开发笔记-后台开发技巧
开发笔记-后台开发技巧
说明
单体应用开发(基于eclipse开发),总结后台业务开发的一些小技巧和常见问题解决方案,不限于某个技术框架应用
- SSO(单体架构到分布式架构的切换,用户登录态处理)
- 数据处理技巧(多级分类、动态菜单、常量维护、Excel数据处理、JSON数据转换、对象重复性验证、数据格式处理等相关)
- 开发工具相关(常用工具类、工具包、Lombok)
[TOC]
后台开发技巧
【1】用户登录说明
针对用户在不同的客户端登录或不同用户在同一客户端登录的情况作分析讨论
问题说明:在如果在同一个浏览器下只有一个用户登录的情况,在服务端可以使用 Session 存储用户登录信息。但是在项目中如果需要在同一个浏览器下允许多个不同的用户登录,这样做会存在问题,因为服务端区分不同用户是通过 Cookie 中存储的 JSESSIONID 区分的,如果 JSESSIONID 相同,那么他们在服务端将会使用同一个 Session 对象。而同一浏览器使用的 Cookie 是相同的, 从而 JSESSIONID 也是相同的,无法区分不同的用户。当浏览器登录第一个用户后,用户信息写入到 Session 中,第二个用户登录时,将会覆盖第一个用户的登录信息。
参考解决方法:不再依赖 Tomcat 默认的 JSESSIONID 来标识客户端,每进行一次登录后,服务端根据用户信息生成一份令牌,一份写入到数据库中并设置有效时间与身份信息存储在一起,定时清除,另一份返回到客户端。这个令牌可以放到页面的某个隐藏域中,但是不能存放在 Cookie 内,因为这样还是不能唯一区分用户。接下来客户端每次访问服务端都带上该令牌,以供校验身份信息,根据令牌的值,在数据库中找到对应的身份信息。这样就能区分同一浏览器下登录的不同用户了。校验通过后,再将此令牌返回给客户端,以供其下次访问使用。为防止令牌被盗用,尽量使用 Https。
参考链接:
- Java实现基于token认证
- Web基础-Token
- 了解cookie、session、token
- Web项目防止同一账号在不同session下重复登录
- java web实现同一账号在不同浏览器不能同时登录
a.不同用户在同一个浏览器登录问题
方式1:允许不同用户在同一个浏览器中先后登录。即后面登录的用户会覆盖前一个登录的用户信息,但是需要触发页面进行主动刷新,否则页面显示很不友好(前面的用户明明被挤掉但还是能够访问到信息,无意识下访问的是后登陆的用户信息),可考虑前端通过“轮询”方式每隔一段时间向后台发出请求进行验证,验证当前登录用户是否被挤下线
方式2:不允许不同用户在同一个浏览器中同时登录。即如果一个用户在一个浏览器中登录,则其想直接访问登录页面再次进行登录时,后台会验证当前是否存在登录用户,随后重定向到主页面,不让其新开登录窗口。除非用户退出登录,此时即可访问登录页面重新执行登录操作。(即后台验证当前浏览器请求数据,如果存在已登录且有效的用户信息则直接重定向到主页面)
b.同一个用户在不同浏览器登录问题
针对用户登录信息保存,需要用同一个容器去存储用户的登录信息,并在这个容器范围内进行判断。此前陷入误区利用JFinal的controller的getsession()去获取内容,发现无法替换同一用户重复登录的情况,原因是针对不同浏览器请求后台根据getsession()获取到的数据sessionId是不同的,就算对象的内容一致但后台还是会辨认为不同的对象(除非重写指定Model对应的equals和hashCode方法),从而允许同一个用户在不同浏览器同时登录从而导致出错。
因此可借助JFinal的CacheKit(缓存操作工具类)进行操作,该缓存在服务器开启期间有效,当用户登录后随即调用CacheKit的put方法保存登录用户信息,获取登录用户信息则用get方法,移除数据则用remove方法
c.登录拦截器设定
针对“浏览器直接访问页面,能够直接访问,session清除有页面显示但无数据加载”的情况需要前后端结合验证
相应地,设置登录拦截器,当前端调用相关接口的时候验证当前是否存在登录用户信息,如果存在则放行,如果不存在则返回提示信息让用户执行登录操作。此处亦可借助拦截器进行控制,如果页面请求失败,则直接跳转到自定义的404,或者是强制登录页面
【2】后台数据处理-多级分类构建
构建多级分类:
1.创建树结构和原数据实体
2.调用方法获取递归封装树形结构
3.controller测试:获取所有数据,调用封装方法随后进行测试
参考链接:https://www.jb51.net/article/125076.htm
a.基本树结构
说明:Tree为树形结构定义,后续可根据实际需求扩展节点属性,例如借助一个普通的“菜单”节点可包括nodeId(节点id)、nodeName(节点名称)、parentId(父级节点id)、nodeURL(访问URL)、nodeIcon(节点图标)、checked(节点是否选中)、chkDisabled(节点是否禁用)、isLeaf(是否为子节点)等属性,可参考前端引用的树形菜单插件进行设置,结合要扩展的功能完成属性设置
/**
* 类名称:Tree(节点Model定义,后续可根据需求相应扩展节点属性定义)
* 类描述:树形结构(构造多级分类树结构)
*/
public class Tree {
private String id;
private String pId;
private String name;
}
b.树形构造工具类
说明:树形构造工具类,通过“递归”的方式封装传入的List<Tree>集合,返回相应的树状集合List<Object>供前端引用(结合前端菜单插件进行调用,例如此处使用的是ztree插件,则参考ztree插件封装JSON数据的格式)
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import com.dada.manager.entity.Tree;
// 递归构造树型结构
public class MenuTreeUtil {
public static Map<String,Object> mapArray = new LinkedHashMap<String, Object>();
public List<Tree> menuCommon;
public List<Object> list = new ArrayList<Object>();
public List<Object> menuList(List<Tree> menu){
this.menuCommon = menu;
for (Tree x : menu) {
Map<String,Object> mapArr = new LinkedHashMap<String, Object>();
// 最高级节点(设定最高级节点数据的父节点ID-定义为常量数据)
if(x.getpId().equals("-1")){
mapArr.put("id", x.getId());
mapArr.put("name", x.getName());
mapArr.put("pid", x.getpId());
mapArr.put("childList", menuChild(x.getId()));
list.add(mapArr);
}
}
return list;
}
public List<?> menuChild(String id){
List<Object> lists = new ArrayList<Object>();
for(Tree a:menuCommon){
Map<String,Object> childArray = new LinkedHashMap<String, Object>();
if(a.getpId().equals(id) ){
childArray.put("id", a.getId());
childArray.put("name", a.getName());
childArray.put("pid", a.getpId());
childArray.put("childList", menuChild(a.getId()));
lists.add(childArray);
}
}
return lists;
}
}
c.Controller层调用
@RequestMapping("/getTree")
@ResponseBody
public ResponseEntity<ResultManage> getTree() {
MenuTreeUtil menuTree = new MenuTreeUtil();
List<AuthorityInfo> authorityList = authorityInfoService.listAuthorityInfo(null);
Map<String, Object> resultMap = new HashMap<>(4);
// 结合业务需求查找树形结构
List<Tree> treeNodes = new ArrayList<>(authorityList.size());
for (AuthorityInfo authorityInfo : authorityList) {
Tree node = new Tree();
node.setId(authorityInfo.getAuthorityId());
node.setpId(authorityInfo.getParentId());
node.setName(authorityInfo.getAuthorityName());
treeNodes.add(node);
}
List<Object> menuList = menuTree.menuList(treeNodes);
// 将数据转换成对应的json字符串形式
resultMap.put("list", menuList);
return getJsonResult(resultMap);
}
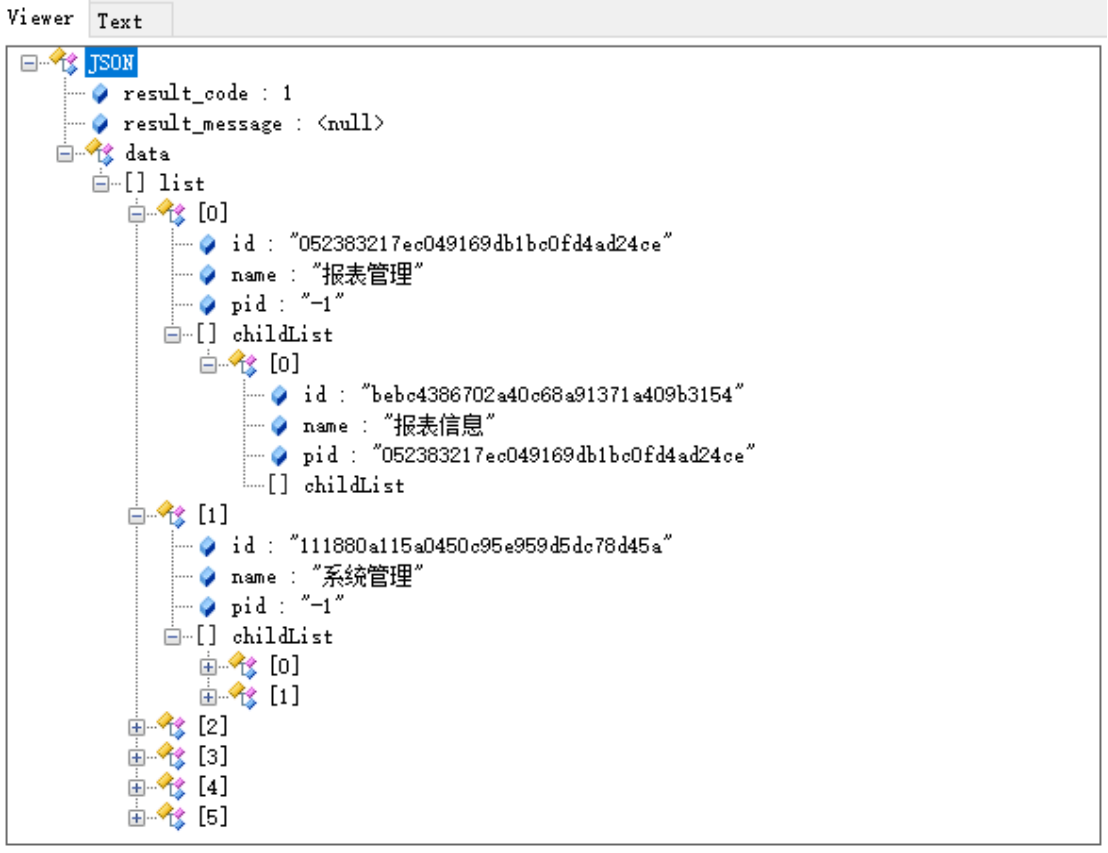
【3】动态菜单实现
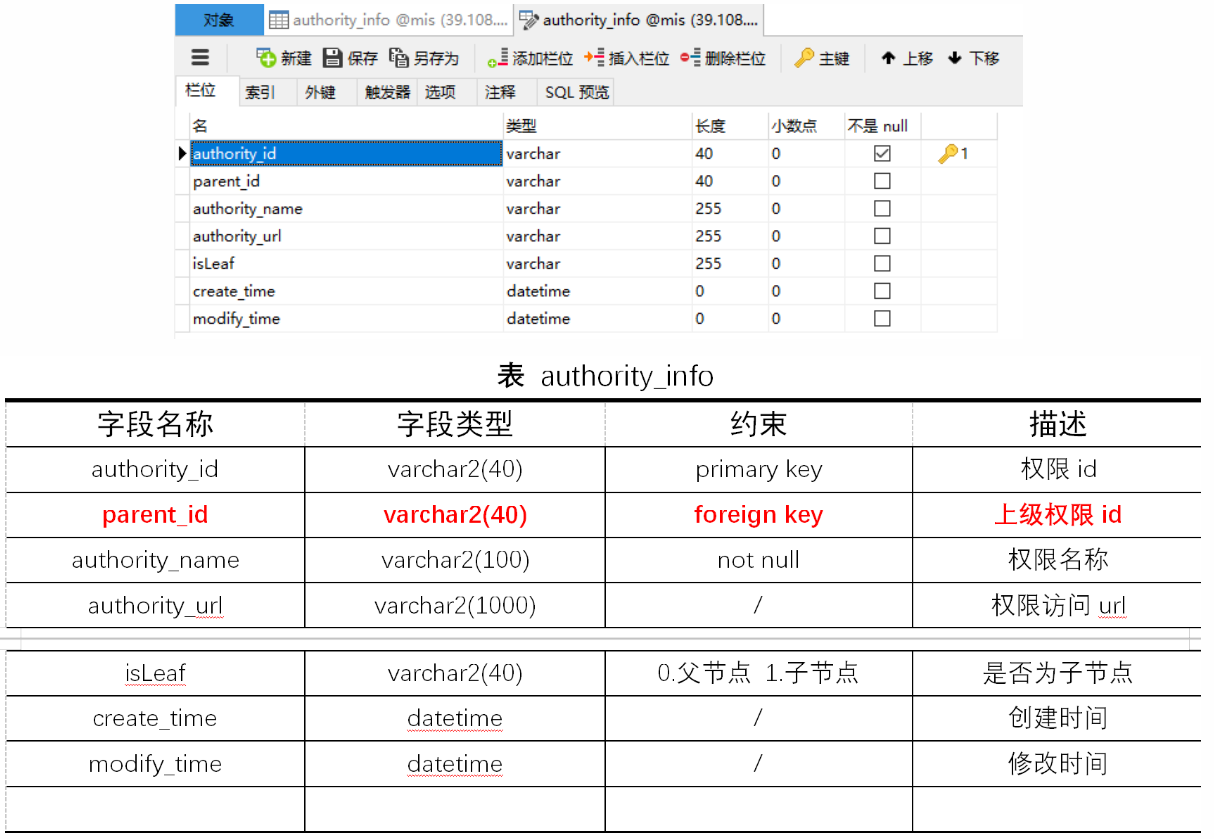
a.数据库设计
authority_info表主要用于存储菜单信息(权限信息),其具体设计如下表所示。其中authority_id作为主键,且权限之间设定了上下级关联关系(多级权限管理)。每个用户对应一个角色,而每个角色对应相应的多个不同的菜单访问权限
b.后台代码设计说明
如若仅仅只是反显多级菜单之间的联系,则可参考上述“多级分类构建”的调用过程,将数据封装成树状菜单即可。但若需要结合用户角色实现,则需考虑实际情况下用户当前所属角色能够访问的菜单,因此涉及到菜单、权限限定。其基本思路均是理清角色与权限之间的关系并确定后台与前端交互的数据格式。
结合多级分类插件反显数据:例如ztree的树状菜单插件均提供了属性实现菜单数据封装,后台只需要提供相关的数据、设定好基本属性值直接代入到其中便可方便实现。但针对自定义多级菜单:可以考虑通过循环遍历、递归等方式封装js代码,在页面加载时封装菜单数据。两种实现方式各有千秋,实际则可参考项目需求选择不同的方式实现
- 应用场景举例说明:
应用场景1:权限信息反显(结合ztree插件实现多级分类菜单反显)
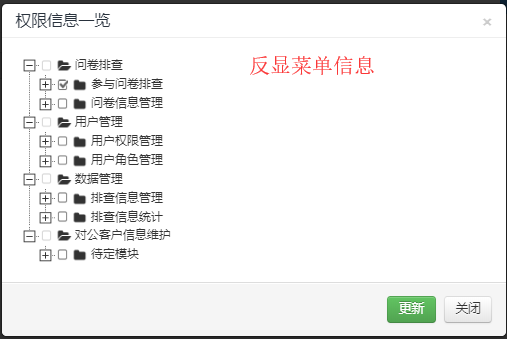
限定子级结构:权限菜单设置(针对用户角色的权限信息,只给子级的菜单设置多选框,只存储用户选中的最低一级的菜单信息)
chkDisabled:默认false表示复选框可用,true表示复选框禁用
checked:默认false表示复选框默认不选中,true表示复选框默认选中
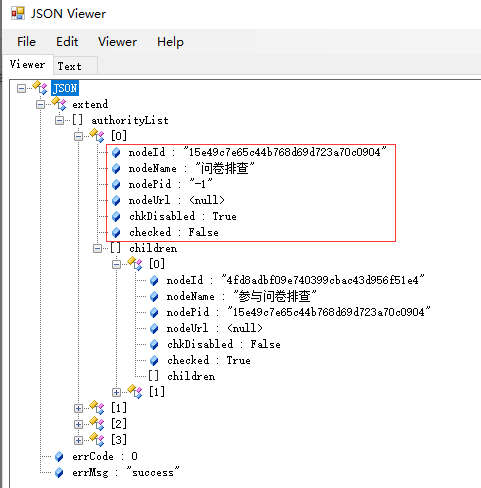
其返回的节点数据均可参考ztree官方文档,由前后端约定后进行配置
参考ztree学习网站:http://www.treejs.cn/v3/main.php#_zTreeInfo
应用场景2:根据用户角色不同的访问权限封装左侧菜单数据
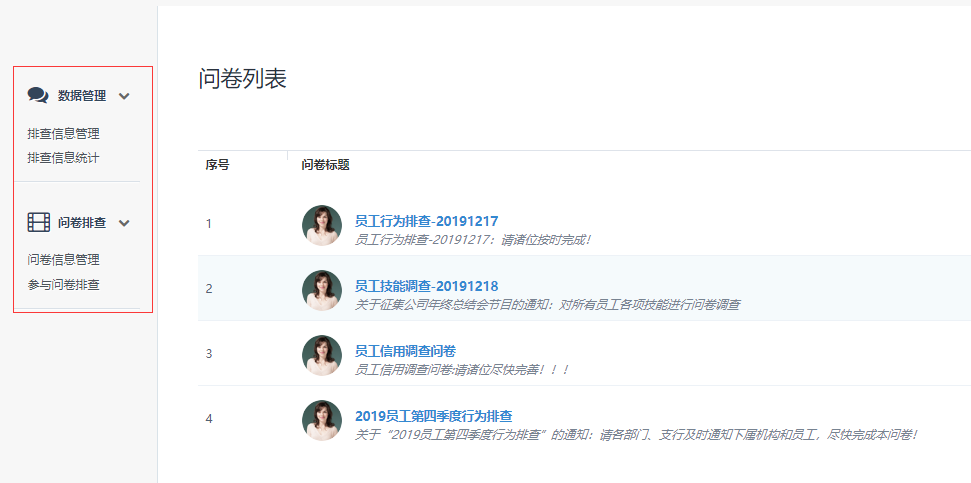
后台需要根据当前登录用户角色确定权限列表,随后依据前端指定数据格式返回列表信息,实际节点字段属性和返回数据的格式则倾向考虑前端如何自定义封装菜单方便
c.自定义多级菜单前端代码参考
(1)参考html代码片段

