是字节流通向字符流的桥梁,它将字节流转换为字符流
public class InputStreamReaderDemo {
public static void main(String[] args) {
try {
test();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void test() throws Exception
{
/**
* System.in返回的是一个字节流对象,通过
* InputStreamReader将字节流转化为字符流
*/
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
BufferedWriter bw = new BufferedWriter(new FileWriter("e:/dev/test.txt"));
String line = null;
while((line=br.readLine())!=null)
{
if("exit".equals(line)){
break;
}
bw.write(line);
bw.newLine();
bw.flush();
}
bw.close();
br.close();
}
}
- OutputStreamWriter:是字符流通向字节流的桥梁,它将字符流转换为字节流
public class OutputStreamWriterDemo {
public static void main(String[] args) {
try {
test();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void test() throws Exception
{
/**
* 通过OutputStreamWriter实现将字符流转化为字节流
* 输出(System.out)
*/
BufferedReader br = new BufferedReader(new FileReader("e:/dev/test.txt"));
OutputStreamWriter osw = new OutputStreamWriter(System.out);
BufferedWriter bw = new BufferedWriter(osw);
String line = null;
while((line=br.readLine())!=null)
{
bw.write(line);
bw.newLine();
bw.flush();
}
br.close();
bw.close();
}
}
【6】打印流
打印流是输出流,分为printStream字节打印流、printWriter字符打印流
public class PrintStreamDemo {
public static void main(String[] args) throws Exception {
// PrintStream ps = new PrintStream("e:/dev/test.txt");
//指定输出数据到控制台
PrintStream ps = new PrintStream(System.out);
/**
* 1.wirter方法:PrintStream的write方法是将一个
* int类型的数据的最低字节输出(最低八位)
*/
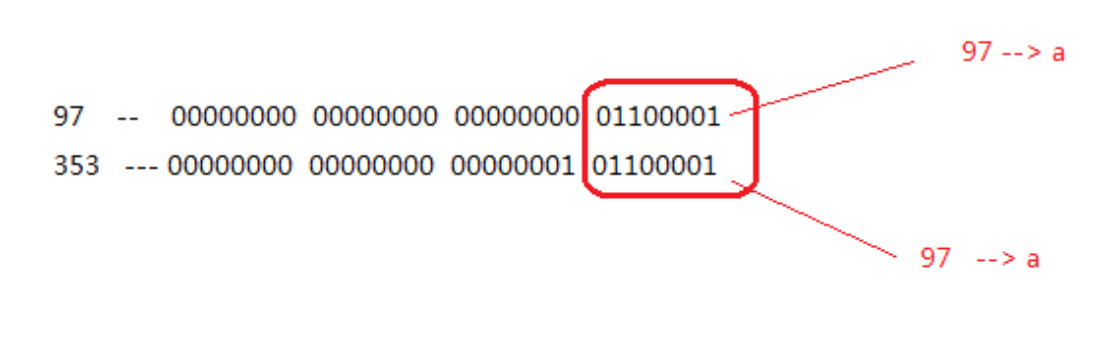
ps.write(97); //a
ps.write(353); //a
/**
* 2.println方法:PrintStream的println方法是保持
* 数值的形式不变直接输出
*/
ps.println(97); //97
ps.println(353); //353
//关闭打印流
ps.close();
}
}
public class PrintWriteDemo {
public static void main(String[] args) throws Exception {
// 通过InputStreamReader将标准字节流(System.in)转化为字符流,再用缓冲流进行封装
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 定义输出的缓冲流,将缓冲流再次封装为打印流
BufferedWriter bw = new BufferedWriter(new FileWriter("e:/dev/gogo.txt"));
PrintWriter pw = new PrintWriter(bw);
String line = null;
while((line=br.readLine())!=null)
{
// 如果输入exit标识退出
if(line.equals("exit")){
break;
}
pw.write(line);// 写入数据
pw.println(); // 换行
pw.flush(); // 立即写入
}
pw.close();
br.close();
}
}
案例分析
public class RedictIn {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("e:/dev/gogo.txt");
// 将标准输入流重定向到 fis输入流中
System.setIn(fis);
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
System.out.println(sc.next());
}
/**
* 结果显示:
* 通过语句System.setIn(fis);将标准输入流重定向到
* fis输入流中,从而实现从指定路径的文件中读取数据
*/
}
}
public class RedictOut {
public static void main(String[] args) throws Exception {
PrintStream ps =new PrintStream("e:/dev/bibi.txt");
//将标准输出流 重定向到 ps输出流中
System.setOut(ps);
Scanner scanner =new Scanner(System.in);
while(scanner.hasNext()) {
System.out.println(scanner.next());
}
/**
* 结果显示:
* 通过语句System.setOut(ps);将标准输出流重定向到
* ps打印流中,从而实现将相关的内容输出到指定路径的文件中
*/
}
}
【7】切割合并流
SequenceInputStream表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
参考案例:切割合并流:将一个文件切割至多份进行操作,随后再将文件进行合并
public class SequenceInputStreamDemo {
public static void main(String[] args) throws Exception {
File srcFile = new File("e:/dev/PhpStorm-2021.2.3.exe");
// 切割文件
splitFile(srcFile,"e:/dev/splitFile/",".part");