(2)参考js代码片段
方式1:通过拼接字符串填充HTML片段

方式2:通过DOM操纵节点数据实现属性填充

d.结合ztree树状菜单封装数据前端代码参考
(1)引入ztree相关js、css

(2)定义容器存放ztree数据

(3)定义js代码加载节点数据
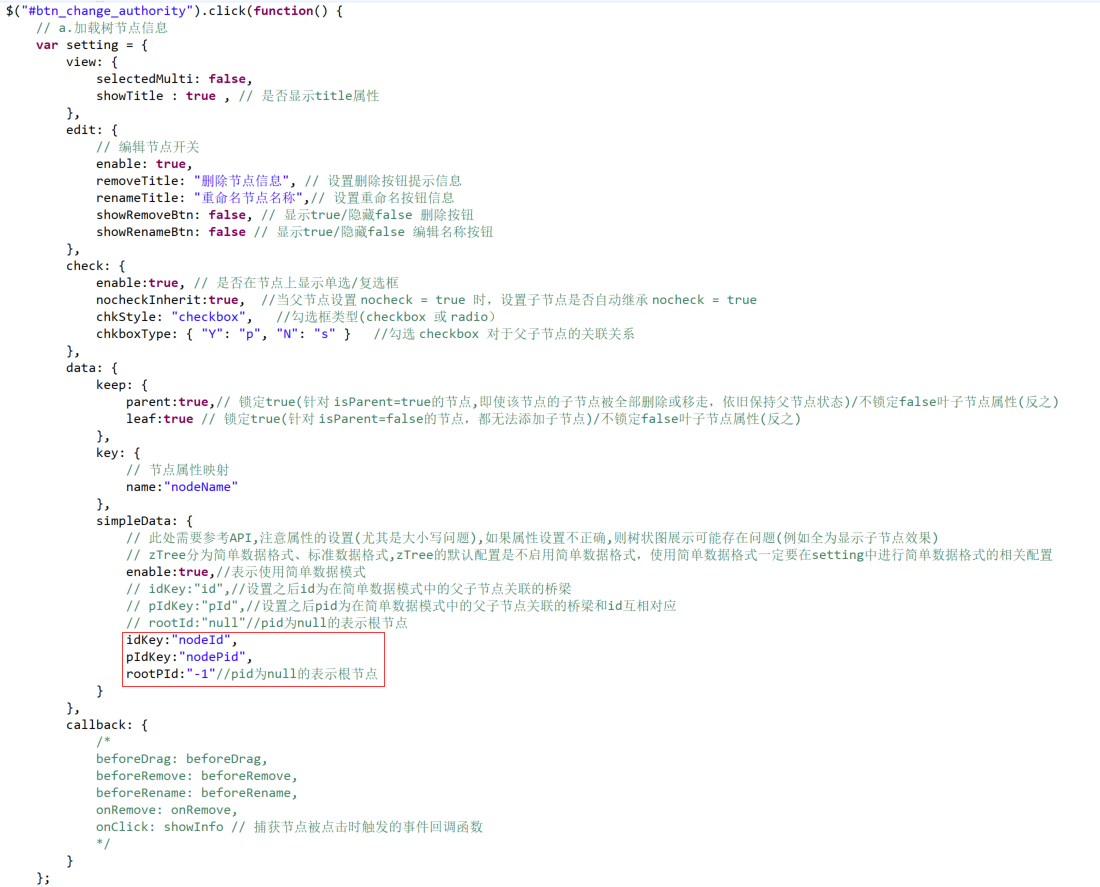

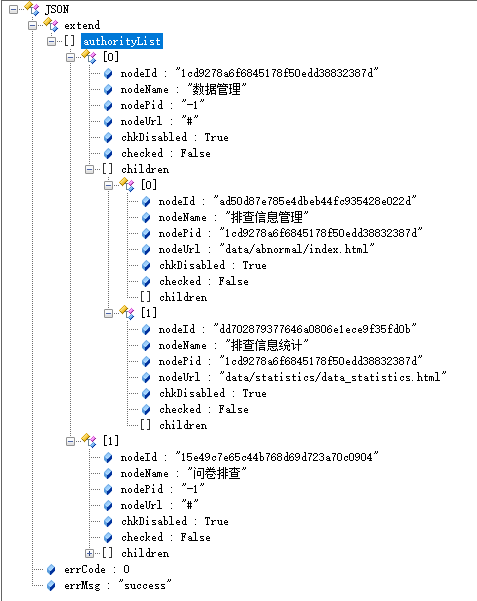
e.多级菜单返回json数据参考
f.前后端分离开发动态菜单
参考学习链接:前后端分离开发动态菜单、JAVA实现用户的权限管理
动态菜单(即不同用户登录成功后会看到不同的菜单项):后端做权限控制,前端提高用户体验,不能依靠前端展示或者隐藏一个按钮来实现权限控制,这样肯定是不安全的。例如用户注册时需要输入邮箱地址,需要前后端进行校验,前端校验是为了提高响应速度以优化用户体验,后端校验则是为了确保数据完整性。权限管理也是如此,前端按钮的展示/隐藏都只是为了提高用户体验,真正的权限管理需要后端来实现。做前后端分离开发中的权限管理,首先要建立合适的思考框架,然后再去考虑其他问题。
下述参考网上资料说明两种方式实现动态菜单(展示动态菜单):
方式1:后端动态返回
参考案例:“微人事”权限管理相关的表一共有五张表,如下:
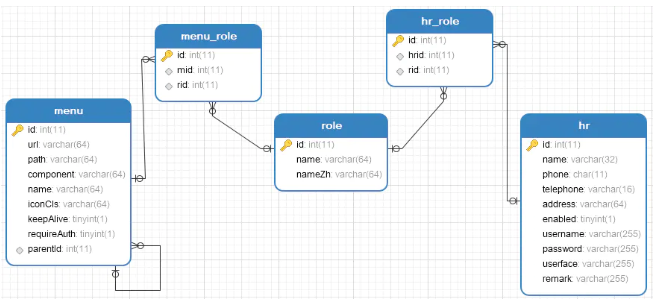
其中 hr 表就是用户表,用户登录成功之后,可以查询到用户的角色,再根据用户角色去查询出来用户可以操作的菜单(资源),然后把这些可以操作的资源,组织成一个 JSON 数据,返回给前端,前端再根据这个 JSON 渲染出相应的菜单。以微人事为例返回的 JSON 数据格式如下:

返回的JSON由前端根据实际展示需求进行二次处理后进行回显,这种方式的一个好处是后台进行sql语句操作以简化前端的判断逻辑。另外这种方式还有一个优势就是可以动态配置资源-角色以及用户-角色之间的关系,进而调整用户可以操作的资源(菜单)。
方式2:前端动态渲染
前端动态渲染可针对权限关系较为简单的系统,这种方式将逻辑处理交由前端以简化后台操作。其主要是直接在前端把所有页面都在路由表里边定义好,然后在 meta 属性中定义每一个页面需要哪些角色才能访问,如下所示:

上述定义表示当前登录用户需要具备 admin 或者 user 角色,才可以访问 EmpBasic 组件。其主要实现思路:meta定义只是一个标记,在项目首页中,会先遍历这个数组做菜单动态渲染,然后根据当前登录用户的角色并结合当前组件需要的角色,来决定是否把当前组件所对应的菜单项渲染出来。
这种实现方式下后端只需要在登录成功后返回当前用户的角色就可以了,剩下的判断逻辑则交前端。不过这种方式有一个弊端就是菜单和角色的关系在前端代码中写死了,以后如果想要动态调整则可能需要调整代码。由其不推荐在大项目或者是权限比较复杂的时候使用
说明:
在传统的前后端不分离的开发中,权限管理主要通过过滤器或者拦截器来进行(权限管理框架本身也是通过过滤器来实现功能),如果用户不具备某一个角色或者某一个权限,则无法访问某一个页面。在前后端分离中,基本理念便是页面的跳转统统交给前端去做,后端只提供数据。但是权限管理不能再按照之前的思路来,首先要明确一点——“数据安全不能依靠前端”,前端是展示给用户看的,所有的菜单显示或者隐藏目的不是为了实现权限管理,而是为了给用户一个良好的体验,不能依靠前端隐藏控件来实现权限管理。这点就像普通的表单提交一样,前端做数据校验是为了提高效率,提高用户体验,后端才是真正的确保数据完整性。
因此,真正的数据安全管理是在后端实现的,后端在接口设计的过程中,就要确保每一个接口都是在满足某种权限的基础上才能访问,也就是说,不怕将后端数据接口地址暴露出来,即使暴露出来,只要你没有相应的角色,也是访问不了的。
前端为了良好的用户体验,往往需要将用户不能访问的接口或者菜单隐藏起来。如果用户直接在地址拦输入某一个页面的路径,怎么办?此时,如果后台没有做任何额外的访问处理的话,用户确实可以通过直接输入某一个路径进入到系统中的某一个页面中,但是,后台可限定必须指定角色方可访问相关的接口,以遏制数据泄露问题。
为提升用户体验,可以使用 Vue 中的前置路由导航守卫,来监听页面跳转,如果用户想要去一个未获授权的页面,则直接在前置路由导航守卫中将之拦截下来,重定向到登录页,或者直接就停留在当前页,不让用户跳转,并给用户展示未获授权的提示信息(可由后端拦截器间接实现)。
由上述可知,在权限管理模块设计中,前端侧重提高用户体验,后端实现权限校验,常用参考框架结合:SSM 架构+ Shiro框架 、 Spring Boot + 微服务+ Spring Security框架
【4】常量维护-“数据字典”
a.数据字典说明
数据字典Data Dictionary是一种通用的程序设计方法,是指对数据的数据项、数据结构、数据流、数据存储、处理逻辑等进行定义和描述,其目的是对数据流程图中的各个元素做出详细的说明,使用数据字典为简单的建模项目。简而言之,数据字典是描述数据的信息集合,是对系统中使用的所有数据元素的定义的集合
举例:职员“证件类型”(证件类型包含多个不同属性),普通实现方式:
| 职员信息 | ||
|---|---|---|
| 姓名 | 证件类型 | 证件号码 |
| 张三 | 身份证 | 0001 |
| 李四 | 港澳通行证 | 0002 |
针对上述案例,数据字典的实现方式有两种:
方式1:把主体的属性代码化放入独立的表中,不是和主体放在一起,主体中只保留属性的代码。这里属性的数量是不变的,而属性取值的数量可以是变化的
| 职员信息 | ||
|---|---|---|
| 姓名 | 证件类型ID | 证件号码 |
| 张三 | 身份证 | 0001 |
| 李四 | 港澳通行证 | 0002 |
| 证件表 | |
|---|---|
| 证件类型ID | 证件类型 |
| 01 | 身份证 |
| 02 | 港澳通行证 |
| 03 | 台湾通行证 |
此方法局限性在于“属性”难以扩展,每增加一个属性便关联一个数据表,资源消耗较大,随着系统复杂程度扩展,后期维护也较为困难
方式2:用一个表来放结构相同的所有属性信息,不同属性的不同取值统一编码,用“类型”来区别不同的属性,主体中保留属性代码的列表。此举更具一般性、通用性
| 系统代码分类表 | |
|---|---|
| 分类标识 | 分类名称 |
| 01 | 证件类型 |
| 02 | 国籍 |
扩展“属性”概念,每一条分类数据代表某个“属性”,可根据实际需求无限进行扩展和维护
| 系统代码表 | ||
|---|---|---|
| 代码标识 | 所属分类(对应分类标识) | 内容 |
| 001 | 01 | 身份证 |
| 002 | 01 | 港澳通行证 |
| 003 | 01 | 台湾通行证 |
| 004 | 02 | 中国 |
| 005 | 02 | 美国 |
| … | … | … |
《系统代码表》的“分类”字段都指向《系统代码分类表》中的“分类标识”。这样,在程序需要获得某个属性列表时,只要通过特定标识去《系统代码表》中检索就可以了,此举便于建立一个单独的程序模块来维护所有的这些公共信息,日后就算数据库内容变更也不影响程序逻辑
数据字典的优势:
1.在一定程度上,通过系统维护人员即可改变系统的行为(功能)。使得系统的变化更快,能及时响应客户和市场的需求;提高了系统的灵活性、通用性,减少了主体和属性的耦合度;
2.简化了主体类的业务逻辑;
3.能减少对系统程序的改动,使数据库、程序和页面更稳定。特别是数据量大的时候,能大幅减少开发工作量;
4.使数据库表结构和程序结构条理上更清楚,更容易理解,在可开发性、可扩展性、可维护性、系统强壮性上都有优势
b.通用数据字典的设计模式
| 字段名 | 类型 | 说明 |
|---|---|---|
| 编号 | char(16) | 间断增量(Not Null,PK) |
| 分类名称 | varchar(64) | 用来进行过滤选取字典表相关域 |
| 内容 | varchar(255) | 数据内容 |
| 父级编号 | char(16) | 取Dictionary的编号(FK),用来进行等级设计,使之成为树型结构 |
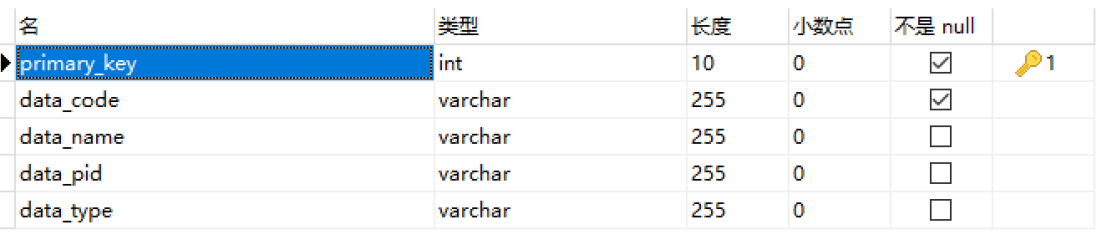
// 获取根据数据类型获取数据工具类可参考下述代码:
package util;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import entity.StaticData;
class DataUtil {
public static Map<String,Object> mapArray = new LinkedHashMap<String, Object>();
public List<Tree> menuCommon;
public List<Object> list = new ArrayList<Object>();
public List<Object> menuList(List<Tree> menu){
this.menuCommon = menu;
for (Tree x : menu) {
Map<String,Object> mapArr = new LinkedHashMap<String, Object>();
// 最高级节点
if(x.getpId().equals("-1")){
mapArr.put("nodeId", x.getId());
mapArr.put("nodeName", x.getName());
mapArr.put("nodePid", x.getpId());
mapArr.put("children", menuChild(x.getId()));
list.add(mapArr);
}
}
return list;
}
public List<?> menuChild(String id){
List<Object> lists = new ArrayList<Object>();
for(Tree a:menuCommon){
Map<String,Object> childArray = new LinkedHashMap<String, Object>();
if(a.getpId().equals(id) ){
childArray.put("nodeId", a.getId());
childArray.put("nodeName", a.getName());
childArray.put("nodePid", a.getpId());
childArray.put("children", menuChild(a.getId()));
lists.add(childArray);
}
}
return lists;
}
}
public class StaticDataGenerator {
// insert into static_data(data_code,data_name,data_pid) select code,name,pid from industry
public static Map<String, Object> getStaticData(String type,String oper) {
String sql = "select * from static_data where data_type like '%"+type+"%'";
List<StaticData> dataList = StaticData.dao.find(sql);
DataUtil menuTree = new DataUtil();
Map<String, Object> resultMap = new HashMap<>(4);
if("0".equals(oper)) {
// 结合业务需求查找树形结构
List<Tree> treeNodes = new ArrayList<>(dataList.size());
for (StaticData data : dataList) {
Tree node = new Tree();
node.setId(data.getStr("data_code"));
node.setName(data.getStr("data_name"));
node.setpId(data.getStr("data_pid"));
treeNodes.add(node);
}
List<Object> menuTreeList = menuTree.menuList(treeNodes);
// 将数据转换成对应的json字符串形式
resultMap.put("dataList", menuTreeList);
}else if("1".equals(oper)) {
List<String> nameList = new ArrayList<String>(dataList.size());
for (StaticData data : dataList) {
nameList.add(data.getStr("data_code")+"-"+data.getStr("data_name"));
}
// 将数据转换成对应的json字符串形式
resultMap.put("dataList", nameList);
}
// System.out.println(JSON.toJSONString(resultMap));
return resultMap;
}
}
返回前端封装数据可参考:
单级下拉框数据封装(字符串列表):
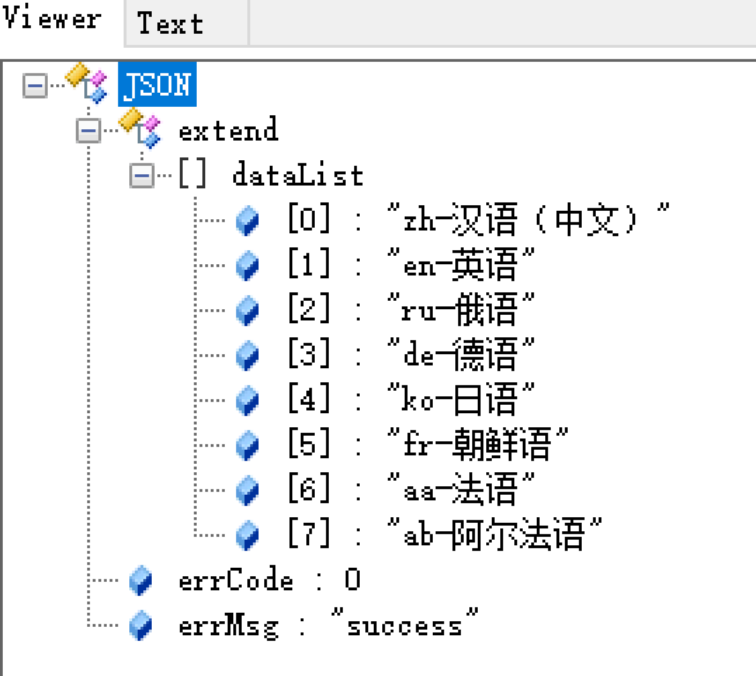
多级下拉框数据封装(树状结构):
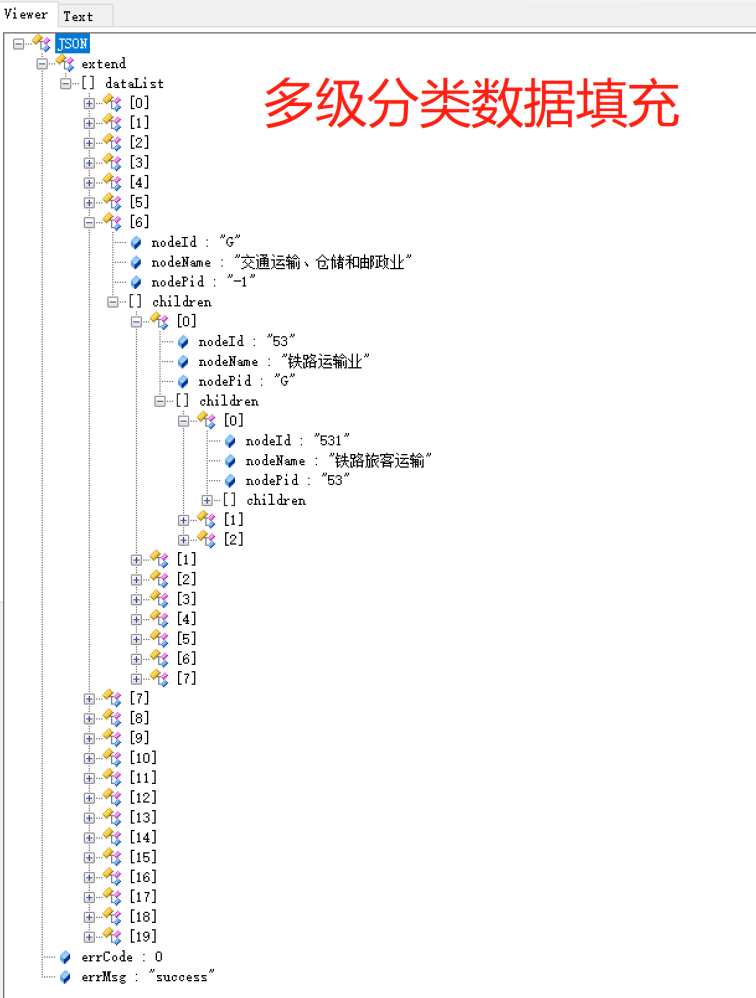
常用数据库sql参考:
获取指定第一级的子节点数据:
select sdc.data_code
from static_data_copy sdc
where data_type='行业类型' and data_pid = '-1'
如果需要获取第n级的节点数据,则可通过嵌套查询
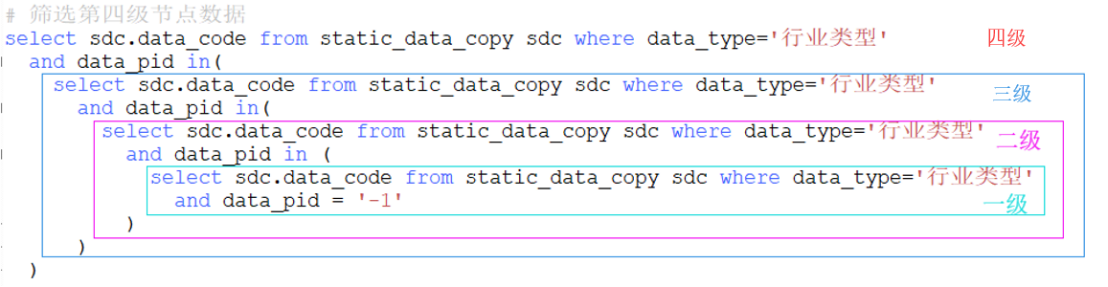
将某一节点和其子节点数据对应起来,如果其没有子节点则cid(子节点)为null,查询成功可灵活为其添加子节点,但需要注意的是不管如何绝不允许子节点和父节点编号相同,否则在构建树形数据的时候会抛出“内存溢出”问题,原因在于在递归构建树形数据的时候会出现死循环操作而造成java内存溢出
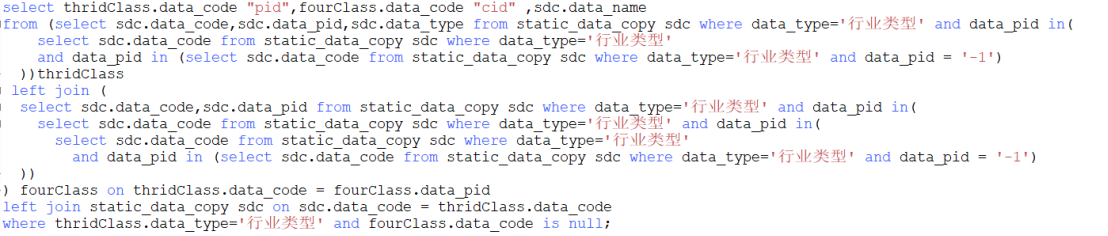
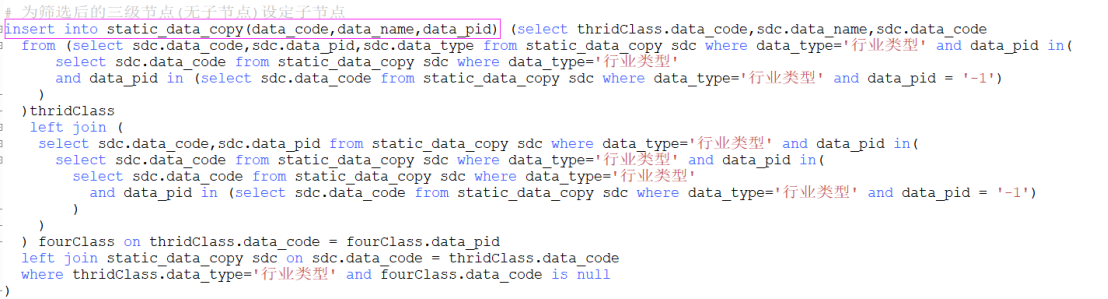
因此,在构建多级下拉框数据的时候,后台可借助递归封装无限级数据,前台在实现的时候则可根据判断当前节点是否存在子节点,如果存在子节点则继续封装下一级数据,如果不存在子节点(子节点默认为其本身或者设置指定的值)则相应进行处理
【5】POI:Excel数据转换(导入导出)
参考学习链接:
POI+JAVA实现数据导入:https://blog.csdn.net/caicai1171523597/article/details/95454339
读取Excel指定行列数据:https://blog.csdn.net/zhufengyan521521/article/details/82871505
动态生成带下拉框的Excel模板:https://www.cnblogs.com/mingyue1818/p/6054188.html
Java Excel导入数据解析:https://blog.csdn.net/qq_24192465/article/details/80436875
excel大数据量操作工具类:https://blog.csdn.net/welan123123/article/details/83382223
POI中设置Excel单元格样式:(考虑不同版本问题)
https://www.cnblogs.com/jym-sunshine/p/4917476.html
https://blog.csdn.net/Weirdo_zhu/article/details/79912606
https://blog.csdn.net/qq_38218238/article/details/89311443
html-table数据导成excel数据:https://www.cnblogs.com/suyuanli/p/7945102.html
POI+JAVA实现excel数据导出:https://blog.csdn.net/jiankang66/article/details/89040742
POI+JAVA读取excel(包含合并单元格处理):
https://www.cnblogs.com/rain-in-summer/p/8243358.html
此处案例结合JFinal与poi的使用进行说明
a.数据导入
参考思路:
解析.xls、.xlsx后缀格式的文件数据,验证文件模板和数据
数据验证通过则批量处理数据导入
参考代码:
用户模板导入相关常量维护:

(1)Controller层
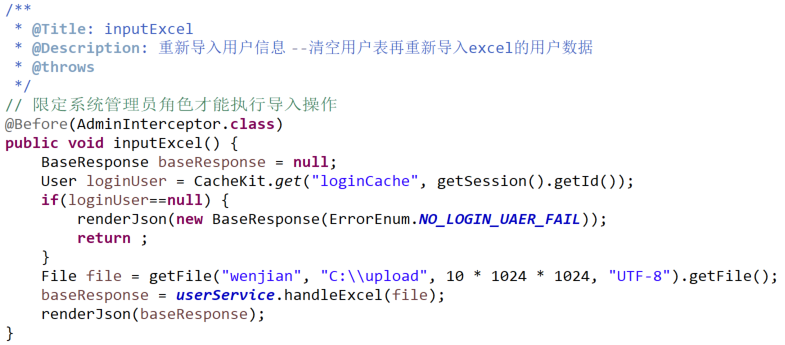
(2)Service层
# 临时文件处理(用户上传文件解析完成随即删除临时文件,避免文件服务器数据冗余)

# 用户数据处理-处理系统留存数据(重置系统)
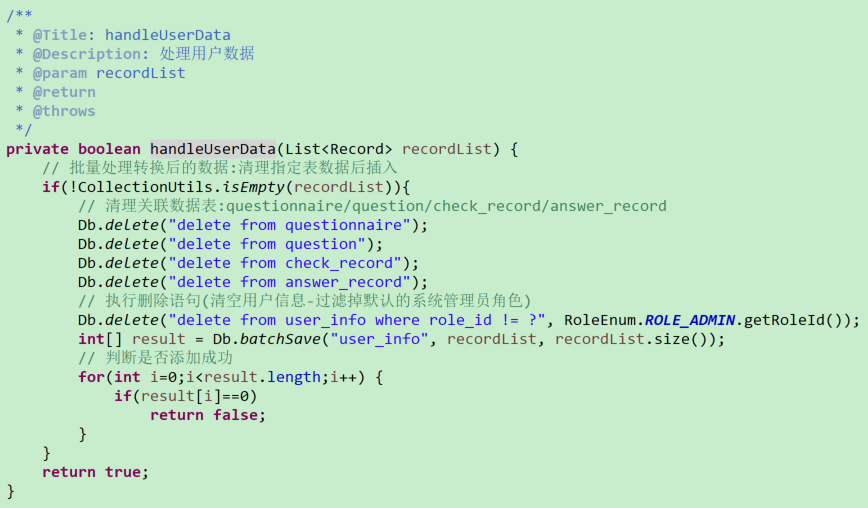
# 用户数据处理-验证用户编号、登录账号数据唯一性
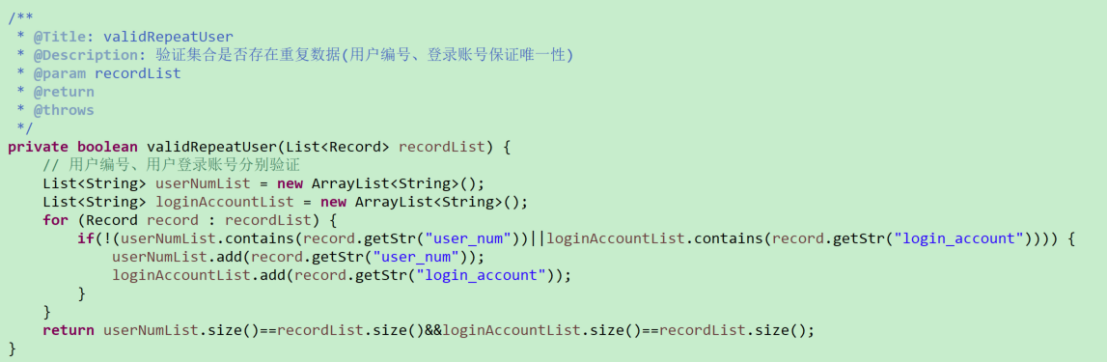
# 公有方法入口-导入模板信息(传入指定参数,处理不同的模板数据)