// 合并文件
mergeFile("e:/dev/splitFile/",".part","e:/dev/mergeFile/");
}
/**
* 切割文件
* @param srcFile 文件源
* @param targetFilePath 目标文件夹路径
* @param suffix 切割文件后缀(切割文件按一定规律存储,例如数字递增)
* @throws Exception
*/
public static void splitFile(File srcFile,String targetFilePath,String suffix) throws Exception
{
FileInputStream fis = null;
FileOutputStream fos = null;
//定义临时变量用以记录分割后文件的个数
int count = 1;
fis = new FileInputStream(srcFile);
byte[] buffer = new byte[1024*1024];
int hasRead = 0;
while((hasRead=fis.read(buffer))!=-1)
{
// 创建一个文件,指定文件的位置(例如e:/dev/xxx.part)
fos = new FileOutputStream(new File(targetFilePath,(count++)+suffix));
fos.write(buffer,0,hasRead);
fos.flush();
fos.close();
}
// 在统计目录中定义一个文件用以记录分割后的文件信息(切分后的文件个数、源文件的名称)
Properties prop = new Properties();
prop.setProperty("partCount", (count-1)+"");
prop.setProperty("fileName", srcFile.getName());
//将相关的属性保存至指定的文件
fos = new FileOutputStream(new File(targetFilePath,"info.properties"));
prop.store(fos, "save partFile info");
//释放打开的资源
fos.close();
fis.close();
}
/**
* @param sourceFilePath 要合并的文件目录源
* @param suffix 合并的源文件后缀
* @param outFilePath 合并输出的文件路径
* @throws IOException
*/
public static void mergeFile(String sourceFilePath,String suffix,String outFilePath) throws IOException {
/**
* SequenceInputStream 特点
* a)将多个源合并为一个流
* b)接受的是一个枚举接口对象
*/
// 1.创建ArrayList列表,将所有需要合并的文件输入流加载进列表中
ArrayList<FileInputStream> al =new ArrayList<>();
// 读取配置文件获取切割文件信息(或者通过遍历文件跟踪切割文件信息)
Properties prop = new Properties();
FileReader fr = new FileReader(sourceFilePath+File.separator+"info.properties");
prop.load(fr);
int partCount = Integer.valueOf(prop.getProperty("partCount"));
String fileName = prop.getProperty("fileName");
fr.close();
// 遍历切割的子文件列表
for(int i=1;i<=partCount;i++) {
al.add(new FileInputStream(sourceFilePath+i+suffix));
}
// 2.SequenceInputStream需要一个枚举类型
Enumeration<FileInputStream> en = Collections.enumeration(al);
SequenceInputStream sis =new SequenceInputStream(en);
// 3.创建目的地
FileOutputStream fos =new FileOutputStream(outFilePath+fileName);
byte [] buffer =new byte[1024];
int hasRead=0;
while((hasRead=sis.read(buffer))!=-1) {
fos.write(buffer,0,hasRead);
}
fos.close();
sis.close();
}
}
【8】RandomAccessFile
RandomAccessFile类的实例支持对随机访问文件的读取和写入。随机访问文件的行为类似存储在文件系统中的一个大型 byte 数组。存在指向该隐含数组的光标或索引,称为文件指针;输入操作从文件指针开始读取字节,并随着对字节的读取而前移此文件指针。如果随机访问文件以读取/写入模式创建,则输出操作也可用;输出操作从文件指针开始写入字节,并随着对字节的写入而前移此文件指针。写入隐含数组的当前末尾之后的输出操作导致该数组扩展。该文件指针可以通过getFilePointer方法读取,并通过 seek方法设置
"r" - 以只读方式打开:调用结果对象的任何 write 方法都将导致抛出 IOException
"rw" - 打开以便读取和写入:如果该文件尚不存在,则尝试创建该文件
"rws" - 打开以便读取和写入:对于 "rw",还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备
"rwd" - 打开以便读取和写入:对于 "rwd",还要求对文件内容的每个更新都同步写入到底层存储设备
public class RandomAccessFileDemo {
/**
* RandomAccessFile的特点:
* 1.既可以读取数据,也可以写入数据
* 2.只是针对文件进行操作
* 3.内部维护一个大型的Byte数组,将字节流输入流和字节输出流进行封装
* 4.通过索引的方式对数组中的元素进行操作(获取和设置索引的方法 getFilePointer、seek)
* 5.随机访问的原理就是通过操作索引的方法对指针进行自定义的指定位置进行读写
*/
public static void main(String[] args) throws Exception {
//1.随机写入数据
write();
//2.随机读取指定位置的数据
read();
}
public static void write() throws Exception
{
/**
* 1.随机创建读写文件的对象,如果文件不存在则会自行创建,如果文件存在则不会创建新的文件
* "r":以只读方式打开文件
* "rw":以读写方式打开文件
* "rws":以读写方式打开文件
* "rwd":以读写方式打开文件
*/
RandomAccessFile raf = new RandomAccessFile("e:/dev/raf.txt","rw");
//2.将数据写入到相应的文件中,并相应地获取当前指针的位置
raf.write("张小三".getBytes());
raf.writeInt(18);
System.out.println("当前的指针位置为:"+raf.getFilePointer());
raf.write("李小四".getBytes());
raf.writeInt(28);
System.out.println("当前的指针位置为:"+raf.getFilePointer());
raf.write("王小五".getBytes());
raf.writeInt(38);
System.out.println("当前的指针位置为:"+raf.getFilePointer());
//3.数据保存完毕,关闭流
raf.close();
}
public static void read() throws Exception
{
/**
* 1.创建随机读写文件的对象
*/
RandomAccessFile raf = new RandomAccessFile("e:/dev/raf.txt","r");
/**
* 2.跳过指定的字节数不读,读取指定位置的数据
* 一个中文字符占3个字节
* 一个int类型的整型数据占4个字节
*/
// 跳过指定字节不读,等价于raf.seek(10*2);
raf.skipBytes(13*2);
//读取姓名
byte[] buffer = new byte[9];
raf.read(buffer);
String name = new String(buffer);
//读取年龄
int age = raf.readInt();
System.out.println("姓名:"+name);
System.out.println("年龄:"+age);
//3.关闭流
raf.close();
/**
* 结果:(跳过了指定的内容)
* 姓名:王小五
* 年龄:38
*/
}
}
【9】Properties
Perperties基础
Properties概念
Properties是一个Map体系的集合类,它可以将数据保存到流中或从流中加载数据,其属性列表中的每个键及其对应的值都是一个字符串
参考案例
public class PropertiesDemo01 {
public static void main(String[] args) {
// 创建集合对象
Properties prop = new Properties();
//存储元素
prop.put("zs", "张三");
prop.put("ls", "李四");
//遍历集合
Set<Object> keySet = prop.keySet();
for (Object key : keySet) {
Object value = prop.get(key);
System.out.println(key + "," + value);
}
}
}
Properties作为Map集合特有的方法
setProperty、getProperty、stringPropertyNames
| 方法名 | 说明 |
|---|---|
Object setProperty(String key, String value) | 设置集合的键和值,都是String类型,底层调用 Hashtable方法 put |
String getProperty(String key) | 使用此属性列表中指定的键搜索属性 |
Set<String> stringPropertyNames() | 从该属性列表中返回一个不可修改的键集,其中键及其对应的值是字符串 |
参考案例
public class PropertiesDemo02 {
public static void main(String[] args) {
//创建集合对象
Properties prop = new Properties();
// Object setProperty(String key, String value):设置集合的键和值,都是String类型
prop.setProperty("zs", "张三");
prop.setProperty("ls", "李四");
//String getProperty(String key):使用此属性列表中指定的键搜索属性
System.out.println(prop.getProperty("zs"));
System.out.println(prop.getProperty("ls"));
System.out.println(prop);
// Set<String> stringPropertyNames():从该属性列表中返回一个不可修改的键集,其中键及其对应的值是字符串
Set<String> names = prop.stringPropertyNames();
for (String key : names) {
String value = prop.getProperty(key);
System.out.println(key + "," + value);
}
}
}
IO流中Properties应用
| 方法名 | 说明 |
|---|---|
void load(Reader reader) | 从输入字符流读取属性列表(键和元素对) |
void store(Writer writer, String comments) | 将此属性列表(键和元素对)写入此 Properties表中,以适合使用 load(Reader)方法的格式写入输出字符流 |
public class PropertiesDemo03 {
public static void main(String[] args) throws IOException {
// 1.存储集合中的数据保存到文件
// myStore();
// 2.将文件中的数据加载到集合
myLoad();
}
private static void myLoad() throws IOException {
Properties prop = new Properties();
// void load(Reader reader):
FileReader fr = new FileReader("test\\test.txt");
prop.load(fr);
fr.close();
System.out.println(prop);
}
private static void myStore() throws IOException {
Properties prop = new Properties();
prop.setProperty("zs","张三");
prop.setProperty("ls","李四");
//void store(Writer writer, String comments):
FileWriter fw = new FileWriter("test\\test.txt");
prop.store(fw,null);
fw.close();
}
}
4.对象序列化
【1】基本概念
为什么要有java序列化?