(3)自定义CustomExcelUtil:(定义方法处理Excel数据)
# 空行数据验证处理

# 单元格数据处理

# 合并单元格处理

# 获取指定合并单元格的值

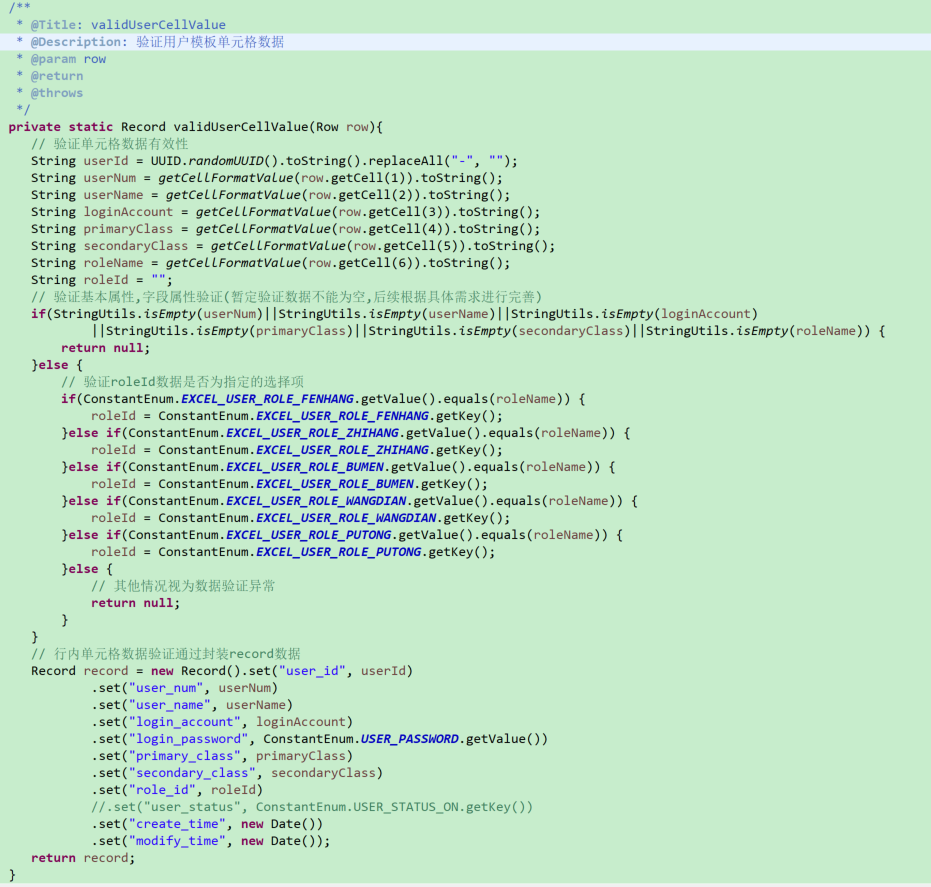
# 用户模板验证

# 问卷模板验证

# 公共方法入口1(传入指定参数,验证指定模板文件)

# 用户模板-单元格数据验证
# 问卷模板-单元格数据验证
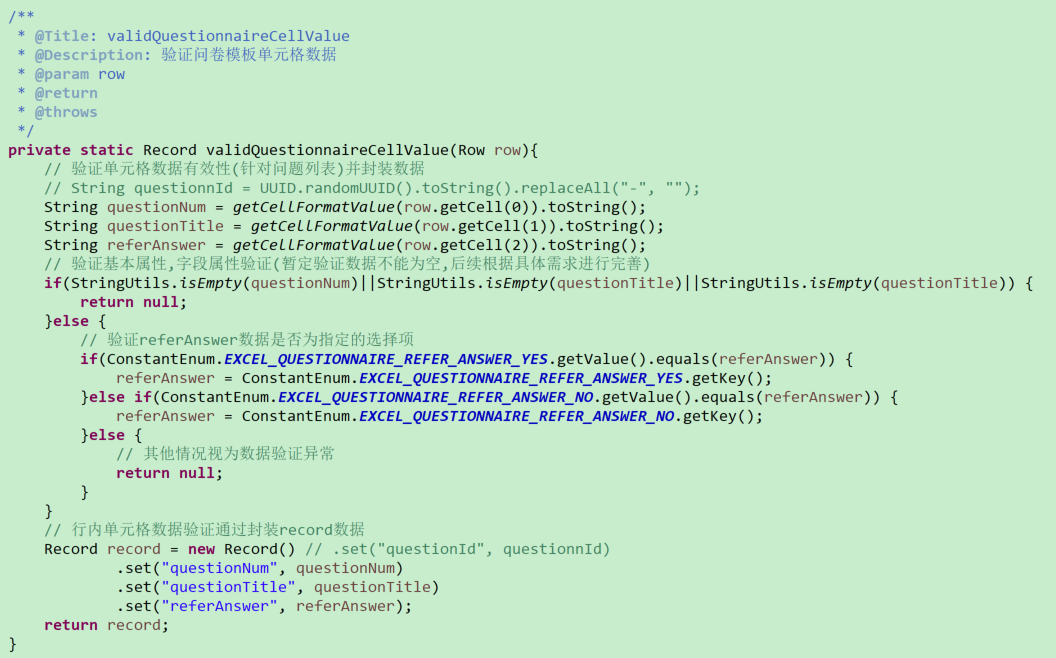
# 公有方法入口2(单元格数据验证)-传入指定参数,验证指定模板单元格数据

# 用户模板-解析模板数据(返回用户信息列表)
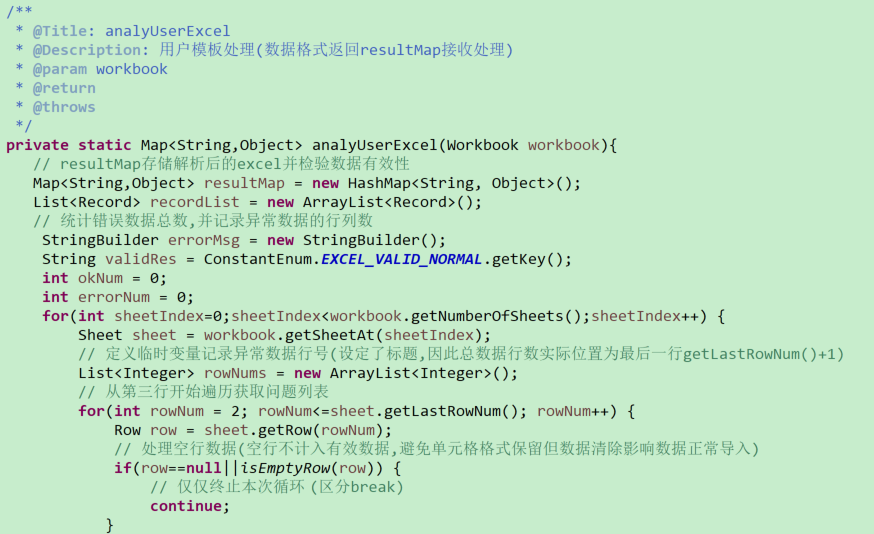

# 问卷模板-解析模板数据(返回问卷信息列表,包含问卷主体和关联问卷两个部分)


# 公有方法入口3(解析数据模板)-传入指定参数,根据需求解析不同模板格式

b.数据导出
# Excel文件生成、数据封装导出相关
(1)Controller层
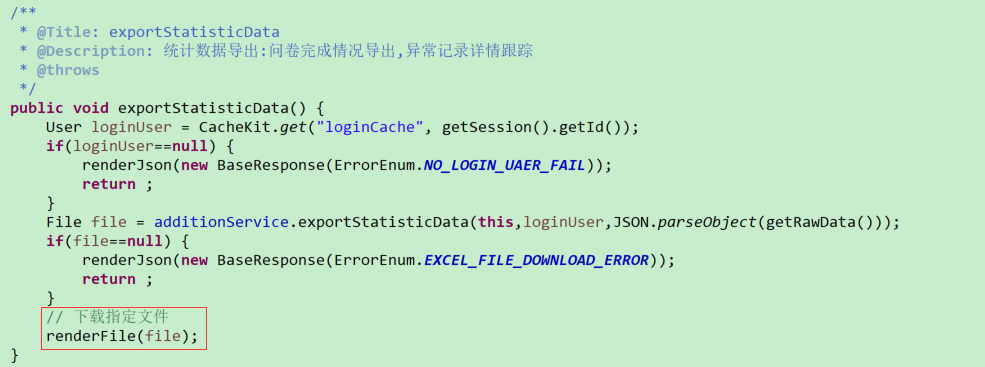
(2)Service层
针对数据导出,可能有以下两种应用场景:
其一是模板数据导出(用户需要填充的Excel模板):可以考虑将模板放置在指定的文件服务器路径,随后提供一个路径跳转下载接口,前端直接通过访问该接口直接下载数据;亦可每次用户访问的时候均动态生成一次模板文件,此处暂定生成临时文件,随后调用JFinal提供的renderFile系列方法访问临时文件进行下载,但每次下载完成均需考虑“临时文件残留”问题,需要及时清理生成的临时文件,避免长时间数据冗余
参考如下:其实现思路是设定模板标题、样式、下拉框等属性,随后调用自定义工具类方法封装模板,并写成相应的文件
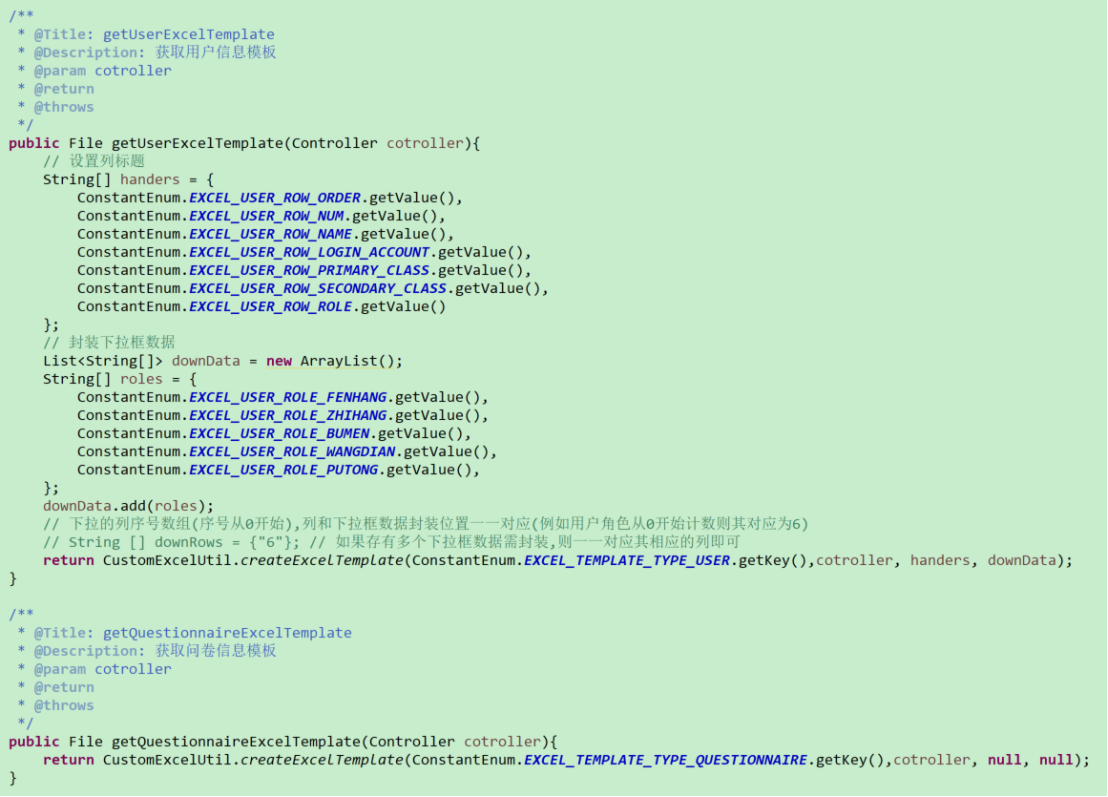
其二是指定数据导出(例如一些特定的用户、历史记录等数据):需要先生成一个模板原型,随后填充数据,参考如下:其实现思路是Service调用dao层获取数据,随后调用自定义工具类封装传入的数据
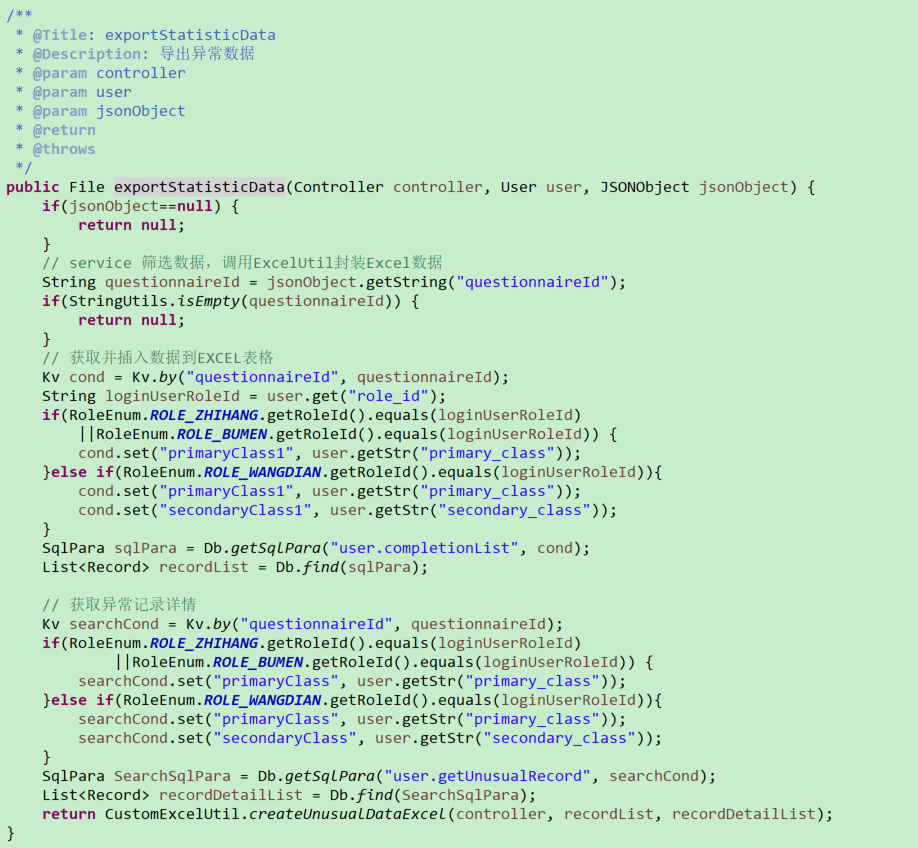
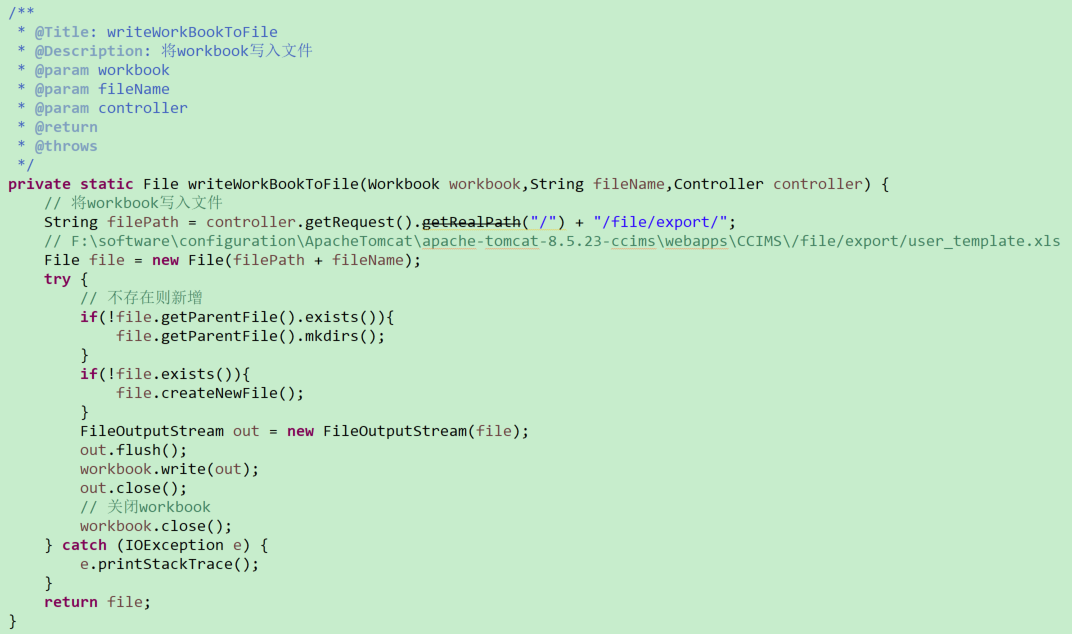
3>自定义CustomExcelUtil:(定义方法处理Excel数据)
# 公有方法-将Excel数据写入文件流
# Excel模板生成-用户模板创建