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
序列化的目标是对象保存到磁盘中,或者允许在网络中传输对象,对象序列化的机允许把内存中的java对象转换为与平台无关的二进制流,从而允许吧这种二进制流持久的保存到磁盘中。也可以把二进制流通过网络传输到另外一个节点,其他程序一旦获取这种二进制流,就可以恢复成原来的java对象。
Java平台允许我们在内存中创建可复用的Java对象,但只有当JVM(Java虚拟机)处于运行时,这些对象才可能存在,也就是这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存指定的对象(持久化对象),并在将来重新读取被保存的对象。Java对象序列化就实现了该功能。
网络通信时,无论是何种类型的数据,都会转成字节序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。Java对象序列化也实现了该功能。
序列化的意义
我们知道当虚拟机停止运行之后,内存中的对象就会消失;另外一种情况就是JAVA对象要在网络中传输,如RMI过程中的参数和返回值。这两种情况都必须要将对象转换成字节流,而从用于保存到磁盘空间中或者能在网络中传输。
由于RMI是JAVA EE技术的基础---所有分布式应用都需要跨平台、跨网络。因此序列化是JAVA EE的基础,通常建议,程序创建的每个JavaBean类都可以序列化。
序列化的机制是运行实现序列化的java对象转换为字节序列,这些字节序列可以永久的保存到磁盘上,或者通过网络进行传输,之后可以恢复成原来的java对象,序列化的机制就是使对象可以脱离程序独立存在。
对象序列化的几个原则
如果要让每个对象支持序列化机制,必须让它的类是可序列化的,则该类必须实现如下两个接口之一:
Serializable、Extmalizable
对象序列化有几个常见的原则:
Serializable是一个标示性接口,接口中没有定义任何的方法或字段,仅用于标示可序列化的语义- 静态变量和成员方法不可序列化
- 一个类要能被序列化,该类中的所有引用对象也必须是可以被序列化的。否则整个序列化操作将会失败,并且会抛出一个NotSerializableException,除非我们将不可序列化的引用标记为transient。
- 声明成transient的变量不被序列化工具存储,同样,static变量也不被存储。
- 一个类实现了序列化,那么同时能被反序列化,恢复为原对象
对象操作流
对象序列化流(ObjectOutputStream)
将Java对象的原始数据类型和图形写入OutputStream。 可以使用ObjectInputStream读取(重构)对象。 可以通过使用流的文件来实现对象的持久存储。 如果流是网络套接字流,则可以在另一个主机上或另一个进程中重构对象
对象反序列化流(ObjectInputStream)
ObjectInputStream反序列化先前使用ObjectOutputStream编写的原始数据和对象
/**
* 对象序列化实现步骤:
* 1.定义一个类实现Serializable接口
* 2.通过ObjectOutputStream创建对象将对象序列写入指定的文件中
* writeObject(Object obj);方法实现
* 3.通过ObjectInputStream创建对象获取指定文件的对象序列,并实现
* 对象反序列化,通过readObject();方法实现
*/
public class Person implements Serializable {
/**
* Person是一个普通的java对象,只是实现了Serializable的空接口
* Serializable是一个标识接口
* 该接口所标识的类是可以被序列化和反序列化
*/
/**
* 可以相应地指定序列的标识版本号serialVersionUID
* 在读写的时候必须保证序列地表示版本号一致,否则会报错
*/
private static final long serialVersionUID = 3408349495970716223L;
private String name;
private int age;
public Person()
{
}
public Person(String name,int age)
{
this.name = name;
this.age = age;
}
public void setName(String name)
{
this.name = name;
}
public String getName()
{
return this.name;
}
public void setAge(int age)
{
this.age = age;
}
public int getAge()
{
return this.age;
}
}
public class ObjetOutputStreamTest {
public static void main(String[] args) throws Exception {
File file = new File("e:/object.txt");
//向指定的文件中写入对象数据
write(file);
}
public static void write(File file) throws Exception
{
//创建ObjectOutputStream对象写入对象数据
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
//创建Person对象,将其输出到指定的文件中
Person p = new Person("罐头鱼",1);
oos.writeObject(p);
/**
* 在指定的文件中可以看到经过“对象序列化”后的对象信息
* (虽然有存在乱码,但可以通过对象反序列化实现对象的还原)
*/
}
}
public class ObjectInputStreamTest {
public static void main(String[] args) throws Exception {
File file = new File("e:/object.txt");
//从指定的文件中读取对象数据
read(file);
}
public static void read(File file) throws Exception
{
//创建ObjectInputStream对象读取指定的对象数据
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
//从指定文件中读取对象信息(需要进行强制类型转换为指定的对象)
Person p = (Person)ois.readObject();
System.out.println("姓名:"+p.getName()+"--年龄:"+p.getAge());
}
}
serialVersionUID、transient
serialVersionUID
- 用对象序列化流序列化了一个对象后,假如我们修改了对象所属的类文件,读取数据会不会出问题呢?
- 会出问题,会抛出InvalidClassException异常
- 如果出问题了,如何解决呢?
- 重新序列化
- 给对象所属的类加一个serialVersionUID
- private static final long serialVersionUID = 42L;
- 用对象序列化流序列化了一个对象后,假如我们修改了对象所属的类文件,读取数据会不会出问题呢?
transient
- 如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?
- 给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程
- 如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?
5.NIO与NIO2
【1】NIO(同步非阻塞式IO)
BufferedReader 它有一个特性—当BufferedReader读取输入流中的数据时,如果没有读取到有效的数据,程序将在该处阻塞程序的执行,(使用InputStream的read方法从流中读取数据,如果数据源中没有数据,它也会阻塞该程序的执行),也就是NIO之前所学的所有的输入流和输出流都是阻塞式的输入输出流。
不仅如此传统的IO 输入流和输出流都是通过字节的移动来处理(即使不是处理字节流,但是底层还是依赖字节处理),也就是面向流的输入和输出都是一次性只能处理一个字节,所以面向流的输入和输出效率都不是很高。
从jdk1.4之后java提供了一系列的改进。这些新的功能被称为新IO( NIO)新增了许多用于处理输入流和输出流的类,这些类都是在java.nio包下并且对源java.io包中很多类进行了改写
Java新IO的概述
新IO和传统的IO有相同的目的,都是用于输入和输出。但是新IO使用了不同的方式处理输入和输出,新IO采用内存映射文件的方式处理输出和输出,新IO将文件或者文件的一段区域映射到内存中。这样就可以象访问内存一样来访问文件。通过这种方式进行操作远远效果高于传统的io。
新IO提供了如下包:
java.nio :主要是各种与Buffer相关的类
java.nio.channels:主要是包含与Channel和Selector相关的类
java.nio.channels.spi :主要是与Channel相关的服务提供者编程接口
java.nio.charset :主要是与字符集相关的类
java.nio.charset.spi : 主要是包含和字符集相关的服务提供者编程接口
使用Buffer
从内部结构上看 Buffer就像一个数组,它可以保存多个类型相同的数据,Buffer是一个抽象类。它可以在底层字节数组上进行get/set操作。常见的Buffer的子类包括以下几种:
ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer、MappedByteBuffer、ShortBuffer
以上这些Buffer都采用相同的方法来管理数据,各自管理的数据类型不同。
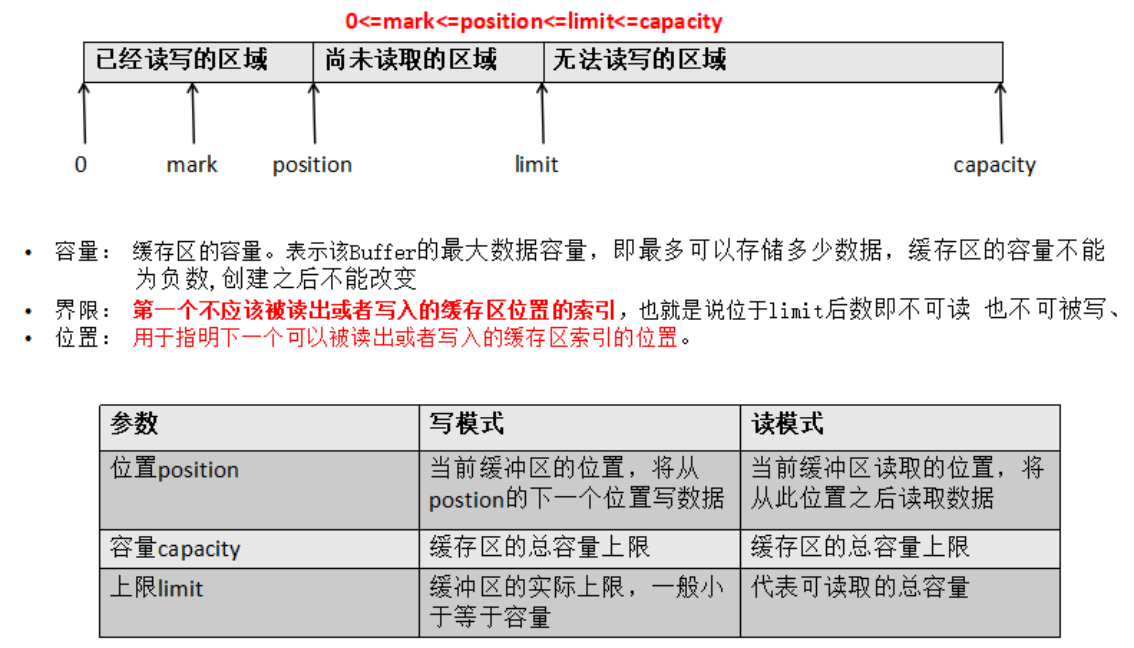
Buffer中有三个重要的概念 :容量(capacity)、界限(limit) 和位置(position)
容量:缓存区的容量。表示该Buffer的最大数据容量,即最多可以存储多少数据,缓存区的容量不能为负数, 创建之后不能改变。
界限:第一个不应该被读出或者写入的缓存区位置的索引,也就是说位于limit后数即不可读,也不可被写
位置:用于指明下一个可以被读出或者写入的缓存区索引的位置
public class BufferTest {
public static void main(String[] args) {
/**
* CharBuffer测试:创建Buffer,分别讨论Buffer的三个概念
* capacity容量、limit界限、position位置
*/
//1.新分配CharBuffer对象
CharBuffer cb = CharBuffer.allocate(8);
System.out.print(cb.capacity()); //8
System.out.print(cb.limit()); //8
System.out.println(cb.position()); //0
//2.向Buffer中添加数据后,分别查看三个概念对应的取值并进行分析
cb.put('a');
cb.put('b');
cb.put('c');
System.out.print(cb.capacity()); //8
System.out.print(cb.limit()); //8
System.out.println(cb.position()); //3
/**
* 使用filp方法将未被使用的部分加以区分,
* 并使得position指针指向0位置,
* 分别查看三个概念对应的取值并进行分析
*/
//3.使用filp方法区分不同的区域
cb.flip();
System.out.print(cb.capacity()); //8
System.out.print(cb.limit()); //3
System.out.println(cb.position()); //0
//4.此时取出第一个元素,查看并分析相关数据
System.out.print(cb.get());
System.out.print(cb.capacity()); //8
System.out.print(cb.limit()); //3
System.out.println(cb.position()); //1
//再次进行第二次添加数据,此次添加一个数据
// cb.put('d');
// cb.flip();
//5.取出下一个元素
System.out.print(cb.get()); //取出第二个元素
System.out.print(cb.capacity()); //8
System.out.print(cb.limit()); //3
System.out.println(cb.position()); //2
//6.将Buffer清空,后分别查看三个概念对应的取值并进行分析
cb.clear();
System.out.print(cb.capacity()); //8
System.out.print(cb.limit()); //8
System.out.println(cb.position()); //0
}
}






使用Channel
Channel类类似于传统的流对象,与传统的流对象有两个重要的区别:
Channel可以直接将文件的部分或者全部直接映射为Buffer
程序不能直接访问Channel中的数据,包括读取写入都不行,Channel只能与Buffer进行交互、也就是说如果需要从Channel中获取数据必须先使用Buffer从Channel中取出数据。然后让程序Buffer中读取这些数据
Java为Channel提供了以下实现类