# Excel模板生成-问卷模板创建(有关合并单元格、下拉框处理)

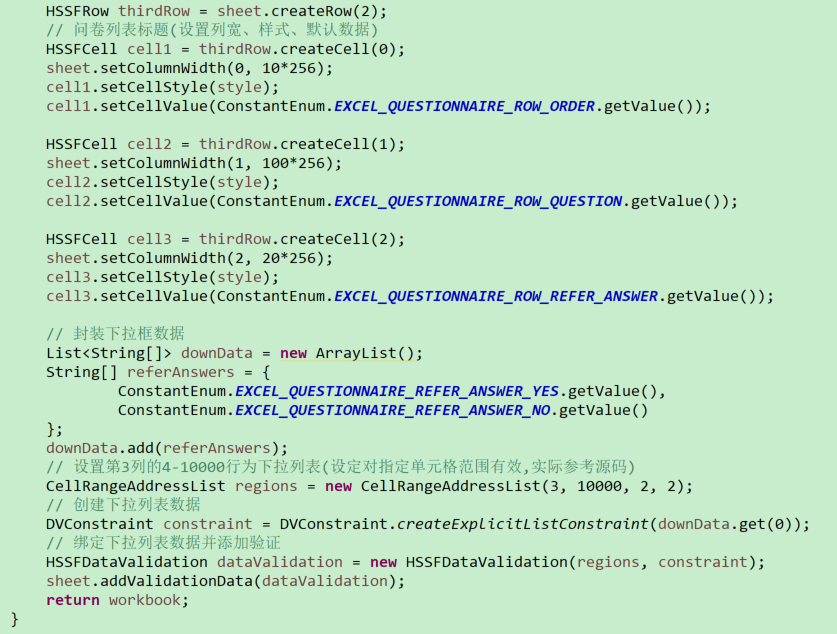
# 公有方法-创建指定Excel模板
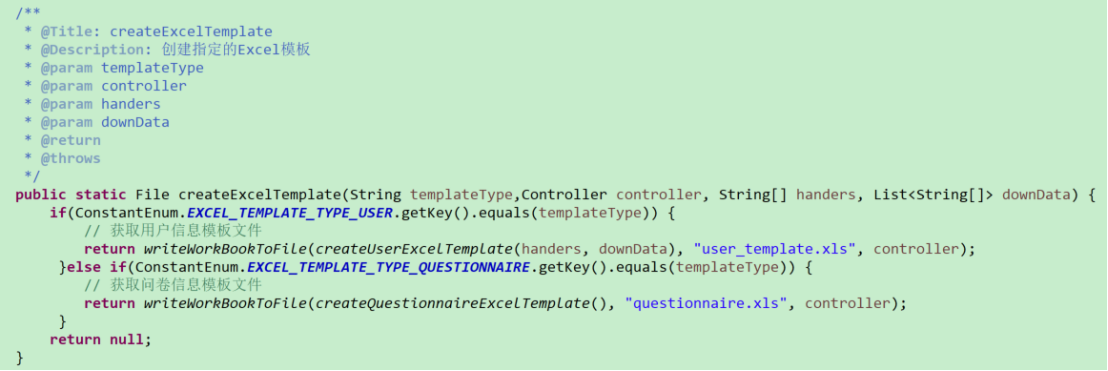
# 针对异常数据导出

c.JAVA+POI完成数据转化
(1)POI操作Excel常见问题
POI在读取文件名时读取名字中含有标点符号“.”

POI兼容07以下的Excel格式和07以上的Excel格式
处理文件格式问题:区分.xls、.xlsx两种不同后缀的处理方式
xls解析相关:HSSFWorkbook、 HSSFSheet、HSSFRow
xlsx解析相关:XSSFWorkbook、 XSSFSheet、XSSFRow



POI读取最大行数时将带格式空行读取或存在空行,导致批量导入失败
问题分析:客户端在操作单元格的时候对不在导入数据单元格范围以外的单元格也设置了格式:比如调整了行高及列宽,边框单元格属性等,实际上这些“空白内容”在数据范围外的单元格已经不是默认的格式了,所以获取的行数或列数将不正确。仅仅只是“清空了数据”,并非删除单元格,因此在统计的时候java后台调用的getLastRowNum方法还是会将数据统计进去
实际案例说明:通过getLastRowNum()获取行数,然而当客户端清空了某些行数据的时候,后台获取到的总行数仍然是原来的数据,例如100行删掉20行,本应统计80行但仍然统计100行,从而导致隐藏bug
解决方式:后台处理做限定,排除这一情况,删除空白无效的“单元格”,即选中有效数据区域外的可疑单元格--右键删除--保存即可(需注意空指针异常处理)
getPhysicalNumberOfRows()获取的是物理行数,不包括那些空行(隔行)的情况
getLastRowNum()获取的是最后一行的编号(编号从0开始,即索引)
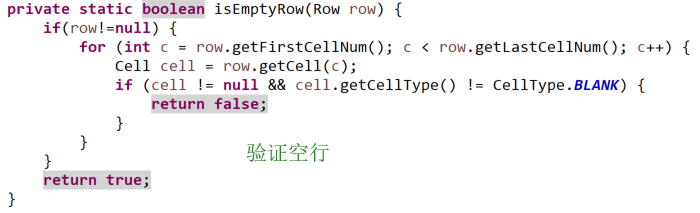
因此实际上处理的时候需要排除空白行的情况,并以最后一行所在位置作为结束节点进行判断,否则忽略中间空白行导致的行数差

参考分析:
getLastRowNum:如果sheet中一行数据都没有则返回-1,只有第一行有数据则返回0,最后有数据的行是第n行则返回 n-1(行索引);
getLastCellNum:如果row中一列数据都没有则返回-1,只有第一列有数据则返回1,最后有数据的列是第n列则返回 n(列数);
getPhysicalNumberOfRows:获取有记录的行数,即:最后有数据的行是第n行,前面有m行是空行没数据,则返回n-m;
getPhysicalNumberOfCells:获取有记录的列数,即:最后有数据的列是第n列,前面有m列是空列没数据,则返回n-m;
数据转换异常:解决POI无法同时读取带多种格式的单元格表格
使用Apache-POI读取excel文件时,往往可能遇到一些数据转换异常问题
如果获取数据的方法与实际类型不符,会抛出IllegalStateException错误,如下

解决方式1:统一转换成String格式进行处理:

解决方式2:按照不同数据格式进行自定义处理:

POI版本兼容问题
不同poi版本部分方法的调用方式可能不太一样,需要根据自身项目引用的jar版本对照相应的API进行调用,原有版本部分方法可能已经取消或者是替换成新版本的其他方法,因此在参考相关资料或实现方法的时候,要相应确认poi版本,随后进行适度调整
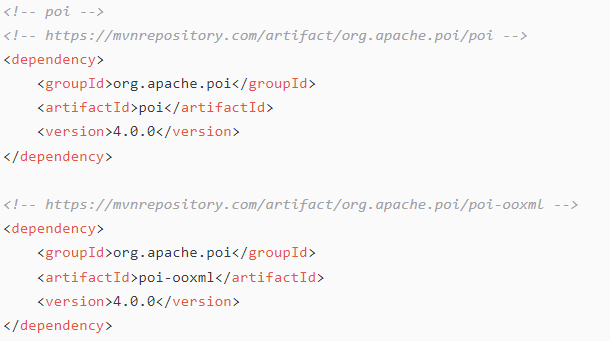
Excel文件中的数据无法正常读取(Excel文件正常上传,后台处理报错)
问题分析:excel上传报错如下,用工具导出的excel无法读取到最后一行文件,或者是参考如下错误java.lang.NoClassDefFoundError: org/apache/poi/poifs/filesystem/,可能是excel文件没有正常关闭或者是设置了访问权限,打开excel文件 重新保存
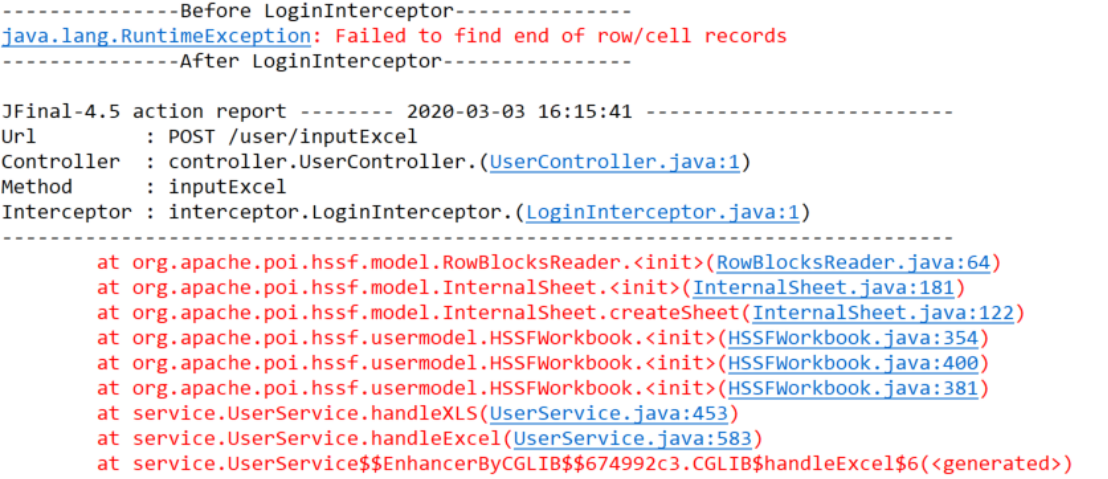
针对excel文件后缀为“.xls”的文件,部分文件打开可能存在如下问题
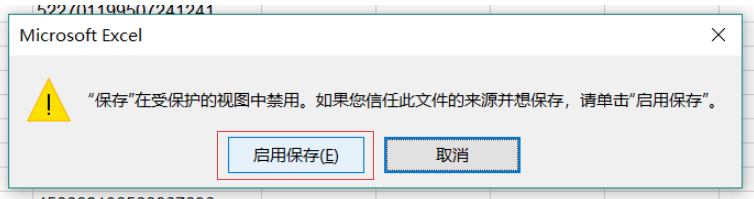
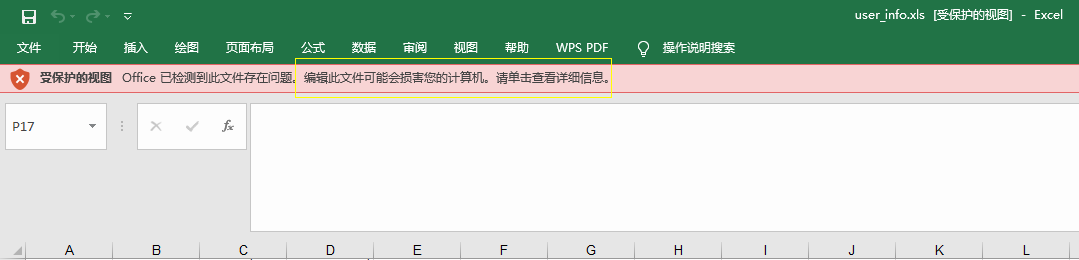
点击编辑该文件,在如下视图中选择“仍然编辑”,随后重新保存文件,再次测试
Excel数据导出列数限制(不同excel版本导出)
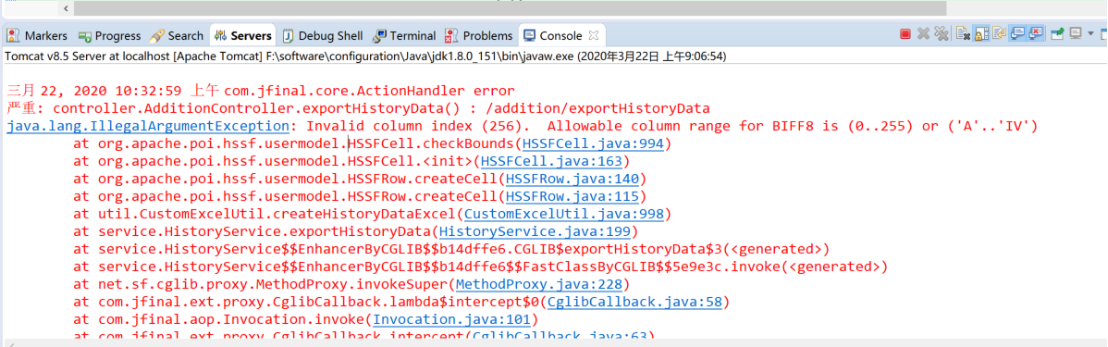
关于 NPOI 报 Invalid column index (256). Allowable column range for BIFF8 is (0..255) or ('A'..'IV') 错误的解决办法:从字面意义上理解,列数限制说法是相对于 Office 2003 的,在 Office 2007 之前,最多只可以创建 256 列;在 Office 2007 之后,扩大可创建列数限制,使用 Office 2013 实测最多可以创建 16384 列,参考网上内容,可适当调整代码:
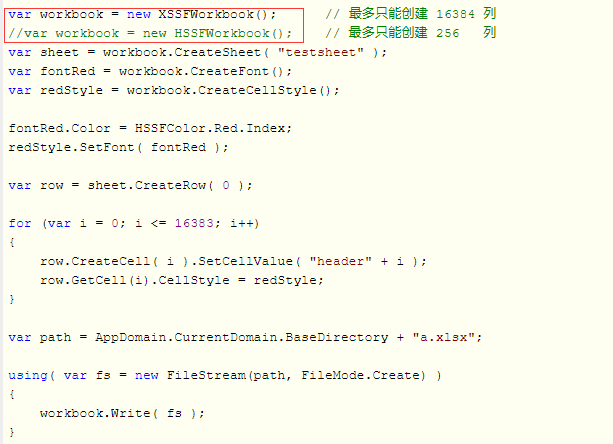
(2)POI操作Excel参考开发技巧
⚡自定义方法读取Excel文件中指定数据


⚡Java+POI设定模板下拉框相关
导出模板设定指定单元格下拉框
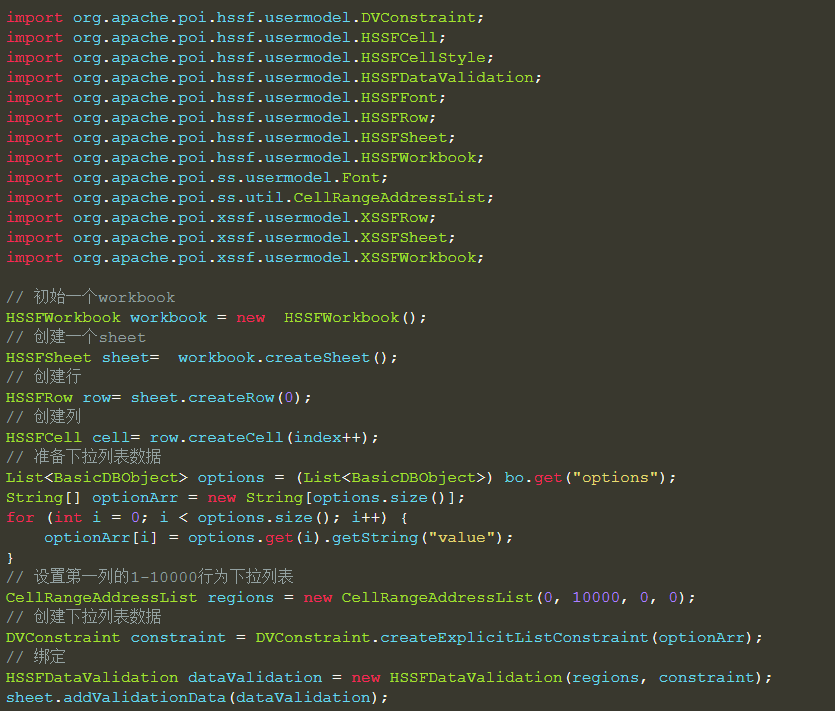
java动态生成带下拉框的Excel导入模板:
https://www.cnblogs.com/mingyue1818/p/6054188.html
常见问题:数据验证时单元格范围指定错误
CellRangeAddressList regions = new CellRangeAddressList(firstRow, endRow, firstCol, endCol);
上述方法表示从firstRow行到endRow行、firstCol到endCol列范围,因此在设置传参的时候必然需要满足firstRow<=endRow、firstCol<=endCol,否则报“越界”异常;如若需要指定某一行或者某一列只要使得firstRow=endRow或者是firstCol=endCol即可
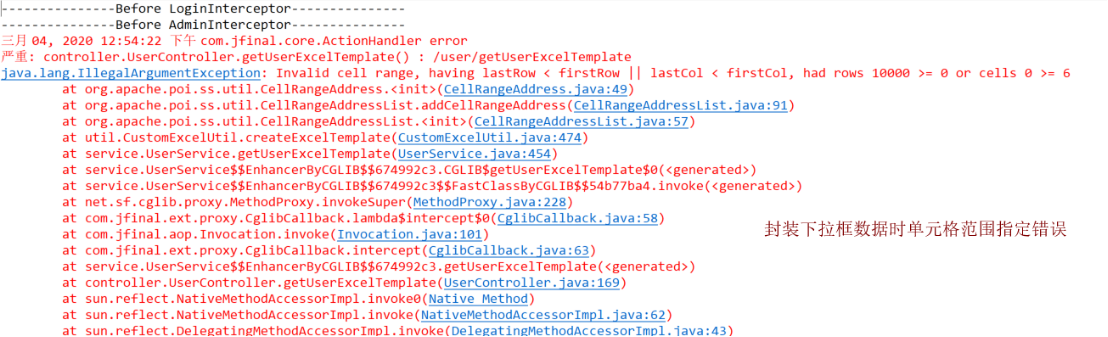
此外,针对下拉框数据列表,可以参考类似的形式将相关联的下拉框数据进行封装,放置在sheet中的某列,便于进行对照或者是后期维护参考。在实际项目的过程中有接触部分下拉框文件数据被隐藏,则可通过查看是否存在有隐藏的sheet存储了要封装的下拉框数据
获取Excel文件指定下拉框行、列的值(POI-3.17)

【6】JSON数据转换(数据库存取)
JSON:JavaScript Object Notation(JavaScript 对象表示法),其具备两种基本组成结构
键值对的无序集合{}:JSONObject对象(或者叫记录、结构、字典、哈希表、有键列表或关联数组等)

值的有序列表[]:JSONArray数组

JSON:“无序键值对”- 对象可包括多个key/value(键/值)对,其中key为字符串,value可为:null、数字(整数或浮点数)、字符串("xxx")、逻辑值(true 或 false)、数组([ ])、对象({ })
语法格式:
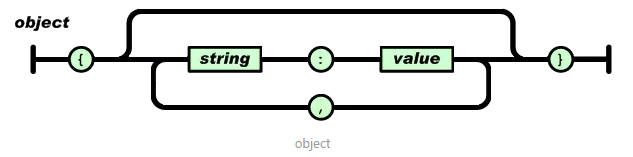
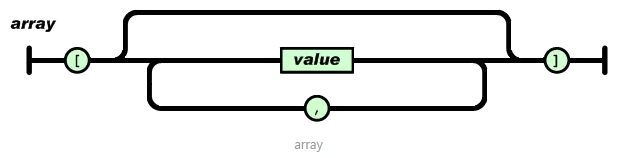
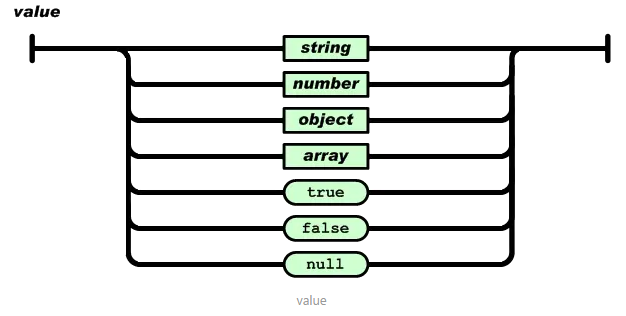
其中字符串(string)是由双引号包围的任意数量Unicode字符的集合,使用反斜线转义。一个字符(character)即一个单独的字符串(character string),因此通过JSON工具类转换的json字符串,如果直接打印或存储到数据库中部分字符串数据相应会转义成带反斜杠的字符串形式,这种形式通过JSON工具类在后台正常解析是没有问题的,但如果是直接将解析数据返回给前台则相应要进行处理,将其处理成指定格式的JSON数据(一般可通过“去反斜杠”、“借助Map<String,Object>”转义封装)
a.常见JAVA后台解析JSON数据
(1)常用方法解析JSON数据
JSONObject类常用方法:
构造方法:JSONObject(String)
获取属性值:Object get(String)
获取数组和对象:JSONArray getJSONArray(String)、JSONObject getJSONObject(String)
获取迭代器包含关键字:Iterator<String> keys( )
解析方法的选择取决于当前要解析的这个key所对应的value是什么值,如果是普通value则直接get系列方法获取指定类型的属性值,如果是对象则通过getJSONObject获取,如果是数组则通过getJSONArray获取

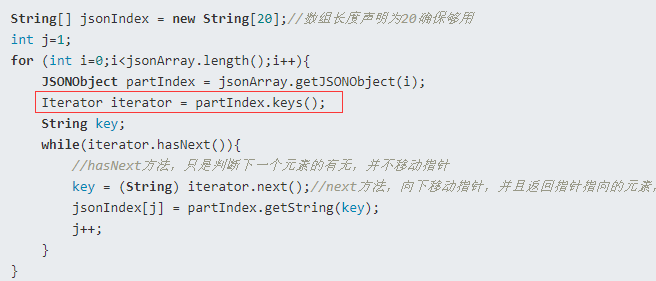
举例说明:
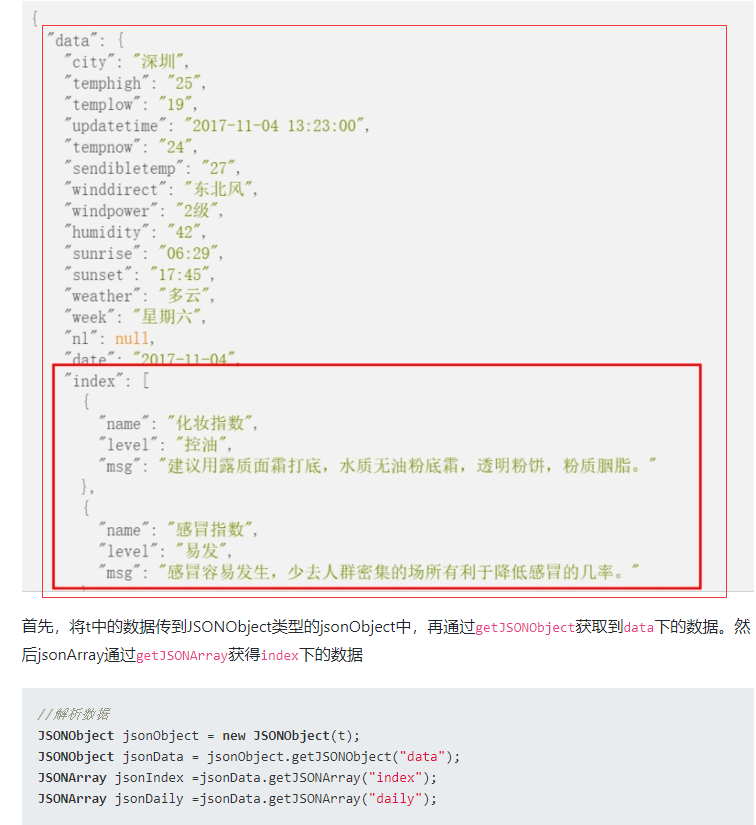
解析方式1:循环解析元素
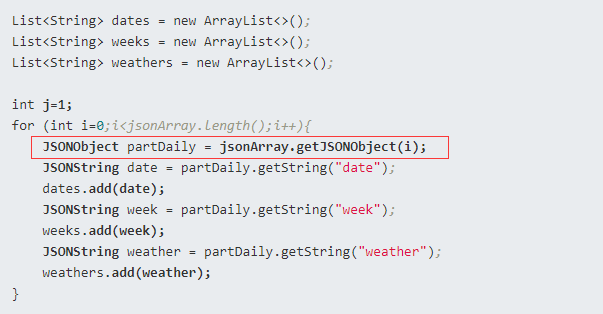
解析方式2:迭代器解析元素
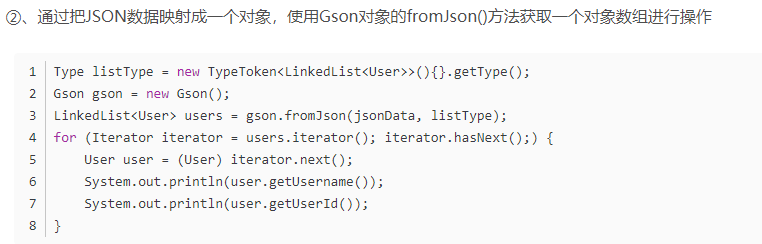
(2)使用JSON类库Gson解析JSON数据
Gson是Google提供的用来在 Java对象和JSON数据之间进行映射的Java类库。可以从code.google.com/p/google-gson/downloads/list下载GsonAPI(google-gson-1.7.1-release.zip、gson-1.7.jar)