DatagramChannel、FileChannel、SelectableChannel、ServerSocketChannel、SocketChannel
使用Channel中最常用的三类方法是map、read、write 方法
map方法是将Channel对应的全部或者部分数据映射为ByteBuffer
read或者write方法都有很多重载使用
(1)基础使用
public class FileChannelTest {
public static void main(String[] args) throws Exception {
File from = new File("e:/in.txt");
File to = new File("e:/out.txt");
test(from,to);
}
public static void test(File from,File to) throws Exception
{
/**
* 1.使用相应的FileInputStream、FileOutputStream对象的
* getChannel()方法创建读、写通道
*/
FileChannel inChannel = new FileInputStream(from).getChannel();
FileChannel outChannel = new FileOutputStream(to).getChannel();
/**
* 2.将读取到的文件内容全部映射到内存中
* 使用通道的map(参数映射方式,position,文件大小)方法实现
*/
MappedByteBuffer buffer = inChannel.map(FileChannel.MapMode.READ_ONLY, 0, from.length());
/**
* 3.如果读取的内容是纯文本文件,则需要设置指定的编码集
* 以防出现乱码问题
* 常见的编码集:UTF-8、GBK、GB2312、ISO-8859-1
*/
//设定指定的编码集
/**
* 4.将buffer中的内容(即内存中的数据)全部输出到写通道中
*/
outChannel.write(buffer);
/**
* 5.调用clear方法,复原buffer中的位置
*/
buffer.clear();
/**
* 6.解决编码问题
* a.创建解码器对象
* b.使用解码器将指定的ByteBuffer转换为CharBuffer
* c.输出解码后相应的内容
*/
//a.设定指定的编码集,创建解码器对象
Charset charset = Charset.forName("GBK");
CharsetDecoder decoder = charset.newDecoder();
//b.使用解码器将ByteBuffer转换为CharBuffer
CharBuffer charBuffer = decoder.decode(buffer);
//c.输出解码后相应的内容
System.out.println("解码后的内容:\n"+charBuffer);
}
}
(2)RandomAccessFile
获取Channel的方式,除了inputStream或者outputStream之外。还可以通过RandomAccessFile也包含一个getChannel的方法,这个方法返回的FileChannel是只读的还是读写的取决这个文件的打开模式
public class RandomChannelTest {
public static void main(String[] args) throws Exception {
File file = new File("e:/in.txt");
test(file);
}
public static void test(File file) throws Exception
{
/**
* RandomAccessFile对象提供了一个getChannel方法获取相应的
* 读写通道,这个方法返回的是读还是写通道是取决于这个文件的打开方式
*/
/**
* 1.创建RandomAccessFile对象,打开方式为“rw”
* 用一个FileChannel接收其通过getChannel方法后返回的内容
*/
RandomAccessFile raf = new RandomAccessFile(file,"rw");
FileChannel randomChannel = raf.getChannel();
/**
* 2.将要读取的指定路径的文件内容全部以ByteBuffer形式映射到
* 内存中(使用map(参数映射方式,position,文件大小)实现)
* 可以指定相应的编码集,以防止在读取、写入的过程中出现乱码问题
*/
//此时的randomChannel对应的为“读”通道
ByteBuffer buffer = randomChannel.map(FileChannel.MapMode.READ_ONLY, 0, file.length());
/**
* 3.将buffer中的内容(即内存中的数据)通过写通道写入指定的文件中
* 由于操作的始终是同一个文件,为了让结果明显一点,在写入指定的文件时
* 先将当前文件的指针位置移动到最后,从而实现在文本末尾追加数据
*/
//此时的randomChannel对应的为“写”通道
randomChannel.position(file.length());
randomChannel.write(buffer);
}
}
(3)读取问题
如果用户习惯使用传统的io多次重复读取的过程,或者担心文件过大,使用map一次将所有内容映射到内存中可能导致性能的下降。也可以使用Channel和Buffer结合使用传统的方式进行多次多写
public class MuliReadFile {
/**
* 结合传统io多次读取和文件映射的方式对文件进行操作
* @throws Exception
*/
public static void main(String[] args) throws Exception {
File in = new File("e:/in.txt");
File out = new File("e:/out.txt");
test(in,out);
}
public static void test(File in,File out) throws Exception
{
/**
* 1.通过FileInputStream、FileOutputStream的getChannel
* 方法创建相应的读、写通道
*/
FileChannel inChannel = new FileInputStream(in).getChannel();
FileChannel outChannel = new FileOutputStream(out).getChannel();
/**
* 2.设置每次读写的buffer容量
*/
ByteBuffer buffer = ByteBuffer.allocate(256);
/**
* 3.多次读取指定的内容并相应的写入指定文件、控制台
* 要设置指定的编码集,用以防止出现乱码问题
*/
int hasRead = 0;
while((hasRead=inChannel.read(buffer))!=-1)
{
/**
* 1.锁定buffer的空白区
*/
buffer.flip();
/**
* 2.1向指定文件写入缓存中的数据
*/
// outChannel.position(out.length());
// outChannel.write(buffer);
/**
* 2.2将内存中的内容解码并输出到控制台
*/
//设定指定的编码集和解码器,将内容输出到控制台
Charset charset = Charset.forName("GBK");
CharsetDecoder decoder = charset.newDecoder();
//将ByteBuffer相应地转化为CharBuffer
CharBuffer charBuffer = decoder.decode(buffer);
System.out.println("解码之后的内容:"+charBuffer);
/**
* 3.将buffer初始化,为下一次读取数据作准备
*/
buffer.clear();
}
}
}
字符集和Charset
public class CharsetTest {
public static void main(String[] args) {
/**
* 获取并打印Java支持的所有字符集
* 常见的编码集:
* GBK 简体中文字符集
* Big5 繁体中文字符集
* ISO-8859-1 ISO 拉丁字母表 ISO-LANTIN-1
* UTF-8 8位UCS转换格式
*/
SortedMap<String,Charset> map = Charset.availableCharsets();
map.forEach((key,value)->System.out.println("key:"+key+"--value:"+value));
}
}
public class CharsetDemo {
public static void main(String[] args) throws Exception {
test();
}
public static void test() throws Exception
{
/**
* 编码集的设置、编码、解码
* 1.创建指定的编码集
* 2.创建指定编码集对应的编码器和解码器
* 3.创建xxxBuffer对象,对指定的内容进行测试
*/
//1.创建GBK对应的编码集
Charset cn = Charset.forName("GBK");
//2.创建指定编码集对应的编码器和解码器
CharsetEncoder encoder = cn.newEncoder();
CharsetDecoder decoder = cn.newDecoder();
//3.创建CharBuffer对象进行,添加数据测试
CharBuffer cb = CharBuffer.allocate(256);
cb.put("坚");
cb.put("持");
cb.put("住");
//将未使用区域进行划分,以免访问到没有使用的区域而导致出错
cb.flip();
//通过编码器将CharBuffer转化为ByteBuffer类型的数据输出
ByteBuffer bb = encoder.encode(cb);
System.out.println("编码后的内容:");
for(int i=0;i<bb.capacity();i++)
{
System.out.print(bb.get(i)+"--");
}
//通过解码器将ByteBuffer转化为CharBuffer类型的数据输出
CharBuffer buffer = decoder.decode(bb);
System.out.println("\n解码后的内容:\n"+buffer);
}
}
【2】NIO2(异步非阻塞式IO)
Path、Paths、和Files核心API
早期java只提供了一个File类访问文件系统,但是File类功能有限,他不能利用特定文件系统和的特性。 File 提供的方法性能也不高。 大多数方法在出现错误只能返回失败。并不会提供任何异常信息。
NIO2为了弥补不足,引入了Path接口。Path接口是与平台无关的的路径,除此之后NIO2还提供了Files和Paths工具类。
public class PathTest {
public static void main(String[] args) {
test();
}
public static void test()
{
/**
* 以当前的路径信息创建Path对象
* 即指在当前程序所在之处创建Path对象
*/
Path path = Paths.get(".");
/**
* 打印当前路径的相关信息
* a.getNameCount()获取当前路径包含的路径数量(多少级)
* b.getRoot()获取当前路径的根路径
*/
System.out.println("path中包含的路径的数量:"+path.getNameCount());
System.out.println("path的根路径为:"+path.getRoot());
//获取与当前路径的绝对路径相关的信息:E:\eclipse\IOTest\src...