此外,可借助GsonFormat 插件(https://github.com/zzz40500/GsonFormat)快速创建json所对应的JavaBean对象(自动生成实体类代码)
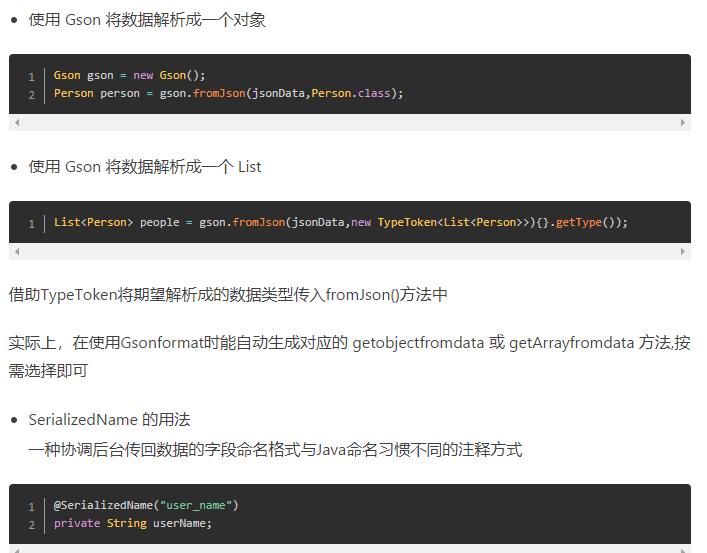
(3)自定义JsonUtils实现JSON数据和对象的转换
参考方式1:
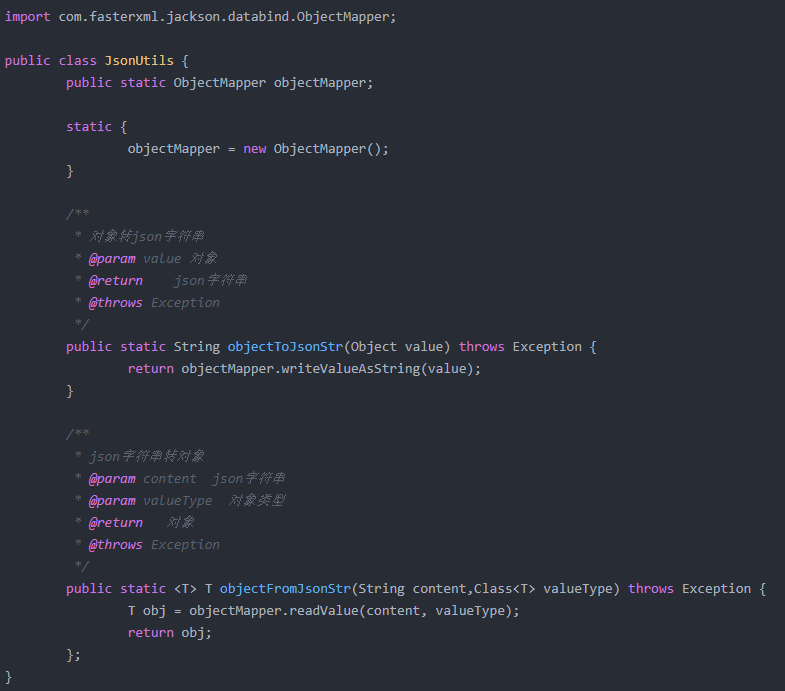
参考方式2:
package util;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.JavaType;
import com.fasterxml.jackson.databind.ObjectMapper;
/**
* @ClassName: CustomJsonUtils
* @Description: 自定义JSONUtils实现JSON与JAVA对象的转换
* @author
* @date 2020年3月24日
*/
public class CustomJsonUtils {
// 定义jackson对象
private static final ObjectMapper MAPPER = new ObjectMapper();
/**
* @Title: objectToJson
* @Description: 将对象转换成json字符串
* @param data
* @return
*/
public static String objectToJson(Object data) {
try {
String string = MAPPER.writeValueAsString(data);
return string;
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return null;
}
/**
* @Title: jsonToPojo
* @Description: 将json结果集转化为对象
* @param <T>
* @param jsonData
* @param beanType
* @return
*/
public static <T> T jsonToPojo(String jsonData, Class<T> beanType) {
try {
T t = MAPPER.readValue(jsonData, beanType);
return t;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* @Title: jsonToList
* @Description: 将json数据转换成pojo对象list
* @param <T>
* @param jsonData
* @param beanType
* @return
*/
public static <T>List<T> jsonToList(String jsonData, Class<T> beanType) {
JavaType javaType = MAPPER.getTypeFactory().constructParametricType(List.class, beanType);
try {
List<T> list = MAPPER.readValue(jsonData, javaType);
return list;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
(4)Map转化实体类
将map值转化为对应实体类属性
方式1:借助fastjson
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.30</version>
</dependency>
// 通过fastjson现将map转化为json字符串,随后再将字符串转化为实体类
JSON.parseObject(JSON.toJSONString(Map<String, ? extends Object>), Class<T> bean);
方式2:借助commons-beanutils
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
// 遍历map<key, value>中的key,如果bean中有这个属性,就把这个key对应的value值赋给bean的属性
BeanUtils.populate(Object bean, Map<String, ? extends Object> map)
(5)后台解析JSON数据常见问题
针对通过JSON工具类解析的json数据带有“反斜杠”(转义符)的情况,如果直接返回给前端或者是存储到数据库,虽然后台可以进行解析,但是不便于后台直接对数据进行错误排查。
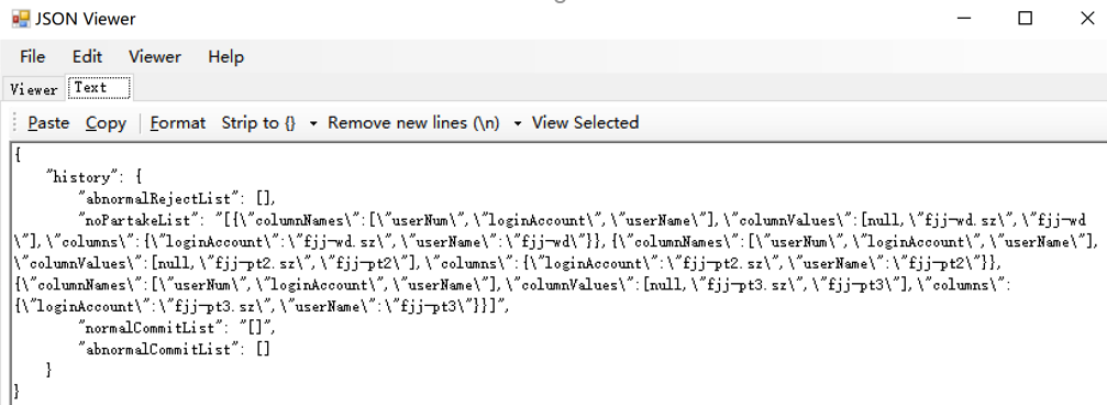
在解析json数据的时候将属性值当做“字符串”处理,因此可能出现。可考虑去除反斜杠或者是将相关数据强制映射成Map<String,Object>的形式
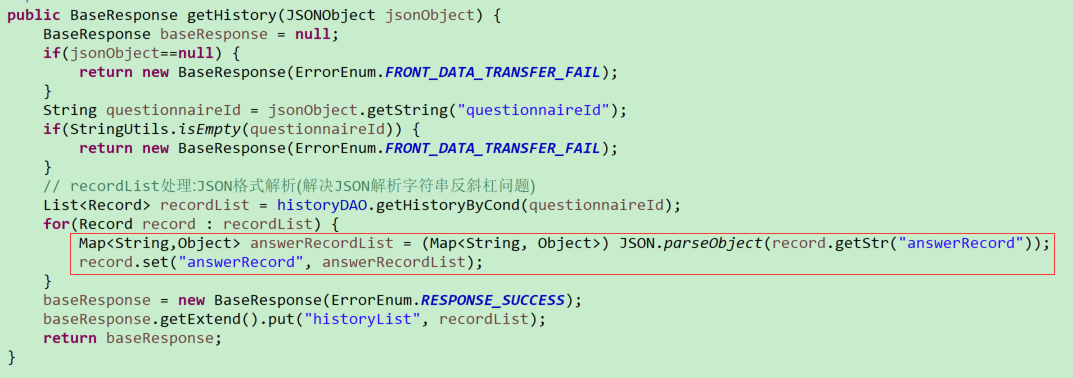
可以理解为Map<String,Object>对应的是一个JSONObject、List< Map<String,Object>>对应的是一个JSONArray
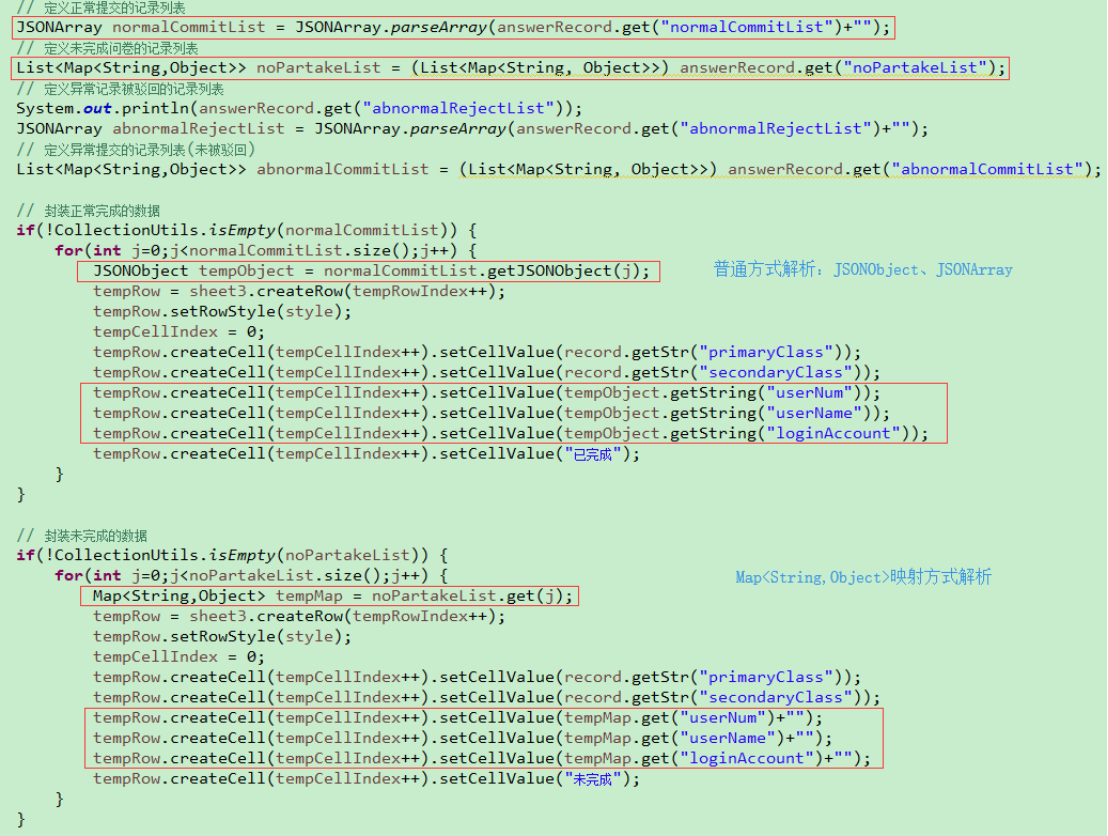
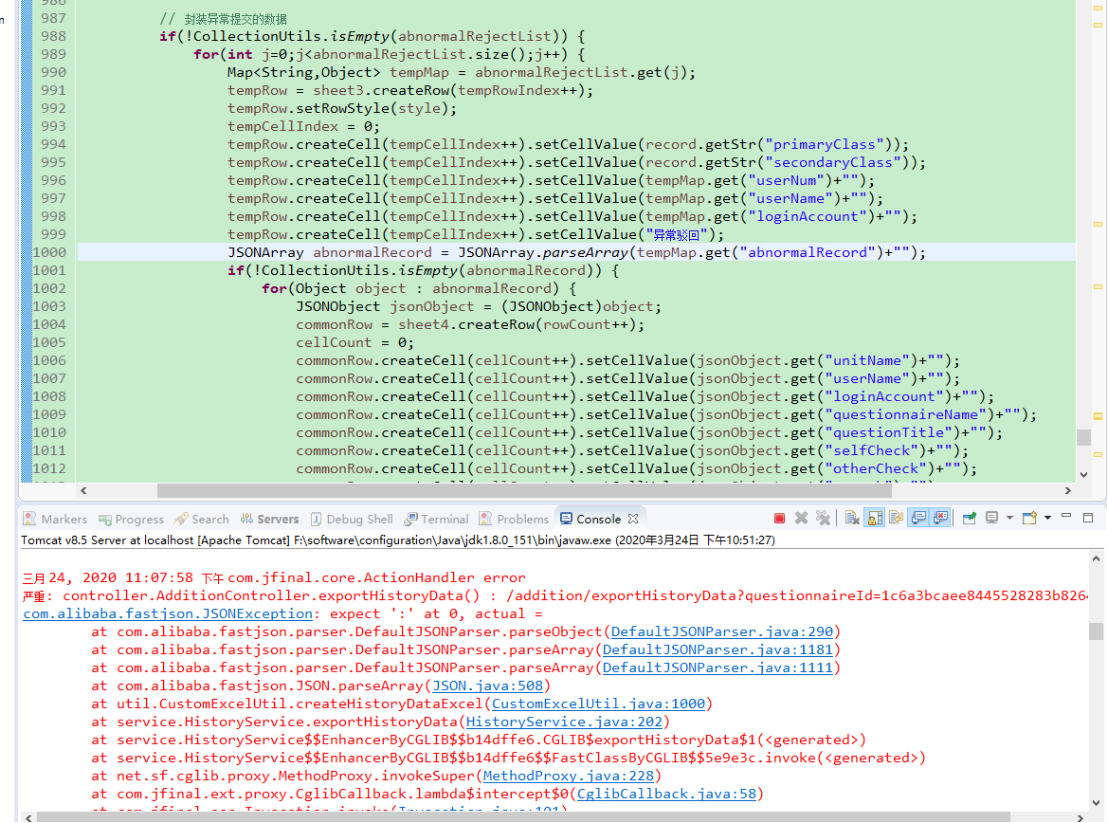
实际处理的时候不要混淆JSON处理相关方法与Map相关方法的使用,时刻注意每次解析出来的数据是否满足“标准JSON格式”,否则可能会出现如下JSON解析失败的问题(要采用正确的JSON解析方式)
其次,针对对象的某些属性出现null值的情况,需要对null进行处理。有些JSON工具类转化的数据出现“返回json数据为null的字段不显示”的问题,字段缺失可能引起前后端交互数据的时候出现异常,因此要进行相应处理
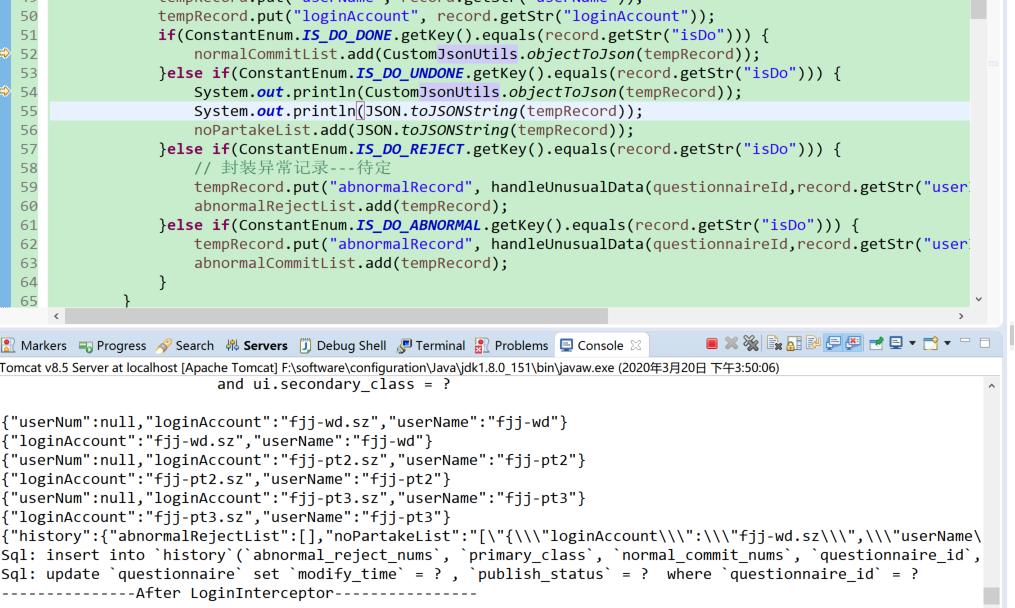
此外,亦可通过注解的形式使得属性值为null的字段也正常转换成相应的json数据(在定义了实体类的基础上实现)

b.常见JS解析JSON数据
JSON 文本格式在语法上与创建 JavaScript 对象的代码相同。由于这种相似性,无需解析器,JavaScript 程序能够使用内建的 eval() 函数,用 JSON 数据来生成原生的 JavaScript 对象。
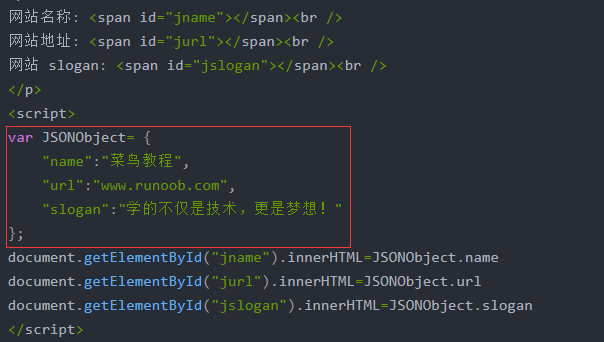
简单获取JSONObject数据:
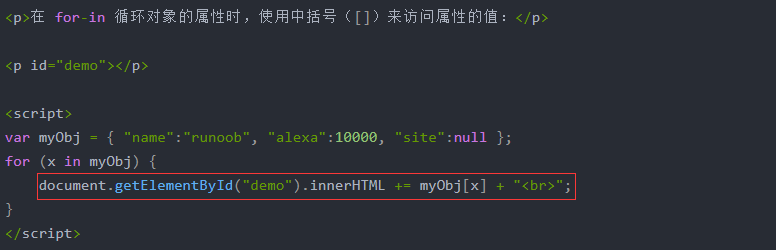
循环获取JSON对象属性:
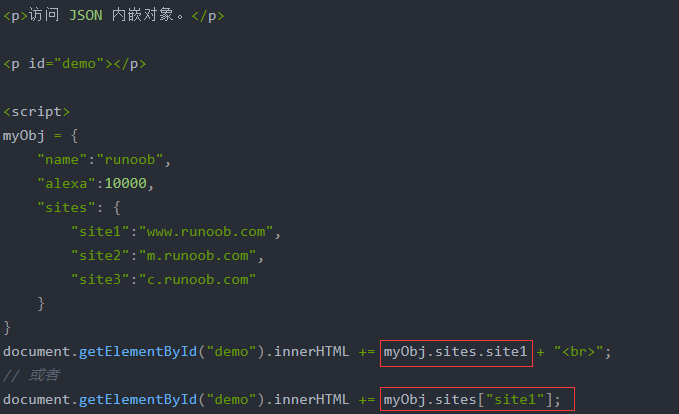
两级JSON内嵌:
通过索引值访问数组:(循环遍历)
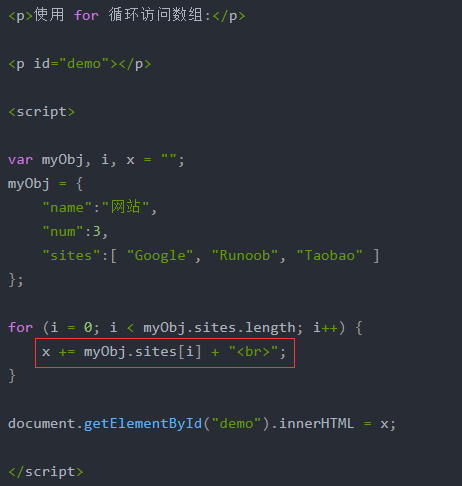
多级JSON内嵌:
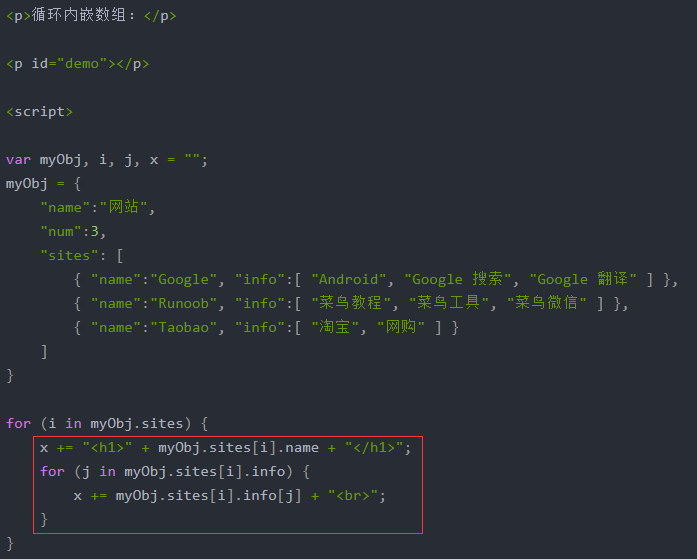
亦可通过‘.’和‘[ ]’修改、删除指定元素
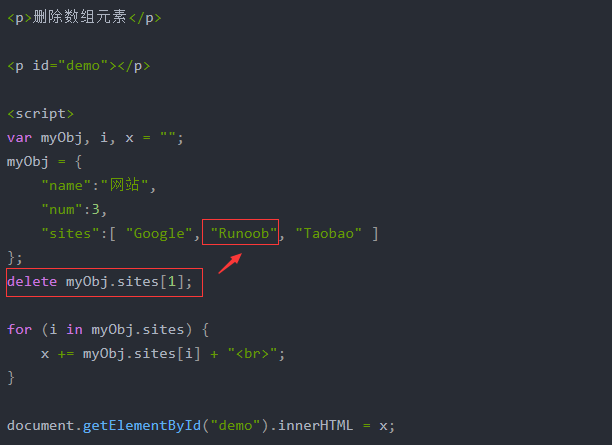
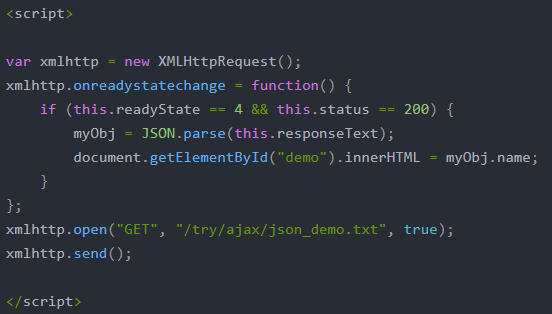
c.前后端交互数据
JSON 通常用于与服务端交互数据
前台接收服务器数据一般是字符串形式,JSON.parse()是标准的JSON格式),常见前后端通过ajax进行数据交互