Path absolutePath = path.toAbsolutePath();
//获取绝对路径的根路径
System.out.println("path绝对路径的根路径:"+absolutePath.getRoot());
System.out.println("path绝对路径中包含的路径的数量:"+absolutePath.getNameCount());
System.out.println("获取某级路径:"+absolutePath.getName(1));
//通常以多个String构建Path对象
Path p = Paths.get("e:","test","create.sql");
System.out.println(p);
/**
* 结果分析:
* path中包含的路径的数量:1
* path的根路径为:null
* path绝对路径的根路径:E:\
* path绝对路径中包含的路径的数量:3
* 获取某级路径:JavaIO
* e:\test\create.sql
*/
}
}
public class FilesTest {
/**
* 借助Files类结合Path实现前面io所涉及的问题
* a.实现文件复制
* b.判断文件是否隐藏
* c.文件内容读取
* d.判断某个文件的大小
* e.列举当前目录下所有的文件和子目录
* f.得到系统磁盘的相关信息
* g.将多个字符串的内容直接写入指定的文件中
*/
public static void main(String[] args) throws Exception {
// copyFile();
// isHidden();
// readFile();
// fileSize();
// listAllFile();
// readDisk();
writeFile();
}
public static void copyFile() throws Exception
{
/**
* 1.文件复制
* 将指定路径为"e:/test/create.sql"文件
* 复制到目的路径"e:/test.sql"
* copy(source, out)方法需要接收一个文件来源路径Path
* 和一个写入文件的输出流参数
*/
Path path = Paths.get("e:","test","create.sql");
FileOutputStream fos = new FileOutputStream("e:/test.sql");
Files.copy(path, fos);
}
public static void isHidden() throws Exception
{
/**
* 2.判断文件是否隐藏
* isHidden(path)方法需要接收一个文件来源路径
*/
Path path = Paths.get("e:","test","create.sql");
System.out.println(Files.isHidden(path));
}
public static void readFile() throws Exception
{
/**
* 3.读取文件内容
* 使用Files的readAllLines(path)方法实现一次性读取所有行
* 此方法需要接收一个文件来源路径,返回的是一个List<String>类型
* 此处需要指定相应的编码集,否则有可能报错
*/
Path path = Paths.get("e:","in.txt");
List<String> list = Files.readAllLines(path,Charset.forName("gbk"));
for(String s : list)
{
System.out.println(s);
}
}
public static void fileSize() throws Exception
{
/**
* 4.判断某个文件的大小
* 使用size(path)方法实现,该方法需要接收一个文件来源路径
*/
Path path = Paths.get("e:","in.txt");
System.out.println(Files.size(path));
}
public static void listAllFile() throws Exception
{
/**
* 5.列举当前目录下所有的文件和子目录
* 用Files的list(dir)方法实现,该方法需要接收一个文件来源路径
* 返回的是Stream<Path>类型
*/
Path path = Paths.get("e:/test");
Stream<Path> stream = Files.list(path);
stream.forEach(System.out::println);
}
public static void readDisk() throws Exception
{
/**
* 6.得到系统磁盘的相关信息
* 通过Files的getFileStore(path),该方法需要接收一个文件来源路径
* 其返回的结果是FileStore类型
*/
Path path = Paths.get("e:");
FileStore store = Files.getFileStore(path);
//输出磁盘的总空间与剩余的可用空间
System.out.println("e盘总空间:"+store.getTotalSpace());
System.out.println("e盘剩余的可用空间:"+store.getUsableSpace());
}
public static void writeFile() throws Exception
{
/**
* 7.将多个字符串内容直接写入指定的文件中
* a.用List<String>存储数据
* b.使用Files的write方法实现
* write(目的文件路径,存储数据的集合,编码集...)
*/
List<String> list = new ArrayList<>();
list.add("hello haha");
list.add("好好学习,天天向上!");
list.add("good good study,day day up!!");
Path path = Paths.get("e:","out.txt");
Files.write(path, list, Charset.forName("gbk"));
}
}
使用FileVistitor遍历文件和目录
有了Files工具类的帮助 可以更优雅的的遍历文件和子目录
public class FileVistitorTest {
public static void main(String[] args) throws Exception {
/**
* 遍历指定的目录和子目录的内容
*/
Files.walkFileTree(Paths.get("e:","实习资料"), new SimpleFileVisitor<Path>(){
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("正在访问:"+file+"文件");
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("正在访问:"+dir+"路径");
return FileVisitResult.CONTINUE;
}
});
}
}
使用WatchService监控文件变化
在之前的java版本中如果需要程序监控文件的变化必须手动启动一个后台线程然后让这个线程每隔一段时间遍历指定文件夹监听文件夹数据的变化
public class WatchServiceTest {
public static void main(String[] args) throws Exception {
listen();
}
public static void listen() throws Exception
{
/**
* 1.获取文件系统的WatchService对象
*/
WatchService ws = FileSystems.getDefault().newWatchService();
/**
* 2.为指定的目录或者是磁盘设置监听
* 监听事件:创建文件、删除文件、修改文件
*/
Path path = Paths.get("e:","gogo");
path.register(ws, StandardWatchEventKinds.ENTRY_CREATE,
StandardWatchEventKinds.ENTRY_DELETE, StandardWatchEventKinds.ENTRY_MODIFY);
/**
* 3.开始监听文件
*/
while(true)
{
/**
* 每当监听的文件或者是磁盘发生了变化就得到该对象
* 并打印相应的提示信息
*/
WatchKey key = ws.take();
for(WatchEvent<?> event:key.pollEvents())
{
System.out.println(event.context()+"--文件发生了变化--"
+event.kind()+"事件!");
}
/**
* 每当监听完一个变化记录之后重置监听,如果重置
* 失败则退出监听
*/
boolean vaild = key.reset();
if(!vaild)
break;
}
}
}