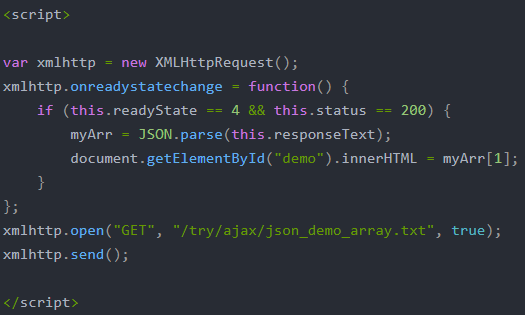
前台向服务器发送数据时一般是字符串形式,JSON.stringify()方法可将 JavaScript 对象转换为字符串,随后通过ajax请求发送给服务器
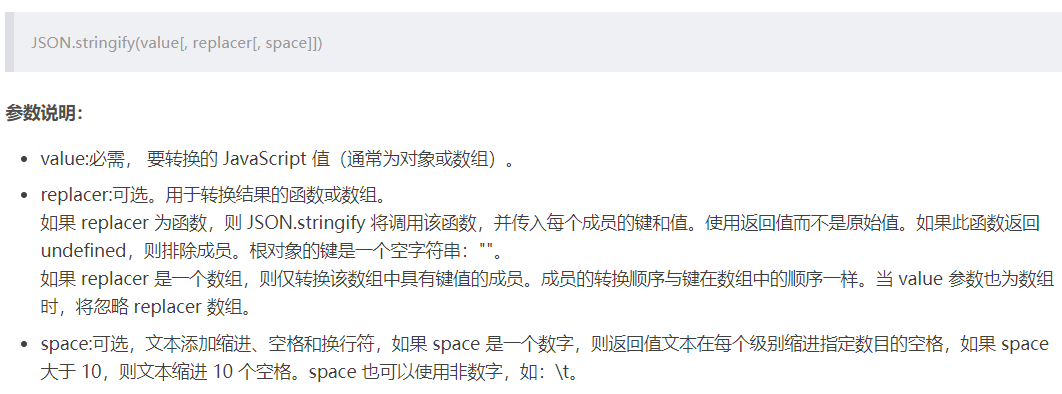
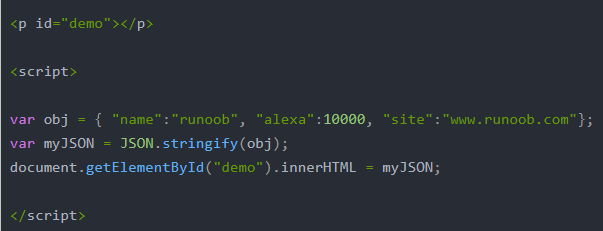
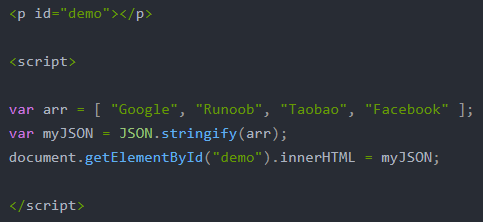
d.JSON转化常见异常
(1)JSON处理Date类型参数
JSON不能存储Date对象,因此在前后端交互的时候需要将日期转化为字符串形式,后台再对字符串进行解析,或者是后台通过注解方式处理带有日期格式的json数据


JSON不允许包括函数,JSON.stringify( ) 会删除 JavaScript 对象的函数,包括 key 和 value。如果需要在JSON中使用函数,则在封装JSON数据前先将指定函数内容转化为字符串形式(一般不建议在JSON中使用函数)
(2)JSON转化实体时Double数值转化精度丢失问题
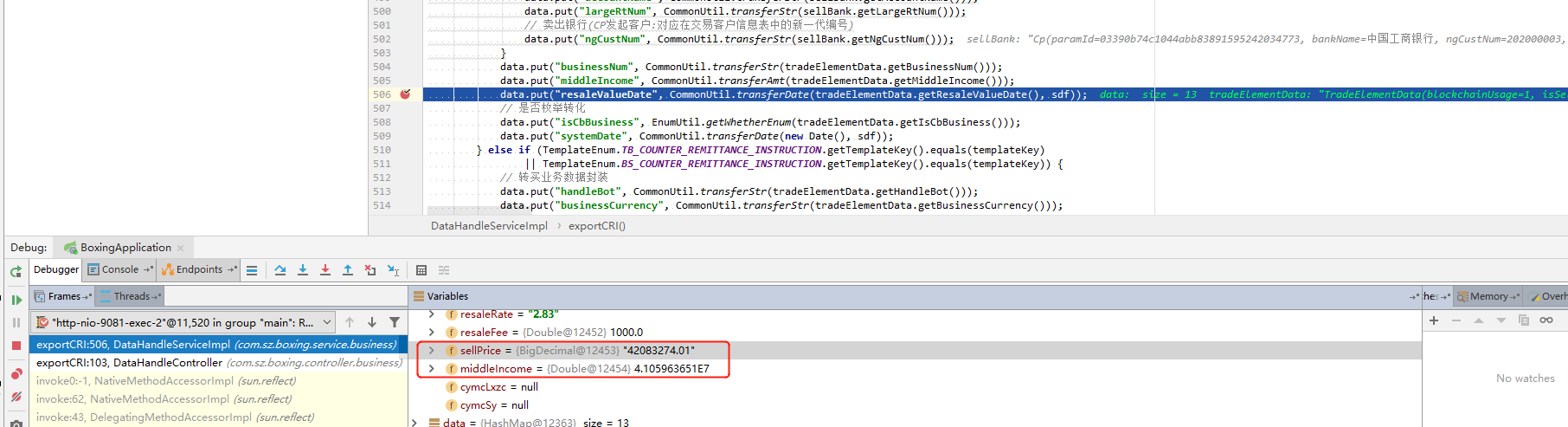
参考链接:
https://blog.csdn.net/ysh19911011/article/details/78934007
https://blog.csdn.net/jiachunchun/article/details/90235617
Feature参考:https://blog.csdn.net/u010246789/article/details/52539576
解决方式1:直接存储字符串数据,需要进行处理的时候再调整为double类型
解决方式2:把实体value字段数据类型定义为Object
参考方式:将Double类型全部调整为Object类型,相应需要注意JSON转化和数据处理
价格发布:日期处理问题(后台sql查询条件封装sql处理)
e.JSONP
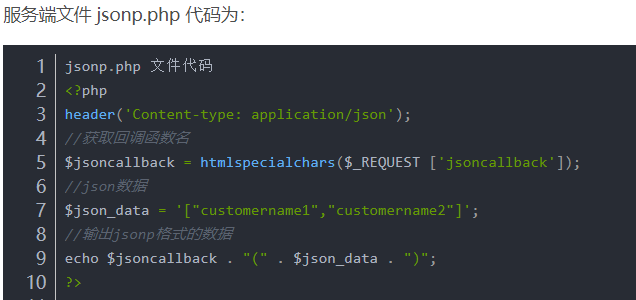
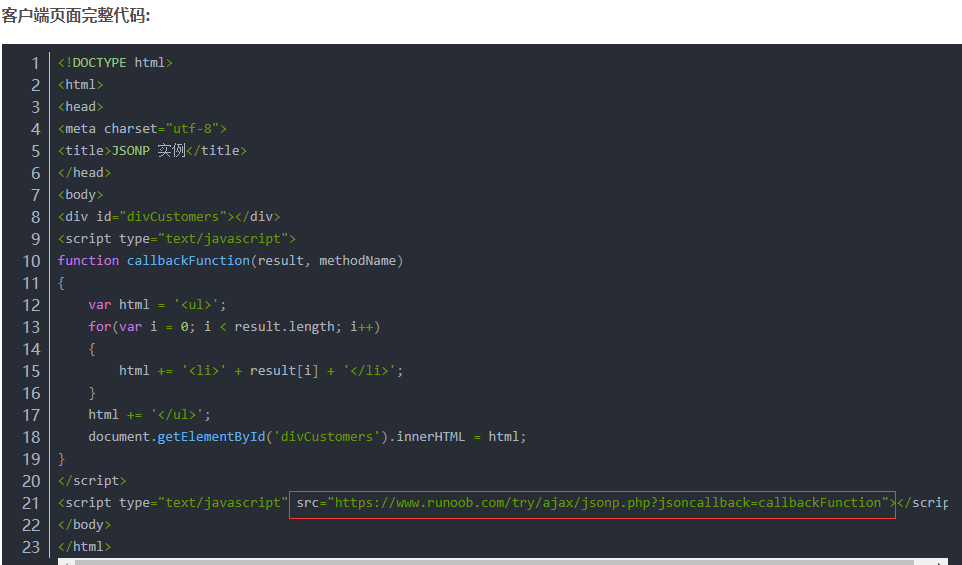
Jsonp(JSON with Padding) 是 json 的一种"使用模式",可以让网页从别的域名(网站)那获取资料,即跨域读取数据。同源策略是由 Netscape 提出的一个著名的安全策略,现在所有支持 JavaScript 的浏览器都会使用,这个策略的存在限制了页面从不同的域(网站)访问数据,可借助JSONP实现跨域请求
参考如下:
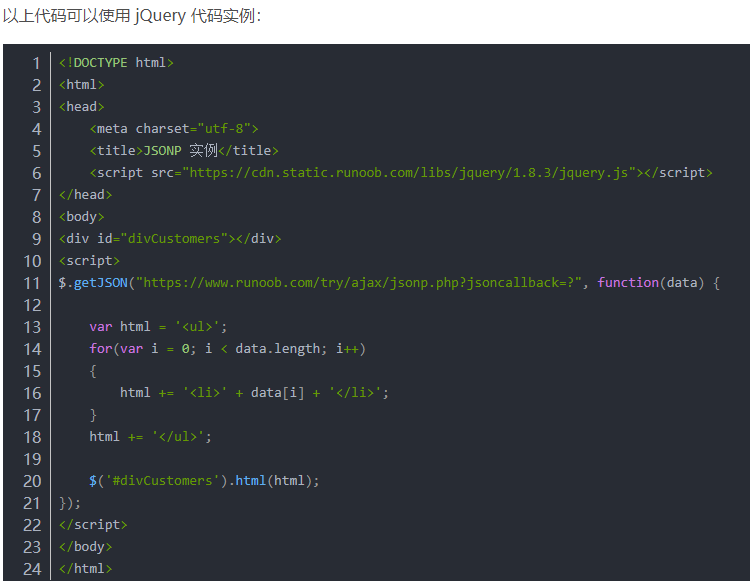
【7】对象“重复性验证”
【8】数据格式处理相关
a.大数格式处理
参考链接:https://www.cnblogs.com/jpfss/p/9987319.html
/**
* 金额格式化
* @param s 金额
* @param len 小数位数
* @return 格式后的金额
*/
public static String insertComma(String s, int len) {
if (s == null || s.length() < 1) {
return "";
}
NumberFormat formater = null;
double num = Double.parseDouble(s);
if (len == 0) {
formater = new DecimalFormat("###,###");
} else {
StringBuffer buff = new StringBuffer();
buff.append("###,###.");
for (int i = 0; i < len; i++) {
buff.append("#");
}
formater = new DecimalFormat(buff.toString());
}
return formater.format(num);
}
/**
* 金额去掉“,”
* @param s 金额
* @return 去掉“,”后的金额
*/
public static String delComma(String s) {
String formatString = "";
if (s != null && s.length() >= 1) {
formatString = s.replaceAll(",", "");
}
return formatString;
}
public static String formatMoney(String s, int len)
{
if (s == null || s.length() < 1) {
return "";
}
NumberFormat formater = null;
double num = Double.parseDouble(s);
if (len == 0) {
formater = new DecimalFormat("###,###");
} else {
StringBuffer buff = new StringBuffer();
buff.append("###,###.");
for (int i = 0; i < len; i++) {
buff.append("#");
}
formater = new DecimalFormat(buff.toString());
}
String result = formater.format(num);
if(result.indexOf(".") == -1)
{
result = "¥" + result + ".00";
}
else
{
result = "¥" + result;
}
return result;
}
【9】其他
项目启动的时候初始化数据到缓存(字典公共类数据等),当数据更新之后相应清空缓存
因此要考虑什么接口触发的时候会影响到缓存数据,相应要进行更新
提供通用的公有方法(例如通用文件上传、下载方法)
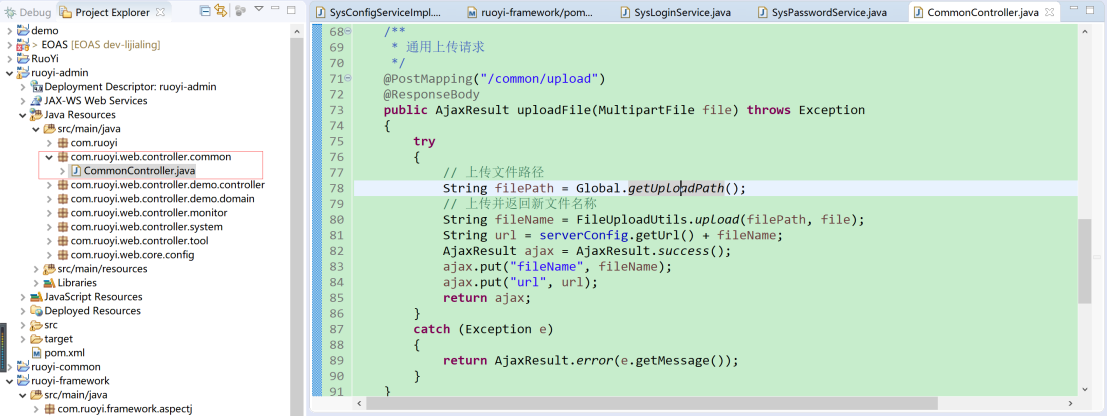
开发工具类
【1】工具类
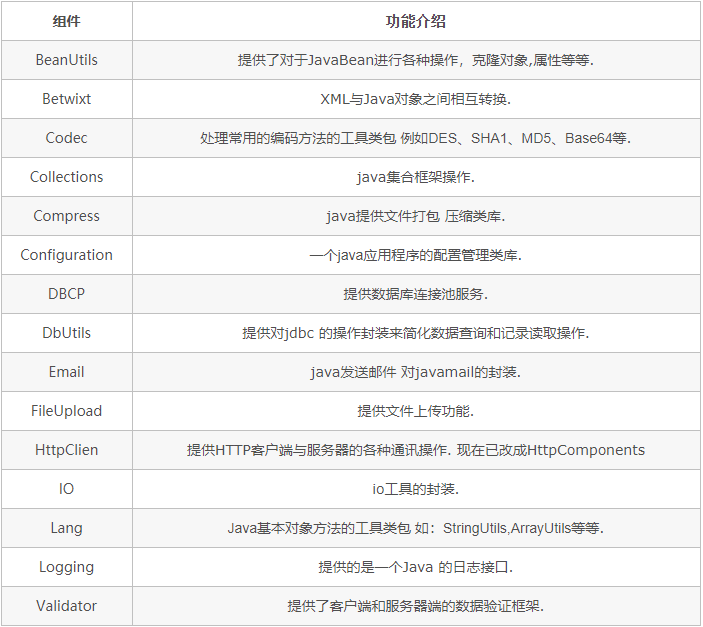
【2】Apache Commons jar包
参考链接:https://blog.csdn.net/HaHa_Sir/article/details/79583627
【3】简化代码工具lombok
lombok@EqualsAndHashCode注解的影响